博主介绍:✌全网粉丝50W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅
2、大数据、计算机专业选题(Python/Java/大数据/深度学习/机器学习)(建议收藏)✅
1、项目介绍
技术栈:
Python语言、Flask框架、selenium爬虫框架、MySQL数据库、Echarts可视化、数据清洗
2、项目界面
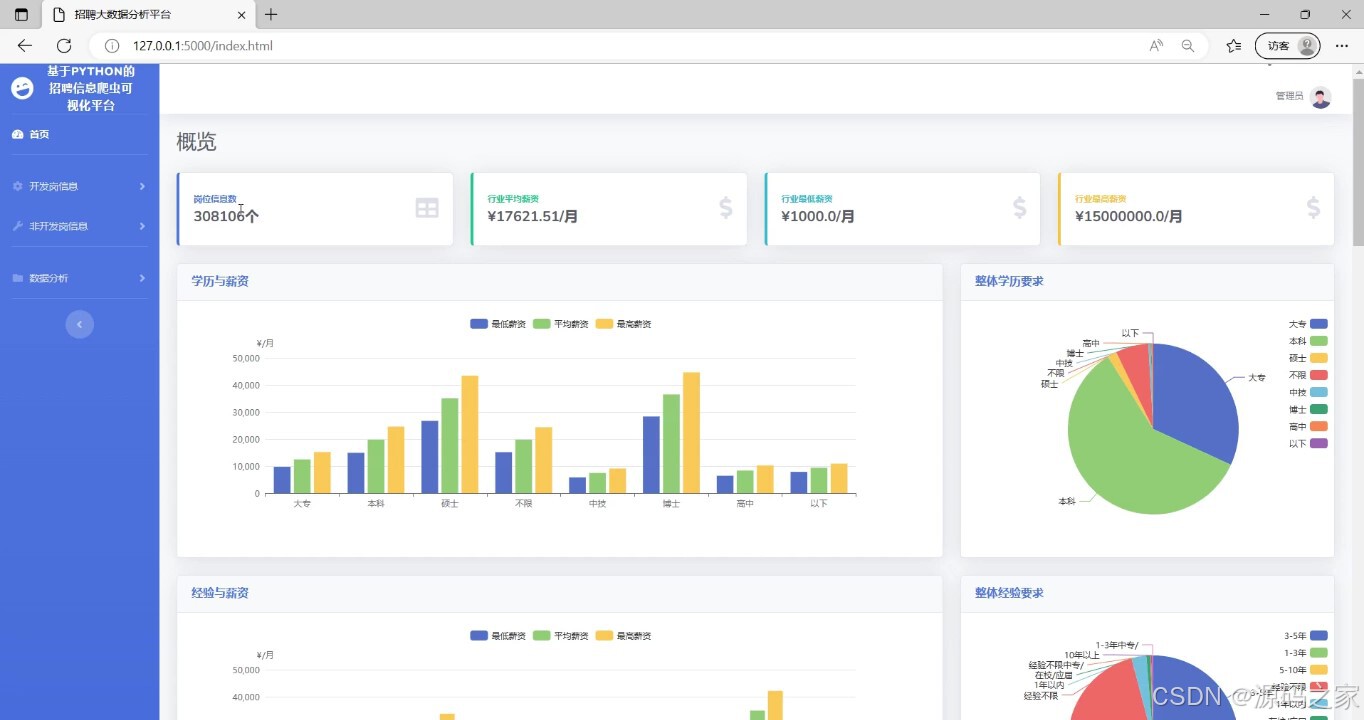
(1)数据大屏
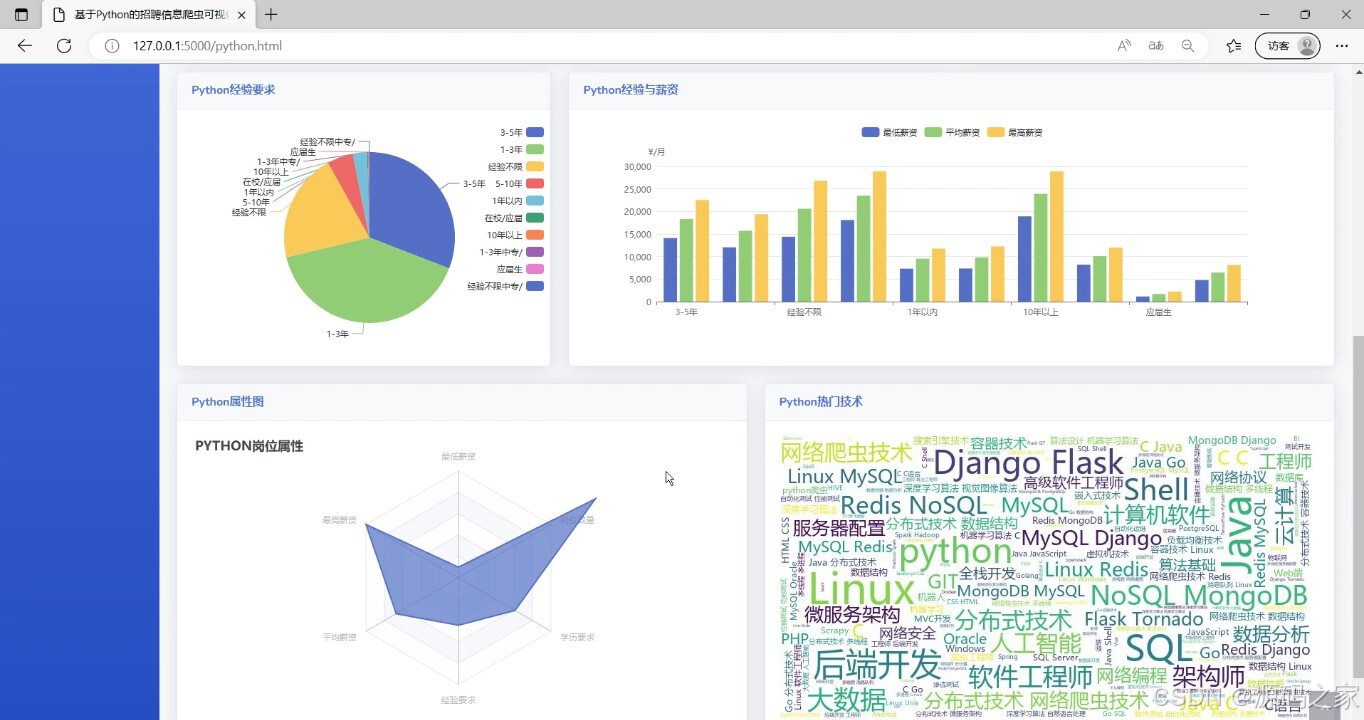
(2)详细分析
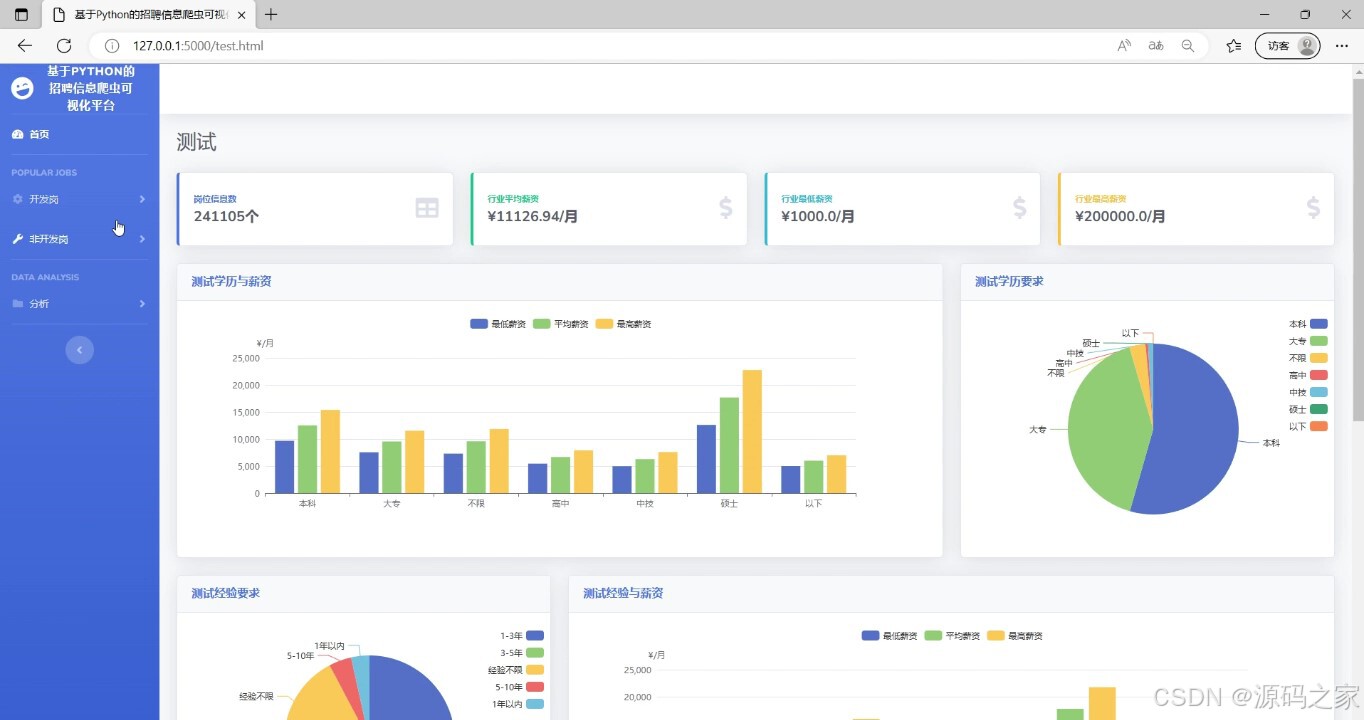
(3)测试岗位数据分析
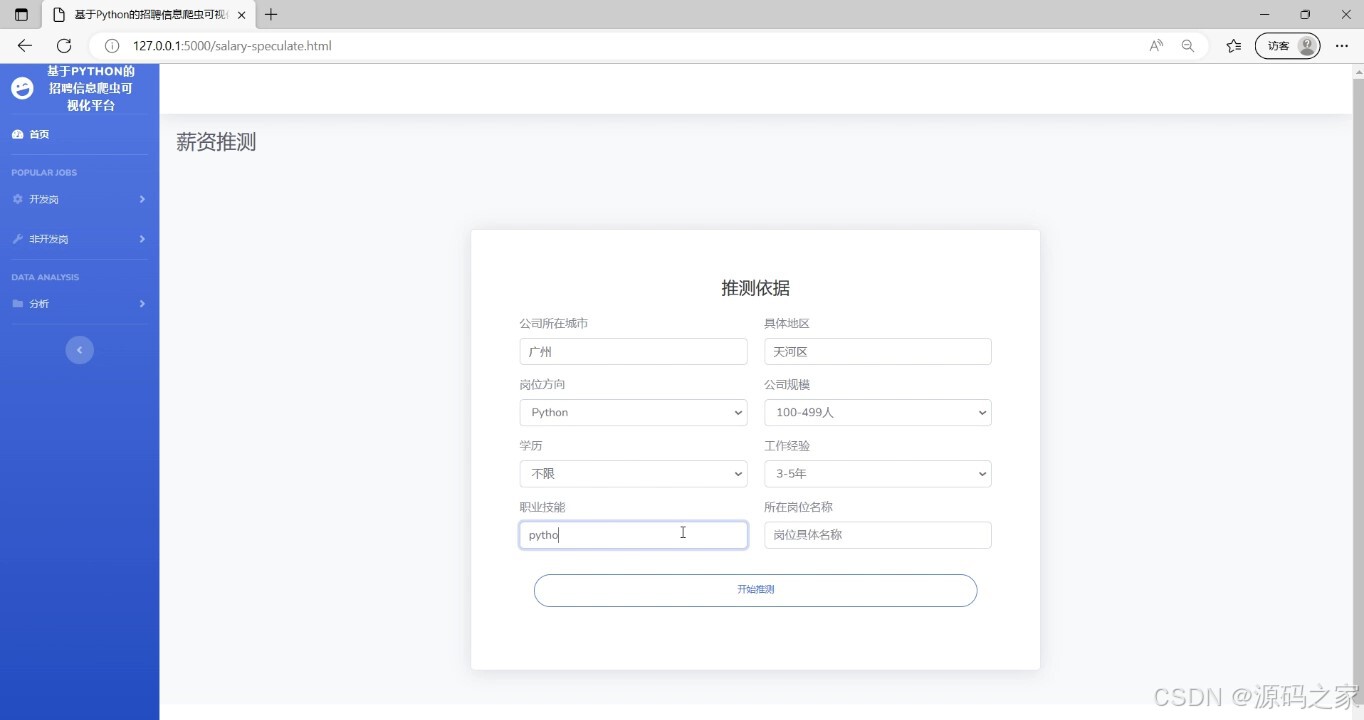
(4)薪资预测
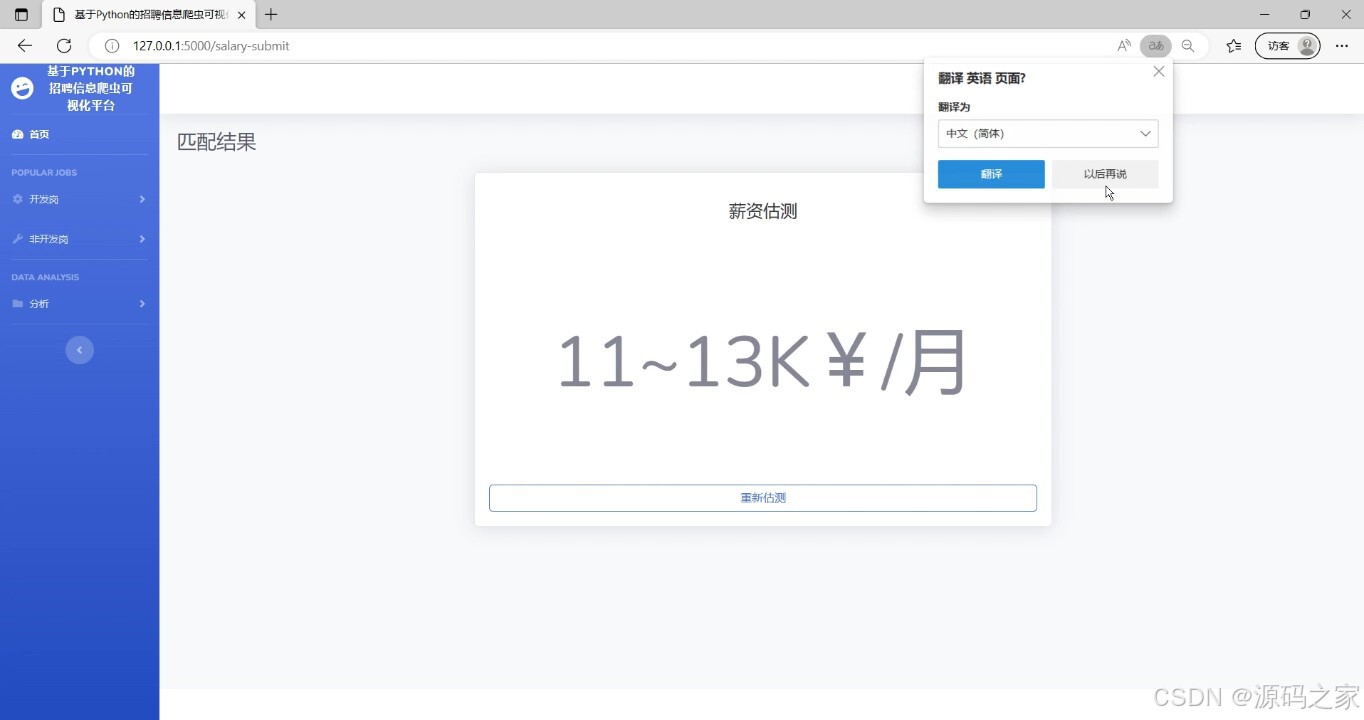
(5)薪资预测结果
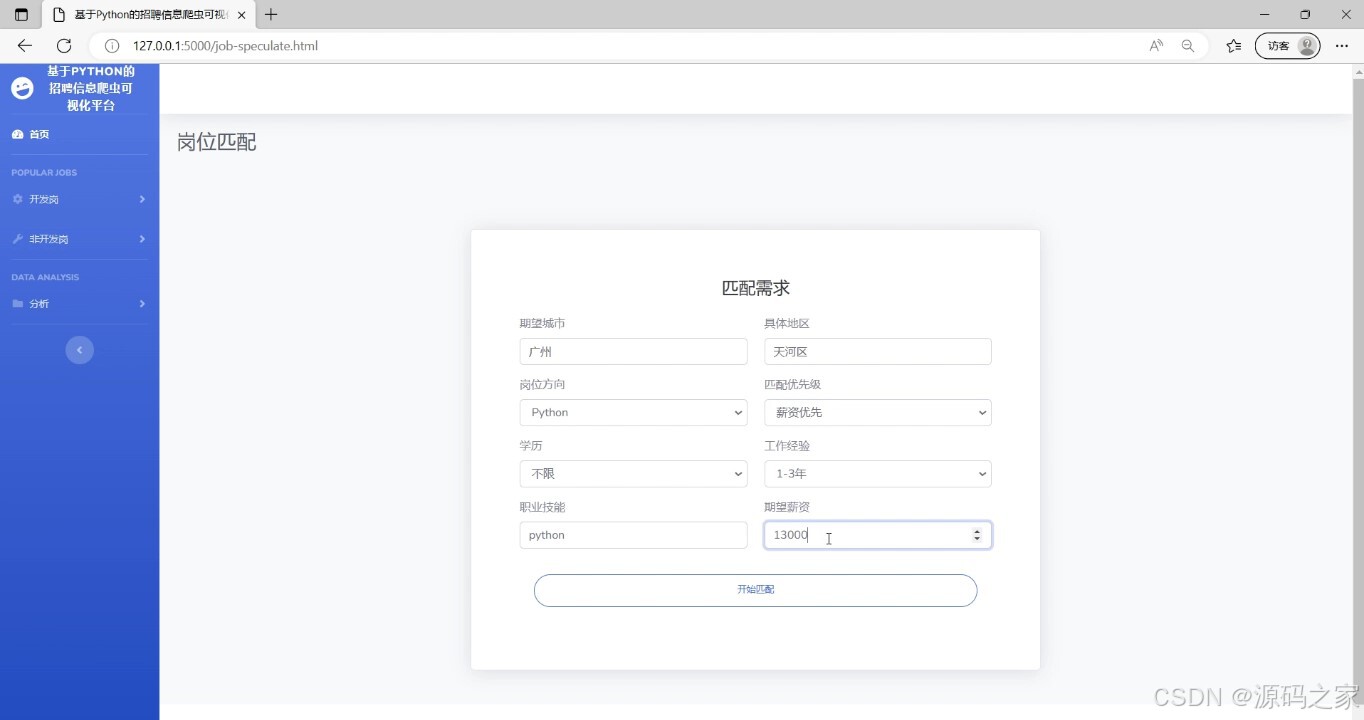
(6)岗位匹配推荐
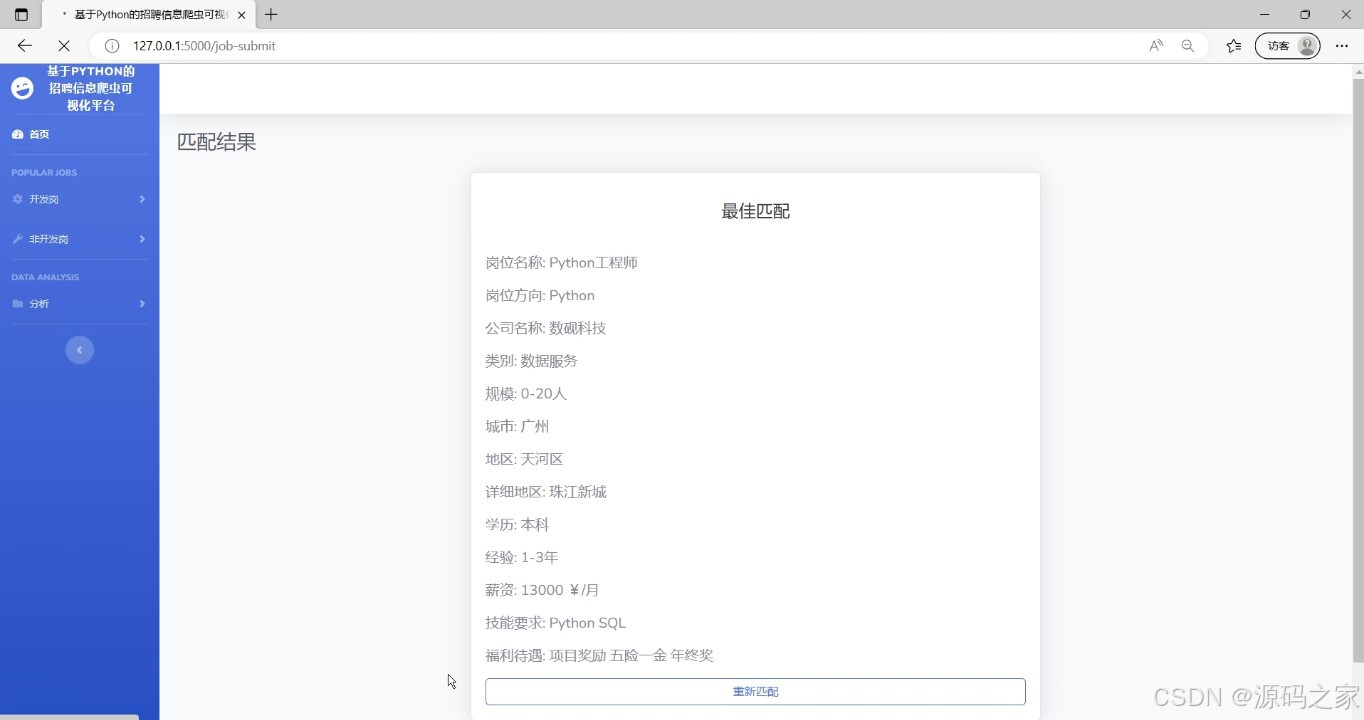
(7)岗位匹配推荐
3、项目说明
摘 要
如今时代,人们获取信息的方式已经从传统媒体如电视、报纸、书籍、信件等转变为以互联网为主要来源,这促进了信息的快速更新和获取,与此同时,计算机的存储能力和复杂算法的飞速发展,导致数据量在近年是指数级增长,导致各行各业的决策越来越依赖于数据,从"业务驱动"向"数据驱动"转变。因此,我们需要充分利用数据的海量处理和智能分析能力,准确抓取时代的热点数据,并在此基础上构建高效率的分析系统。
