本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。
多模型服务的挑战: 你有两个大语言模型,每个都能单独运行在GPU上,但无法同时加载。传统方案迫使您在两个不理想的选择中权衡:
- 同时加载两个模型 → 需要2倍GPU显存(成本高昂,往往不可行)
- 按需重载模型 → 每次切换需要30-100+秒(速度慢,资源浪费)

vLLM睡眠模式
vLLM睡眠模式提供了第三种方案: 模型在几秒内进入休眠,快速唤醒------在保持按需加载效率的同时,实现持久化服务的速度。
两种睡眠级别满足不同需求
- • 级别1(Level 1): 将模型权重卸载到CPU内存(唤醒时间快)
- • 级别2(Level 2): 完全丢弃权重(唤醒时间几乎同样快,内存占用最小)
两种级别都比完整重载快18-200倍,并且无缝支持张量并行(TP)、流水线并行(PP)和专家并行(EP)。
为什么睡眠模式优于快速权重加载器
即使拥有即时权重加载能力,每次冷启动仍需支付睡眠模式能够避免的隐藏成本:
| 成本项 | 描述 | 快速权重加载器 | 睡眠模式 |
|---|---|---|---|
| 1. 显存加载时间 | 将权重复制到GPU | ✅ 已优化 | ✅ 保留 |
| 2. 内存分配器设置 | CUDA分配器初始化 | ❌ 每次都要 | ✅ 保留 |
| 3. CUDA图捕获 | 记录执行图 | ❌ 每次都要 | ✅ 保留 |
| 4. GPU内核JIT编译 | DeepGEMM、FlashInfer、TorchInductor | ❌ 每次都要 | ✅ 保留(初次预热后) |
| 5. 缓存预热 | 首次请求开销 | ❌ 每次都要 | ⚡ 快速重新预热 |
通过保持进程活跃,睡眠模式保留了基础设施(2-4),避免了昂贵的重新初始化。这就是为什么基准测试显示睡眠模式推理比冷启动快61-88% 。
本文涵盖:
- • 跨模型规模(0.6B到235B)和GPU(A4000到A100)的全面基准测试
- • 深入技术剖析,解释性能提升的原因
- • 预热影响和FP8量化的消融研究
- • 选择合适睡眠级别的决策指南
快速入门:使用睡眠模式
在线服务API
启动两个启用睡眠模式的vLLM服务器:
css
# 终端1:启动 Phi-3-visionexport VLLM_SERVER_DEV_MODE=1vllm serve microsoft/Phi-3-vision-128k-instruct --enable-sleep-mode --port 8001# 终端2:启动 Qwen3-0.6Bexport VLLM_SERVER_DEV_MODE=1vllm serve Qwen/Qwen3-0.6B --enable-sleep-mode --port 8002休眠和唤醒模型
rust
