(摘要的内容来源于百度百科)
PyTorch是一个用于机器学习和深度学习的开源深度学习框架,由Facebook于2016年发布,其主要实现了自动微分功能,并引入动态计算图使模型建立更加灵活。Pytorch可分为前后端两个部分,前端是与用户直接交互的python API,后端是框架内部实现的部分,包括Autograd,它是一个自动微分引擎。
Pytorch基于已有的张量库Torch开发,在PyTorch的早期版本中,使用的是Torch7,后来随着PyTorch的发展,逐渐演变成了PyTorch所使用的张量库。
现如今,Pytorch已经成为开源机器学习系统中,在科研领域市场占有率最高的框架,其在AI顶会上的占比在2022年已达80%
一、什么是PyTorch
PyTorch 是一个开源的深度学习框架,由 Facebook's AI Research lab (FAIR) 开发,广泛应用于学术研究和工业界。它提供了高效且灵活的工具,用于构建和训练深度学习模型。
关于学习框架的更多内容,可参考:【人工智能系列:走近人工智能04】了解人工智能的框架:从TensorFlow到PyTorch
二、PyTorch的关键功能和特点
1. 动态计算图(Dynamic Computation Graph)
PyTorch 的计算图是动态的,这意味着计算图在每一次迭代时都会被重新构建。这使得调试和修改模型更加灵活,因为可以在运行时查看和修改计算图。这一特性与 TensorFlow 的静态计算图(TensorFlow 1.x)不同,但在 PyTorch 中,这种灵活性为快速原型设计和实验提供了极大的便利。
2. 强大的张量操作
PyTorch 提供了一个强大的张量(Tensor)库,类似于 NumPy,但能够支持 GPU 加速。PyTorch 张量可以在 CPU 或 GPU 上运行,能够进行高效的数学运算,支持自动微分,非常适合进行机器学习和深度学习的计算。
3. 自动微分(Autograd)
PyTorch 内置的 Autograd 模块自动计算梯度,这使得反向传播(backpropagation)过程变得简便。Autograd 支持对所有操作进行自动微分,这对于深度学习中的梯度优化过程非常关键。
4. GPU加速
PyTorch 支持通过 CUDA(NVIDIA 提供的并行计算平台)将张量和计算过程从 CPU 转移到 GPU,这大大提高了计算效率,尤其是在训练大型神经网络时。
5. 模块化设计(torch.nn)
PyTorch 提供了一个名为 torch.nn 的模块,用于构建神经网络。这个模块包括了各种层(如卷积层、池化层、全连接层等),损失函数,以及优化算法(如 SGD、Adam 等)。使用这些模块,你可以快速构建并训练深度学习模型。
6. TorchVision 和 TorchText
- TorchVision:这是一个用于计算机视觉任务的 PyTorch 扩展,提供了常用的图像数据集、预训练模型以及图像处理工具。
- TorchText:用于处理自然语言处理(NLP)任务,提供了文本处理、数据加载和词汇映射的工具。
7. Eager Execution
PyTorch 采用 Eager Execution 模式,这意味着运算是立即执行的。每次操作都会立刻返回结果,便于调试和验证代码逻辑。相较于 TensorFlow 的静态图执行,Eager Execution 更加直观,适合调试和开发阶段。
8. 跨平台支持
PyTorch 可以在多个平台上运行,包括 Windows、Linux 和 macOS。它还可以在云计算环境中部署,支持与各种硬件设备的集成(如 CPU、GPU 和 TPUs)。
9. 广泛的社区支持
PyTorch 拥有一个活跃的开发社区,许多最新的深度学习研究和技术都首先在 PyTorch 中实现。此外,PyTorch 还与许多流行的工具和库(如 Hugging Face 的 Transformers、fastai 等)兼容,进一步增强了其在各种应用中的灵活性。
10. 用于生产部署
虽然 PyTorch 起初是为研究而设计的,但随着时间的推移,PyTorch 也推出了一些工具和扩展来支持生产部署。例如,TorchServe 是一个用于部署 PyTorch 模型的工具,适用于大规模应用。
三、PyTorch 的应用领域
- 计算机视觉:图像分类、目标检测、图像生成等。
- 自然语言处理:文本分类、情感分析、机器翻译、生成模型等。
- 强化学习:强化学习算法的实现和训练。
- 生成对抗网络(GAN):用于图像生成、风格迁移等任务。
四、PyTorch 的简单示例代码
这是一个简单的 PyTorch 示例,展示如何创建一个简单的神经网络并训练它:
python
import torch
import torch.nn as nn
import torch.optim as optim
# 定义一个简单的神经网络
class SimpleNN(nn.Module):
def __init__(self):