本论文旨在通过使用Python语言和网络爬虫技术爬取BOSS直聘网站的招聘数据,并对数据进行清洗和持久化保存,以研究市场上招聘信息的趋势和分布情况。使用Flask框架作为后端技术,将数据库中的数据呈现给前端展示,借助基于前端框架的应用,并结合图表展示工具ECharts,将数据以饼图、条形图等形式进行可视化展示。主要展示了招聘信息不同岗位的招聘情况和的数量分布、薪资分布情况以及关键词的分布情况。通过数据分析和可视化展示,得出如下结论:不同城市和行业的招聘信息数量和薪资水平有明显差异,而不同的招聘职位则有不同的职能和技能要求。因此,这些数据和分析结果对于个人求职者和企业招聘者提供了有益的参考。
关键词: python;招聘;数据分析;可视化
本文的主要工作的实现一个针对boss招聘网站的数据进行爬取分析,为求职者收集岗位招聘信息并进行可视化的分析,提高求职效率。爬虫和数据分析基于Python语言,简单易用导出数据存入csv文件中,通过pandas进行数据分析,并用matplotlib进行可视化展示数据分析结果。
本文首先阐述了选择该课题的背景和意义,而后介绍了国内外研究现状,分别针对爬虫和数据分析和可视化的国内外研究现状做了简单的介绍,接着介绍了课题研究的主要内容和组织结构。最后再下面几章中介绍了爬虫设计以及数据分析的实现过程。
本文通过细致的需求分析和脚本设计,爬取到所需要的招聘网站职位信息,对提取后的数据进行存储后进行数据清洗,将职位地区分布、薪资标准以及岗位学历要求进行图形化展示。系统主要分为数据爬取、数据分析和分析结果图形化展示三个功能模块。
