在 Excel 中,正则表达式(通过 REGEXTEST、REGEXEXTRACT、REGEXREPLACE 等函数实现)是处理文本的强大工具,其核心作用是通过模式匹配对文本进行精准的查找、验证、提取或替换,大幅提升复杂文本处理的效率。
REGEXEXTRACT 抓取函数
REGEXREPLACE 替换函数
REGEXTEST 用于检查文本是否与指定的正则表达式模式匹配
正则表达式字符集
基础部分:
abc 包含字符,且按照文字先后关系
[def] 是否包含字符: d, e, f
[g-z] 从字符d到h是否被包含
开始结束类型 :
^The 开始是否为:The
end$ 结束是否为:end
[^xyz] 不存在字符: x, y, z
^[^A-Z] 开始字符不是在范围: a-m
匹配类型 :
. 匹配任何单个文本字串(不包含换行符)
\. 转义成是否存在.
[0-9] 任意单个数字
\d 任意单个数字
.{3} 任意3个字符构成
.{2,3} 最少2个字符构成,最大3个字符构成
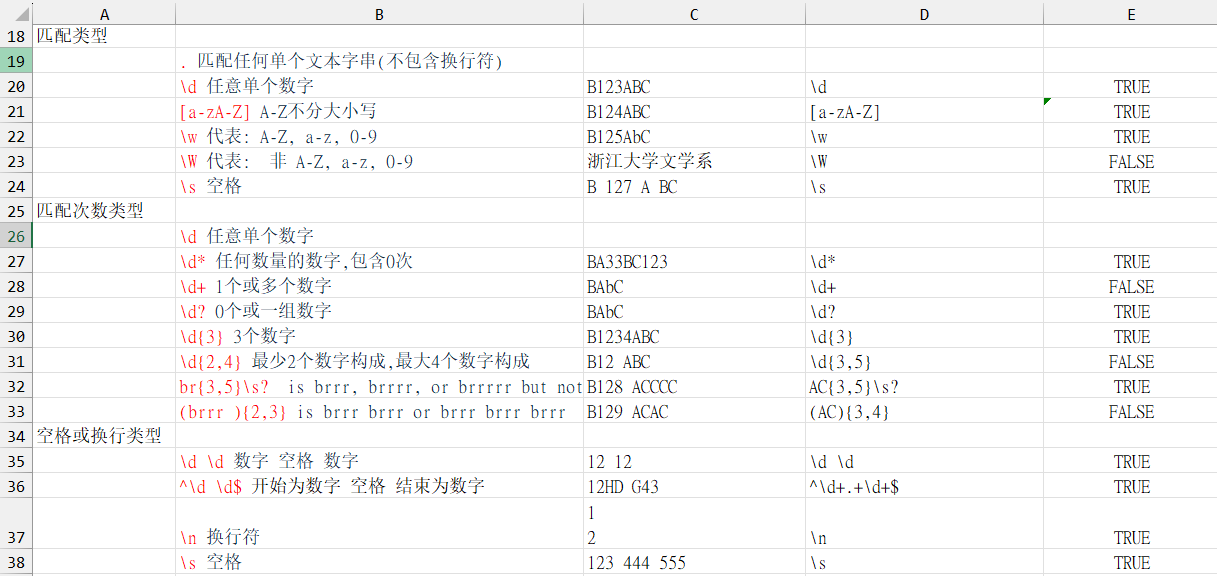