# 让 Phi-3-vision 进入睡眠(级别2 - 最小内存占用)curl -X POST 'localhost:8001/sleep?level=2'# 让 Qwen3-0.6B 进入睡眠(级别2)curl -X POST 'localhost:8002/sleep?level=2'# 唤醒 Phi-3-vision 进行推理curl -X POST 'localhost:8001/wake_up'curl -X POST 'localhost:8001/collective_rpc' \ -H 'Content-Type: application/json' \ -d '{"method":"reload_weights"}'# 重要:级别2唤醒后需重置前缀缓存curl -X POST 'localhost:8001/reset_prefix_cache'# 现在在 Phi-3-vision 上运行推理...# (这里是您的推理请求)# 完成后让它重新睡眠curl -X POST 'localhost:8001/sleep?level=2'# 唤醒 Qwen3-0.6Bcurl -X POST 'localhost:8002/wake_up'# (级别1不需要 reload_weights 或 reset_prefix_cache)# 在 Qwen3-0.6B 上运行推理...Note
对于级别2睡眠,唤醒后必须调用
reload_weights和reset_prefix_cache。级别1睡眠不需要这些额外步骤。
Warning安全性:
/sleep、/wake_up、/collective_rpc和/reset_prefix_cache端点需要设置VLLM_SERVER_DEV_MODE=1,且只应在可信网络中暴露。这些管理端点可能会干扰服务,仅适用于训练集群或后端应用等封闭环境。
性能概览
让我们看看睡眠模式相比传统模型重载的性能表现。
睡眠模式L1与无睡眠模式的性能对比
下方的交互式图表显示了执行5次模型切换的总时间:在模型A上运行推理,切换到模型B,在模型B上运行推理,然后重复这个模式(A→B→A→B→A→B)。
使用睡眠模式: 模型在切换间休眠/唤醒,保留基础设施。 不使用睡眠模式: 每次切换需要完整的vLLM重启和重载。
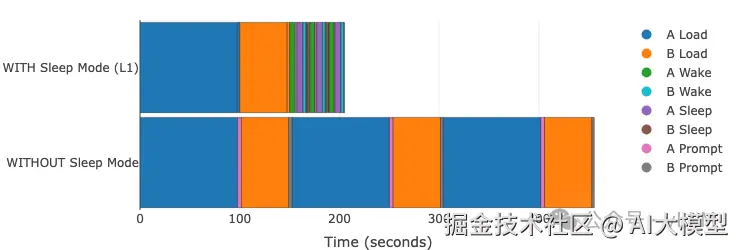
模型 A: Qwen3-235B-A22B-Instruct-2507-FP8 (TP=4) | 模型 B: Qwen3-Coder-30B-A3B-Instruct (TP=1) GPU: A100 | vLLM 0.11.0 | Sleep Level: 1 | 编译: cudagraph_mode: FULL_AND_PIECEWISE
推理性能提升