在系统的视线中,对数据的爬取、数据分析和分析结果图形化展示三个功能进行了相关的阐述。其中,数据爬取模块主要实现了对boss招聘网站进行爬取,获得页面内容后提取所需的信息并存储到CSV文件中等功能;数据分析模块主要实现了根据提取出的职位数据相关信息对其进行处理,对筛选条件统计进行合并分析;分析结果图形化展示模块主要实现了对数据分析模块中的分析结果进行图形化展示,包括数据分析师岗位招聘的地区分布、薪资分布以及岗位学历要求等进行展示。爬取分析完成后,对数据可视化进行了实际的验证,基本符合了实际运行的需求,可为求职者提供实际的帮助。
综合上述,本文首先对基于Python对职位数据的爬取与分析进行了系统的需求分析,在需求分析的基础上进行了爬虫脚本的设计和实现,最终完成了对职位数据的分析,并实现了分析结果的图形化展示,达到了预期目标。
4、核心代码
python
from selenium import webdriver
from bs4 import BeautifulSoup
import mysql
class Spider(object):
def __init__(self):
# 创建数据库对象
self.__sql = mysql.MySql()
# 无头浏览器开启
self.__driver = webdriver.Chrome('spider/chromedriver.exe')
# 隐式等待
self.__driver.implicitly_wait(20)
# 设置需要爬取的 【关键词】
#self.__keyword = ['c', 'java', 'python', 'web前端', '.net', 'u3d', 'c#', 'c++', '算法', 'ios', 'Android']
