ELK日志系统部署与使用(Elasticsearch、Logstash、Kibana)
一、背景与目标
背景
- 日志是系统和业务状态的重要记录。
- 传统方式(如
rsyslog、grep、awk)在分布式环境下效率低下,无法满足统计、检索和可视化需求。 - 需要一套集中式的日志收集、分析与展示系统。
任务目标
- 搭建 ELK 集群(Elasticsearch + Logstash + Kibana)。
- 收集系统与业务日志并进行可视化展示。
二、ELK 简介
组件说明
| 组件 | 功能 |
|---|---|
| Elasticsearch | 分布式搜索引擎,负责存储与检索 |
| Logstash | 日志收集、过滤、转发 |
| Kibana | 图形化日志展示与分析界面 |
架构流程
txt
应用服务器 → Logstash(收集过滤) → Elasticsearch(存储索引) → Kibana(可视化展示)三、环境准备
主机规划
| IP | 主机名 | 角色 |
|---|---|---|
| 192.168.100.10 | es1.example.com | Elasticsearch |
| 192.168.100.20 | es2.example.com | Elasticsearch |
| 192.168.100.30 | logstash.example.com | Logstash |
系统配置
-
关闭防火墙和 seLinux
-
时间同步
-
修改
/etc/hosts
四、Elasticsearch 部署
1. 安装
bash
# 查看 java 版本
[root@es1 ~]# java -version
[root@es1 ~]# rpm -qa |grep openjdk
bash
# 安装 Elasticsearch
[root@es1 ~]# wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.5.2.rpm
[root@es1 ~]# rpm -ivh elasticsearch-6.5.2.rpm2. 配置文件 /etc/elasticsearch/elasticsearch.yml
bash
[root@es1 ~]# vim /etc/elasticsearch/elasticsearch.yml
[root@es1 ~]# systemctl restart elasticsearch.service
[root@es1 ~]# systemctl enable elasticsearch.service
yaml
cluster.name: elk-cluster # 可以自定义一个集群名称
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0 # 打开注释,并修改为监听所有
http.port: 9200 # 打开注释,监听端口92003. 验证
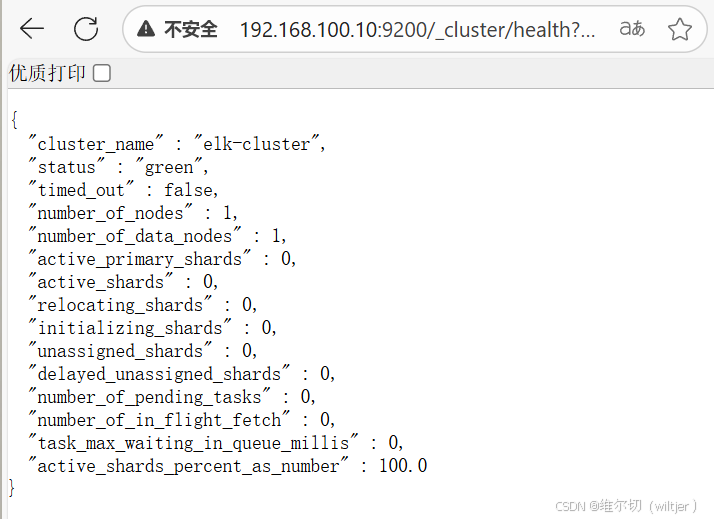
五、Elasticsearch 集群部署
集群部署主要注意以下几个方面
集群配置参数:
- discovery.zen.ping.unicast.hosts,Elasticsearch默认使用Zen Discovery来做节点发现机制,推荐使用unicast来做通信方式,在该配置项中列举出Master节点
- discovery.zen.minimum_master_nodes,该参数表示集群中Master节点可工作Master的最小票数,默认值是1。为了提高集群的可用性,避免脑裂现象。官方推荐设置为(N/2)+1,其中N是具有Master资格的节点的数量
- discovery.zen.ping_timeout,表示节点在发现过程中的等待时间,默认值是30秒,可以根据自身网络环境进行调整,一定程度上提供可用性
集群节点:
- 节点类型主要包括Master节点和data节点(client节点和ingest节点不讨论)。通过设置两个配
