一、概述
目前从事机器学习平台Infra相关工作,业务繁忙,导致蛮久未更新,今天对搭建的平台进行简单测试:
首先不谈代码,简单聊一下模型训练链路,因为决定训练效率的,不仅在于算力本身,还在于数据与模型在存储、内存、显存之间的高效协调,分为几大步骤:
存储盘------>内存(CPU负责)
-
传输内容:基础权重(模型初始权重)、数据集(训练样本和标签)、模型结构定义(网络架构代码,超参数配置等)
-
核心技术:多进程并行数据加载
内存------>GPU显存(CPU负责)
-
内存中的数据处理:完整模型权重和结构传输到GPU,包括所有参数、权重矩阵、归一化层参数(全量传输);训练数据集流式传输(持续进行)
-
核心技术:cpu准备训练的下一次数据,异步传输,错误处理和传输重试机制;
GPU训练计算(GPU负责)
-
常驻数据区:模型权重参数+模型训练架构
-
动态计算区:前向传播(参数动态更新)、反向传播(各层梯度值、损失函数计算结果)、当前批次训练数据
CheckPoint异步落盘(CPU负责)
存储盘------>内存【该部分cpu负责,传输内容包括基础权重、数据集初版】------>GPU【导入基础权重+数据集训练,将训练中间量保存在显存中,异步落盘】
神经网络机器训练模型:
-
正向传播:使用pai0模型(参数总量固定的、隐藏层数超参数配置),根据采集数据集,更改初始参数(base0_params),此过程参数是动态变化的;
-
反向传播:使用生成的参数生成预测值同样本值进行比较,根据loss函数(关于各个参数的多层复合函数------>影响因素是隐藏层层数)的最小化法(比如梯度下降法),对正向传播中产生的静态参数进行调整,作为下此训练的参数,梯度(多维向量)就是多个参数的复合变化对loss值的影响"清单";
本质上是获取loss最小值的"最快下降方向";
二、Distributed Data Parallel(DDP)框架下的分布式训练测试
环境:裸金属+k8s+calico+PvcProvisor+nvidia-device-pluigin+kubeflow+prometheus/grafana+kuboard环境,对kubeflow的notebook-operator+juypter-web进行了简单二开,配置路由规则+vpn打通client和云集群;

图2.1 kubeflow登录界面
图2.2 集群Namespace展示
图2.3 kuboard界面展示(运维专用)
先不谈集群平台如何搭建,真的爬过蛮多坑(有人知道如何在部署是如何取消istio-system默认自动安装可以在评论区讨论下,实际项目中使用如下代码创建profile后取消"istio-injection"标签实现ns下的端口开放,一点都不优雅~);
python
def create_update_profile(self,username,cpu,memory,gpu,role):
"""create/update profile"""
validate_resource(cpu,"cpu")
validate_resource(memory,"memory")
validate_resource(gpu,"gpu")
profile_name = self.get_profile_name(username)
email = self.get_email(username)
profile_body = {
"apiVersion": "kubeflow.org/v1",
"kind": "Profile",
"metadata": {"name": profile_name},
"spec":{
"owner":{"kind":"User","name":email},
"resourceQuotaSpec": {
"hard": {
"limits.cpu": str(cpu),
"limits.memory": str(memory),
"nvidia.com/gpu": str(gpu)
}
}
}
}2.1 单机多卡测试
直接上代码,为了使训练结果可视化,加了debug输出,如下:
python
#!/opt/conda/envs/mlenv/bin/python3
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.utils.data import Dataset, DataLoader, DistributedSampler
import os
import time
class RandomDataset(Dataset):
def __init__(self, size=10000, input_dim=10, num_classes=2): # 增大数据集
self.data = torch.randn(size, input_dim)
self.label = torch.randint(0, num_classes, (size,))
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx], self.label[idx]
def train(local_rank, world_size):
os.environ["MASTER_ADDR"] = "127.0.0.1"
os.environ["MASTER_PORT"] = "29500"
os.environ["WORLD_SIZE"] = str(world_size)
os.environ["RANK"] = str(local_rank)
dist.init_process_group(backend='nccl')
torch.cuda.set_device(local_rank)
device = torch.device(f"cuda:{local_rank}")
# 确保每个rank有足够的数据
dataset = RandomDataset(size=1000000) # 更大的数据集