#self.__keyword = ['.net', 'u3d', 'c#', 'c++', '算法', 'ios', 'Android']
#self.__keyword = ['测试', '运维','算法', 'ios', 'Android']
self.__keyword = ['python']
# self.__keyword = ['python', '算法', '测试']
# self.__keyword = ['Android']
def __del__(self):
# 关闭无头浏览器,减少内存损耗
self.__driver.quit()
# 设置爬取关键词
def setKeyword(self, keyword):
self.__keyword = []
if isinstance(keyword, list):
self.__keyword = keyword
else:
var = str(keyword)
var.strip()
if " " in var:
keyword_list = var.split(' ')
self.__keyword = keyword_list
else:
self.__keyword.append(var)
# 获取所有关键词
def getKeyword(self):
return self.__keyword
# 爬虫方法
def run(self):
print(">>>开始获取...")
# 城市json
# 在下方设置需要爬取的【城市】
cities = [{"name": "北京", "code": 101010100, "url": "/beijing/"},
{"name": "上海", "code": 101020100, "url": "/shanghai/"},
]
# 总记录数
all_count = 0
# 关键词爬取
for key in self.__keyword:
print('>>>当前获取关键词: "{}"'.format(key))
# 单个关键词爬取记录数
key_count = 0
# 每个城市爬取
for city in cities:
print('>>>当前获取城市: "{}"'.format(city['name']))
# 记录每个城市爬取数据数目
city_count = 0
# 只获取前十页
urls = ['https://www.zhipin.com/c{}/?query={}&page={}&ka=page-{}'
.format(city['code'], key, i, i) for i in range(1, 11)]
# 逐条解析
for url in urls:
self.__driver.get(url)
# 获取源码,解析
html = self.__driver.page_source
bs = BeautifulSoup(html, 'html.parser')
# 获取搜索框,用于判断是否被异常检测
flag = bs.find_all('div', {'class': 'inner home-inner'})
# 主要信息获取
job_all = bs.find_all('div', {"class": "job-primary"})
# 解析页面
for job in job_all:
# 工作名称
job_name = job.find('span', {"class": "job-name"}).get_text()