匹配类型
. 匹配任何单个文本字串(不包含换行符)
\d 任意单个数字
[a-zA-Z] A-Z不分大小写
\w 代表: A-Z, a-z, 0-9
\W 代表: 非 A-Z, a-z, 0-9
\s 空格
匹配次数类型
\d 任意单个数字
\d* 任何数量的数字,包含0次
\d+ 1个或多个数字
\d? 0个或一组数字
\d{3} 3个数字
\d{2,4} 最少2个数字构成,最大4个数字构成
br{3,5}\s? is brrr, brrrr, or brrrrr but not br or brr
(brrr ){2,3} is brrr brrr or brrr brrr brrr
空格或换行类型
\d \d 数字 空格 数字
^\d \d$ 开始为数字 空格 结束为数字
\n 换行符
\s 空格
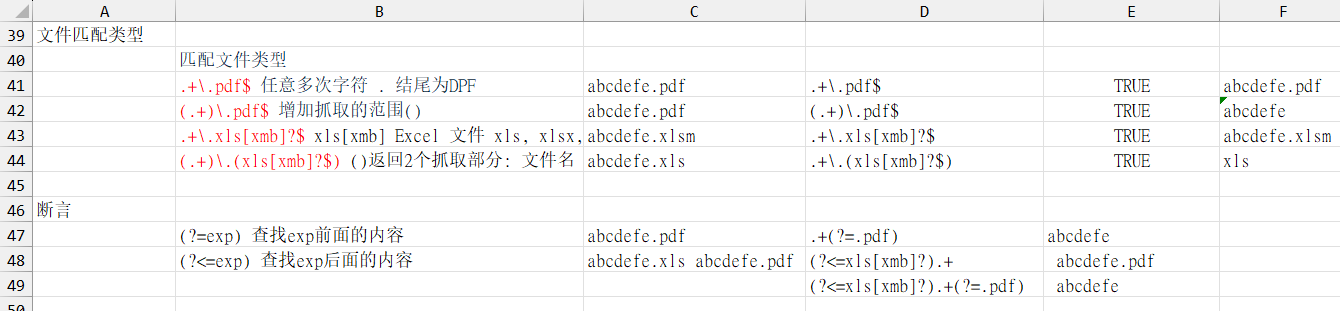
文件匹配类型
匹配文件类型
.+\.pdf$ 任意多次字符 . 结尾为DPF
(.+)\.pdf$ 增加抓取的范围()