sampler = DistributedSampler(dataset, num_replicas=world_size, rank=local_rank, shuffle=True)
#调整batch size和数据加载器参数
dataloader = DataLoader(
dataset,
batch_size=5120, # 增大batch size
sampler=sampler,
num_workers=16, # 添加数据加载workers
pin_memory=True # 固定内存,加速数据传输
)
# 使用更复杂的模型确保有足够的计算量
class ComplexModel(torch.nn.Module):
def __init__(self):
super().__init__()
self.net = torch.nn.Sequential(
torch.nn.Linear(10, 512),
torch.nn.ReLU(),
torch.nn.Linear(512, 1024),
torch.nn.ReLU(),
torch.nn.Linear(1024, 2048),
torch.nn.ReLU(),
torch.nn.Linear(2048, 512),
torch.nn.ReLU(),
torch.nn.Linear(512, 256),
torch.nn.ReLU(),
torch.nn.Linear(256, 128),
torch.nn.ReLU(),
torch.nn.Linear(128, 2)
)
def forward(self, x):
return self.net(x)
model = ComplexModel().to(device)
ddp_model = DDP(model, device_ids=[local_rank])
optimizer = torch.optim.SGD(ddp_model.parameters(), lr=0.001)
criterion = torch.nn.CrossEntropyLoss()
# 训练循环 - 添加详细监控
for epoch in range(9): # 增加epoch数
sampler.set_epoch(epoch)
total_loss = 0.0
batch_count = 0
#添加时间监控
epoch_start = time.time()
for batch_idx, (x, y) in enumerate(dataloader):
batch_start = time.time()
x, y = x.to(device, non_blocking=True), y.to(device, non_blocking=True)
# 前向传播
outputs = ddp_model(x)
loss = criterion(outputs, y)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
batch_count += 1
# 每个rank都打印批次信息
if batch_idx % 50 == 0: # 更频繁的打印
batch_time = time.time() - batch_start
current_memory = torch.cuda.memory_allocated(device) / 1024 ** 2
print(f"Rank {local_rank}: Epoch {epoch}, Batch {batch_idx}, "
f"Loss: {loss.item():.4f}, Time: {batch_time:.3f}s, "
f"Memory: {current_memory:.2f}MB")
epoch_time = time.time() - epoch_start
avg_loss = total_loss / batch_count
# 所有rank都打印epoch信息
print(f"Rank {local_rank}: Epoch {epoch + 1} completed, "
f"Avg Loss: {avg_loss:.4f}, Epoch Time: {epoch_time:.2f}s")
# 同步点,确保所有rank完成当前epoch
dist.barrier()
# 清理
dist.destroy_process_group()
if __name__ == '__main__':
world_size = torch.cuda.device_count()
print(f"检测到 {world_size} 个GPU")
mp.spawn(
train,
args=(world_size,),
nprocs=world_size,
join=True
)
#启动命令
chmod +x onemachine.py
./onemachine.py
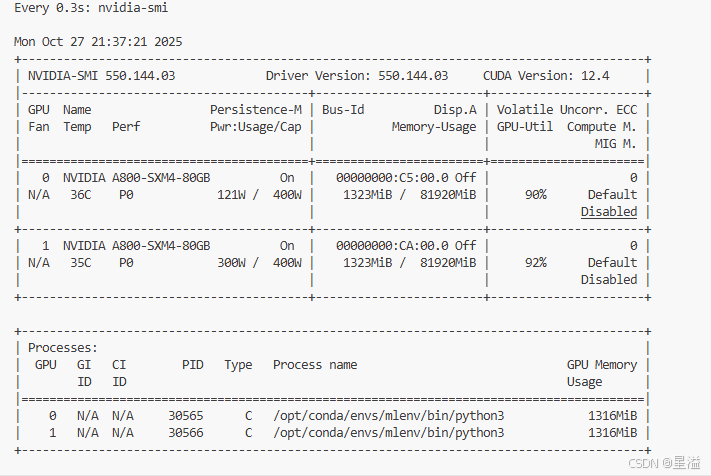
图2.4 单机多卡训练展示
2.2 多机多卡测试
- 多机多卡训练前,先通信测试(默认走ncll)
python
#!/usr/bin/env python3
import os
import torch
import torch.distributed as dist
import time
def connection_demo():
"""测试节点联通性"""
#从环境变量中获取配置
world_size = int(os.environ.get("WORLD_SIZE", 1))
rank = int(os.environ.get("RANK", 0))
local_rank = int(os.environ.get("LOCAL_RANK", 0))
print(f"节点{rank}(本地rank {local_rank} 开始初始化...)")
