
【作者主页】Francek Chen
【专栏介绍】⌈ ⌈ ⌈PyTorch深度学习 ⌋ ⌋ ⌋ 深度学习 (DL, Deep Learning) 特指基于深层神经网络模型和方法的机器学习。它是在统计机器学习、人工神经网络等算法模型基础上,结合当代大数据和大算力的发展而发展出来的。深度学习最重要的技术特征是具有自动提取特征的能力。神经网络算法、算力和数据是开展深度学习的三要素。深度学习在计算机视觉、自然语言处理、多模态数据分析、科学探索等领域都取得了很多成果。本专栏介绍基于PyTorch的深度学习算法实现。
【GitCode】专栏资源保存在我的GitCode仓库:https://gitcode.com/Morse_Chen/PyTorch_deep_learning。
文章目录
我们继续实现词嵌入(word2vec)中定义的跳元语法模型。然后,我们将在PTB数据集上使用负采样预训练word2vec。
首先,让我们通过调用d2l.load_data_ptb函数来获得该数据集的数据迭代器和词表,该函数在用于预训练词嵌入的数据集中进行了描述。
python
import math
import torch
from torch import nn
from d2l import torch as d2l
batch_size, max_window_size, num_noise_words = 512, 5, 5
data_iter, vocab = d2l.load_data_ptb(batch_size, max_window_size,
num_noise_words)一、跳元模型
我们通过嵌入层和批量矩阵乘法实现了跳元模型。首先,让我们回顾一下嵌入层是如何工作的。
(一)嵌入层
如序列到序列学习(seq2seq)中所述,嵌入层将词元的索引映射到其特征向量。该层的权重是一个矩阵,其行数等于字典大小(input_dim),列数等于每个标记的向量维数(output_dim)。在词嵌入模型训练之后,这个权重就是我们所需要的。
python
embed = nn.Embedding(num_embeddings=20, embedding_dim=4)
print(f'Parameter embedding_weight ({embed.weight.shape}, '
f'dtype={embed.weight.dtype})')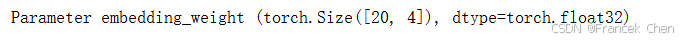
嵌入层的输入是词元(词)的索引。对于任何词元索引 i i i,其向量表示可以从嵌入层中的权重矩阵的第 i i i行获得。由于向量维度(output_dim)被设置为4,因此当小批量词元索引的形状为(2,3)时,嵌入层返回具有形状(2,3,4)的向量。
python
x = torch.tensor([[1, 2, 3], [4, 5, 6]])
embed(x)
(二)定义前向传播
在前向传播中,跳元语法模型的输入包括形状为(批量大小,1)的中心词索引center和形状为(批量大小,max_len)的上下文与噪声词索引contexts_and_negatives,其中max_len在用于预训练词嵌入的数据集中定义。这两个变量首先通过嵌入层从词元索引转换成向量,然后它们的批量矩阵相乘返回形状为(批量大小,1,max_len)的输出。输出中的每个元素是中心词向量和上下文或噪声词向量的点积。
python
def skip_gram(center, contexts_and_negatives, embed_v, embed_u):
v = embed_v(center)
u = embed_u(contexts_and_negatives)
pred = torch.bmm(v, u.permute(0, 2, 1))
return pred 让我们为一些样例输入打印此skip_gram函数的输出形状。
python
skip_gram(torch.ones((2, 1), dtype=torch.long),
torch.ones((2, 4), dtype=torch.long), embed, embed).shape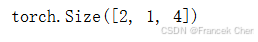
二、训练
在训练带负采样的跳元模型之前,我们先定义它的损失函数。
(一)二元交叉熵损失
根据近似训练中负采样损失函数的定义,我们将使用二元交叉熵损失。
python
class SigmoidBCELoss(nn.Module):
# 带掩码的二元交叉熵损失
def __init__(self):
super().__init__()
def forward(self, inputs, target, mask=None):
out = nn.functional.binary_cross_entropy_with_logits(
inputs, target, weight=mask, reduction="none")
return out.mean(dim=1)
loss = SigmoidBCELoss()回想一下我们在用于预训练词嵌入的数据集中对掩码变量和标签变量的描述。下面计算给定变量的二进制交叉熵损失。
python
pred = torch.tensor([[1.1, -2.2, 3.3, -4.4]] * 2)
label = torch.tensor([[1.0, 0.0, 0.0, 0.0], [0.0, 1.0, 0.0, 0.0]])