置项node.master和node.data为true或false来决定将一个节点分配为什么类型的节点 - 尽量将Master节点和Data节点分开,通常Data节点负载较重,需要考虑单独部署
内存:
- Elasticsearch默认设置的内存是1GB,对于任何一个业务部署来说,这个都太小了。通过指ES_HEAP_SIZE环境变量,可以修改其堆内存大小,服务进程在启动时候会读取这个变量,并相应的设置堆的大小。建议设置系统内存的一半给Elasticsearch,但是不要超过32GB
硬盘空间:
- Elasticsearch默认将数据存储在/var/lib/elasticsearch路径下,随着数据的增长,一定会出现
硬盘空间不够用的情形,大环境建议把分布式存储挂载到/var/lib/elasticsearch目录下以方便
扩容
配置参考文档:
节点1
bash
[root@es1 ~]# vim /etc/elasticsearch/elasticsearch.yml
[root@es1 ~]# systemctl restart elasticsearch.service
yaml
cluster.name: elk-cluster
node.name: 192.168.100.10
node.master: false
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
http.port: 9200
discovery.zen.ping.unicast.hosts: ["192.168.100.10", "192.168.100.20"]节点2
bash
[root@es2 ~]# vim /etc/elasticsearch/elasticsearch.yml
[root@es2 ~]# systemctl restart elasticsearch.service
yaml
cluster.name: elk-cluster
node.name: 192.168.100.20
node.master: true
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
http.port: 9200
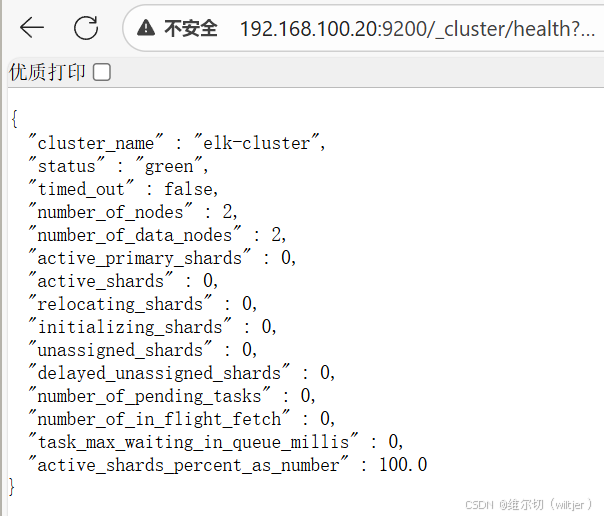
discovery.zen.ping.unicast.hosts: ["192.168.100.10", "192.168.100.20"]验证
六、Elasticsearch 基础概念
| 术语 | 说明 |
|---|---|
| Node | 单个 ES 实例 |
| Cluster | 多个节点组成的集群 |
| Index | 文档集合,类比数据库 |
| Type | 索引中的逻辑分类(已逐步弃用) |
| Document | 索引中的一条记录 |
| Shard | 索引的分片 |
| Replica | 分片的副本 |
七、Elasticsearch 基础 API 操作
查看索引
默认现在没有任何索引
bash
[root@es2 ~]# curl http://192.168.100.20:9200/_cat/indices?v
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size创建索引
bash
[root@es2 ~]# curl -X PUT http://192.168.100.20:9200/nginx_access_log
{"acknowledged":true,"shards_acknowledged":true,"index":"nginx_access_log"}[root@es2 ~]#
[root@es2 ~]# curl http://192.168.100.20:9200/_cat/indices?v