super(SimpleNN, self).__init__()
self.fc1 = nn.Linear(784, 128) # 输入层 784 -> 隐藏层 128
self.fc2 = nn.Linear(128, 10) # 隐藏层 128 -> 输出层 10(假设是10分类问题)
def forward(self, x):
x = torch.relu(self.fc1(x)) # 使用 ReLU 激活函数
x = self.fc2(x) # 输出层
return x
# 创建模型、损失函数和优化器
model = SimpleNN()
criterion = nn.CrossEntropyLoss() # 分类问题常用损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 假设训练数据是一个 batch 大小为 64 的输入数据(784维)和对应标签
inputs = torch.randn(64, 784) # 随机生成输入数据
labels = torch.randint(0, 10, (64,)) # 随机生成标签
# 前向传播
outputs = model(inputs)
loss = criterion(outputs, labels)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Loss: {loss.item()}")五、TorchScript、TorchServe 和 PyTorch
TorchScript 、TorchServe 和 PyTorch 都属于同一个机器学习框架生态,但它们各自承担着不同的角色,互为补充。下面是它们之间的关系与区别:
1. PyTorch
PyTorch 是一个开源的深度学习框架,广泛应用于研究和生产环境中。它提供了一个灵活的框架,可以方便地定义和训练神经网络,支持动态图(即动态计算图)以及强大的自动微分(autograd)机制。它的核心特点包括:
- 灵活性:动态计算图,使得研究人员可以更容易地调试和修改模型。
- 高性能:支持 GPU 加速,并且可以利用各种硬件进行优化。
- 易用性:Pythonic 接口使得代码易于书写和理解。
但是,尽管 PyTorch 很适合研究,它在生产环境中的部署和推理仍然有一些挑战,例如需要将模型转换为可优化和高效运行的格式。
2. TorchScript
TorchScript 是 PyTorch 的一个扩展,目的是让 PyTorch 模型能够脱离 Python 运行。这解决了 PyTorch 模型在生产环境中难以部署的问题。它的主要功能是:
- 静态图转换:TorchScript 可以将动态计算图(PyTorch 默认的执行方式)转换为静态图,从而让模型能在没有 Python 解释器的环境中运行(比如在移动设备或生产环境中)。
- 跨平台支持 :通过 TorchScript,PyTorch 模型可以被导出为一种更通用的格式(例如
.pt或.torchscript文件),可以在多种平台上运行,包括 C++ 环境、iOS、Android 等。 - 性能提升:通过静态图优化,TorchScript 在推理阶段通常比原始的 PyTorch 更高效。
3. TorchServe
TorchServe 是由 AWS 和 Facebook 合作开发的一个用于 模型部署和服务的框架,专为 PyTorch 设计。它提供了一整套工具和服务,用于将 PyTorch 模型高效地部署到生产环境中,并提供模型推理服务。其主要功能包括:
- 模型管理:支持模型的部署、版本控制、监控和更新。
- 高效推理:通过优化的推理引擎(例如多线程、批量处理),提升模型的推理性能。
- API 服务:提供 RESTful API 接口,便于客户端调用模型进行推理。
- 弹性扩展:支持与 Kubernetes 等容器管理平台结合,提供横向扩展能力。
TorchServe 与 PyTorch 的关系是,它利用 PyTorch 模型和 TorchScript 技术提供了一种标准化的部署方式,可以非常方便地将训练好的 PyTorch 模型发布为 HTTP API 服务供其他应用调用。
4. 三者的关系
- PyTorch:是基础框架,用于模型训练、定义和开发,特别适用于研究。
- TorchScript:是 PyTorch 的扩展,用于将动态计算图转换为静态图,目的是让 PyTorch 模型可以在生产环境中高效运行,特别是在不需要 Python 环境的设备上。
- TorchServe:是基于 PyTorch 和 TorchScript 开发的一个模型部署和服务平台,用于将训练好的模型快速高效地部署为在线推理服务。
- 三者之间的关系如下:
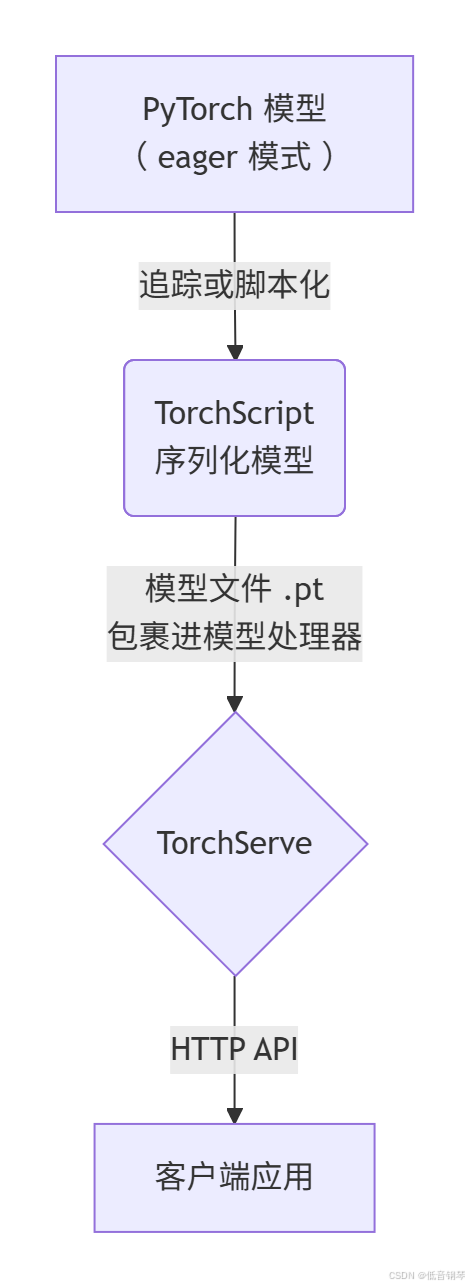
- PyTorch 负责训练和开发模型。
- TorchScript 用于模型的静态化和优化,使得模型可以在生产环境中高效运行。