.+\.xls[xmb]?$ xls[xmb] Excel 文件 xls, xlsx, xlsm, xlsb
(.+)\.(xls[xmb]?$) ()返回2个抓取部分: 文件名 & 文件类型
断言
(?=exp) 查找exp前面的内容
(?<=exp) 查找exp后面的内容
懒惰模式(非贪婪模式)
*?、+?、??、{n,m}? 量词后面加? 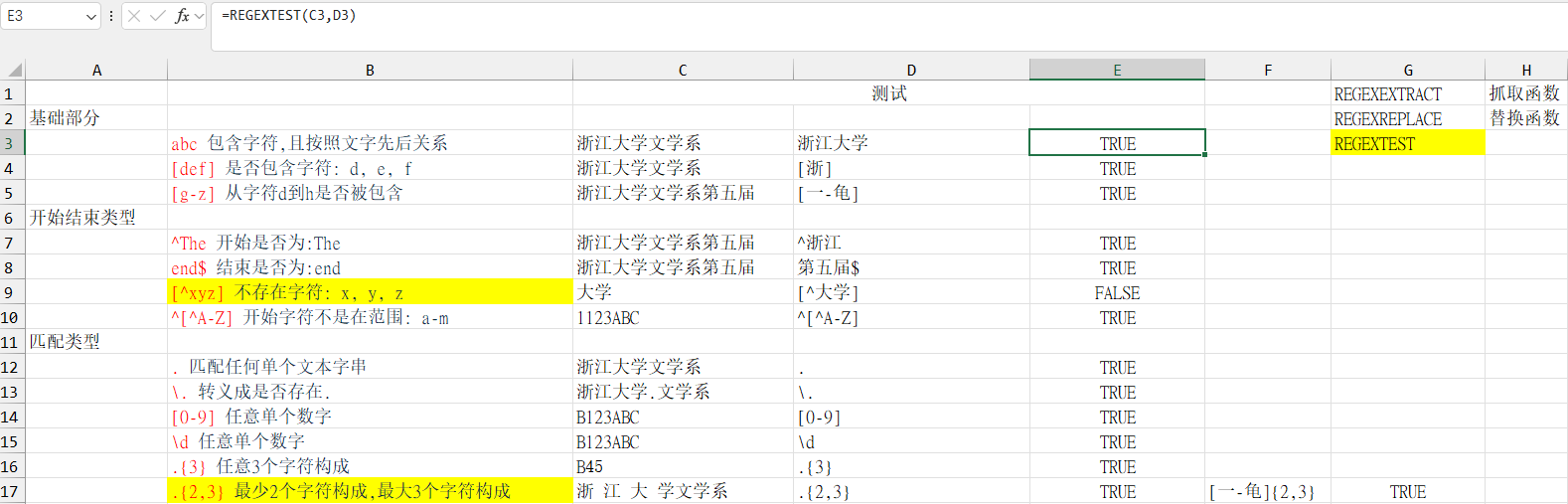

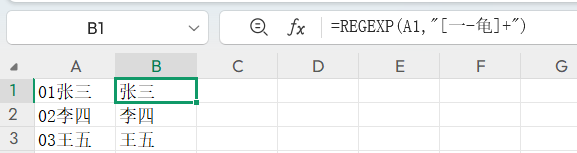
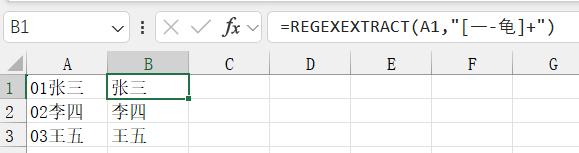
获取文本中的所有中文字符
=REGEXEXTRACT(A1,"[一-龟]+")获取文本中的所有字母、数字
=REGEXEXTRACT(A1,"[a-z]+")
=REGEXEXTRACT(A1,"[A-Z]+")
=REGEXEXTRACT(A1,"[0-9]+")MS函数:
案例一:
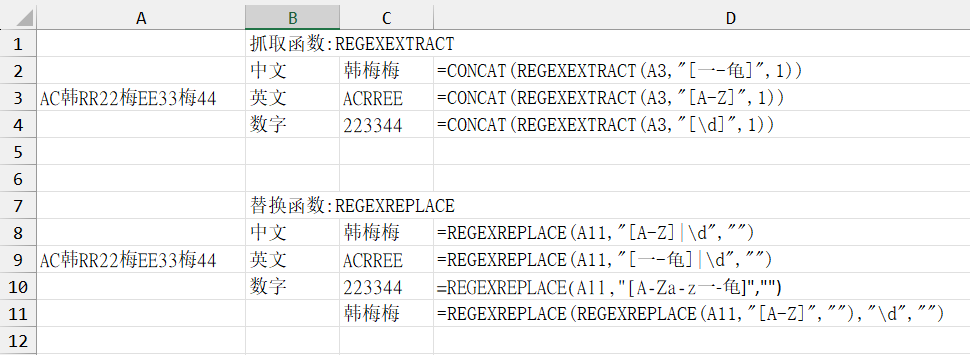
案例二:
{2,}:2个以上
