文章结尾部分有CSDN官方提供的学长 联系方式名片
博主开发经验15年,全栈工程师,专业搞定大模型、知识图谱、算法和可视化项目和比赛
编号:F043 白色版本
1 讲解视频
vue+flask天气预测可视化系统大数据+机器学习+管理端+爬虫+超酷界面+顶级可视化水平
✅ 顶级可视化水平: 看了视频就懂
✅ scikit-learn 回归预测算法预测天气
✅ 全国天气图(可视化细化到市级)
✅ 数据利用超级爬虫更新
✅ 随意选择城市可视化分析、分析风力、高低气温等
✅ 增加漂亮管理端增删改查
✅ vue+flask前后端分离架构2个前端1个后端1个爬虫
2 架构说明
Vue + Flask 前后端分离架构:2个前端 + 1个后端 + 1个爬虫
系统采用当前主流的前后端分离架构 ,确保各模块独立、扩展性强、协作高效:
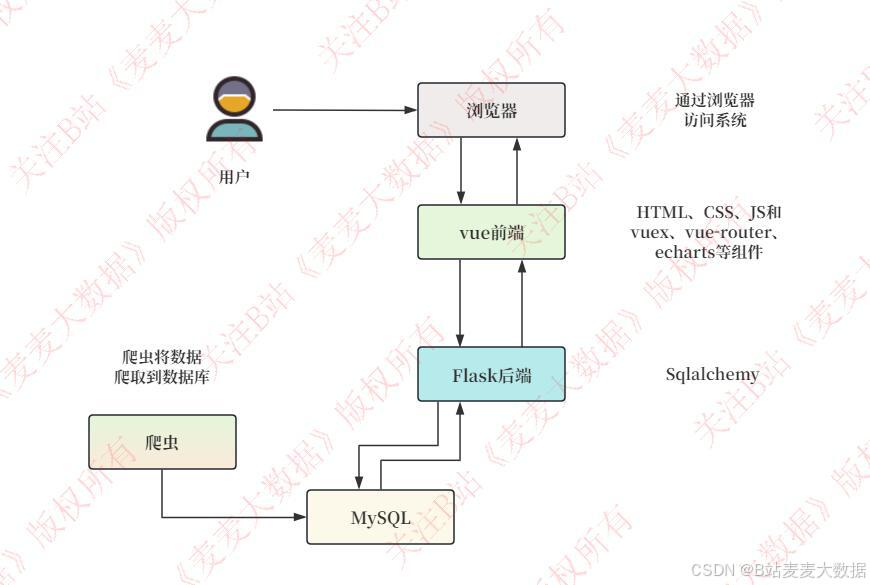
前端部分(Vue.js 构建):
- 用户前端:面向普通用户,提供天气可视化、气温预测可视化、城市选择、地图分为、温度分析、风力分析图表展示等功能,使用 Vue + ECharts 等。
- 管理前端:面向管理员,提供天气数据管理、预报数据、用户管理等后台功能,使用 Vue + ElementUI。
后端部分(Flask 框架):
- 负责处理业务逻辑、接口请求、数据库操作、模型预测等