除了更快的模型切换,睡眠模式还带来更快的推理时间。因为模型从睡眠中唤醒时已经预热,跳过了影响新加载模型的冷启动开销。
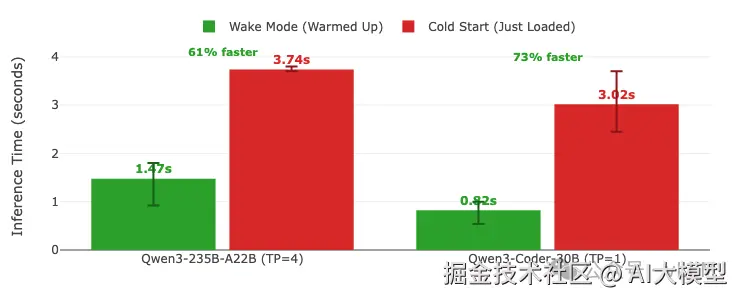
推理时间对比显示唤醒模式(已预热)与冷启动(刚加载)的差异。 推理时间 = 预填充 + 解码(唤醒/加载后的首次请求)。每个请求使用不同问题以避免缓存,输出限制为100个token。 误差棒显示多次运行中的最小/最大变化。数值直接标注在柱形图上。 GPU:A100 | vLLM 0.11.0 | 休眠等级:1 | 编译:cudagraph_mode: FULL_AND_PIECEWISE
为什么睡眠模式能提升推理速度
61-88%的推理加速并非来自更快的权重加载------而是来自保留昂贵的基础设施,这些是冷启动必须从头重建的。
睡眠模式保留的组件:
| 组件 | 是否保留? | 冷启动必须支付 |
|---|---|---|
| 内存分配器(CuMemAllocator) | ✅ 是 | ❌ 每次重新初始化 |
| CUDA图 | ✅ 是 | ❌ 每次重新捕获 |
| 进程状态(Python、CUDA上下文) | ✅ 是 | ❌ 每次重启 |
| GPU内核JIT缓存 | ✅ 是(初次预热后) | ❌ 每次重新编译 |
关键区别:
- • 无睡眠模式: 卸载时进程终止 → 无法从预热中受益
- • 必须重启Python进程和CUDA上下文
- • 必须重新初始化内存分配器
- • 必须重新捕获CUDA图
- • 必须重新JIT编译内核(DeepGEMM、FlashInfer、TorchInductor)
- • 结果: 首次推理慢4-7倍(见基准测试:0.92秒唤醒 vs 3.72秒冷启动)
- • 使用睡眠模式: 进程保持活跃 → 预热产生回报
- • ✅ 初次预热后,分配器、图、进程状态和JIT内核全部保留
- • 结果: 首次推理保持快速(约1秒),避免3-4秒的冷启动惩罚
Note
时间因模型大小、GPU代次和配置而异。详见预热的影响章节,显示无预热时有5-7倍的减速。
模型切换性能
睡眠模式最显著的优势体现在模型切换时间上。唤醒休眠模型比加载全新的vLLM实例快18-20倍。
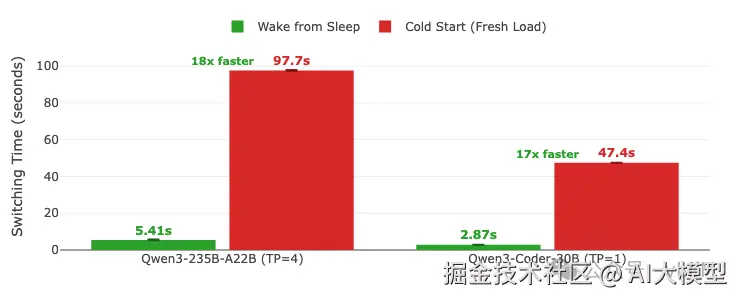
模型切换时间:从睡眠唤醒 vs 冷启动(全新加载)。误差线显示多次运行的最小/最大变化。柱状图上显示数值。GPU: A100 | vLLM 0.11.0 | 睡眠级别:1 | 编译模式:cudagraph_mode: FULL_AND_PIECEWISE
硬件可扩展性:A4000 GPU测试结果
睡眠模式的优势不局限于高端GPU。以下是在A4000 GPU上使用较小模型的相同工作负载,展示了性能提升在不同硬件层级和模型规模上的可扩展性。