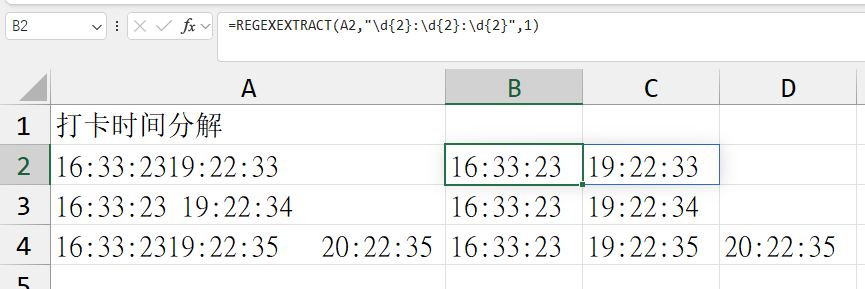
案例三:打卡时间分解
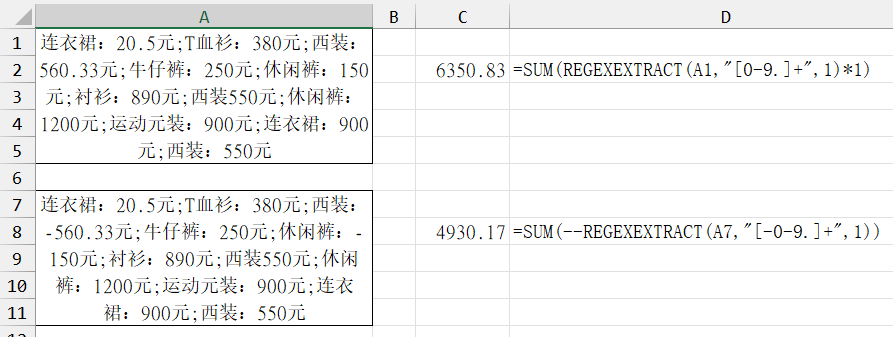
案例四:提取文本中小数点/负数的值并求和
-- 转数值,等同于*1
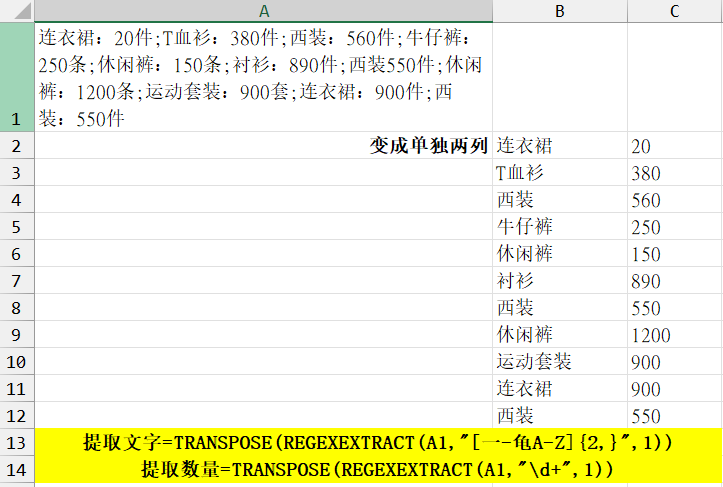
案例五:提取两个单元格的中文和数值至一列
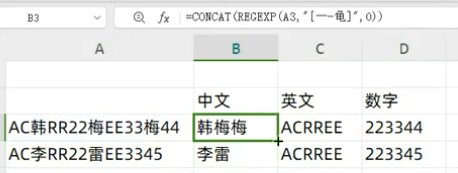
concat合并文本
=TRANSPOSE(REGEXEXTRACT(CONCAT(A1:A2),"[一-龟]+",1))
=TRANSPOSE(REGEXEXTRACT(CONCAT(A1:A2),"\d+",1))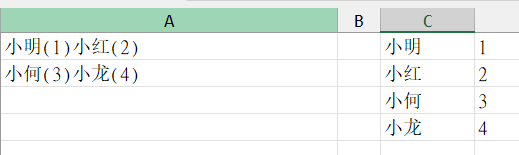
案例六:使用断言提取指定字符后面的值
(?=exp) 查找exp前面的内容
(?<=exp) 查找exp后面的内容
规范的内容1:
=REGEXEXTRACT(A2,"(?<=连衣裙:)\d+",1) # 固定字符串