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open nginx_access_log zquBBLuvRnu0MRHtkJ7CNg 5 1 0 0 2.5kb 1.2kbgreen:所有的主分片和副本分片都已分配。你的集群是100%可用的。yellow:所有的主分片已经分片了,但至少还有一个副本是缺失的。不会有数据丢失,所以搜索结果依
然是完整的。不过,你的高可用性在某种程度上被弱化。如果 更多的 分片消失,你就会丢数据了。把
yellow 想象成一个需要及时调查的警告。red:至少一个主分片(以及它的全部副本)都在缺失中。这意味着你在缺少数据:搜索只能返回部分数
据,而分配到这个分片上的写入请求会返回一个异常。
删除索引
bash
[root@es2 ~]# curl -X DELETE http://192.168.100.20:9200/nginx_access_log
{"acknowledged":true}
[root@es2 ~]# curl http://192.168.100.20:9200/_cat/indices?v
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size八、 ES查询语句
ES提供一种可用于执行查询JSON式的语言,被称为Query DSL
针对elasticsearch的操作,可以分为增、删、改、查四个动作
查询匹配条件:
- match_all
- from,size
- match
- bool
- range
查询应用案例
导入官方示例数据
下载并导入进elasticsearch
bash
# 下载数据
[root@es2 ~]# wget https://raw.githubusercontent.com/elastic/elasticsearch/master/docs/src/test/resources/accounts.json
# 导入数据
[root@es2 ~]# curl -H "Content-Type: application/json" -XPOST "192.168.100.20:9200/bank/_doc/_bulk?pretty&refresh" --data-binary "@accounts.json"
# 查询数据
[root@es2 ~]# curl "192.168.100.20:9200/_cat/indices?v"查询bank索引的数据(使用查询字符串进行查询)
默认结果为10条
_search 属于一类API,用于执行查询操作
q=* ES批量索引中的所有文档
sort=account_number:asc 表示根据account_number按升序对结果排序
pretty调整显示格式
bash
[root@es2 ~]# curl -X GET "192.168.100.20:9200/bank/_search?q=*&sort=account_number:asc&pretty"查询bank索引的数据 (使用json格式进行查询)
注意: 最后为单引号
bash
[root@es2 ~]# curl -X GET "192.168.100.20:9200/bank/_search" -H 'Content-Type:application/json' -d'
> {
> "query": { "match_all": {} },
> "sort": [
> { "account_number": "asc" }
> ]
> }
> '查询匹配动作及案例
- match_all
- 匹配所有文档。默认查询
- 示例:查询所有,默认只返回10个文档
query告诉我们查询什么
match_all是我们查询的类型
match_all查询仅仅在指定的索引的所有文件进行搜索
bash
[root@es2 ~]# curl -X GET "192.168.100.20:9200/bank/_search?pretty" -H 'Content-Type:application/json' -d'
> {
> "query": { "match_all": {} }
> }