- 与前后端通过 RESTful API 进行通信,支持 JSON 数据格式交互
- 提供安全认证、权限控制、数据缓存、异常处理等服务
- 集成天气预测模型,支持模型训练、预测结果返回与实时更新
3 功能说明
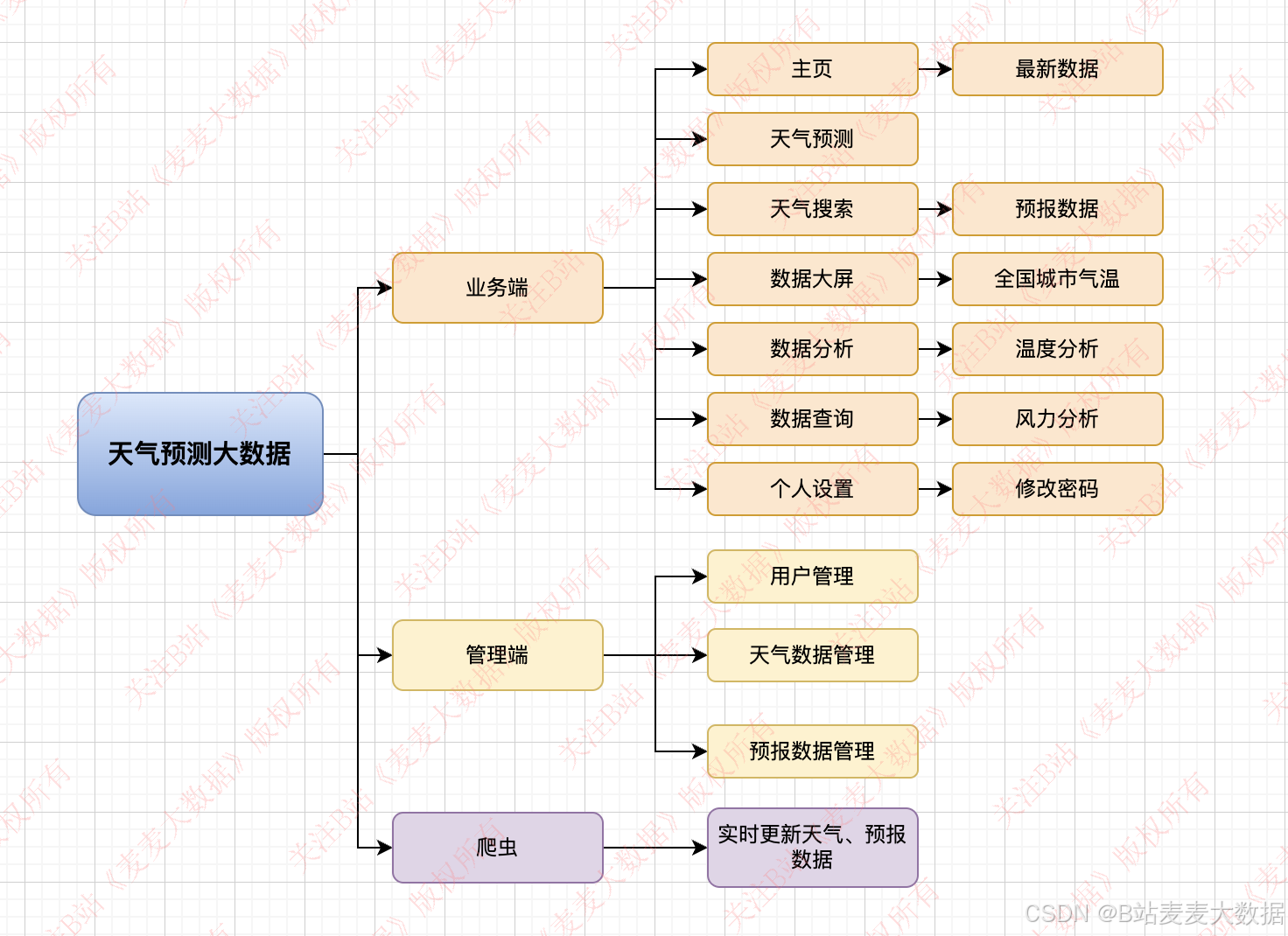
系统简介:本系统是一个基于Vue+Flask构建的天气预测可视化系统,其核心功能围绕天气数据的展示、预测和用户管理展开。主要包括:首页,用于展示系统概览和天气预报视频;数据可视化模块,提供全国天气图(可视化细化到市级),并支持随意选择城市进行详细分析,如风力、 高低气温等天气要素;可视化分析模块,通过顶级可视化技术展示天气变化趋势,为用户提供直观的数据分析;天气预测模块,利用scikit-learn回归预测算法进行智能预测,为用户提供精准的天气参考;以及管理端,提供增删改查功能,以便管理员高效管理系统数据,确保系统的安全性和个性化体验。
该系统采用典型的B/S(浏览器/服务器)架构模式。用户通过浏览器访问Vue前端界面,该前端由HTML、CSS、JavaScript以及Vue.js生态系统中的Vuex(用于状态管理)、Vue Router(用于路由导航)和Echarts(用于数据可视化)等组件构建。前端通过API请求与Flask后端进行数据交互,Flask后端则负责业务逻辑处理,并利用SQLAlchemy(或类似ORM工具)与MySQL数据库进行持久化数据存储。此外,系统还包含一个独立的超级爬虫模块,负责从外部天气数据来源抓取数据并将其导入MySQL数据库,为整个系统提供数据支撑。系统还搭建了一个漂亮的管理端,支持数据的增删改查操作,方便管理员进行数据管理。整个系统以Vue+Flask前后端分离架构为基础,包含2个前端(用户端和管理端)、1个后端以及1个爬虫模块,整体界面设计风格超酷,可视化水平顶级,是一个集大数据、机器学习、管理端和爬虫于一体的天气预测可视化系统。
3.1 爬虫部分(独立运行):
- 使用 Python 编写,基于 requests、BeautifulSoup 或 Scrapy 框架
- 定时运行,从多个数据源获取天气数据
本系统旨在打造一个高效、直观、功能全面的全国天气预测与可视化分析平台,结合前沿的数据爬取、机器学习预测和前后端分离架构,为用户提供精准的天气信息与灵活的交互体验。系统整体设计围绕"数据驱动 + 智能预测 + 可视化呈现 "三大核心展开,力求实现"较好 "的可视化效果和"方便管理天气数据"的管理体验。

3.2 可视化分析
系统采用高度交互式与直观易懂的可视化设计 ,所有关键信息均可通过图表、地图和动态演示方式呈现。用户可通过*动画或动态图表快速理解天气变化趋势、风力走向、温度分布等复杂数据。系统支持 交互式缩放、拖动、图层切换**,确保用户在不依赖专业背景知识的情况下也能轻松掌握天气动态。此外,系统界面风格清新、动画流畅,致力于打造**"视觉即理解"的用户体验**。


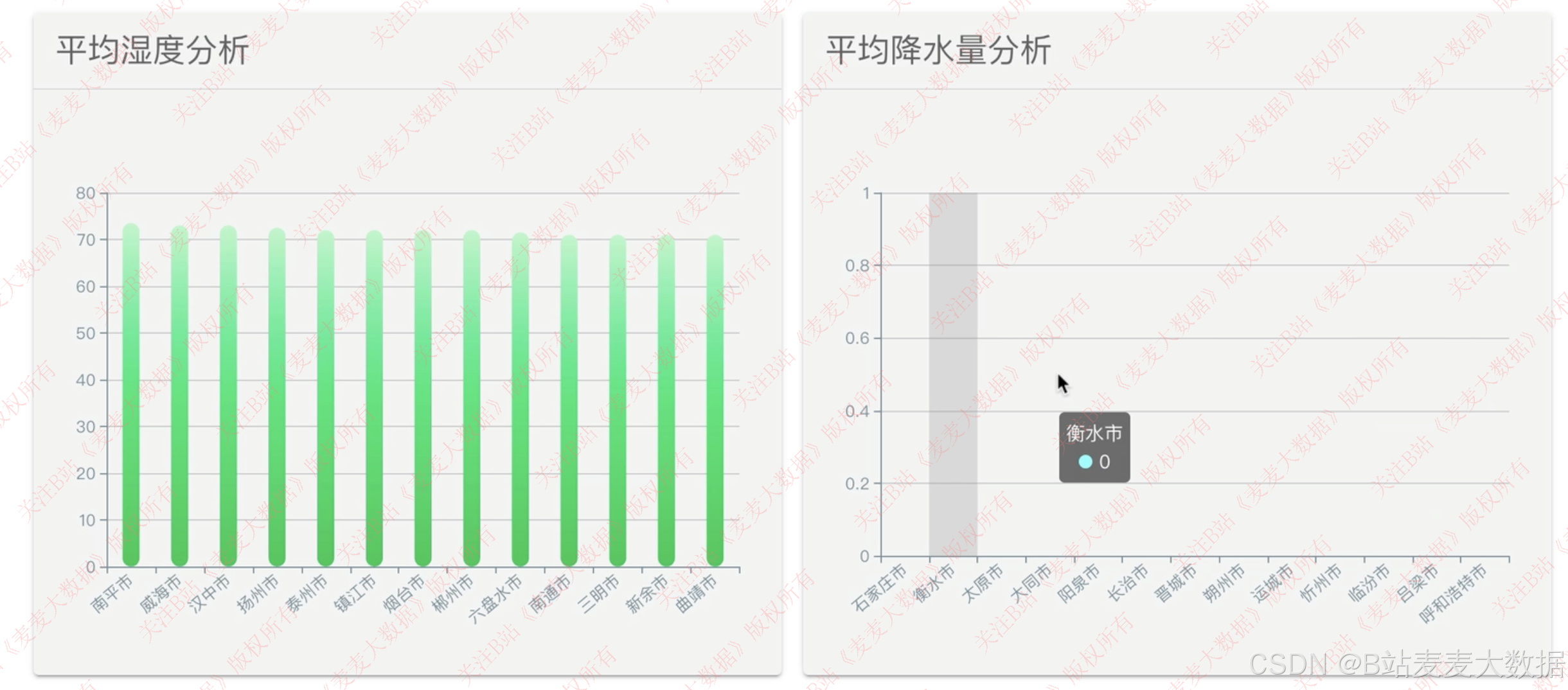

3.3 scikit-learn 回归预测算法预测天气
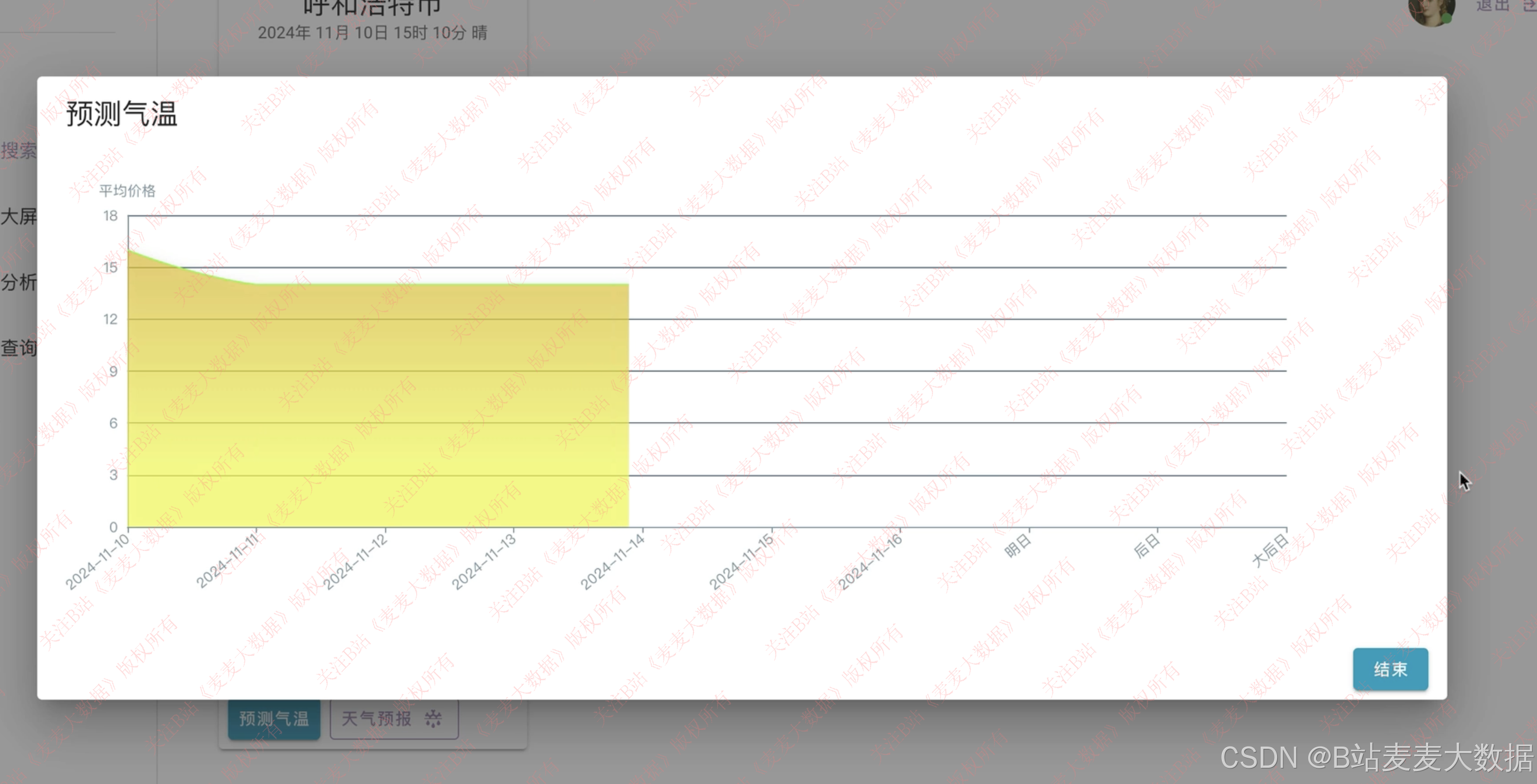
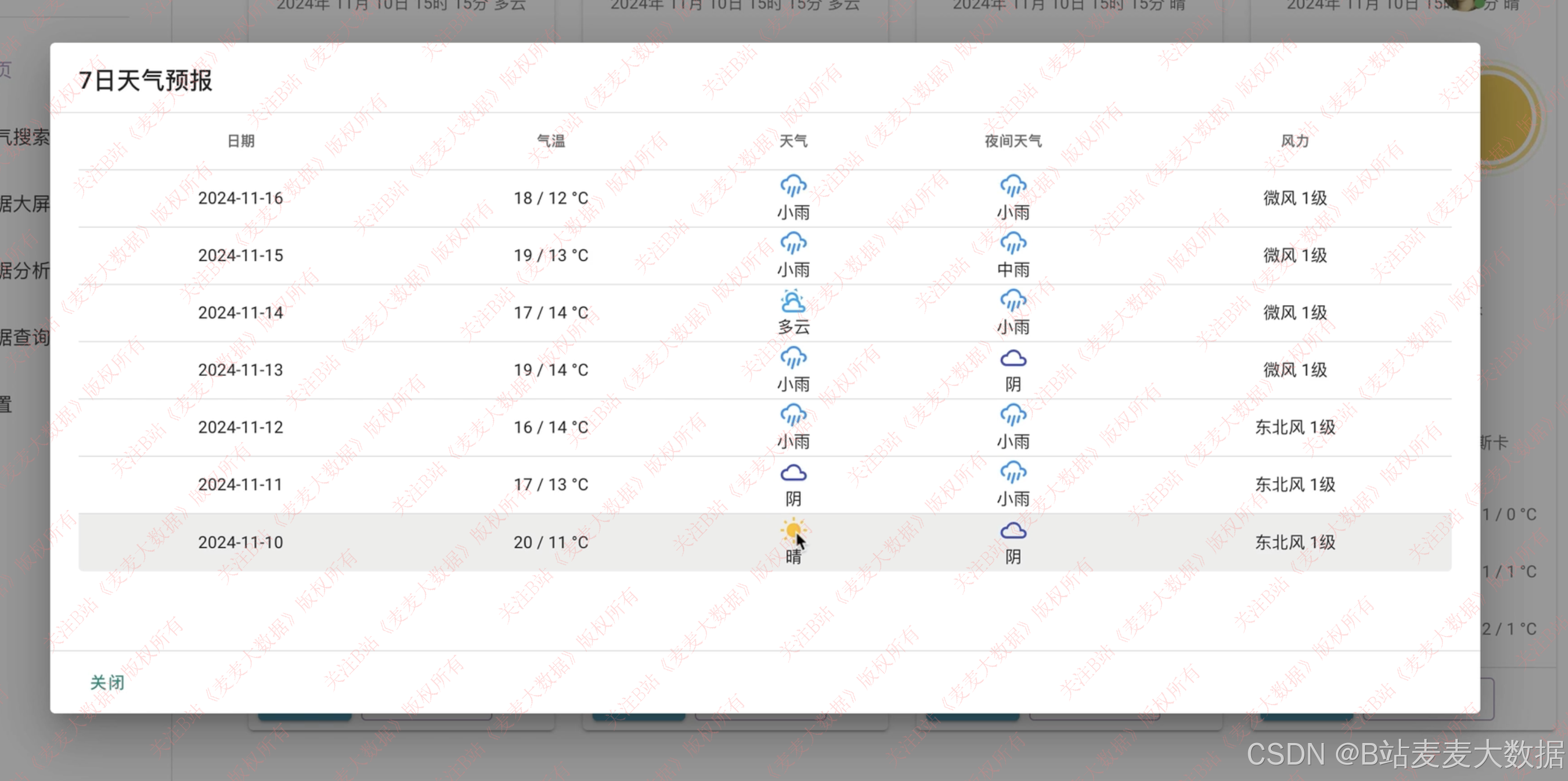
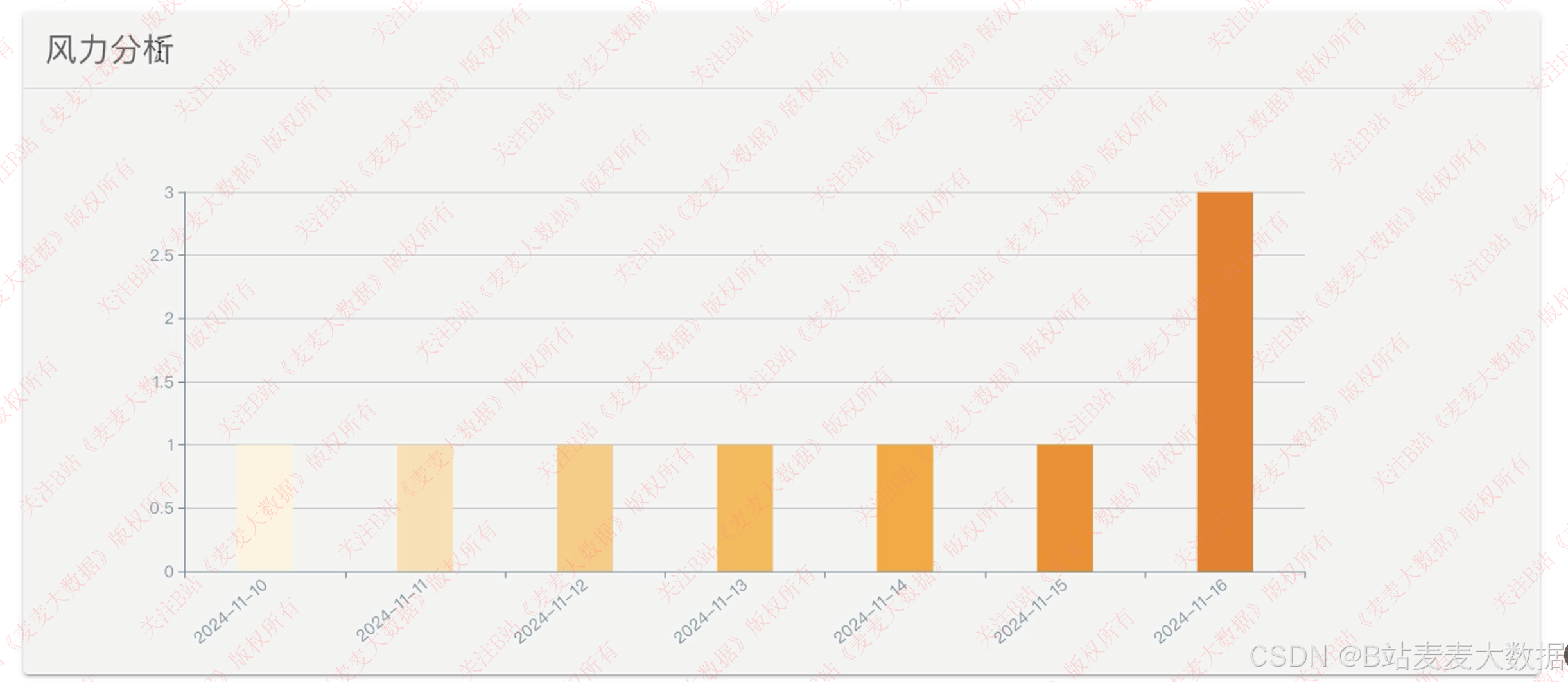
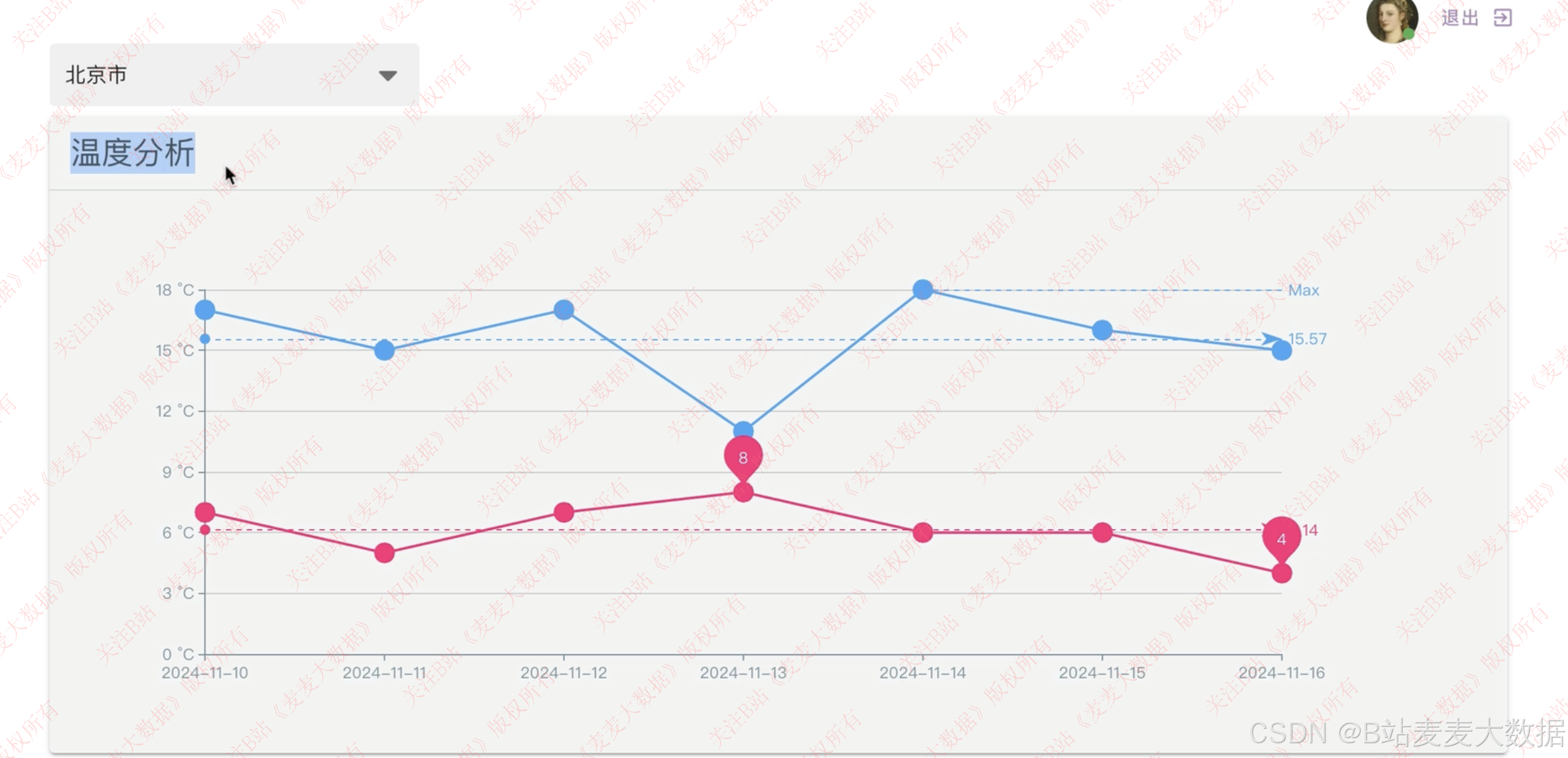
3.4 城市搜索
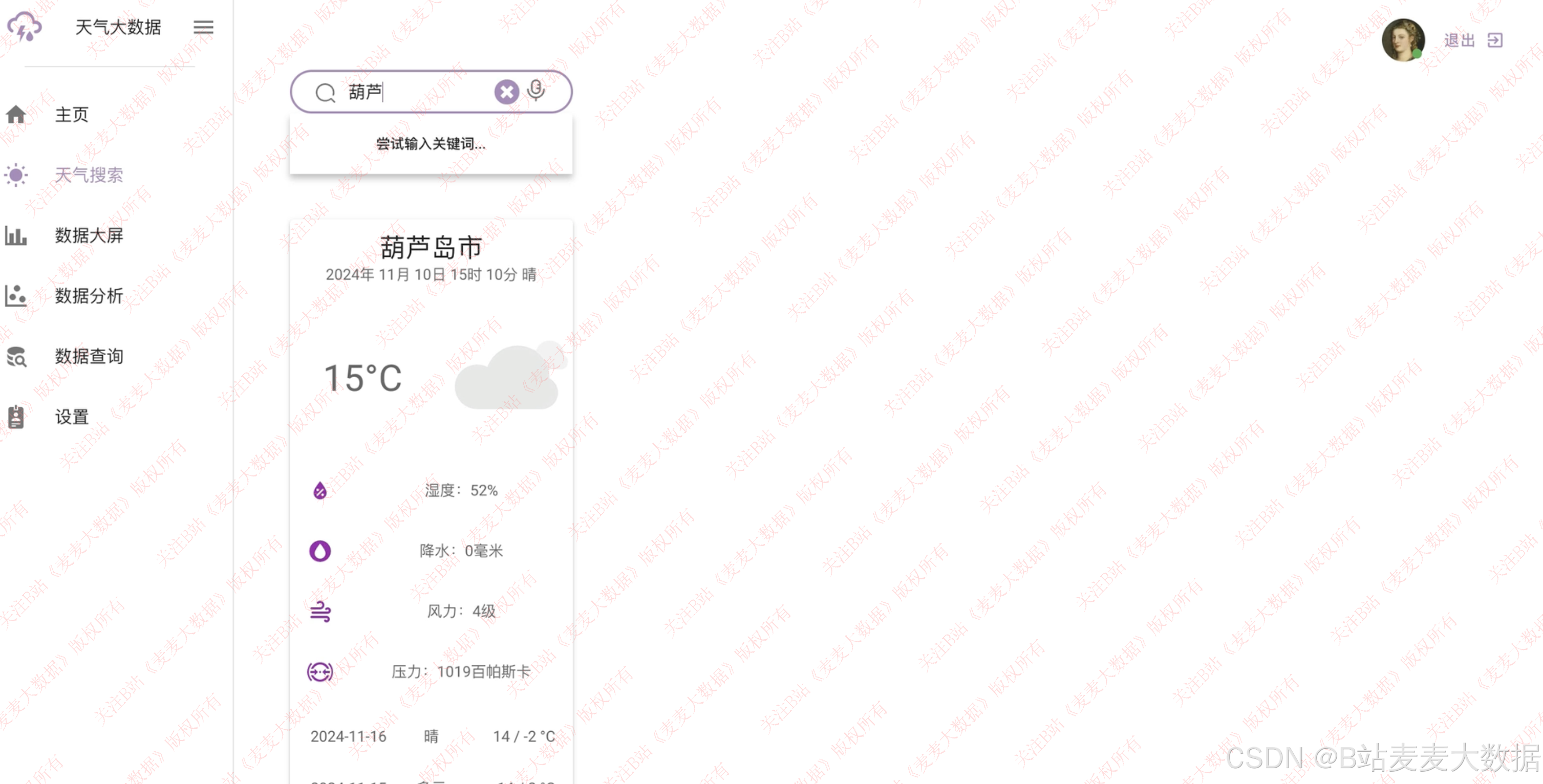
随意选择城市可视化分析、分析风力、高低气温等**
系统支持用户自由选择任意城市 ,进行个性化天气分析。通过交互式地图或城市列表搜索,用户可快速定位目标城市,并通过以下方式查看其天气信息:
- 多维度天气数据分析,包括最高气温、最低气温、降水量、风速、风向、气压、湿度等
- 趋势图表展示,如未来 7 天的气温变化折线图、风速柱状图等
- 对比分析功能,可对比多个城市之间的天气指标
- 历史天气回溯 ,展示过去一周或一个月的天气细节

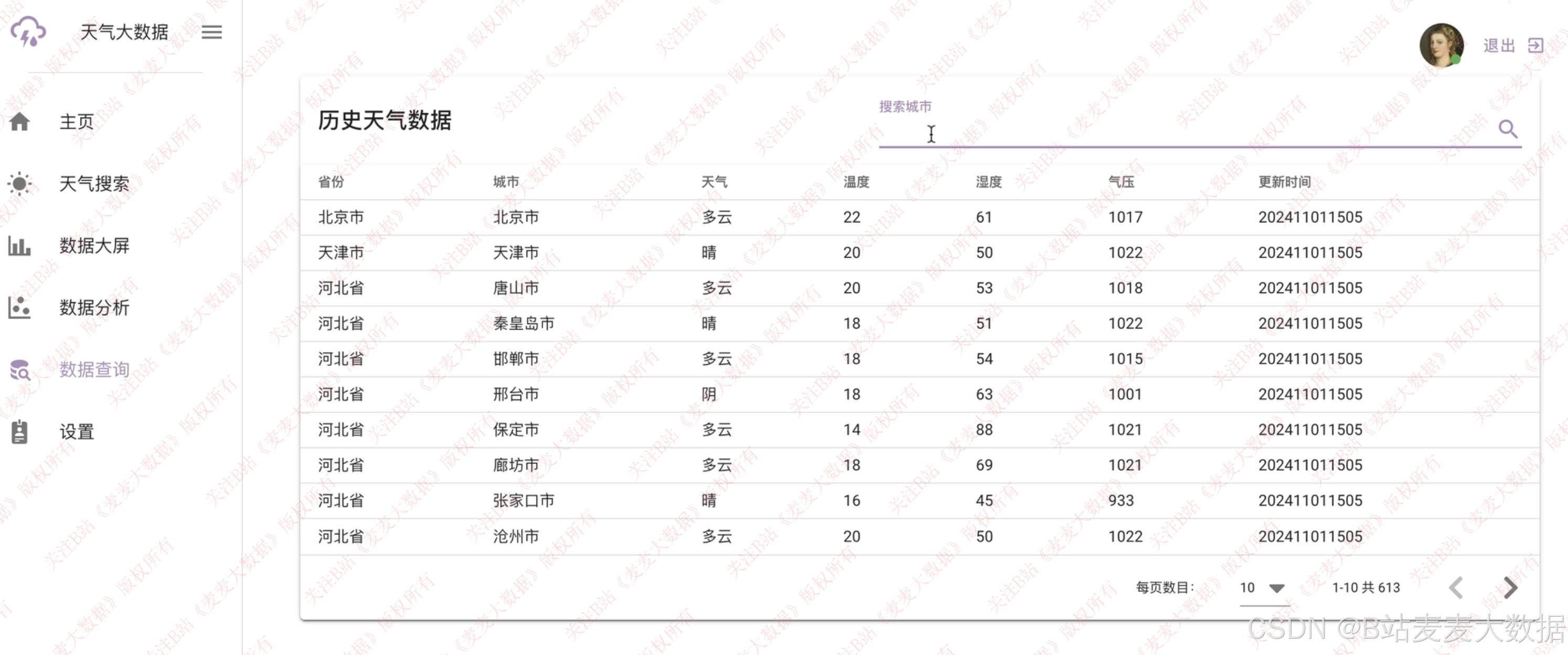
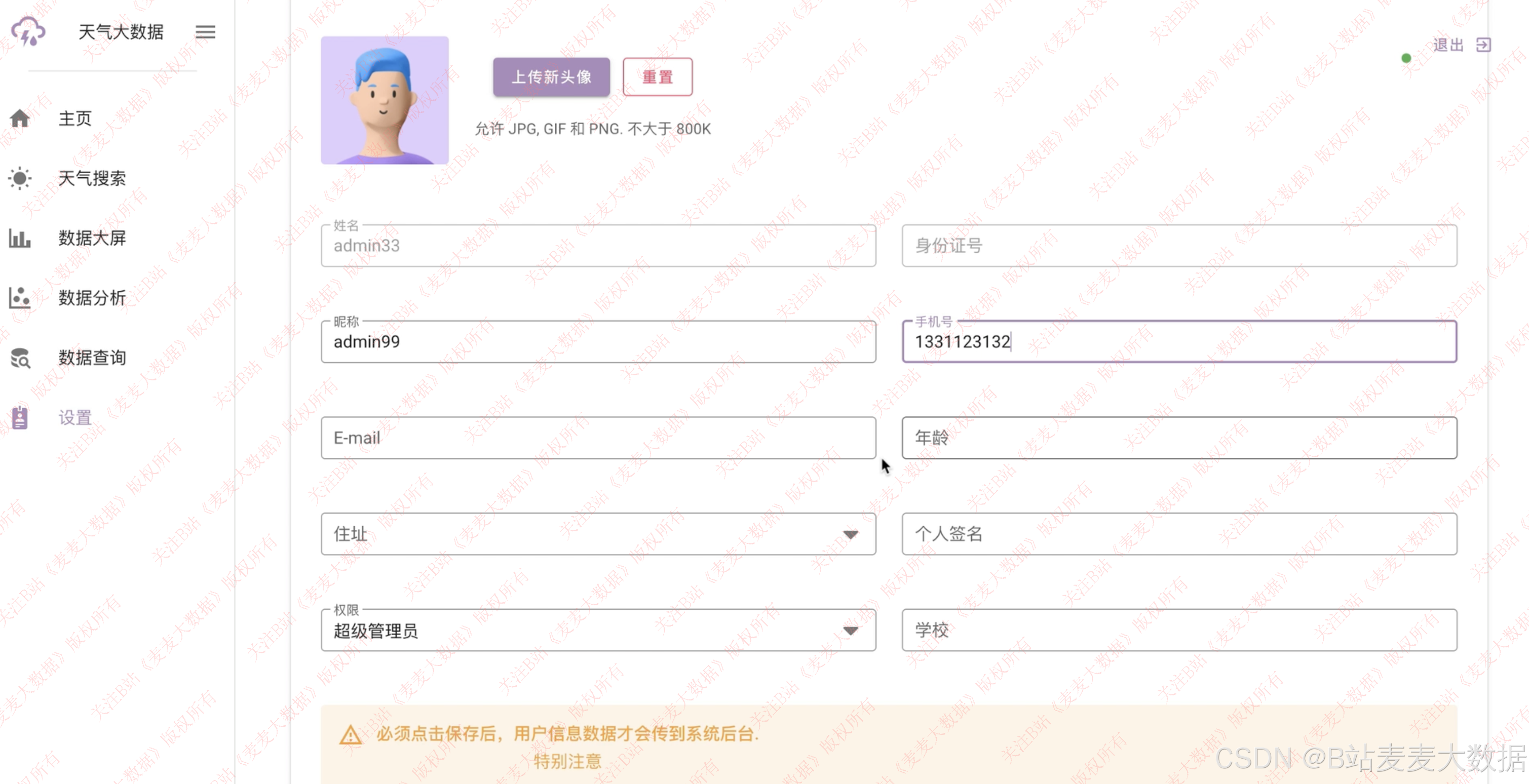
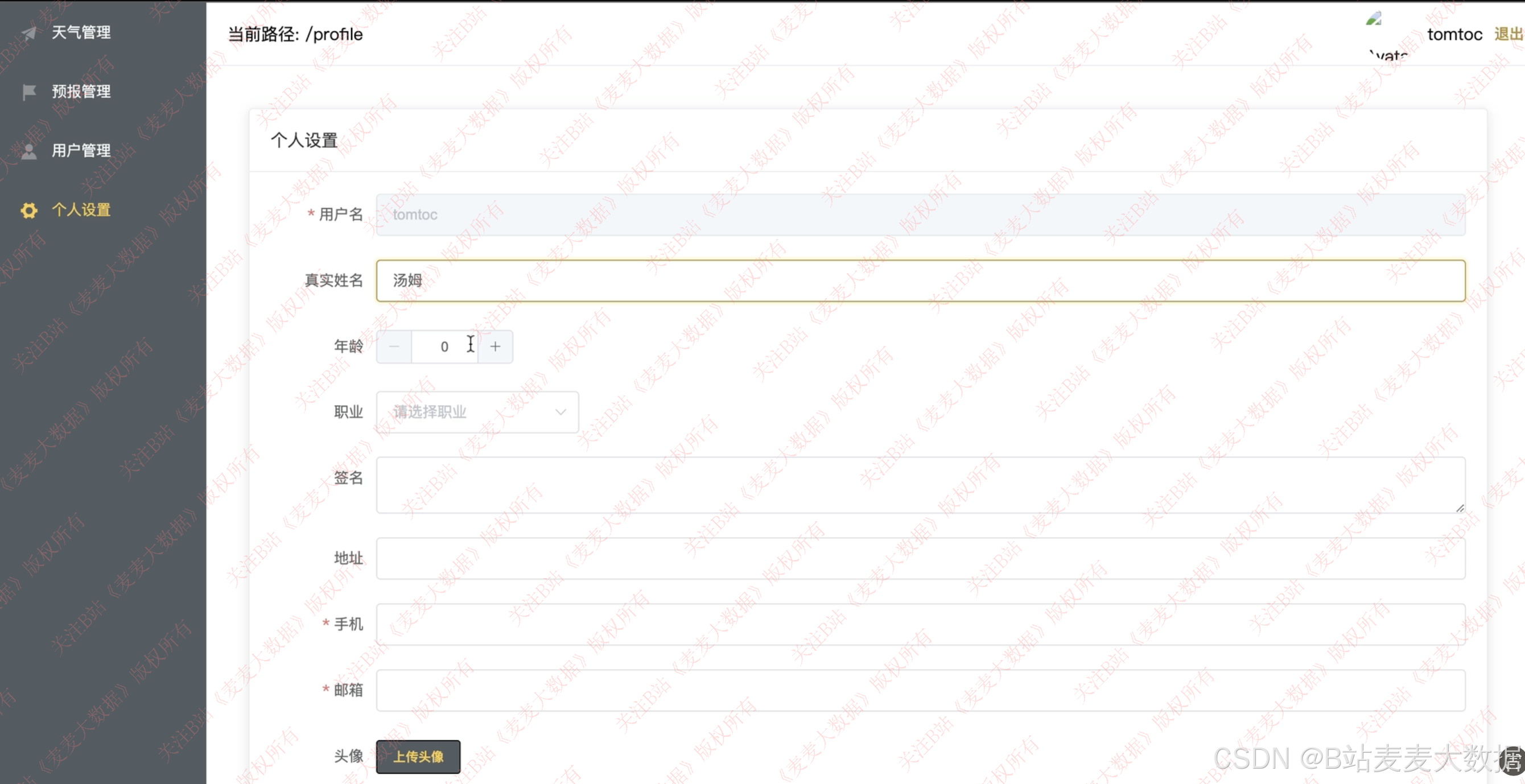
3.5 个人设置
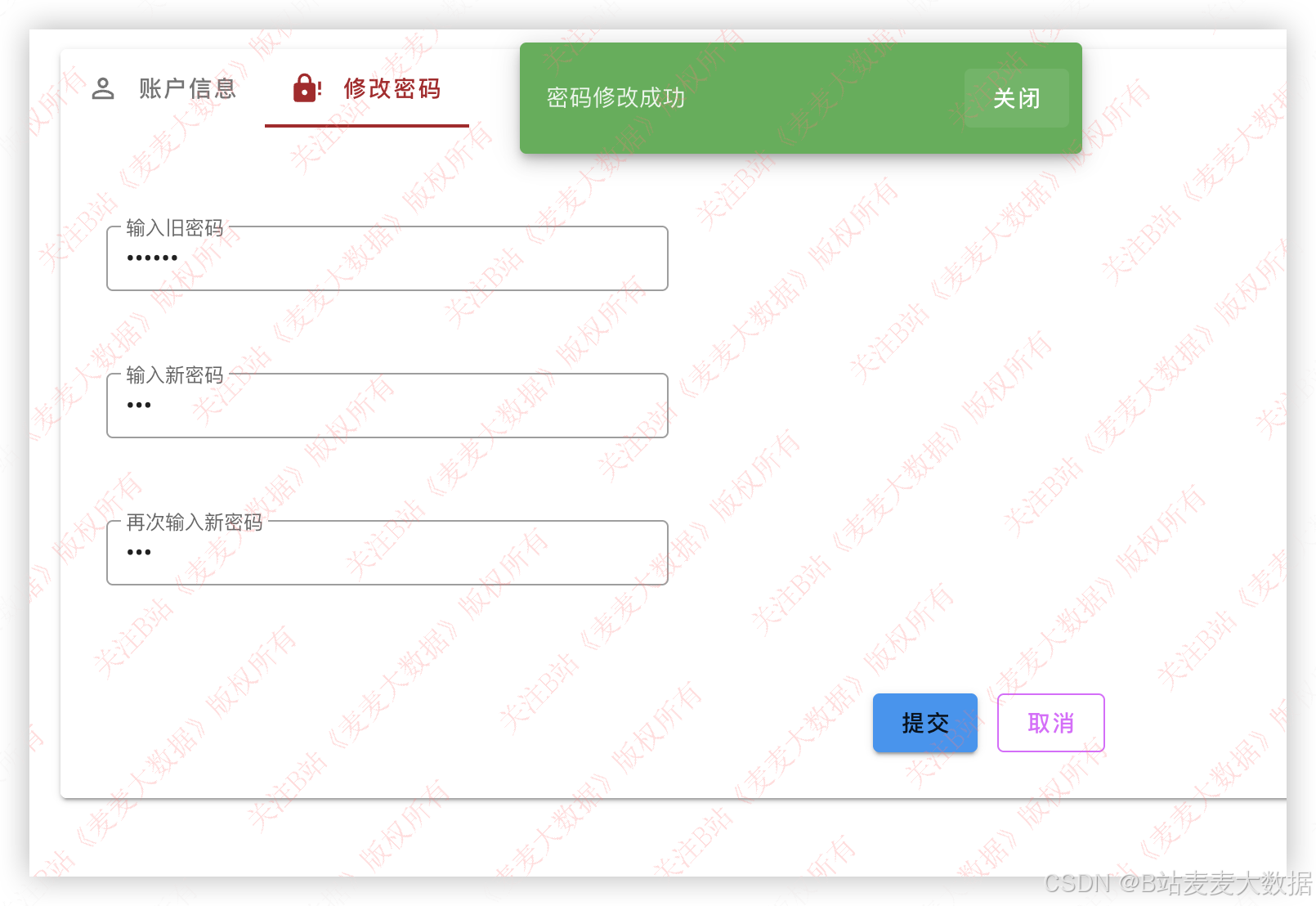
支持个人信息修改、照片修改、个人密码修改:
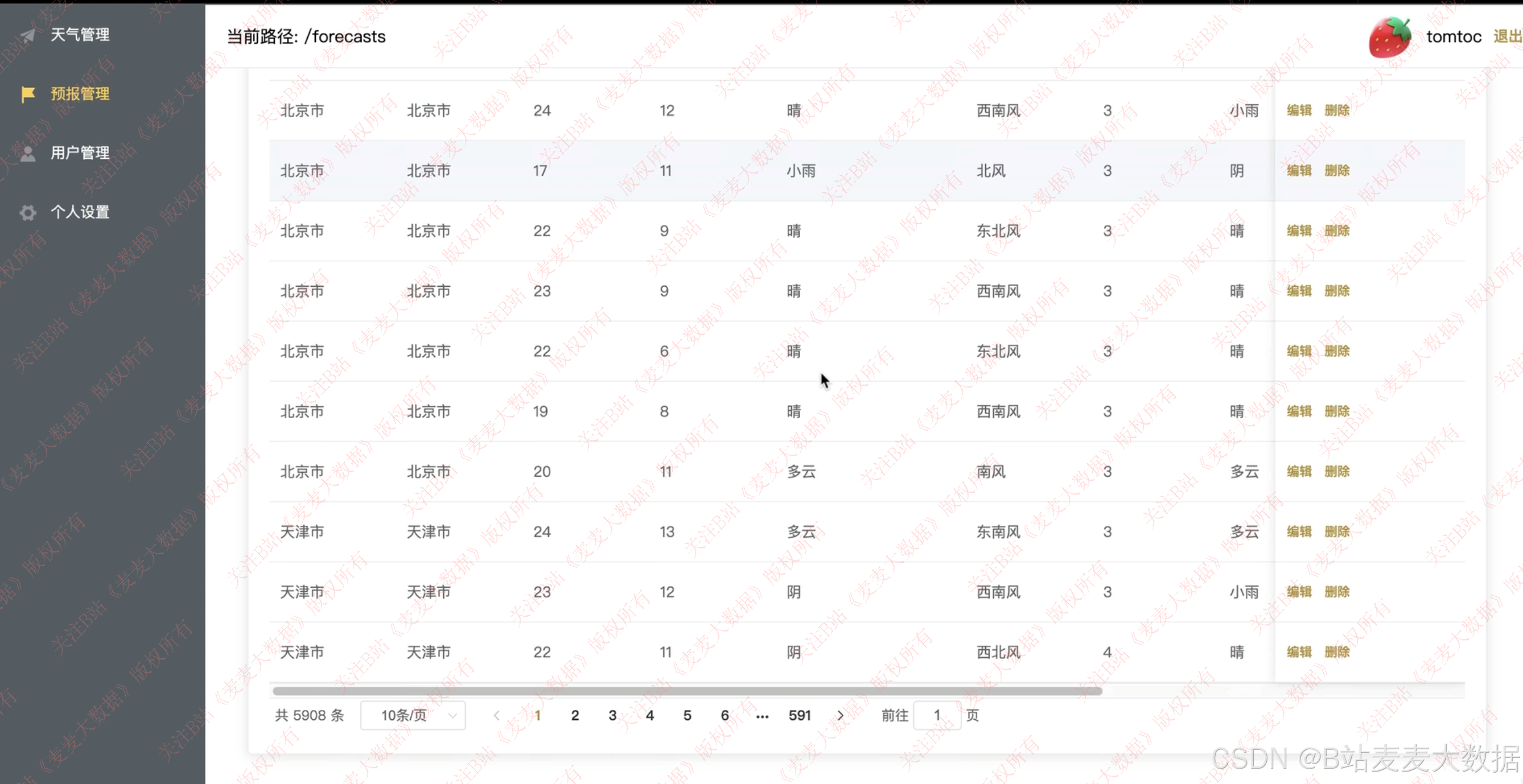
3.6 增管理端增删改查
系统提供一个美观、易用的管理端界面,供管理员对系统中的城市信息、用户数据、模型参数、天气数据等进行统一管理。管理端功能包括:
- 用户管理:查看用户数据、权限配置、活跃度分析
- 数据管理 :审核爬虫抓取的数据、手动添加或修正异常数据
管理端采用现代化 UI 设计,界面整洁、响应迅速,支持数据检索 等高级管理功能,全面提升系统可维护性与可控性。

4 文档和代码
4.1 技术报告文档

4.2 代码介绍
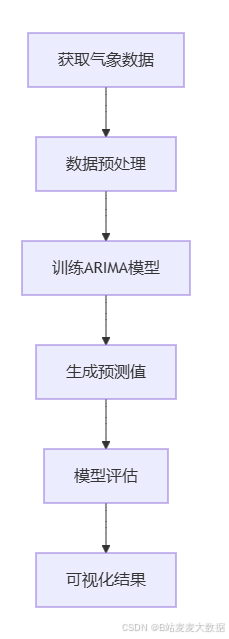
该功能实现了基于算法的城市气温预测,包含数据获取、预处理、模型训练和预测四个主要步骤。首先,从气象数据API获取目标城市的历史气温数据,并进行数据清洗和格式转换。然后,对数据进行差分处理,确保时间序列的平稳性。随后,训练ARIMA模型并使用历史数据验证模型的准确性,最后根据模型生成未来的气温预测值,并通过可视化的方式展示预测结果