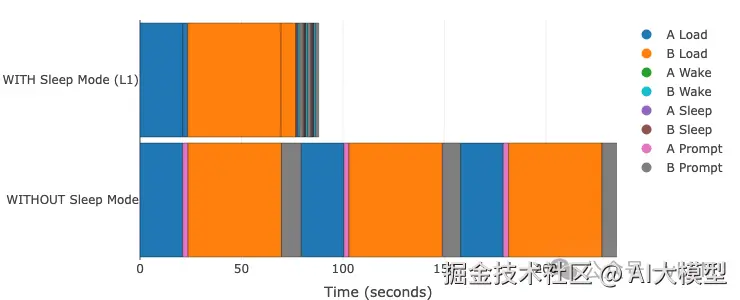
模型A: Qwen3-0.6B | 模型B: Phi-3-vision-128k-instruct GPU: A4000 (TP=1) | vLLM 0.11.0 | 睡眠级别:1 | 编译模式:cudagraph_mode: FULL_AND_PIECEWISE
A4000:推理性能
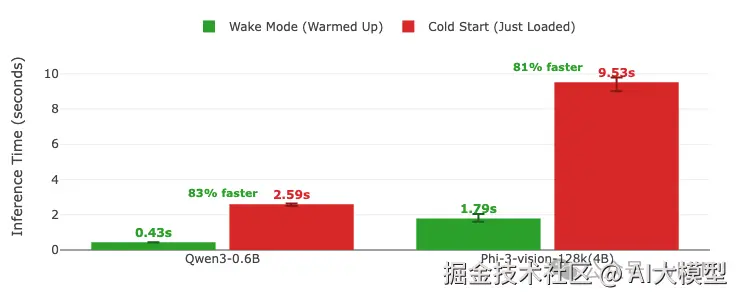
A4000上的推理时间对比:唤醒模式(已预热)vs 冷启动(刚加载)。 推理时间 = 预填充 + 解码(唤醒/加载后的首次请求)。 每个请求使用不同的问题以避免缓存,输出限制为100个token。 误差线显示多次运行的最小/最大变化。柱状图上显示数值。 GPU: A4000 (TP=1) | vLLM 0.11.0 | 睡眠级别:1 | 编译模式:cudagraph_mode: FULL_AND_PIECEWISE
A4000:模型切换性能
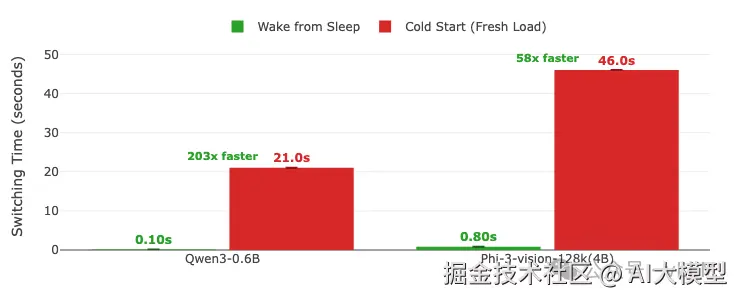
A4000上的模型切换时间:从睡眠唤醒 vs 冷启动(全新加载)。 误差线显示多次运行的最小/最大变化。柱状图上显示数值。 GPU: A4000 (TP=1) | vLLM 0.11.0 | 睡眠级别:1 | 编译模式:cudagraph_mode: FULL_AND_PIECEWISE
A4000上的关键观察:
- • 推理性能: 唤醒模式为Qwen3-0.6B带来83%的加速,为Phi-3-vision带来81%的加速
- • 模型切换: 唤醒时间极快(约0.1-0.8秒),实现了58-203倍的加速相比冷启动
- • 总时间节省:62% (5次模型切换85秒 vs 226秒)
- • 小模型近乎瞬间切换(0.1秒唤醒时间),使多模型服务体验无缝
- • 展示了睡眠模式在不同GPU类别和模型规模上的有效性
睡眠级别:选择合适的模式
vLLM睡眠模式提供两种级别,具有不同的权衡:
级别1(默认): 将模型权重卸载到CPU内存,丢弃KV缓存
- • 最快的唤醒时间(小模型约0.1-0.8秒,大模型约3-6秒)
- • 需要充足的CPU内存来存储模型权重
- • 最适合: 具有足够CPU内存的系统,频繁的模型切换
级别2: 丢弃模型权重和KV缓存,仅在CPU中保留缓冲区(rope scaling张量等)
- • 较慢的唤醒时间(小模型约0.8-2.6秒),因为需要从磁盘重新加载权重
- • CPU内存占用最小 - 仅保留少量缓冲区
- • 最适合: CPU内存有限的系统,或需要管理众多无法全部驻留内存的模型
性能对比:级别1 vs 级别2 vs 无睡眠
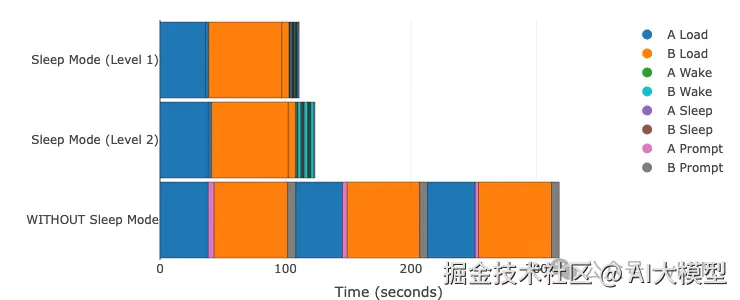