- TorchServe 则是基于 TorchScript 模型部署的服务平台,用于模型的托管、推理和管理。
六、部署说明
1. 创建虚拟环境
首先,为了保持项目的隔离性和避免与其他项目的依赖冲突,建议创建一个 Python 虚拟环境。这里我们使用 venv 来创建环境。
-
打开终端(Linux/macOS)或命令提示符(Windows)。
-
创建一个新的虚拟环境:
bashpython -m venv myenv -
激活虚拟环境:
-
Windows :
bashmyenv\Scripts\activate -
Linux/macOS :
bashsource myenv/bin/activate
-
2. 安装依赖
可以通过 pip 安装所有示例代码所需的 Python 库。
bash
pip install torch torchvision matplotlib numpy pandas scikit-learn statsmodels requests beautifulsoup43. 运行代码示例
在虚拟环境中安装好所需依赖后,可以按以下步骤运行代码:
-
创建一个 Python 文件 ,例如
main.py,并将相应的代码粘贴到文件中。例如,如果你要运行 GAN 示例,将 GAN 的代码放入main.py文件中。 -
在命令行中执行代码:
bashpython main.py
4. 开发环境配置和管理
为了更好地管理和分享你的项目,建议使用 requirements.txt 文件记录所有依赖项。这样,你可以轻松地在其他机器上部署该环境。
- 生成
requirements.txt文件:
bash
pip freeze > requirements.txt这将生成一个包含所有安装包及其版本的文件,可以用来在其他环境中重现相同的环境。
- 使用
requirements.txt安装依赖:
在其他机器上,只需通过以下命令安装所有依赖:
bash
pip install -r requirements.txt七、代码示例
为了让每个场景都有对应的示例代码,并且能展示效果,我将按照你给出的场景逐个列出。由于每个场景的实现都可能较为复杂,因此我会尽量简化代码并确保它可以运行。代码的输出效果将会展示模型的训练结果、图像、预测等内容。
1. 深度学习模型训练示例
示例:简单的神经网络用于手写数字分类(MNIST)
python
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
# 数据加载和预处理
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
trainset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform)
trainloader = DataLoader(trainset, batch_size=64, shuffle=True)
# 定义简单的神经网络
class SimpleNN(nn.Module):
def __init__(self):
super(SimpleNN, self).__init__()
self.fc1 = nn.Linear(28*28, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = x.view(-1, 28*28)
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
# 实例化模型、损失函数、优化器
model = SimpleNN()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 训练模型
for epoch in range(5):
running_loss = 0.0
for inputs, labels in trainloader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f"Epoch {epoch+1}, Loss: {running_loss/len(trainloader)}")2. 自然语言处理 (NLP)示例
示例:使用 BERT 进行文本分类
python
from transformers import BertTokenizer, BertForSequenceClassification
from torch.utils.data import DataLoader
from torch.optim import AdamW
import torch
# 加载BERT Tokenizer和模型
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
# 简单的文本输入
texts = ["I love programming.", "I hate bugs."]