4.3 核心代码
python
api = WeatherAPI()
schema = weather_schema
schema_one = weather_schema_one
search_fields = ['province', 'city']
search_filters = []
# 自定义的分页查询函数
@weatherBp.route('/', methods=['GET'])
def list():
res = ResMsg()
query_set = api.model.query
# 这部分是根据search_fields进行模糊匹配
search_term = request.args.get('search', '')
page = request.args.get('page', 1, type=int)
limit = request.args.get('limit', 10, type=int)
sort_param = request.args.get('sort', '', type=str)
if search_fields and search_term:
search_conditions = [getattr(api.model, field).like(f"%{search_term}%") for field in search_fields if
hasattr(api.model, field)]
query_set = query_set.filter(or_(*search_conditions))
# 这部分是根据search_filter进行单独的匹配
search_params = request.args.to_dict()
exact_match_fields = [f.lstrip('=') for f in search_filters if f.startswith('=')]
fuzzy_match_fields = [f for f in search_filters if not f.startswith('=')]
for field, value in search_params.items():
if field in exact_match_fields and hasattr(api.model, field):
query_set = query_set.filter(getattr(api.model, field) == value)
elif field in fuzzy_match_fields and hasattr(api.model, field):
query_set = query_set.filter(getattr(api.model, field).like(f"%{value}%"))
# 排序处理
if sort_param:
if sort_param.startswith('-'):
print('sort_param==>', sort_param[1:])
query_set = query_set.order_by(desc(getattr(api.model, sort_param[1:])))
else:
print('sort_param==>', sort_param)
query_set = query_set.order_by(getattr(api.model, sort_param))
print('分页...')
paginated_results = query_set.paginate(page=page, per_page=limit)
items = schema.dump(paginated_results.items)
# 构建响应
response = {
"records": items,
"total": paginated_results.total,
"pages": paginated_results.pages,
"page": page
}
res.update(code=ResponseCode.SUCCESS, msg='查询成功', data=response)
return res.data