=IFERROR(REGEXEXTRACT($A2,"(?<="&C$1&":)\d+")*1,"") # 动态字符串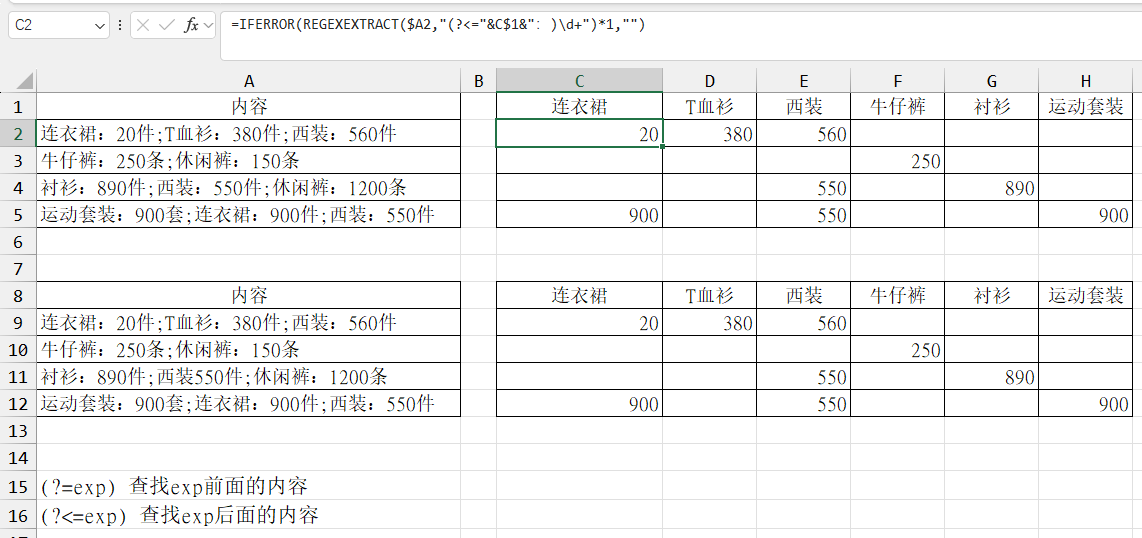
规范的内容2:
难度⭐⭐⭐
=REGEXEXTRACT($A2,"(?<="&B$1&":).+(?="&C$1&")",)
=REGEXEXTRACT($A2,"(?<="&C$1&":).+(?="&D$1&")")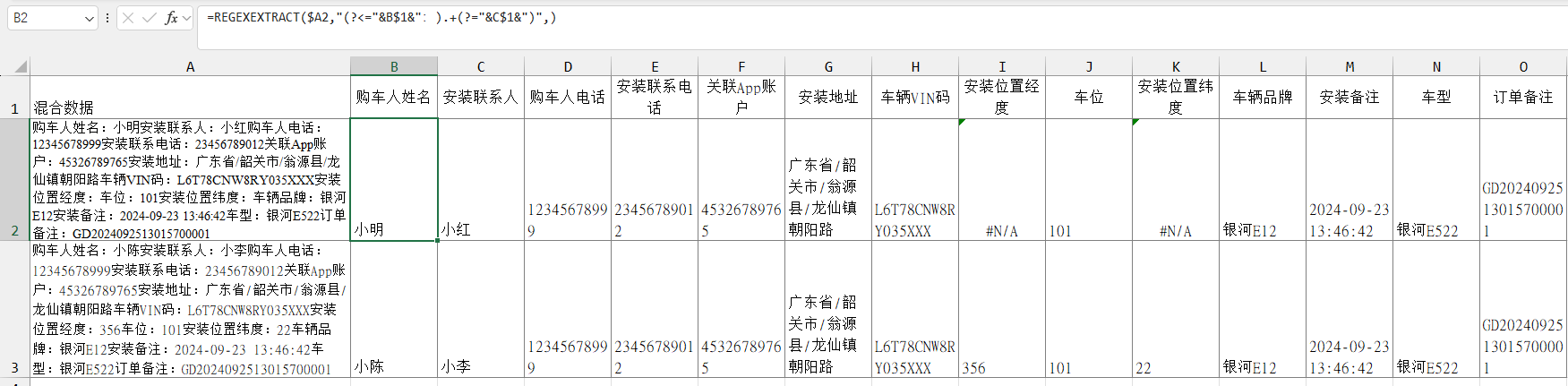
不规范的内容1:
. 匹配任何单个文本字串(不包含换行符)
\d? 0个或一组数字
.{2,3} 最少2个字符构成,最大3个字符构成
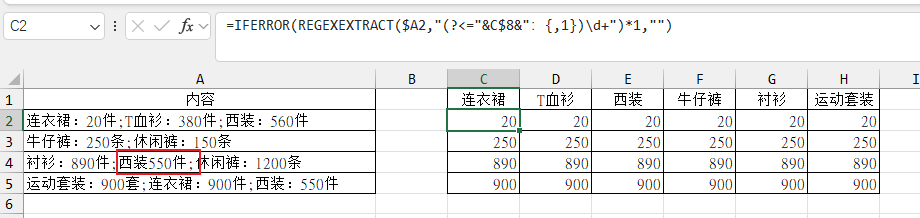
=IFERROR(REGEXEXTRACT($A2,"(?<="&C$8&".)\d+")*1,"")
=IFERROR(REGEXEXTRACT($A2,"(?<="&C$8&":?)\d+")*1,"")