labels = [1, 0] # 1: Positive, 0: Negative
# Tokenization
inputs = tokenizer(texts, return_tensors='pt', padding=True, truncation=True)
# 数据加载器
data = list(zip(inputs['input_ids'], labels))
trainloader = DataLoader(data, batch_size=2)
# 优化器
optimizer = AdamW(model.parameters(), lr=1e-5)
# 训练
model.train()
for epoch in range(3):
for input_ids, label in trainloader:
optimizer.zero_grad()
outputs = model(input_ids, labels=torch.tensor(label))
loss = outputs.loss
loss.backward()
optimizer.step()
print(f"Epoch {epoch+1}, Loss: {loss.item()}")3. 计算机视觉示例
示例:使用 CNN 进行图像分类(CIFAR-10)
python
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
# 数据加载
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
trainloader = DataLoader(trainset, batch_size=64, shuffle=True)
# 定义卷积神经网络,目前我也处于读书不求甚解的水平,所以不用问我这段代码是什么意思,语法我都会,但是连一起我就不知道是什么意思了。
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(3, 64, 3, padding=1)
self.conv2 = nn.Conv2d(64, 128, 3, padding=1)
self.fc1 = nn.Linear(128 * 8 * 8, 1024)
self.fc2 = nn.Linear(1024, 10)
def forward(self, x):
x = torch.relu(self.conv1(x))
x = torch.max_pool2d(x, 2)
x = torch.relu(self.conv2(x))
x = torch.max_pool2d(x, 2)
x = x.view(-1, 128 * 8 * 8)
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
# 模型、损失函数和优化器
model = CNN()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练
for epoch in range(5):
running_loss = 0.0
for inputs, labels in trainloader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f"Epoch {epoch+1}, Loss: {running_loss/len(trainloader)}")4. 强化学习示例
示例:Q-learning 小车环境
python
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
# 简单的Q-learning网络
class QNetwork(nn.Module):
def __init__(self, input_size, output_size):
super(QNetwork, self).__init__()
self.fc1 = nn.Linear(input_size, 128)
self.fc2 = nn.Linear(128, output_size)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
# 定义环境参数
state_space = 4
action_space = 2
env = np.random.rand(10, 10) # 假设一个简单的10x10环境
# 初始化Q网络
model = QNetwork(state_space, action_space)
optimizer = optim.Adam(model.parameters(), lr=0.01)
criterion = nn.MSELoss()
# 简单的训练循环
for episode in range(100):
state = np.random.rand(1, state_space)
action = np.random.choice(action_space)
reward = np.random.randn() # 假设奖励是一个随机数
next_state = np.random.rand(1, state_space)
# Q-learning 更新
target = reward + 0.99 * torch.max(model(torch.tensor(next_state, dtype=torch.float32)))
output = model(torch.tensor(state, dtype=torch.float32))[0][action]
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Episode {episode+1}, Loss: {loss.item()}")5. 生成对抗网络 (GAN)示例
示例:使用GAN生成手写数字(MNIST)
python
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
# 数据加载
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
trainset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform)
trainloader = DataLoader(trainset, batch_size=64, shuffle=True)
# 定义生成器和判别器
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.fc1 = nn.Linear(100, 256)