模型A: Qwen3-0.6B | 模型B: Phi-3-vision-128k-instruct GPU: A100 (TP=1) | vLLM 0.11.0 | 编译模式:cudagraph_mode: FULL_AND_PIECEWISE 对比三种模式:级别1(最快)、级别2(最小内存)、无睡眠。悬停查看精确时间。
性能总结:
| 模式 | 总时间 | 唤醒时间(A/B) | CPU内存 | 最适合 |
|---|---|---|---|---|
| 无睡眠 | 357.1秒 | 不适用(完整重载) | 最小 | 单模型,无切换 |
| 级别1 | 112.6秒 | 0.26秒 / 0.82秒 | 高(每模型约GB级) | 频繁切换,内存充足 |
| 级别2 | 124.6秒 | 0.85秒 / 2.58秒 | 最小(每模型约MB级) | 内存有限,成本优化 |
关键洞察:
- • 级别1最快(比无睡眠快68%),但需要大量CPU内存
- • 级别2几乎同样快(比无睡眠快65%),内存需求最小
- • 级别2唤醒比级别1慢约3倍(Qwen3-0.6B为0.85秒 vs 0.26秒),因为需要重载权重
- • 两种睡眠模式都比无睡眠模式显著改进
为什么级别2仍然比无睡眠模式快
乍看之下,这似乎违反直觉:级别2从SSD重新加载权重 (就像"无睡眠模式"一样),那为什么整体上快23-45倍?
答案:权重加载只是五项成本之一
当您在无睡眠模式下重新加载模型时,需要支付所有这些成本:
| 成本项 | 级别2 | 无睡眠模式 |
|---|---|---|
| 1. 权重加载(SSD → 显存) | ❌ 必须支付 | ❌ 必须支付 |
| 2. 进程初始化 | ✅ 跳过 | ❌ 必须支付 |
| 3. 内存分配器设置 | ✅ 跳过 | ❌ 必须支付 |
| 4. CUDA图捕获 | ✅ 跳过 | ❌ 必须支付 |
| 5. GPU内核JIT编译 | ✅ 保留(已编译) | ❌ 完整编译 + 预热 |
级别2策略:
- • 从SSD重新加载权重(与无睡眠相同)
- • 其他一切都保留: 进程状态、分配器实例、CUDA图和已编译的JIT内核全部完整
- • 无需重新编译: 内核在初始预热期间已编译并保持缓存
- • 平均每次切换:约2.6秒(见上述基准数据)
无睡眠模式现实:
- • 从SSD重新加载权重(与级别2相同)
- • 其他一切重建: 进程重启 + 分配器初始化 + 图重新捕获
- • JIT内核: 完整编译 + 显式预热例程(
kernel_warmup()+ 虚拟运行) - • 平均每次切换:约48秒(见上述基准数据)
基准数据证明: 5次模型切换:
- • 级别2: 总计124.6秒(平均每次约2.6秒)
- • 无睡眠: 总计357.1秒(平均每次约48秒)
即使两者都从SSD重新加载权重,级别2整体快2.9倍,因为它保留了无睡眠模式每次都必须从头重建的昂贵基础设施(进程状态、分配器、CUDA图)。
级别2:推理性能
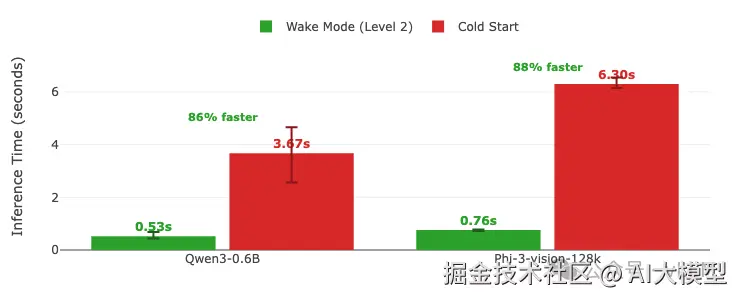
睡眠级别2的推理时间对比:唤醒模式 vs 冷启动。 推理时间 = 预填充 + 解码(唤醒/加载后的首次请求)。 每个请求使用不同的问题以避免缓存,输出限制为100个token。 误差线显示多次运行的最小/最大变化。柱状图上显示数值。 GPU: A100 (TP=1) | vLLM 0.11.0 | 睡眠级别:2 | 编译模式:cudagraph_mode: FULL_AND_PIECEWISE
级别2:模型切换性能
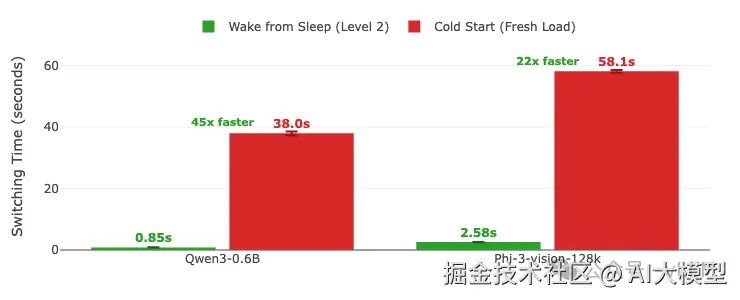
睡眠级别2的模型切换时间:从睡眠唤醒 vs 冷启动。 误差线显示多次运行的最小/最大变化。柱状图上显示数值。 GPU: A100 (TP=1) | vLLM 0.11.0 | 睡眠级别:2 | 编译模式:cudagraph_mode: FULL_AND_PIECEWISE
关键观察:
| 指标 | 无睡眠 | 级别2 | 改进 |
|---|---|---|---|
| 总时间(5次切换) | 357.1秒 | 124.6秒 | 快65% |
| Qwen3-0.6B切换时间 | 平均37.6秒 | 平均0.85秒 | 快45倍 |
| Phi-3-vision切换时间 | 平均58.1秒 | 平均2.58秒 | 快23倍 |
| Qwen3-0.6B推理 | 平均3.67秒 | 平均0.53秒 | 快86% |
| Phi-3-vision推理 | 平均6.30秒 | 平均0.76秒 | 快88% |
| 唤醒时间 vs 级别1 | - | 慢3-10倍 | 用CPU内存换速度 |
何时使用级别2:
- • CPU内存有限: 系统无法在CPU内存中容纳所有模型权重
- • 成本优化: CPU内存较少的云实例更便宜
- • 多模型: 在众多模型间切换,CPU内存成为约束
- • 仍有显著提升: 即使需要重载权重,级别2仍比无睡眠模式快23-45倍
级别1 vs 级别2对比:
- • 级别1:约0.1-0.8秒唤醒时间,每模型需要约10-100GB+ CPU内存
- • 级别2:约0.8-2.6秒唤醒时间,每模型仅需约MB级CPU内存
- • 两者都比完整重载(约20-100秒)快得多
消融研究
预热对睡眠模式的影响
跳过预热阶段会影响性能吗?预热在初始加载期间预编译CUDA图,这可能需要几秒钟。让我们对比有预热和无预热的情况。
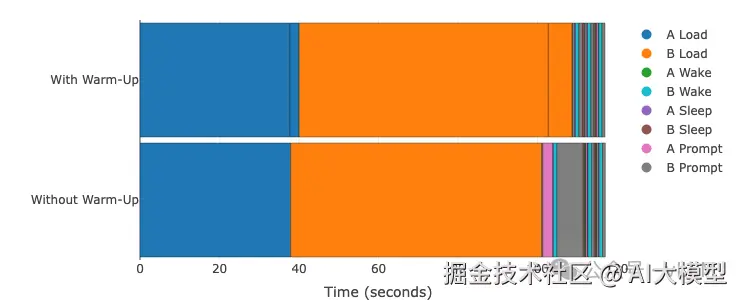
模型A: Qwen3-0.6B | 模型B: Phi-3-vision-128k-instruct GPU: A100 (TP=1) | vLLM 0.11.0 | 睡眠级别:1 | 编译模式:cudagraph_mode: FULL_AND_PIECEWISE对比有预热(预编译)vs 无预热(延迟编译)。悬停查看精确时间。
关键发现:
| 指标 | 有预热 | 无预热 | 差异 |
|---|---|---|---|
| 初始加载时间 | 108.7秒(含8.4秒预热) | 101.1秒(无预热) | 初始节省7.6秒 |
| 首次推理(A) | 0.45秒 | 2.59秒 | 无预热慢5.8倍 |
| 首次推理(B) | 0.93秒 | 6.61秒 | 无预热慢7.1倍 |
| 后续推理 | 平均0.43秒 | 平均0.41秒 | 无差异 |
| 总时间(5次切换) | 119.5秒 | 119.0秒 | 几乎相同 |
洞察:
- • 预热一次编译内核,所有唤醒周期受益: 通过初始预热,JIT编译和CUDA图捕获在加载时进行一次,并在所有后续睡眠/唤醒周期中保留
- • 无预热时,每次唤醒都要支付编译成本: 5-7倍的减速发生在每次唤醒后的首次推理,而不仅仅是一次
- • 已编译内核在睡眠/唤醒间保留: 初始加载期间预热后(8.4秒),所有后续唤醒都有快速的首次推理(0.45秒、0.93秒),证明内核保持缓存
- • 最小预热即可: 单次1-token推理足以触发完整的JIT编译和CUDA图捕获,使预热成本非常低
- • 用初始加载时间换取一致性能: 8.4秒的预热成本支付一次,在所有模型切换中摊销
- • 建议:生产工作负载始终使用预热,以获得一致、快速的推理表现
量化对睡眠模式的影响
量化(FP8)会影响睡眠模式的性能吗?我们在A100 GPU上使用和不使用FP8量化测试了相同的工作负载。
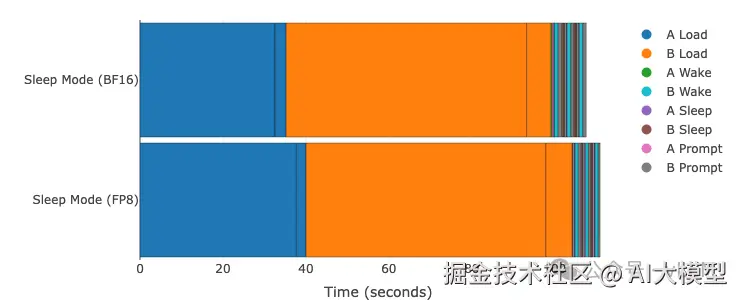
模型A: Qwen3-0.6B | 模型B: Phi-3-vision-128k-instruct GPU: A100 (TP=1) | vLLM 0.11.0 | 睡眠级别:1 | 编译模式:cudagraph_mode: FULL_AND_PIECEWISE对比BF16(基线)vs FP8量化。悬停查看精确时间。
消融:推理性能(BF16 vs FP8)
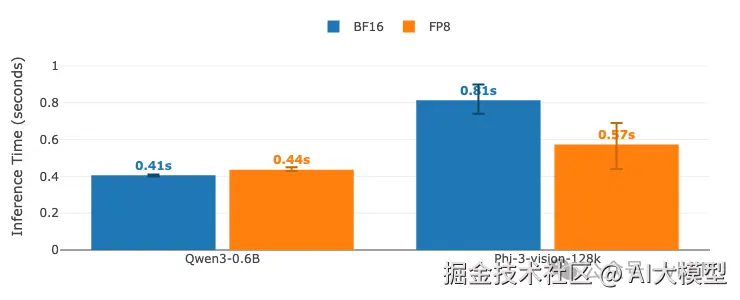
推理时间对比:睡眠模式下BF16 vs FP8量化。 推理时间 = 预填充 + 解码(唤醒/加载后的首次请求)。 每个请求使用不同的问题以避免缓存,输出限制为100个token。 误差线显示多次运行的最小/最大变化。柱状图上显示数值。 GPU: A100 (TP=1) | vLLM 0.11.0 | 睡眠级别:1 | 编译模式:cudagraph_mode: FULL_AND_PIECEWISE
消融:模型切换(BF16 vs FP8)
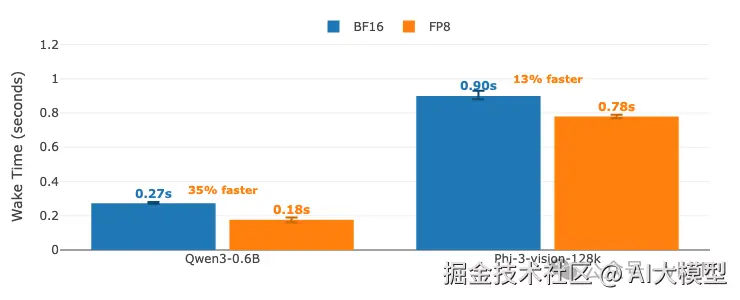
模型切换时间:睡眠模式下BF16 vs FP8量化。 误差线显示多次运行的最小/最大变化。柱状图上显示数值。 GPU: A100 (TP=1) | vLLM 0.11.0 | 睡眠级别:1 | 编译模式:cudagraph_mode: FULL_AND_PIECEWISE
关键发现:
| 指标 | BF16 | FP8 | 改进 |
|---|---|---|---|
| 总时间(5次切换) | 108.2秒 | 113.6秒 | -5%(略慢) |
| Qwen3-0.6B唤醒时间 | 平均0.27秒 | 平均0.18秒 | 快33% |
| Phi-3-vision唤醒时间 | 平均0.90秒 | 平均0.78秒 | 快13% |
| Qwen3-0.6B推理 | 平均0.41秒 | 平均0.44秒 | -7%(略慢) |
| Phi-3-vision推理 | 平均0.81秒 | 平均0.57秒 | 快30% |
| 初始加载时间 | 90.5秒 | 96.9秒 | -7%(预热更长) |
洞察:
- • FP8唤醒操作更快(13-33%更快),因为内存移动更少
- • FP8改善大模型推理(Phi-3-vision快30%),但对小模型差异极小
- • FP8初始加载时间更长,因为预热期间的量化开销
- • 初始加载后,FP8提供更流畅的切换,唤醒周期更快
- • 对于频繁切换的工作负载,FP8更快的唤醒时间可以抵消更长的初始加载
决策指南:使用哪个睡眠级别?
使用睡眠级别1的场景:
- • 您有足够的CPU内存来容纳所有模型权重
- • 您需要最快的唤醒时间(0.1-6秒)
- • 您非常频繁地切换模型(每几秒/分钟)
- • 推理延迟一致性至关重要
使用睡眠级别2的场景:
- • CPU内存有限(无法容纳所有模型权重)
- • 您正在优化云成本(内存更少的实例更便宜)
- • 您有许多模型需要管理(10+个)
跳过睡眠模式的场景:
- • 您只使用单个模型(无需切换)
- • 模型切换极为罕见(每天/周一次)
- • 两个模型可以同时驻留GPU内存
结论
vLLM睡眠模式将多模型GPU服务从30-100秒的重载惩罚转变为亚秒级切换。基准测试本身就说明了一切:
- • 18-200倍更快的模型切换,取决于模型大小和硬件
- • 61-88%更快的推理,预热模型 vs 冷启动
- • 65-68%的总时间节省,跨完整工作负载
- • 在各个规模都有效: 0.6B到235B参数,小型和大型GPU
LLM服务的未来是多模型。睡眠模式让这一切在今天成为现实。
学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。