论文地址: https://arxiv.org/pdf/2501.08457
论文题目:LARGE LANGUAGE MODELS FOR TEXT CLASSIFICATION: CASE STUDY AND COMPREHENSIVE REVIEW
哈喽,大家好,我是朗泽,最近在做大模型意图识别(可以)相关需求,今天分享一篇可以用于大模型技术综述的实证研究。这项研究在虚假新闻检测和员工位置分类两个典型场景中,对9款主流大模型与RoBERTa等传统方法展开了全面对比。结果发现:在复杂的多分类任务中,Llama3和GPT-4的表现甚至优于传统最优模型,但代价是更长的推理时间;而在简单二分类场景中,支持向量机等传统方法反而能以更少时间达成相当效果。研究还揭示了提示工程的显著影响------合适的提示策略可使模型性能提升超过10%,其中思维链与少样本提示的表现最为亮眼。
1. Abstract
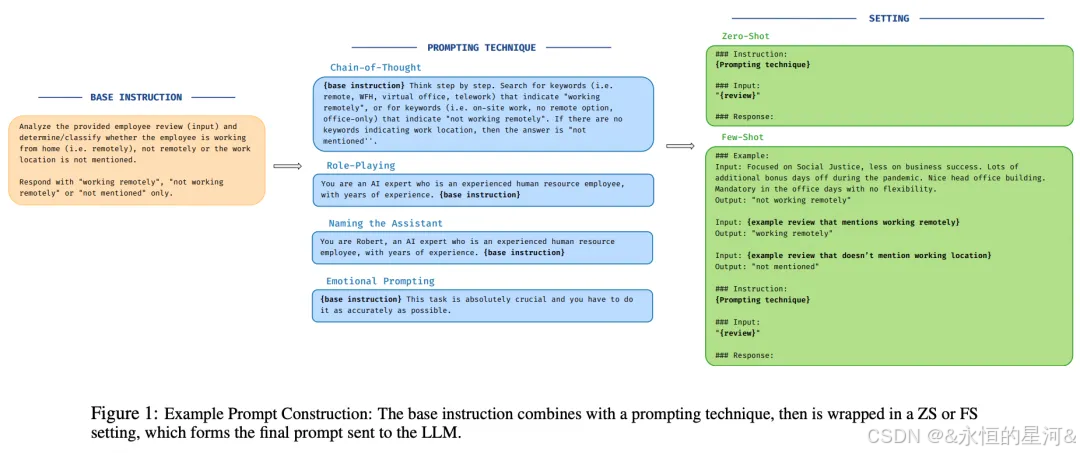
释放大型语言模型在数据分类领域的潜力,代表了自然语言处理中一个充满前景的新前沿。本研究通过两种不同分类场景------其一是基于在线发布的职位评论对员工工作地点进行分类(多类别分类),其二是将新闻文章分类为虚假或非虚假(二分类)------系统评估了不同大型语言模型与前沿深度学习及机器学习模型的性能表现。本文的分析涵盖了在规模、量化和架构上各具特色的多样化语言模型,探索了不同提示技术的影响,并以加权F1分数作为核心评估指标。同时,通过衡量各模型在性能(F1分数)与时间(推理响应时间)之间的权衡关系,为每个模型的实际适用性提供了更精细的解读。研究发现,提示策略的差异会引发模型响应的显著变化。尽管需要付出更长的推理时间代价,但大型语言模型(特别是Llama3和GPT-4)在复杂分类任务(如多类别分类)中能够超越传统方法;而在较简单的二分类任务中,基础机器学习模型则展现出更优的效能时间比。