#初始化分布式环境
dist.init_process_group(backend='nccl', init_method='env://')
print(f"节点{rank}初始化完成")
#测试张量通信
if rank == 0:
#主节点发送数据
tensor = torch.ones(3,3).cuda(local_rank)*(rank+1)
print(f"主节点发送:{tensor}")
else:
tensor = torch.zeros(3,3).cuda(local_rank)
#广播张量
dist.broadcast(tensor,src=0)
print(f"节点{rank} 接收:{tensor}")
#测试all-reduce操作
local_tensor = torch.ones(2,2).cuda(local_rank) * (local_rank+1)
print(f"节点{rank} 本地张量:{local_tensor}")
dist.all_reduce(local_tensor,op=dist.ReduceOp.SUM)
print(f"节点{rank} 全局和:{local_tensor}")
#清理
dist.destroy_process_group()
print(f"节点{rank}测试完成")
if __name__ == '__main__':
connection_demo()
##启动命令
torchrun --nnodes=2 --nproc_per_node=1 --node_rank=0 --master_addr=10.233.97.226 --master_port=29500 netconnection.py
torchrun --nnodes=2 --nproc_per_node=1 --node_rank=1 --master_addr=10.233.97.226 --master_port=29500 netconnection.py
#多个主机上启动该命令:--nnodes:代表集群节点数量;--nproc_per_node:单个节点的GPU数量;--node_rank:节点编号;master_addr:主节点ip; 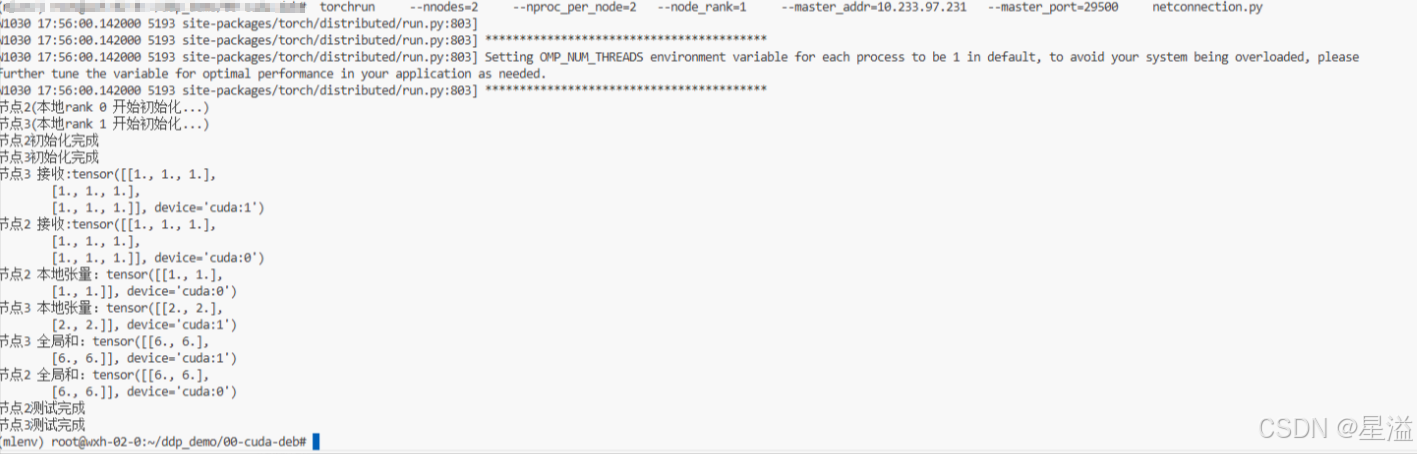
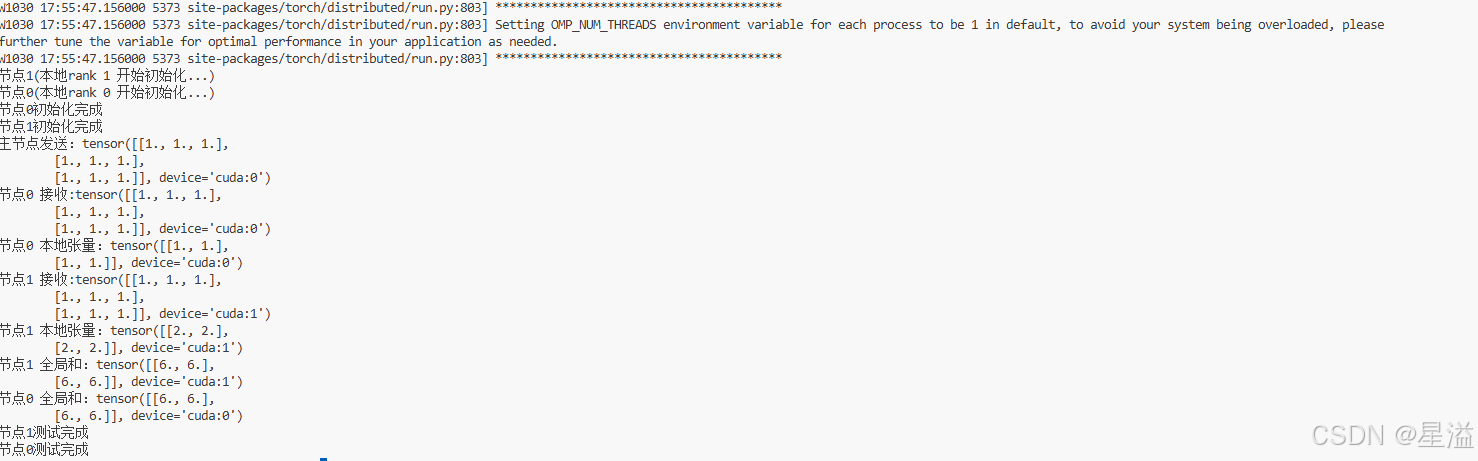
图2.5 多机多卡通信测试成功
- 训练测试
python
#!/usr/bin/env python3
import os
import torch
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.utils.data import Dataset, DataLoader, DistributedSampler
# 数据集和模型保持不变
class RandomDataset(Dataset):
def __init__(self, size=100000, input_dim=10):
self.data = torch.randn(size, input_dim)
self.label = torch.randint(0, 2, (size,))
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx], self.label[idx]
class SimpleModel(torch.nn.Module):
def __init__(self):
super().__init__()
self.net = torch.nn.Sequential(
torch.nn.Linear(10, 512),
torch.nn.ReLU(),
torch.nn.Linear(512, 1024),
torch.nn.ReLU(),
torch.nn.Linear(1024, 2048),
torch.nn.ReLU(),
torch.nn.Linear(2048, 512),
torch.nn.ReLU(),
torch.nn.Linear(512, 256),
torch.nn.ReLU(),
torch.nn.Linear(256, 128),
torch.nn.ReLU(),
torch.nn.Linear(128, 2)
)
def forward(self, x):
return self.net(x)
def train():
local_rank = int(os.environ["LOCAL_RANK"])
torch.cuda.set_device(local_rank)
device = torch.device(f"cuda:{local_rank}")
# 初始化分布式
dist.init_process_group(backend='nccl')
world_size = dist.get_world_size()