=IFERROR(REGEXEXTRACT($A3,"(?<="&C$8&":{0,1})\d+")*1,"") 缺少:
不规范的内容2:
=IFERROR(--REGEXEXTRACT($A2,"(?<="&B$1&".{,3})[0-9.]+"),"")
不规范的内容3:
=IFERROR(--REGEXEXTRACT($A2,"(?<="&B$1&".{,3})[0-9.]+"),"")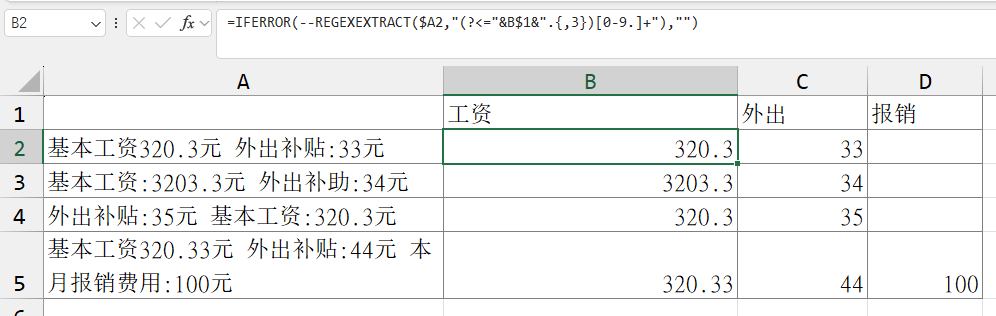
不规范的内容4:
=REGEXEXTRACT(B2,"\d+(?="&C$1&")")
=REGEXEXTRACT(B2,"\d+\*\d+")
案例七:非贪婪模式(懒惰模式)
*?、+?、??、{n,m}? 量词后面加? 转懒惰模式
\s 空格
=REGEXEXTRACT($A$2,"(?<="&B$1&":).+?\s",) # 获取第一个空格前的内容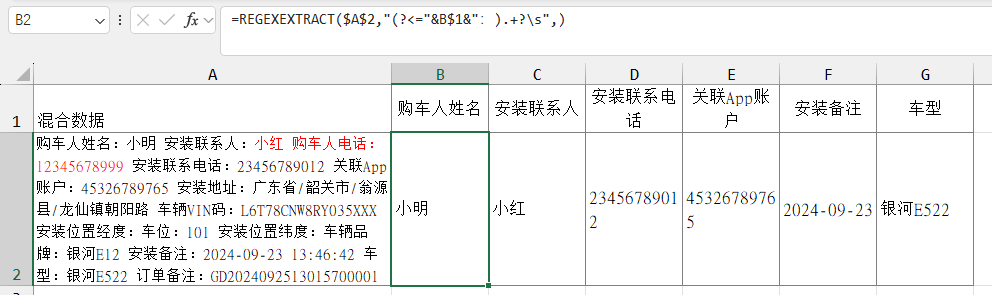
案例八:换行符
\n 换行符
. 匹配任何单个文本字串(不包含换行符)

WPS函数: