消费模式
pull:
- Consumer主动从Broker中拉取消息
- 实时性低
- 拉去时间间隔由用户指定,若设置不当:间隔太短,空请求比例会增加;间隔太长,消息的实时性太差
push:
- Broker收到数据后会主动推送给Consumer
- 实时性高
Kafka采用Pull模式来消费消息,因为push模式由Broker决定发送速率,很难适应所有消费者的消费速率。
如果Kafka中没有数据,消费者有可能陷入循环,一直返回空数据。
工作流程
拉取消息(Poll)
消费者通过 拉取模式(pull) 主动从指定分区拉取消息,拉取时需指定从哪个 offset(消息偏移量) 开始消费。一条消息只能被一个消费者消费,属于是集群消费。
注意:
- 每个分区的数据只能由一个消费者组里的消费者消费
- 一个消费者可以消费多个分区
- 消费者组会统一维护每个分区的消费进度(Offset,即已消费到的消息位置),并将其保存在系统主题(__consumer_offset)里
消费者组
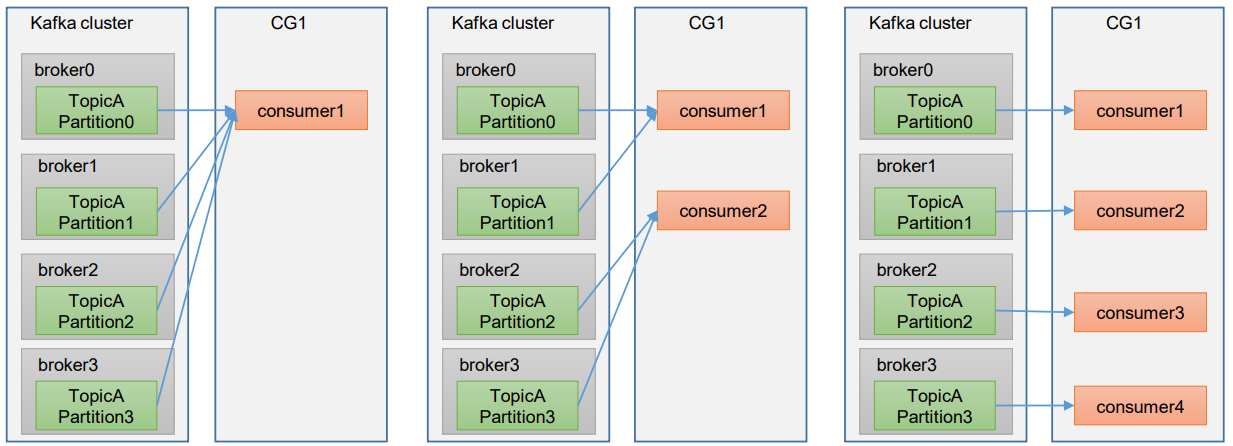
Consumer Group(CG):消费者组,由多个consumer组成。形成一个消费者组的条件,是所有消费者的groupid相同。
作用:
- 避免消息的重复消费,一个分区只会被一个消费者组里的一个消费者消费。如果由多个消费者组,这个消息就会被重复消费
- 实现负载均衡。消费者组通过分区分配机制,将主题的多个分区分配给组内的不同消费者
注意:
- 消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费。
- 消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
- 如果向消费组中添加更多的消费者,超过主题分区数量,则有一部分消费者就会闲置,不会接收任何消息。
初始化
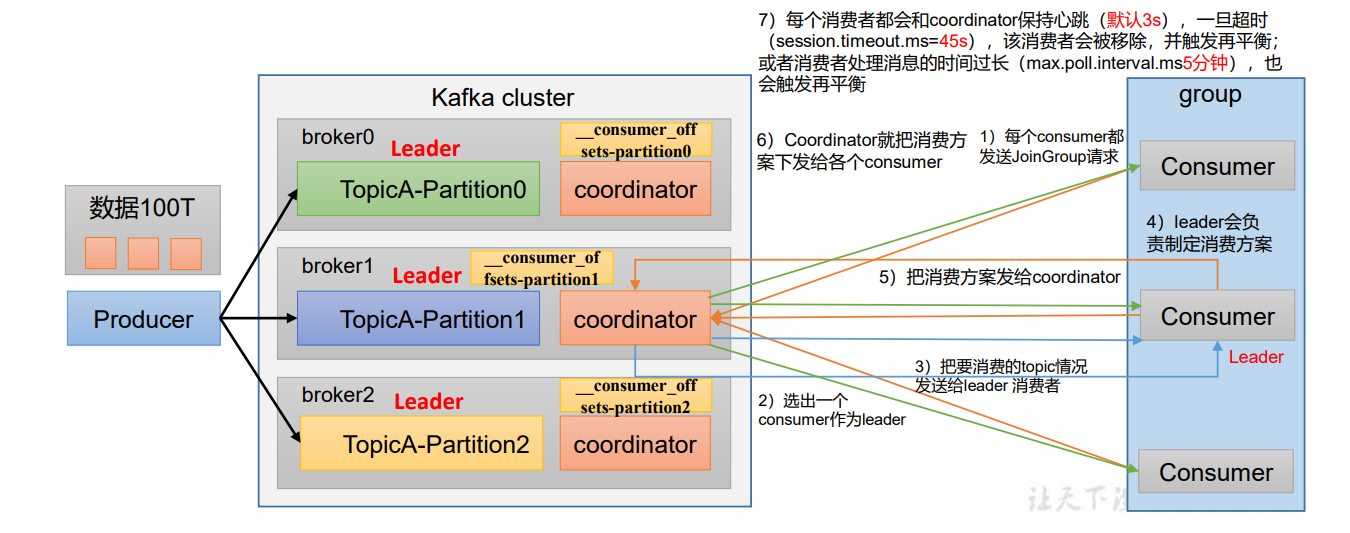
1. Coordinator 节点选择
消费者组的 Coordinator 节点由 group.id 的哈希值对 __consumer_offsets 主题的分区数(默认 50)取模确定。例如,若 group.id 哈希值为1,1%50=1,则选择 __consumer_offsets 主题 1 号分区所在的 Broker 上的Coordinator作为该组的协调者。
2. 消费者组初始化(JoinGroup 流程)
- 发送 JoinGroup 请求 :组内每个消费者向 Coordinator 发送