global_rank = dist.get_rank()
# 数据集
dataset = RandomDataset()
sampler = DistributedSampler(dataset, num_replicas=world_size, rank=global_rank)
dataloader = DataLoader(dataset, batch_size=10240, sampler=sampler,
num_workers=4, pin_memory=True)
model = SimpleModel().to(device)
ddp_model = DDP(model, device_ids=[local_rank], find_unused_parameters=False)
optimizer = torch.optim.SGD(ddp_model.parameters(), lr=0.01)
criterion = torch.nn.CrossEntropyLoss()
for epoch in range(9):
sampler.set_epoch(epoch)
total_loss = 0
for x, y in dataloader:
x, y = x.to(device, non_blocking=True), y.to(device, non_blocking=True)
optimizer.zero_grad()
loss = criterion(ddp_model(x), y)
loss.backward()
optimizer.step()
total_loss += loss.item()
if global_rank == 0:
print(f"Epoch {epoch} finished, Avg Loss: {total_loss/len(dataloader):.4f}")
dist.destroy_process_group()
# local_rank = int(os.environ["LOCAL_RANK"])
# torch.cuda.set_device(local_rank)
# device = torch.device(f"cuda:{local_rank}")
#
# dist.init_process_group(backend='nccl')
#
# world_size = dist.get_world_size()
# global_rank = dist.get_rank()
#
# print(f"[Debug] global_rank={global_rank}, local_rank={local_rank}, world_size={world_size}")
#
# dataset = RandomDataset()
# sampler = DistributedSampler(dataset, num_replicas=world_size, rank=global_rank)
# dataloader = DataLoader(dataset, batch_size=1024, sampler=sampler,
# num_workers=4, pin_memory=True)
#
# model = SimpleModel().to(device)
# ddp_model = DDP(model, device_ids=[local_rank], find_unused_parameters=False)
if __name__ == "__main__":
train()
#启动命令
#主
torchrun --nproc_per_node=2 --nnodes=2 --node_rank=0 --master_addr=10.233.97.231 --master_port=29501 manymmchine.py
#从
torchrun --nproc_per_node=2 --nnodes=2 --node_rank=1 --master_addr=10.233.97.231 --master_port=29501 manymmchine.py 
图2.6 主节点机多卡训练展示(node_rank=0)
图2.7 从节点机多卡训练展示(node_rank=1)
三、总结
PyTorch DDP框架多机多卡分布式训练测试完成。
路漫漫兮修远兮,come on~~
四、参考文档
1、分布式数据并行入门 | PyTorch stable -- Pytorch官方文档|PyTorch教程|PyTorch中文
2、kubernetes-client/python: Official Python client library for kubernetes
3、极致压榨GPU算力:开发、训练、推理 AI 全链路如何提效 - 知乎
4、Kubeflow