mask = torch.tensor([[1, 1, 1, 1], [1, 1, 0, 0]])
loss(pred, label, mask) * mask.shape[1] / mask.sum(axis=1)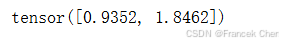
下面显示了如何使用二元交叉熵损失中的Sigmoid激活函数(以较低效率的方式)计算上述结果。我们可以将这两个输出视为两个规范化的损失,在非掩码预测上进行平均。
python
def sigmd(x):
return -math.log(1 / (1 + math.exp(-x)))
print(f'{(sigmd(1.1) + sigmd(2.2) + sigmd(-3.3) + sigmd(4.4)) / 4:.4f}')
print(f'{(sigmd(-1.1) + sigmd(-2.2)) / 2:.4f}')
(二)初始化模型参数
我们定义了两个嵌入层,将词表中的所有单词分别作为中心词和上下文词使用。字向量维度embed_size被设置为100。
python
embed_size = 100
net = nn.Sequential(nn.Embedding(num_embeddings=len(vocab),
embedding_dim=embed_size),
nn.Embedding(num_embeddings=len(vocab),
embedding_dim=embed_size))(三)定义训练阶段代码
训练阶段代码实现定义如下。由于填充的存在,损失函数的计算与以前的训练函数略有不同。
python
def train(net, data_iter, lr, num_epochs, device=d2l.try_gpu()):
def init_weights(m):
if type(m) == nn.Embedding:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
net = net.to(device)
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
animator = d2l.Animator(xlabel='epoch', ylabel='loss',
xlim=[1, num_epochs])
# 规范化的损失之和,规范化的损失数
metric = d2l.Accumulator(2)
for epoch in range(num_epochs):
timer, num_batches = d2l.Timer(), len(data_iter)
for i, batch in enumerate(data_iter):
optimizer.zero_grad()
center, context_negative, mask, label = [
data.to(device) for data in batch]
pred = skip_gram(center, context_negative, net[0], net[1])
l = (loss(pred.reshape(label.shape).float(), label.float(), mask)
/ mask.sum(axis=1) * mask.shape[1])
l.sum().backward()
optimizer.step()
metric.add(l.sum(), l.numel())
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(metric[0] / metric[1],))
print(f'loss {metric[0] / metric[1]:.3f}, '
f'{metric[1] / timer.stop():.1f} tokens/sec on {str(device)}')现在,我们可以使用负采样来训练跳元模型。
python
lr, num_epochs = 0.002, 5
train(net, data_iter, lr, num_epochs)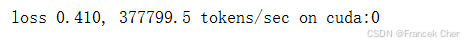
三、应用词嵌入
在训练word2vec模型之后,我们可以使用训练好模型中词向量的余弦相似度来从词表中找到与输入单词语义最相似的单词。
python
def get_similar_tokens(query_token, k, embed):
W = embed.weight.data
x = W[vocab[query_token]]
# 计算余弦相似性。增加1e-9以获得数值稳定性
cos = torch.mv(W, x) / torch.sqrt(torch.sum(W * W, dim=1) *
torch.sum(x * x) + 1e-9)
topk = torch.topk(cos, k=k+1)[1].cpu().numpy().astype('int32')
for i in topk[1:]: # 删除输入词
print(f'cosine sim={float(cos[i]):.3f}: {vocab.to_tokens(i)}')
get_similar_tokens('chip', 3, net[0])
小结
- 我们可以使用嵌入层和二元交叉熵损失来训练带负采样的跳元模型。
- 词嵌入的应用包括基于词向量的余弦相似度为给定词找到语义相似的词。