# 工作地点
job_place = job.find('span', {'class': "job-area"}).get_text()
# 工作公司
job_company = job.find('div', {'class': 'company-text'}).find('h3', {'class': "name"}).get_text()
# 公司规模
job_scale = job.find('div', {'class': 'company-text'}).find('p').get_text()
# 工作薪资
job_salary = job.find('span', {'class': 'red'}).get_text()
# 工作学历
job_education = job.find('div', {'class': 'job-limit'}).find('p').get_text()[-2:]
# 工作经验
job_experience = job.find('div', {'class': 'job-limit'}).find('p').get_text()
# 工作标签
job_label = job.find('a', {'class': 'false-link'}).get_text()
# 技能要求
job_skill = job.find('div', {'class': 'tags'}).get_text().replace("\n", " ").strip()
# 福利
job_welfare = job.find('div', {'class': 'info-desc'}).get_text().replace(",", " ").strip()
#职位类型 追加
type=key
# 数据存储
self.__sql.saveData(job_name, job_place, job_company, job_scale, job_salary, job_education,
job_experience,
job_label,
job_skill,
job_welfare,type)
# 统计记录数
print(job_name, job_place, job_company, job_scale, job_salary, job_education,
job_experience,
job_label,
job_skill,
job_welfare)
city_count = city_count + 1
key_count = key_count + city_count
all_count = all_count + key_count
print('>>>城市: "{}" 获取完成...获取数据: {} 条'.format(city['name'], city_count))
print('>>>关键词: "{}" 获取完成...获取数据: {} 条'.format(key, key_count))
print(">>>全部关键词获取完成...共获取 {} 条数据".format(all_count))🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目编程以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看 👇🏻获取联系方式👇🏻