> '- from,size
- 除了query参数外,还可以传递其他参数影响查询结果,比如前面提到的sort,接下来使用的size
查询1条数据
bash
[root@es2 ~]# curl -X GET "192.1680.100.20:9200/bank/_search?pretty" -H 'Content-Type:application/json' -d'
> {
> "query": { "match_all" {} },
> "size": 1
> }
> '指定位置与查询条数
from 0表示从第1个开始
size 指定查询的个数
bash
[root@es2 ~]# curl -X GET "192.168.100.20:9200/bank/_search?pretty" -H 'Content-Type:application/json' -d'
> {
> "query": { "match_all": {} },
> "from": 0,
> "size": 2
> }
> '- match
- 基本搜索查询,针对特定字段或字段集合进行搜索
查询编号为20的账户
bash
[root@es2 ~]# curl -X GET "192.168.100.20:9200/bank/_search?pretty" -H 'Content-Type:application/json' -d'
> {
> "query": { "match": { "account_number": 20 } }
> }
> '返回地址中包含mill的账户
bash
[root@es2 ~]# curl -X GET "192.168.100.20:9200/bank/_search?pretty" -H 'Content-Type:application/json' -d'
> {
> "query": { "match" { "address": "mill" } }
> }
> '返回地址有包含mill或lane的所有账户
bash
[root@es2 ~]# curl -X GET "192.168.100.20:9200/bank/_search?pretty" -H 'Content-Type:application/json' -d'
> {
> "query": { "match": { "address": "mill lane" } } # 空格就是或的关系
> }
> '- bool
bool must 查询的字段必须同时存在
查询包含mill和lane的所有账户
bash
[root@es2 ~]# curl -X GET "192.168.100.20:9200/bank/_search?pretty" -H 'Content-Type:application/json' -d'
> {
> "query": {
> "bool": {
> "must": [
> { "match": { "address": "mill" } },
> { "match": { "address": "lane" } }
> ]
> }
> }
> }
> 'bool should 查询的字段仅存在一即可
查询包含mill或lane的所有账户
bash
[root@es2 ~]# curl -X GET "192.168.100.20:9200/bank/_search?pretty" -H 'Content-Type:application/json' -d'
> {
> "query": {
> "bool": {
> "should": [
> { "match": { "address": "mill" } },
> { "match": { "address": "lane" } }
> ]
> }
> }
> }
> '- range
- 指定区间内的数字或者时间
- 操作符:gt大于,gte大于等于,lt小于,lte小于等于
查询余额大于或等于20000且小于等于30000的账户
bash
[root@es2 ~]# curl -X GET "192.168.100.20:9200/bank/_search?pretty" -H 'Content-Type:application/json' -d'
> {
> "query": {
> "bool": {
> "must": { "match_all": {} },
> "filter": {
> "range": {
> "balance": {
> "gte": 20000,
> "lte": 30000
> }
> }
> }
> }
> }
> }
> '九、 Elasticsearch-head
elasticsearch-head是集群管理、数据可视化、增删改查、查询语句可视化工具。从ES5版本后安装方式和ES2以上的版本有很大的不同,在ES2中可以直接在bin目录下执行plugin install xxxx 来进行安装,但是在ES5中这种安装方式变了,要想在ES5中安装Elasticsearch Head必须要安装NodeJs,然后通过NodeJS来启动Head。
官网地址:
https://github.com/mobz/elasticsearch-head
配置elasticsearch-head
安装nodejs
bash
[root@es2 ~]# rz -E
rz waiting to receive.
[root@es2 ~]# tar -xf node-v10.24.1-linux-x64.tar.xz -C /usr/local/
[root@es2 ~]# cd /usr/local/
[root@es2 local]# mv node-v10.24.1-linux-x64/ nodejs
[root@es2 local]# cd /usr/local/nodejs/
[root@es2 nodejs]# cd bin/
[root@es2 bin]# ln -s /usr/local/nodejs/bin/npm /bin/npm
[root@es2 bin]# ln -s /usr/local/nodejs/bin/node /bin/node安装git
bash
[root@es2 yum.repos.d]# yum -y install git安装es-head(安装时间较久)
bash
[root@es2 ~]# git clone https://github.com/mobz/elasticsearch-head.git
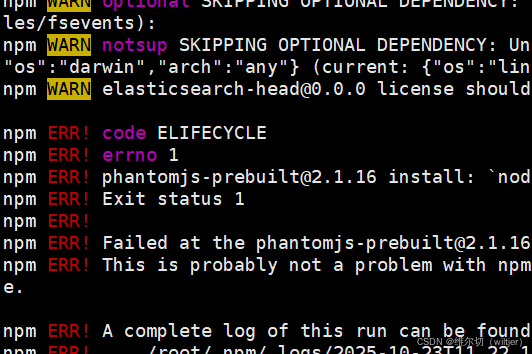
[root@es2 elasticsearch-head]# npm install -g grunt-cli安装可能有很多错误,我这里出现了下面的错误(重点是注意红色的ERR!,黄色的WARN不用管)
解决方法
bash
[root@es2 elasticsearch-head]# npm install phantomjs-prebuilt@2.1.16 --ignore-script
[root@es2 elasticsearch-head]# nohup npm run start &访问浏览器
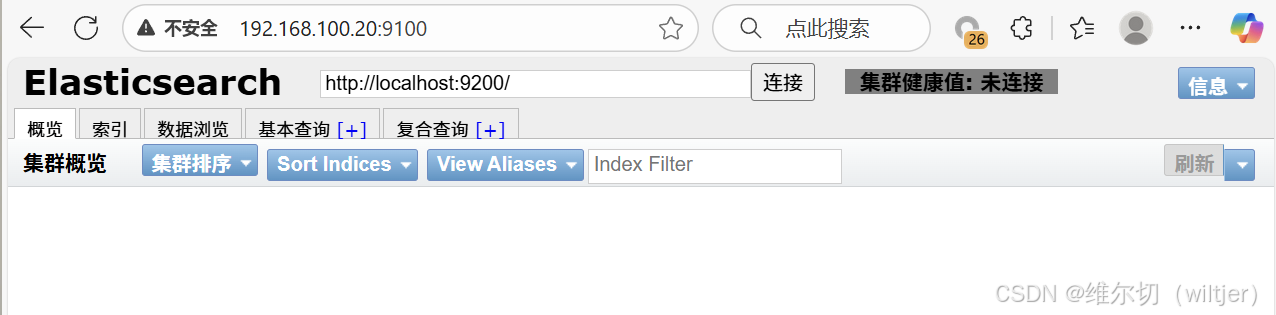
浏览器访问 http://es-head节点IP:9100 ,并在下面的地址里把localhost改为es-head节点IP(浏览器与es-head不是同一节点就要做)
修改ES集群配置文件,并重启服务
es1
bash
[root@es1 ~]# vim /etc/elasticsearch/elasticsearch.yml
[root@es1 ~]# systemctl restart elasticsearch.service
yaml
cluster.name: elk-cluster
node.name: 192.168.100.10
node.master: false
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
http.port: 9200
discovery.zen.ping.unicast.hosts: ["192.168.100.10", "192.168.100.20"]
http.cors.enabled: true
http.cors.allow-origin: "*" # 最后加上这两句es2
bash
[root@es2 ~]# vim /etc/elasticsearch/elasticsearch.yml
[root@es2 ~]# systemctl restart elasticsearch.service
yaml
cluster.name: elk-cluster
node.name: 192.168.100.20
node.master: true
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
http.port: 9200
discovery.zen.ping.unicast.hosts: ["192.168.100.10", "192.168.100.20"]
http.cors.enabled: true
http.cors.allow-origin: "*"再次连接就可以看到信息了
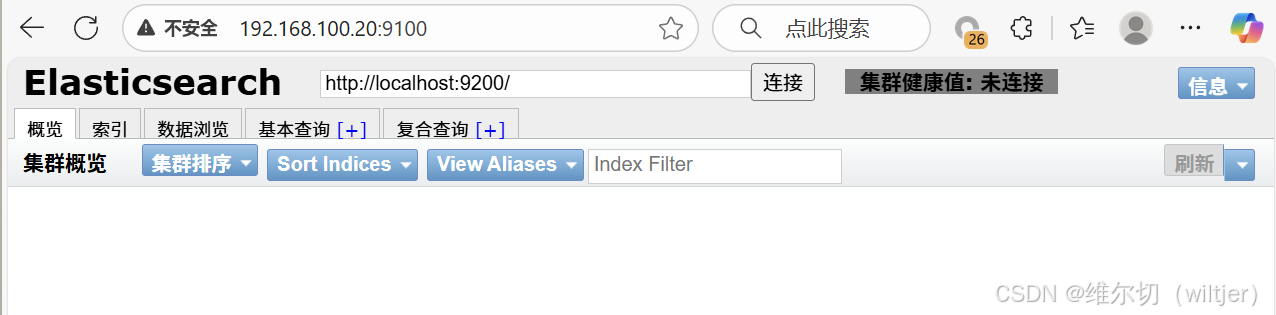
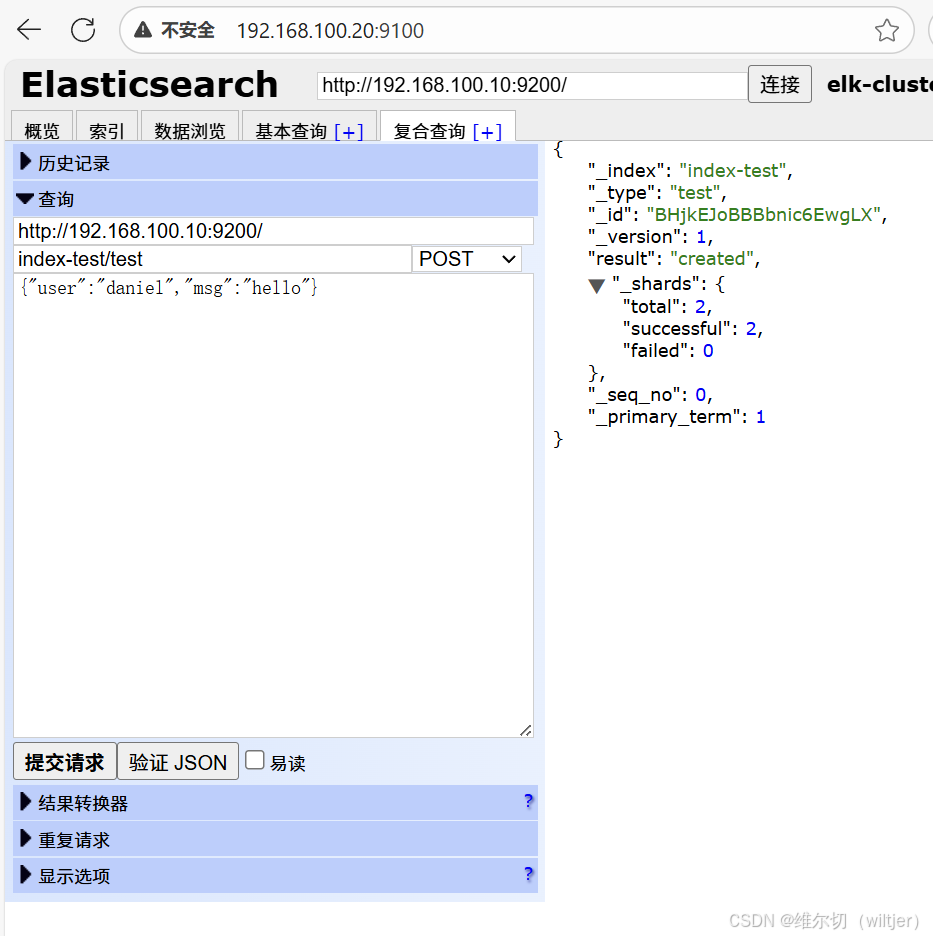
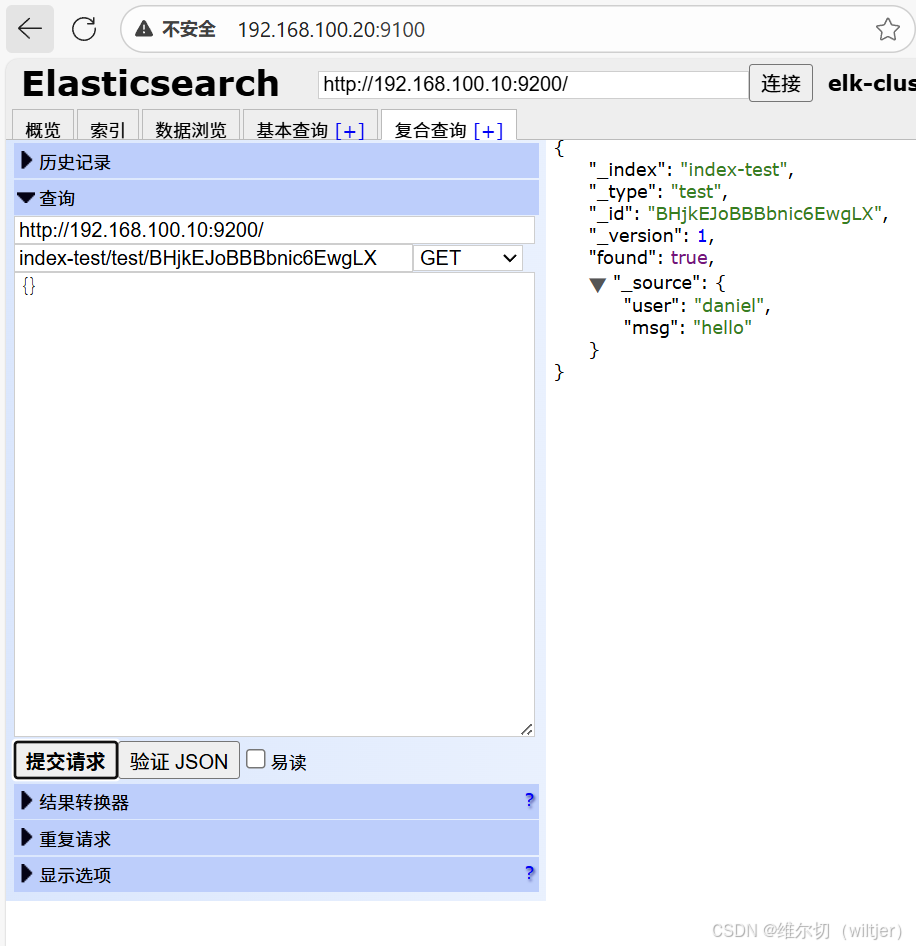
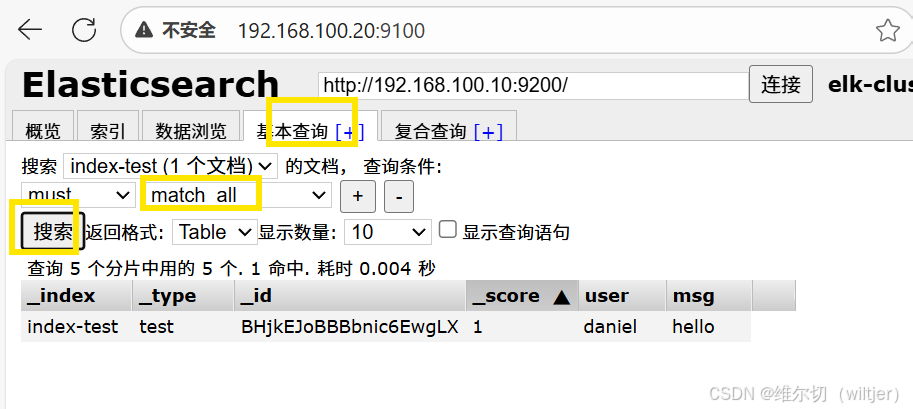
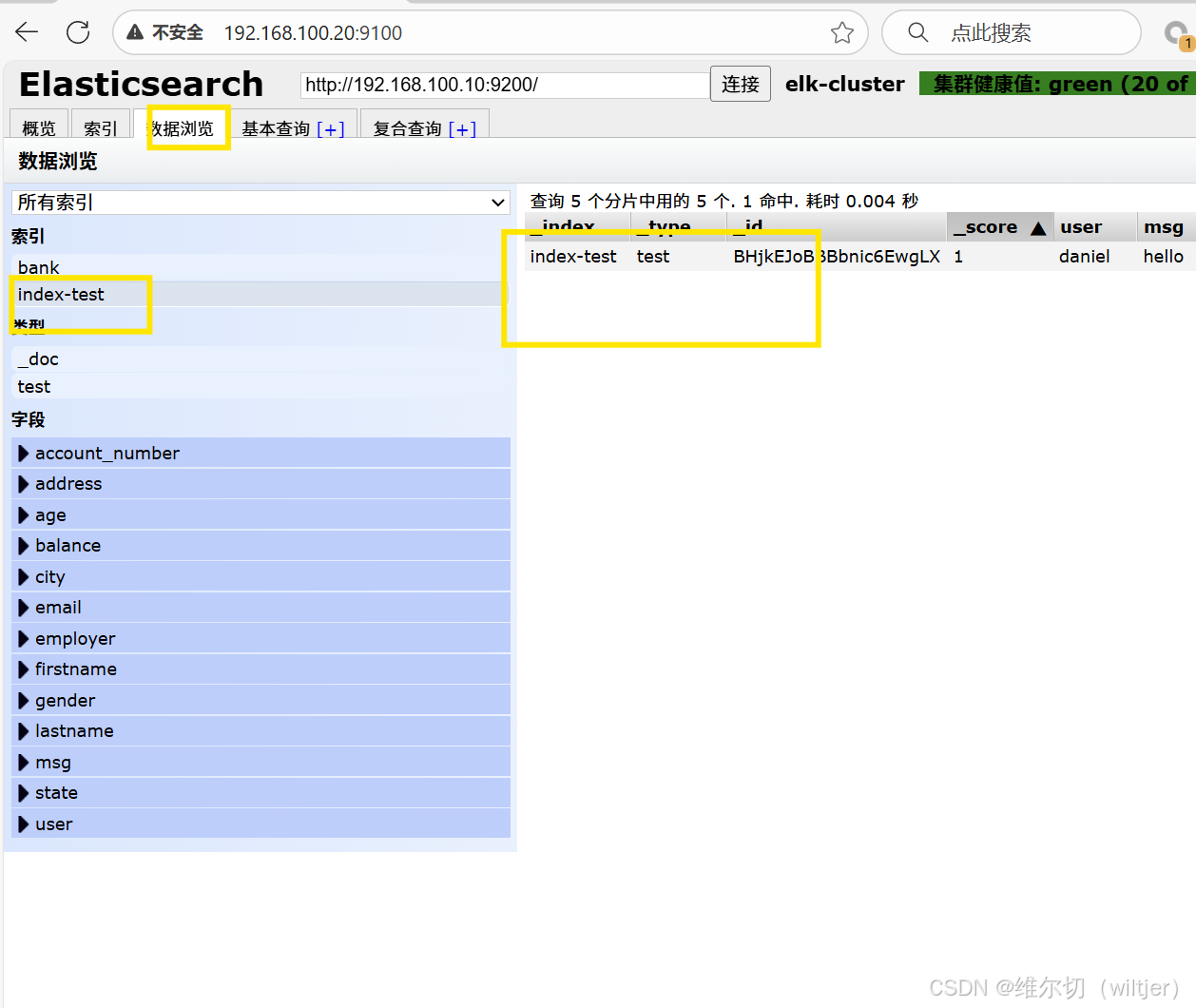
新建索引
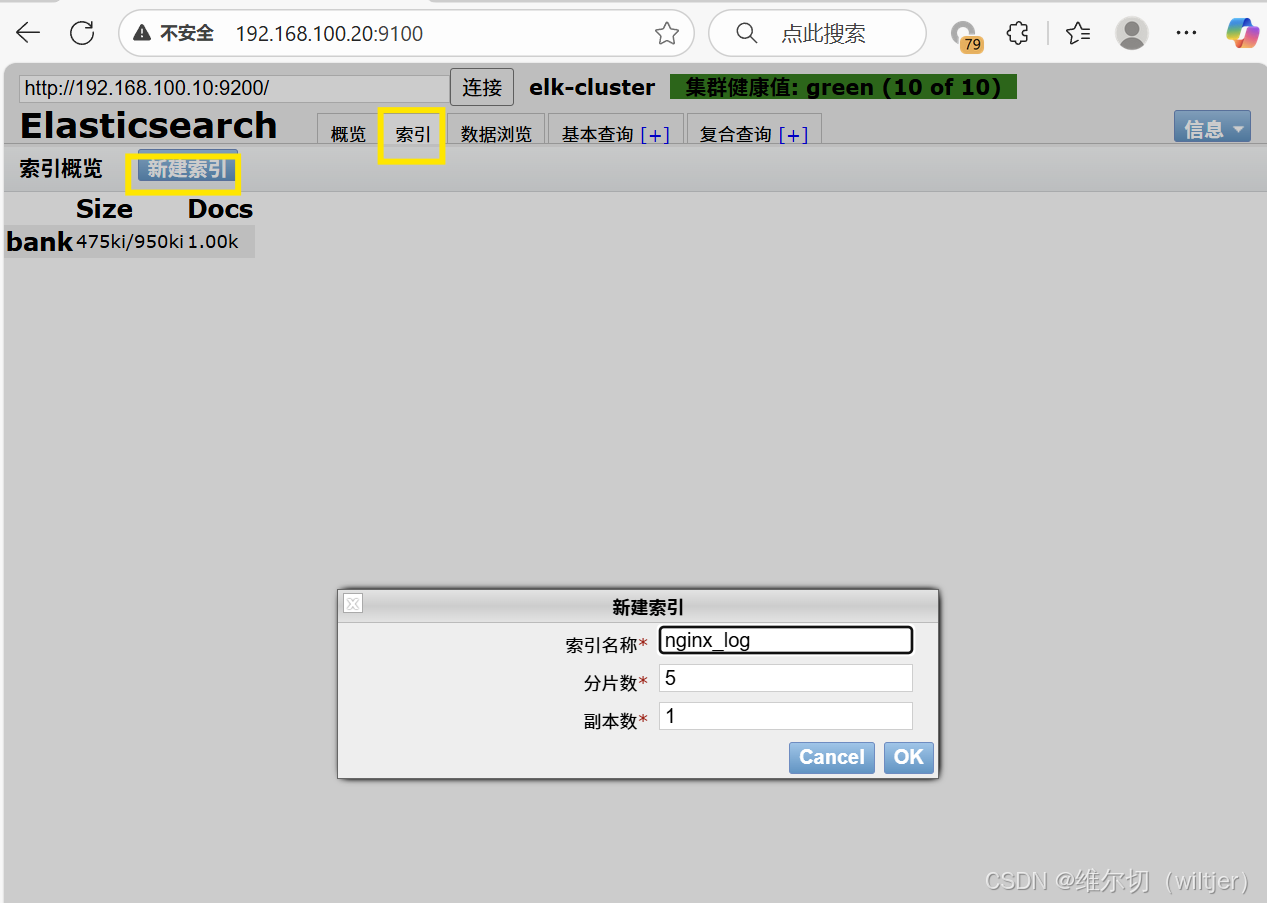
删除索引
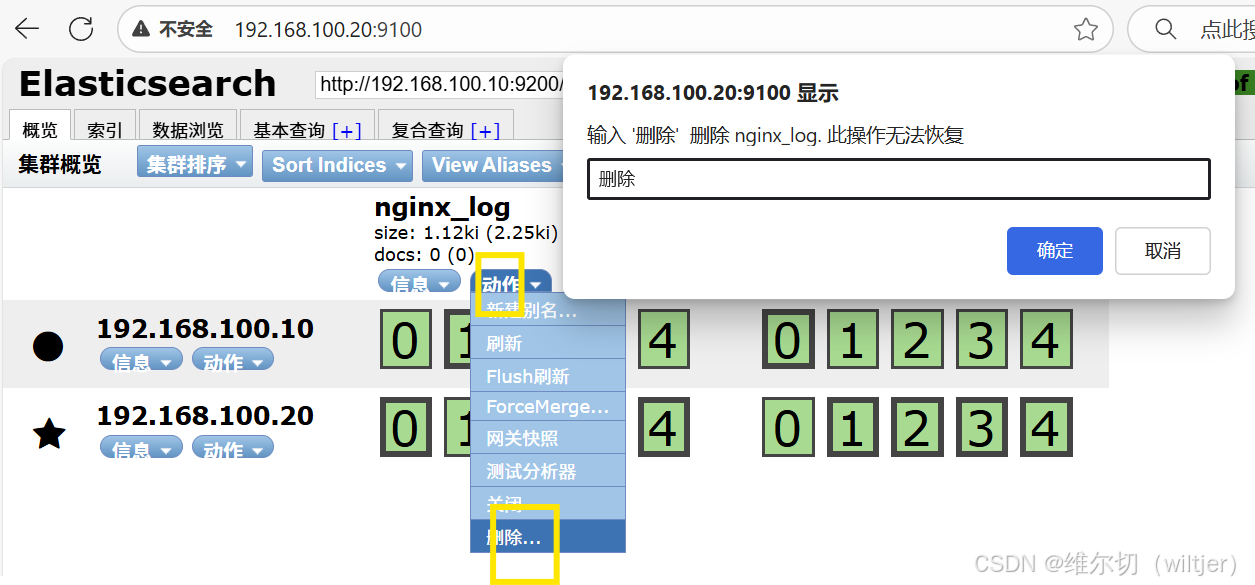
es-head查询验证
十、logstash
logstash是一个开源的数据采集工具,通过数据源采集数据.然后进行过滤,并自定义格式输出到目的地。
数据分为:
- 结构化数据 如:mysql数据库里的表等
- 半结构化数据 如: xml,yaml,json等
- 非结构化数据 如:文档,图片,音频,视频等
logstash可以采集任何格式的数据,当然我们这里主要是讨论采集系统日志,服务日志等日志类型数据。
官方产品介绍
input插件: 用于导入日志源 (配置必须)
filter插件: 用于过滤(不是配置必须的)
output插件: 用于导出(配置必须)
logstash 部署
环境准备
- 关闭防火墙和selinux
- 时钟同步
- 确认 jdk 版本(图形化下载自带版本即可)
安装 logstash
下载:wget https://artifacts.elastic.co/downloads/logstash/logstash-6.5.2.rpm
bash
[root@logstash ~]# rpm -ivh logstash-6.5.2.rpm修改logstash主配置文件
bash
[root@logstash ~]# vim /etc/logstash/logstash.yml
yaml
path.data: /var/lib/logstash
path.config: /etc/logstash/conf.d
http.host: "192.168.100.30"
path.logs: /var/log/logstash启动测试
bash
[root@logstash ~]# cd /usr/share/logstash/
[root@logstash logstash]# cd bin
# 使用下面的空输入和空输出启动测试一下
[root@logstash bin]# ./logstash -e 'input {stdin {}} output {stdout {}}'
# 运行后,输入字符将被stdout做为标准输出内容输出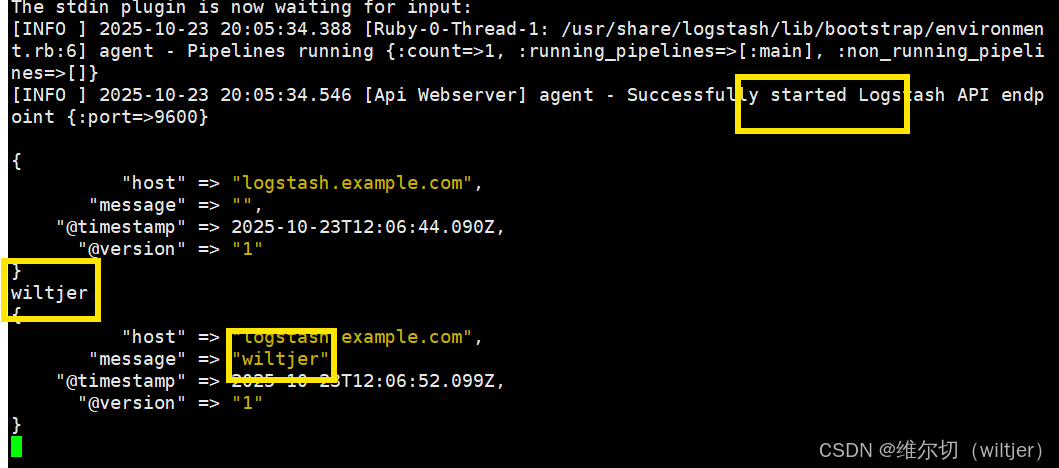
另一种验证方法
--path.settings 指定logstash主配置文件目录
-f 指定片段配置文件
-t 测试配置文件是否正确
codec => rubydebug这句可写可不定,默认就是这种输出方式
bash
[root@logstash ~]# vim /etc/logstash/conf.d/test.conf
[root@logstash ~]# cd /usr/share/logstash/bin/
[root@logstash bin]# ./logstash --path.settings /etc/logstash -f /etc/logstash/conf.d/test.conf -t
ini
input {
stdin {
}
}
filter {
}
output {
stdout {
codec => rubydebug
}
}-r参数很强大,会动态装载配置文件,也就是说启动后,可以不用重启修改配置文件
bash
[root@logstash bin]# ./logstash --path.settings /etc/logstash -r -f /etc/logstash/conf.d/test.conf图略
日志采集
采集messages日志
以/var/log/messages为例,只定义input输入和output输出,不考虑过滤
bash
[root@logstash bin]# vim /etc/logstash/conf.d/test.conf
[root@logstash bin]# ./logstash --path.settings /etc/logstash -r -f /etc/logstash/conf.d/test.conf &
# 后台运行如果要杀掉,请使用pkill java或ps查看PID再kill -9清除
ini
input {
file {
path => "/var/log/messages"
start_position => "beginning"
}
}
output {
elasticsearch {
hosts => ["192.168.100.20"]
index => "test-%{+YYYY.MM.dd}"
}
}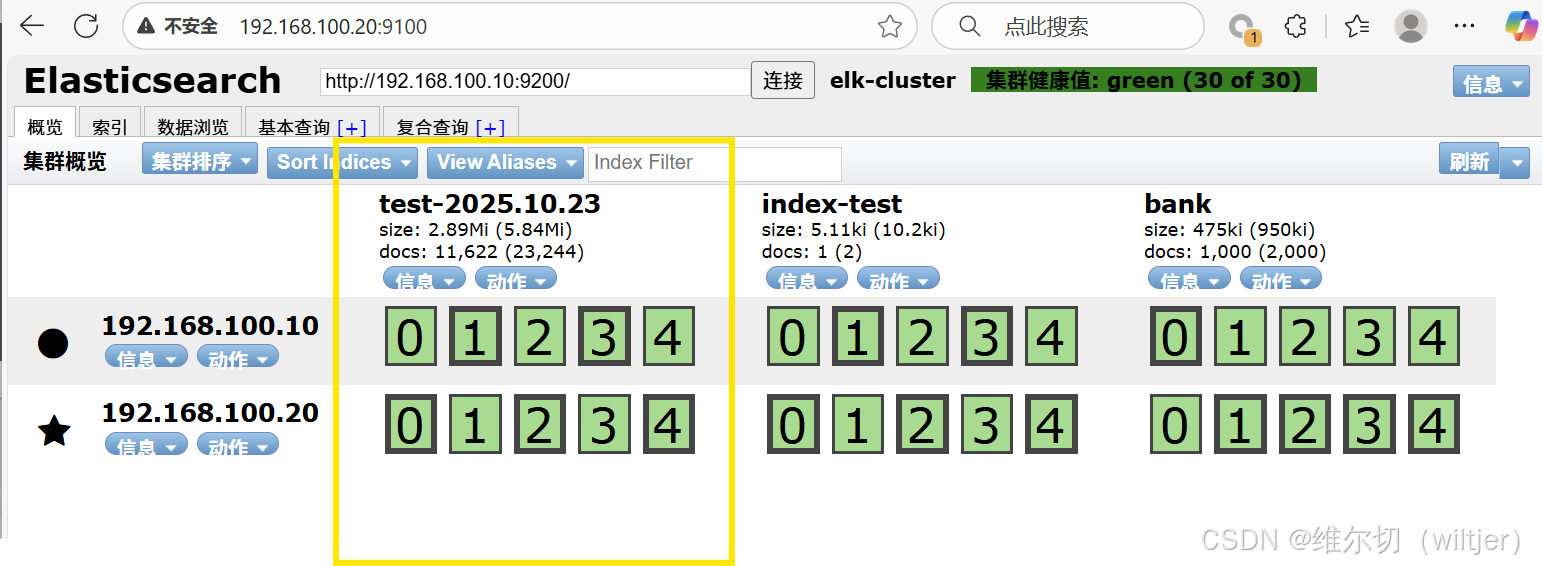
message字段的信息就是logstash上传的/var/log/messages里的日志信息
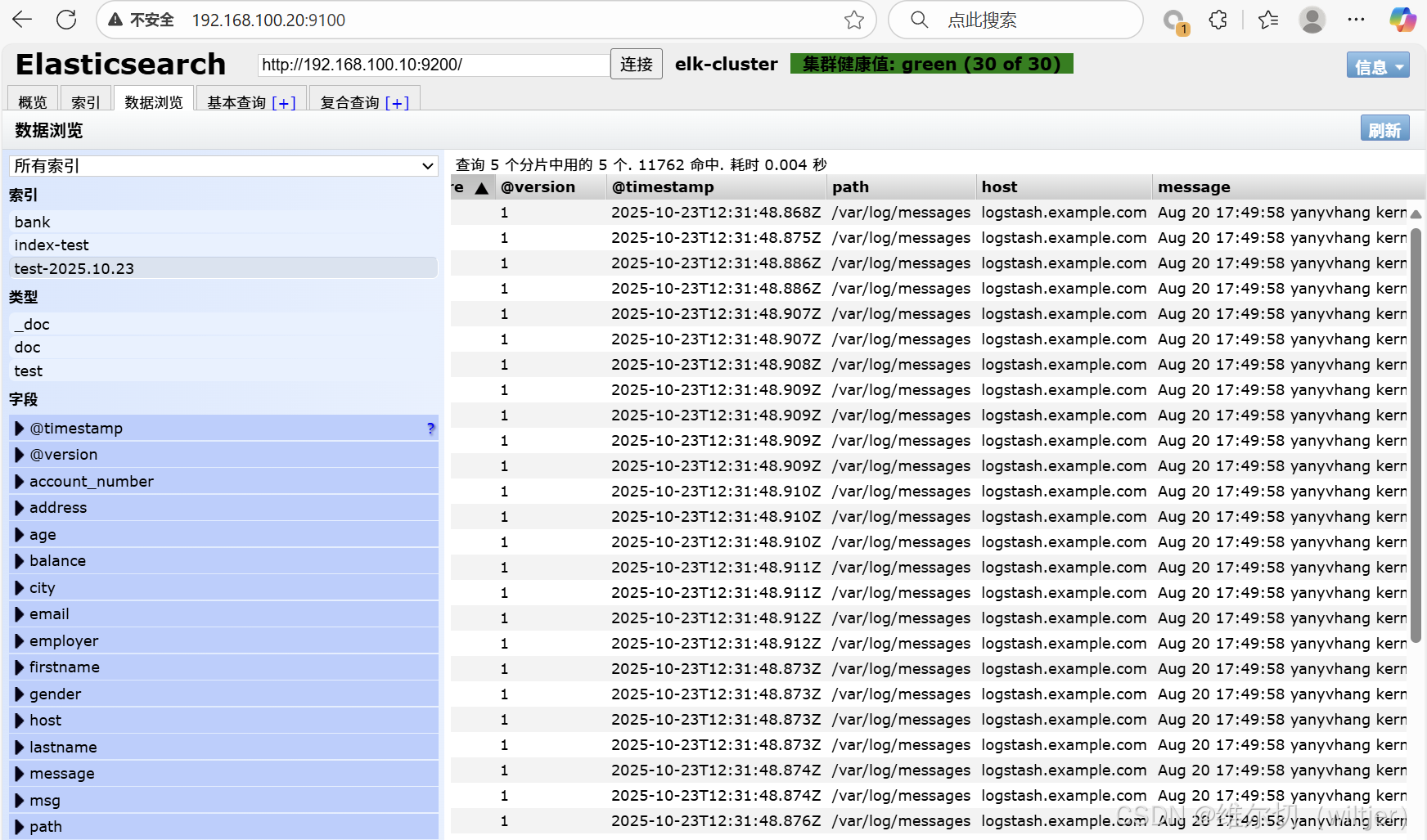
在logstash那台服务器上做一些操作(比如,重启下sshd服务), 让/var/log/message有新的日志信息,然后验证es-head里的数据
结果: 会自动更新, 浏览器刷新就能在es-head上看到更新的数据
2, kill掉logstash进程(相当于关闭), 也做一些操作让/var/log/message日志有更新,然后再次启动logstash
结果: 会自动连上es集群, es-head里也能查看到数据的更新
采集多日志源
bash
ini
input {
file {
path => "/var/log/messages"
start_position => "beginning"
type => "messages"
}
file {
path => "/var/log/yum.log"
start_position => "beginning"
type => "yum"
}
}
filter {
}
output {
if [type] == "messages" {
elasticsearch {
hosts => ["192.168.100.10:9200","192.168.100.20:9200"]
index => "messages-%{+YYYY-MM-dd}"
}
}
if [type] == "yum" {
elasticsearch {
hosts => ["192.168.100.10:9200","192.168.100.20:9200"]
index => "yum-%{+YYYY-MM-dd}"
}
}
}此时只有messages的数据没有yum的
yum安装一个服务
bash
[root@logstash yum.repos.d]# yum -y install httpd
[root@logstash yum.repos.d]# cat /var/log/yum.log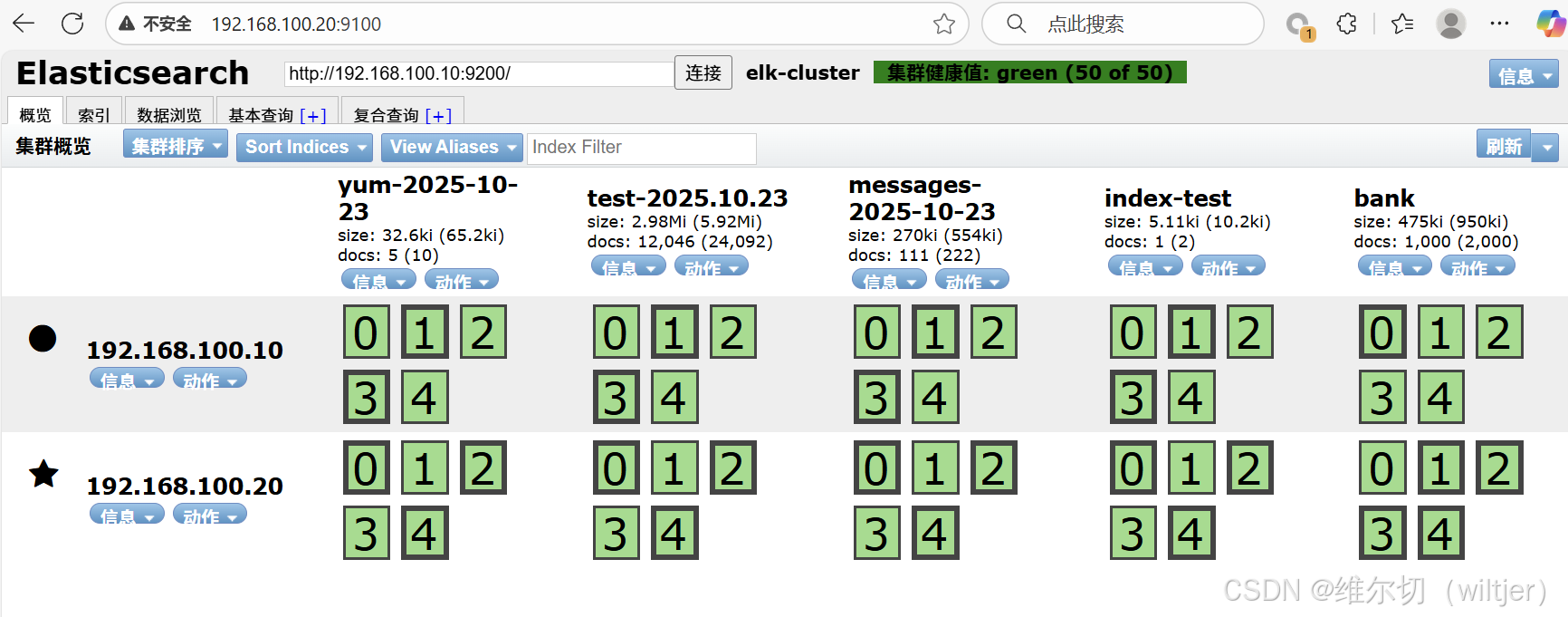
十一、Kibana
Kibana是一个开源的可视化平台,可以为ElasticSearch集群的管理提供友好的Web界面,帮助汇总,分析和搜索重要的日志数据
文档路径: https://www.elastic.co/guide/en/kibana/current/setup.html
Kibana 部署
安装 Kibana
bash
[root@es1 ~]# wget https://artifacts.elastic.co/downloads/kibana/kibana-6.5.2-x86_64.rpm
[root@es1 ~]# rpm -ivh kibana-6.5.2-x86_64.rpm配置 Kibana
bash
[root@es1 ~]# vim /etc/kibana/kibana.yml
# 日志要自己建立,并修改owner和group属性
[root@es1 ~]# touch /var/log/kibana.log
[root@es1 ~]# chown kibana.kibana /var/log/kibana.log
yaml
server.port: 5601 # 端口
server.host: "0.0.0.0" # 监听所有,允许所有人能访问
elasticsearch.url: "http://192.168.100.20:9200" # ES 集群的路径
logging.dest: /var/log/kibana.log # 这里加了 kibana 日志,方便排错与调试启动 Kibana 服务
bash
[root@es1 ~]# systemctl restart kibana.service
[root@es1 ~]# systemctl enable kibana.service
[root@es1 ~]# lsof -i:5601
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
node 8382 kibana 11u IPv4 59122 0t0 TCP *:esmagent (LISTEN)浏览器访问
汉化
bash
[root@es1 ~]# wget https://github.com/anbai-inc/Kibana_Hanization/archive/master.zip
[root@es1 ~]# unzip Kibana_Hanization-master.zip -d /usr/local
[root@es1 ~]# cd /usr/local/Kibana_Hanization-master/
[root@es1 Kibana_Hanization-master]# python main.py /usr/share/kibana/
[root@es1 Kibana_Hanization-master]# systemctl restart kibana.service
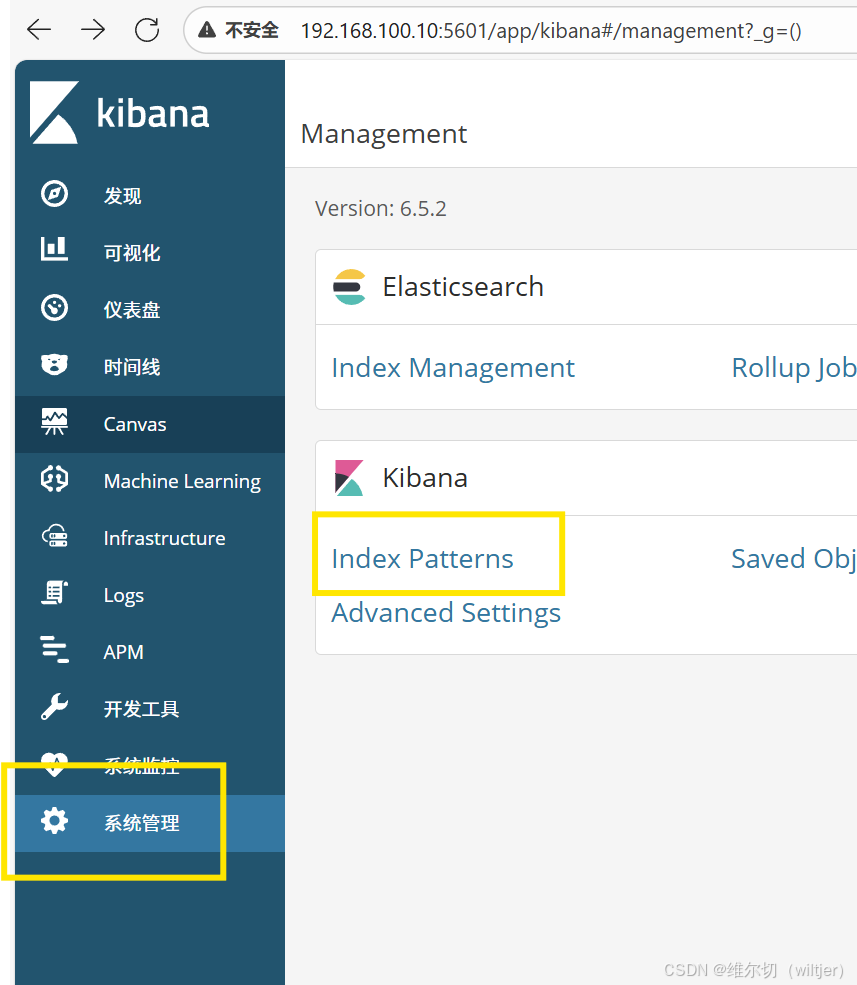
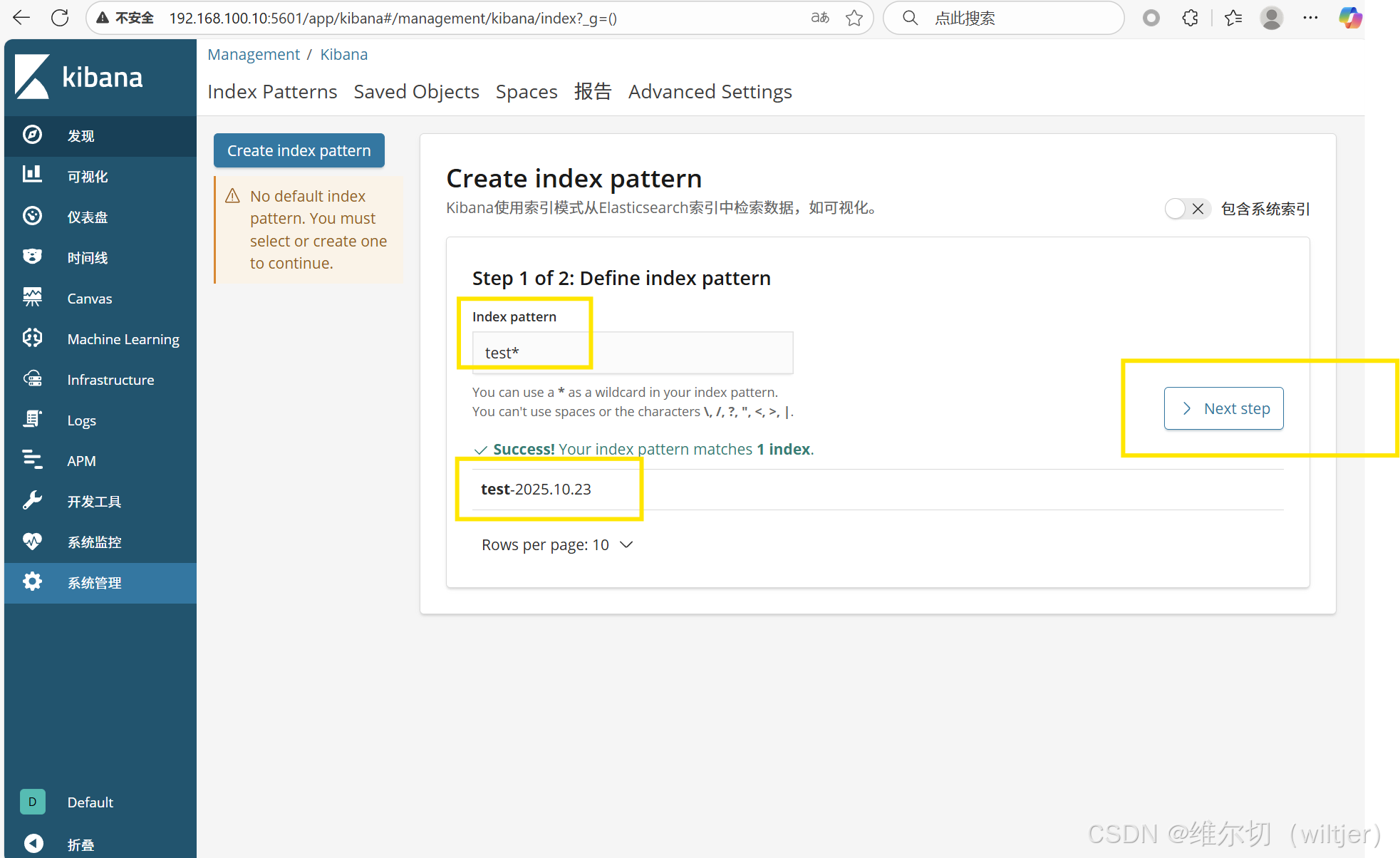
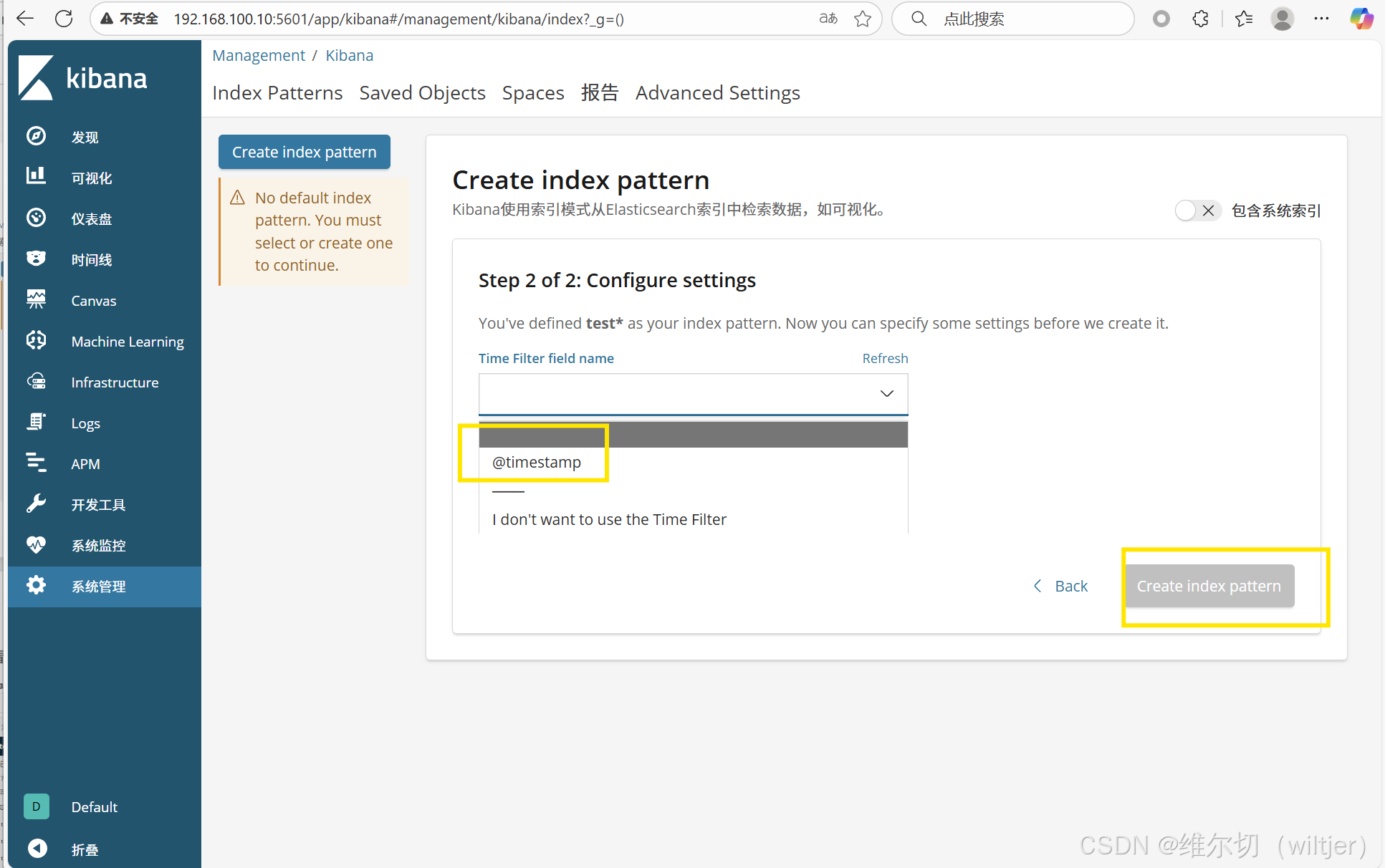
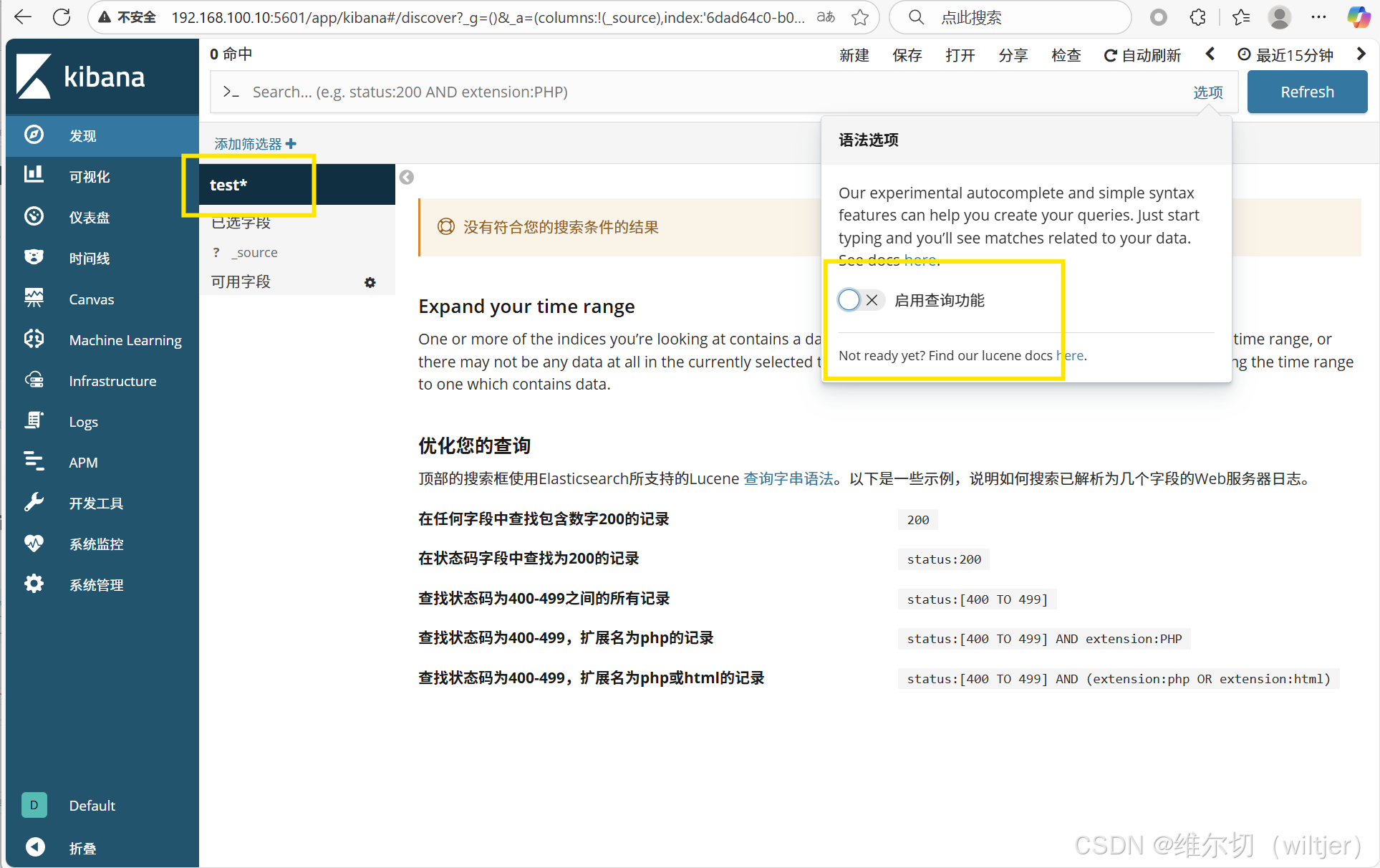
通过kibana查看集群信息
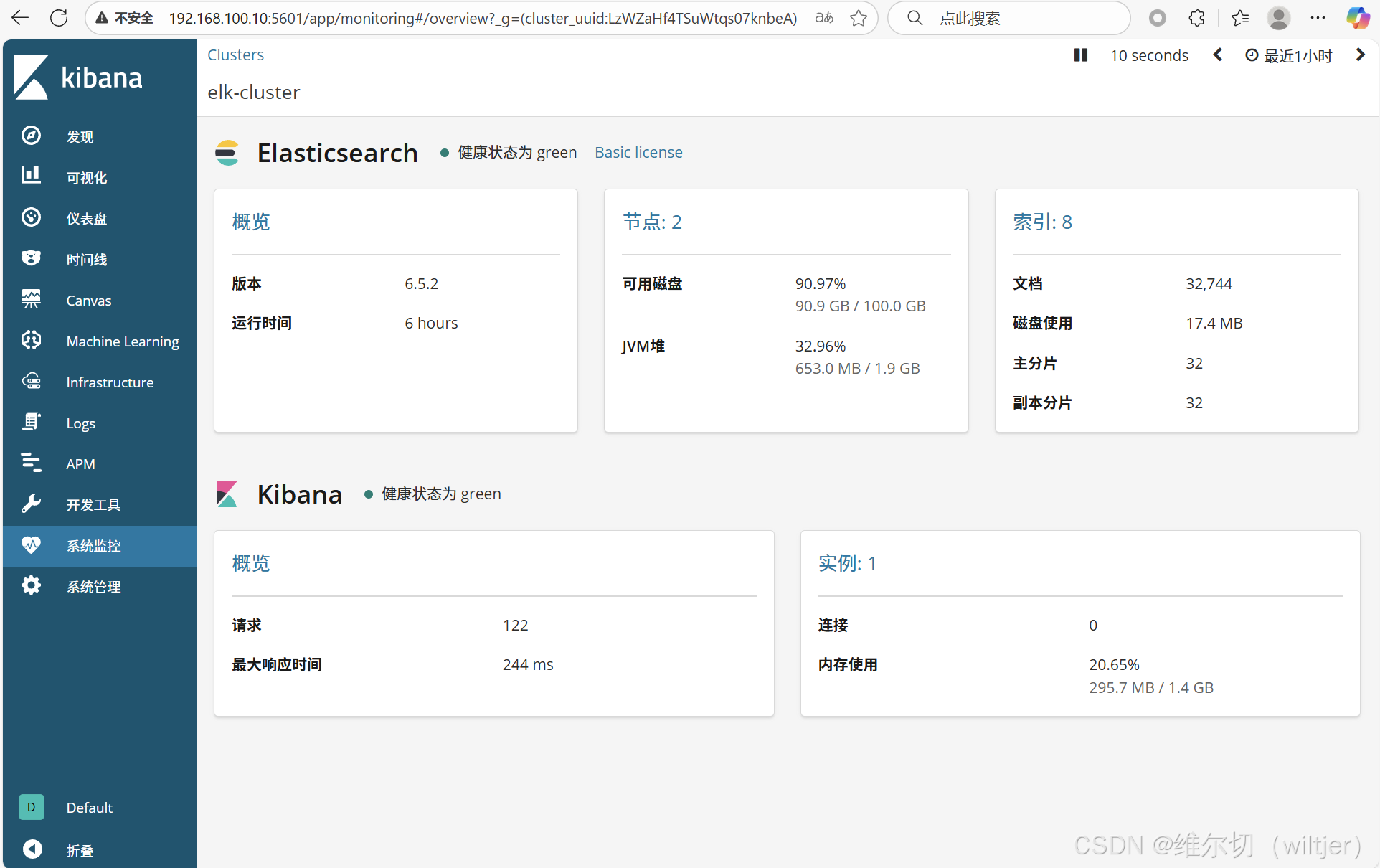
通过 kibana 查看 logstash 收集的日志索引