JoinGroup请求,申请加入消费者组。 - 选举 Leader 消费者 :Coordinator 从组内消费者中选出一个作为 Leader 消费者。
- 上报消费主题信息:所有消费者将自己要消费的 Topic 信息发送给 Leader 消费者。
- 制定消费方案 :Leader 消费者根据组内消费者数量和 Topic 分区情况,制定分区分配方案(如 Range、RoundRobin 策略)。
- 提交消费方案:Leader 消费者将制定的消费方案发送给 Coordinator。
- 下发消费方案:Coordinator 将消费方案下发给组内所有消费者,消费者根据方案确定自己负责的分区。
3. 心跳与重平衡触发
- 每个消费者会与 Coordinator 保持心跳(默认 3 秒)。若消费者超时(
session.timeout.ms默认为 45 秒)或处理消息时间过长(max.poll.interval.ms默认为 5 分钟),Coordinator 会将其移除并触发重平衡,重新分配分区。
4. Offset 提交与存储
消费者提交的 Offset 会发送到对应 Coordinator 管理的 __consumer_offsets 分区中持久化,确保消费进度的可靠性。
消费流程
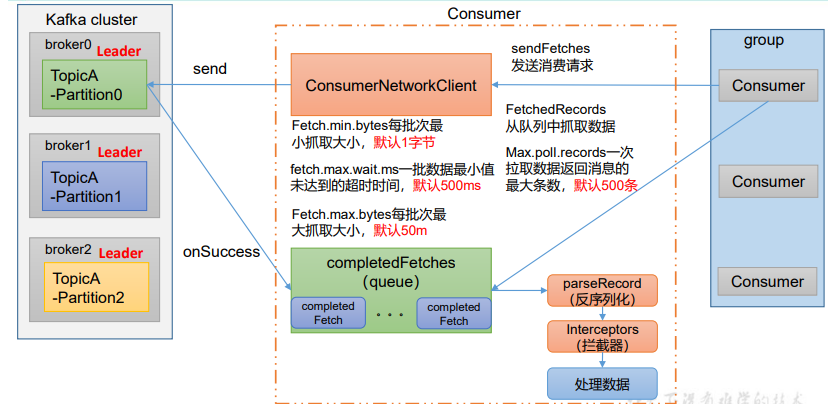
1. 发起拉取请求
消费者通过 ConsumerNetworkClient 向 Kafka 集群中对应分区的 Leader Broker(如 TopicA 的 Partition0、1、2 分别对应 broker0、broker1、broker2 的 Leader)发送拉取请求(Fetch Request)。
2. 拉取参数控制
拉取过程由多个参数控制:
Fetch.min.bytes:每批次最小抓取大小(默认 1 字节),若数据量不足则等待。fetch.max.wait.ms:一批数据未达最小值时的超时时间(默认 500ms),超时后即使数据不足也返回。Fetch.max.bytes:每批次最大抓取大小(默认 50M),防止单次拉取数据量过大。Max.poll.records:一次拉取返回消息的最大条数(默认 500 条)。
3. 接收并缓存拉取结果
Broker 调用回调函数处理拉取请求后,将消息返回给消费者,消费者将结果存入 completedFetches 队列(缓存已完成的拉取任务)。
4. 消息处理流程
消费者组从队列中获取消息后,依次进行:
- 反序列化(parseRecord):将字节数据解析为业务可识别的消息格式。
- 拦截器(Interceptors):可插入自定义逻辑(如日志记录、数据过滤)。
- 业务处理:执行具体的业务逻辑(如存储、计算、转发等)。