self.fc2 = nn.Linear(256, 512)
self.fc3 = nn.Linear(512, 1024)
self.fc4 = nn.Linear(1024, 28*28)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = torch.relu(self.fc3(x))
x = torch.tanh(self.fc4(x))
return x.view(-1, 1, 28, 28)
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.fc1 = nn.Linear(28*28, 1024)
self.fc2 = nn.Linear(1024, 512)
self.fc3 = nn.Linear(512, 256)
self.fc4 = nn.Linear(256, 1)
def forward(self, x):
x = x.view(-1, 28*28)
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = torch.relu(self.fc3(x))
x = torch.sigmoid(self.fc4(x))
return x
# 实例化模型和优化器
generator = Generator()
discriminator = Discriminator()
optimizer_g = optim.Adam(generator.parameters(), lr=0.0002, betas=(0.5, 0.999))
optimizer_d = optim.Adam(discriminator.parameters(), lr=0.0002, betas=(0.5, 0.999))5. 生成对抗网络 (GAN)示例
示例:使用GAN生成手写数字(MNIST)
python
# GAN 训练
num_epochs = 10
for epoch in range(num_epochs):
for i, (real_images, _) in enumerate(trainloader):
batch_size = real_images.size(0)
real_images = real_images.view(batch_size, -1) # Flatten the images for the discriminator
# 训练判别器
optimizer_d.zero_grad()
# 真实图像的判别
real_labels = torch.ones(batch_size, 1)
output_real = discriminator(real_images)
loss_real = torch.nn.functional.binary_cross_entropy(output_real, real_labels)
# 生成假图像并判别
z = torch.randn(batch_size, 100)
fake_images = generator(z)
fake_labels = torch.zeros(batch_size, 1)
output_fake = discriminator(fake_images.detach()) # Detach to avoid gradient updates for generator
loss_fake = torch.nn.functional.binary_cross_entropy(output_fake, fake_labels)
# 总的判别损失
d_loss = loss_real + loss_fake
d_loss.backward()
optimizer_d.step()
# 训练生成器
optimizer_g.zero_grad()
output_fake_for_g = discriminator(fake_images)
g_loss = torch.nn.functional.binary_cross_entropy(output_fake_for_g, real_labels) # We want fake to be classified as real
g_loss.backward()
optimizer_g.step()
print(f"Epoch {epoch+1}/{num_epochs}, D Loss: {d_loss.item()}, G Loss: {g_loss.item()}")
# 每隔一定的epoch展示生成的图像
if (epoch + 1) % 5 == 0:
import matplotlib.pyplot as plt
plt.imshow(fake_images[0].detach().numpy().reshape(28, 28), cmap='gray')
plt.title(f"Generated Image at Epoch {epoch+1}")
plt.show()6. 图像处理示例
示例:图像去噪(使用简单的卷积神经网络)
python
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
# 数据加载
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4, shuffle=True)
# 定义简单的去噪网络
class DenoisingCNN(nn.Module):
def __init__(self):
super(DenoisingCNN, self).__init__()
self.conv1 = nn.Conv2d(3, 64, 3, padding=1)
self.conv2 = nn.Conv2d(64, 3, 3, padding=1)
def forward(self, x):
x = torch.relu(self.conv1(x))
x = self.conv2(x)
return x
# 实例化模型
model = DenoisingCNN()
# 加载一张图片并添加噪声
image, _ = next(iter(trainloader))
noisy_image = image + 0.5 * torch.randn_like(image)
# 输出噪声图像
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.imshow(noisy_image[0].permute(1, 2, 0).numpy())
plt.title("Noisy Image")
# 模型去噪
denoised_image = model(noisy_image)
# 输出去噪后的图像
plt.subplot(1, 2, 2)
plt.imshow(denoised_image[0].detach().permute(1, 2, 0).numpy())
plt.title("Denoised Image")
plt.show()7. 推荐系统示例
示例:简单的协同过滤推荐系统
python
import numpy as np
import pandas as pd
from sklearn.neighbors import NearestNeighbors
# 构建用户-物品评分矩阵
data = {
'User1': [5, 3, 0, 1, 0],
'User2': [4, 0, 0, 1, 2],
'User3': [1, 1, 0, 5, 0],
'User4': [0, 0, 3, 4, 4],
'User5': [2, 3, 4, 0, 0]
}
df = pd.DataFrame(data)
# 训练最近邻模型
knn = NearestNeighbors(n_neighbors=2, metric='cosine')
knn.fit(df.T)
# 假设我们要为User1推荐物品
user_index = df.columns.get_loc('User1')
distances, indices = knn.kneighbors([df.iloc[:, user_index]])
# 输出推荐的用户和评分
print("Recommended users for User1:")
for idx in indices[0]:
print(df.columns[idx], df.iloc[:, idx].tolist())8. 时间序列分析示例
示例:简单的ARIMA模型预测股票价格
python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from statsmodels.tsa.arima.model import ARIMA
# 创建一个示例股票价格数据(假设数据为每日收盘价)
data = {
'Date': pd.date_range(start='2023-01-01', periods=100, freq='D'),
'Price': np.random.randn(100).cumsum() + 100
}
df = pd.DataFrame(data)
df.set_index('Date', inplace=True)
# 使用ARIMA模型进行时间序列预测
model = ARIMA(df['Price'], order=(1, 1, 1)) # ARIMA(1,1,1)
model_fit = model.fit()
# 预测未来7天的股票价格
forecast = model_fit.forecast(steps=7)
forecast_dates = pd.date_range(start=df.index[-1], periods=8, freq='D')[1:]
# 绘制原始数据和预测数据
plt.plot(df.index, df['Price'], label='Historical Prices')
plt.plot(forecast_dates, forecast, label='Forecast Prices', color='red')
plt.legend()
plt.show()9. 数据库操作示例
示例:SQLite数据库操作(创建表、插入数据、查询数据)
python
import sqlite3
# 创建数据库连接
conn = sqlite3.connect(':memory:')
cursor = conn.cursor()
# 创建一个表
cursor.execute('''CREATE TABLE users (id INTEGER PRIMARY KEY, name TEXT, age INTEGER)''')
# 插入数据
cursor.execute("INSERT INTO users (name, age) VALUES ('Alice', 25)")
cursor.execute("INSERT INTO users (name, age) VALUES ('Bob', 30)")
cursor.execute("INSERT INTO users (name, age) VALUES ('Charlie', 35)")
conn.commit()
# 查询数据
cursor.execute("SELECT * FROM users")
rows = cursor.fetchall()
for row in rows:
print(row)
# 关闭连接
conn.close()10. 网络爬虫示例
示例:使用 requests 和 BeautifulSoup 爬取网页内容
python
import requests
from bs4 import BeautifulSoup
# 发送HTTP请求
url = 'https://quotes.toscrape.com/'
response = requests.get(url)
# 解析网页内容
soup = BeautifulSoup(response.text, 'html.parser')
quotes = soup.find_all('span', class_='text')
# 输出抓取的引文
for quote in quotes:
print(quote.text)八、测试与优化
一旦代码能够正常运行,你可以测试代码的性能,并进行优化:
- 模型优化 :例如,使用更高效的优化器、改进模型架构、使用 GPU 加速(如使用
torch.cuda)。 - 数据处理优化:对数据进行预处理,减少训练时间和内存消耗。
- 代码优化 :利用多线程或并行计算(如
multiprocessing或joblib)加速任务。
九、版本控制
版本控制用GIT就好,网络上已经有很多类似的资料,这里简单给出常用命令:
-
初始化一个 Git 仓库:
bashgit init -
添加文件并提交:
bashgit add . git commit -m "Initial commit" -
将代码推送到 GitHub 或其他 Git 托管平台:
bashgit remote add origin <repository_url> git push -u origin master
十、如何开发自己的学习框架
相信对于所有的个人开发者来说,通过PyTorch开发一个自己的学习框架,既有挑战性又令人跃跃欲试。不过在动手写框架之前,通常需要对 神经网络设计、训练优化、自动微分、并行化等领域 有深入的理解。
1. 明确框架目标与功能
首先,你需要明确开发框架的目标。不同的框架可能有不同的侧重点,比如:
- 自动化神经网络构建:例如简化层的构建和组合。
- 特定任务优化:比如为某些特定的应用(如图像处理、自然语言处理)提供优化的工具。
- 高效的训练与优化:通过改进训练流程,提升性能或增加新的训练技巧。
如果你没有具体的框架目标,可以先从一些简单的框架开始,例如:
- 提供一个简化的接口来构建常见的神经网络结构(例如 CNN、RNN 等)。
- 扩展 PyTorch 的训练流程,添加新的优化器或损失函数。
- 创建适用于某些硬件(如 GPU 或 TPU)的高效训练方法。
2. 了解 PyTorch 的核心组件
在开发自己的框架时,深入了解 PyTorch 的内部工作原理非常重要。以下是一些核心组件,你应该熟悉它们:
-
张量(Tensor):PyTorch 的核心数据结构,用于表示多维数组。你需要理解如何高效地操作张量,并利用 PyTorch 的自动微分功能。
-
自动微分(Autograd):PyTorch 的 autograd 引擎允许你轻松地进行反向传播和梯度计算。开发框架时,了解如何自定义梯度计算非常重要。
-
模块(nn.Module) :这是 PyTorch 中定义神经网络的核心类。了解如何扩展
nn.Module,添加自定义层和操作,是构建框架的基础。 -
优化器(Optimizer):PyTorch 提供了多种优化器(例如 SGD、Adam)。如果你想为框架开发自定义的优化算法,理解优化器的实现和工作原理非常关键。
-
数据加载(DataLoader) :数据加载和预处理是深度学习中的重要部分。你可能需要扩展
DataLoader类来处理自定义数据集或加速数据加载。
3. 开发自定义模块
在开发框架时,你将经常需要自定义模块和层。你可以从以下方面着手:
- 自定义层(Layers) :你可以基于
nn.Module创建新的神经网络层,或者结合现有的层(如卷积层、全连接层等)来构建新的复合层。
python
import torch
import torch.nn as nn
class CustomLayer(nn.Module):
def __init__(self, input_size, output_size):
super(CustomLayer, self).__init__()
self.linear = nn.Linear(input_size, output_size)
def forward(self, x):
return self.linear(x)- 自定义损失函数 :你也可以实现自己的损失函数,通过继承
nn.Module类并重写forward方法。
python
class CustomLoss(nn.Module):
def __init__(self):
super(CustomLoss, self).__init__()
def forward(self, output, target):
return torch.mean((output - target) ** 2)- 自定义优化器 :你可以基于 PyTorch 提供的
Optimizer类开发自定义的优化器。自定义优化器适用于某些特定的训练方法或新的算法。
4. 简化训练过程
许多开发者在构建自己的框架时,会选择简化常见的训练和测试流程,提供更高层次的接口。比如,自动化批量训练、验证过程、超参数调优等。你可以设计一个高层接口,简化训练过程:
python
class Trainer:
def __init__(self, model, train_loader, valid_loader, optimizer, loss_fn):
self.model = model
self.train_loader = train_loader
self.valid_loader = valid_loader
self.optimizer = optimizer
self.loss_fn = loss_fn
def train_one_epoch(self):
self.model.train()
total_loss = 0
for inputs, targets in self.train_loader:
self.optimizer.zero_grad()
outputs = self.model(inputs)
loss = self.loss_fn(outputs, targets)
loss.backward()
self.optimizer.step()
total_loss += loss.item()
return total_loss / len(self.train_loader)
def validate(self):
self.model.eval()
total_loss = 0
with torch.no_grad():
for inputs, targets in self.valid_loader:
outputs = self.model(inputs)
loss = self.loss_fn(outputs, targets)
total_loss += loss.item()
return total_loss / len(self.valid_loader)5. 性能优化
随着框架的开发,性能成为一个重要的考虑因素。你可以通过以下方式进行优化:
-
GPU 加速 :确保你的模型和数据能够利用 GPU 进行训练。在 PyTorch 中,可以通过
.to(device)将模型和数据移动到 GPU。 -
并行化 :如果你的模型训练需要处理大量数据,可以利用
DataParallel或DistributedDataParallel来并行训练。 -
混合精度训练 :使用 PyTorch 提供的混合精度训练功能(例如
torch.cuda.amp)来提高训练效率。
6. 框架模块化设计
设计时要考虑到框架的模块化和可扩展性,确保后期能轻松添加新功能。例如,分离训练、数据处理、优化器、损失函数等功能模块,保证框架的灵活性。
- 插件式设计:你可以设计插件系统,让开发者方便地扩展和使用自己的模块。例如,提供基础的训练模块,但允许用户通过插件添加自定义优化器、数据预处理方法等。
7. 文档与社区支持
- 文档:框架开发完成后,撰写详细的文档和教程至关重要。文档能够帮助其他开发者快速上手并贡献代码。
- 开源社区:考虑将你的框架开源,接受社区的反馈和贡献。这将帮助你发现问题并快速迭代。