
🌟 Hello,我是蒋星熠Jaxonic!
🌈 在浩瀚无垠的技术宇宙中,我是一名执着的星际旅人,用代码绘制探索的轨迹。
🚀 每一个算法都是我点燃的推进器,每一行代码都是我航行的星图。
🔭 每一次性能优化都是我的天文望远镜,每一次架构设计都是我的引力弹弓。
🎻 在数字世界的协奏曲中,我既是作曲家也是首席乐手。让我们携手,在二进制星河中谱写属于极客的壮丽诗篇!
摘要
大家好,我是蒋星熠Jaxonic。作为一名深耕AI领域多年的技术探索者,我见证了人工智能从单一模态向多模态融合方向的跨越式发展。在这篇文章中,我想和大家分享我对多模态技术的深入理解与实践经验。随着GPT-4V、DALL-E、CLIP等模型的横空出世,多模态AI已不再是未来的概念,而是当下技术革新的核心驱动力。这种能够同时处理文本、图像、音频等多种数据类型的能力,正在重塑我们与计算机的交互方式,开创人机协作的新纪元。从理论基础到技术架构,从经典算法到前沿应用,我将带领大家全面剖析多模态技术的内在机理,探讨其面临的挑战与机遇,希望能为正在这条技术道路上探索的同行们提供一些有价值的思考与启发。
1. 多模态技术概述
1.1 什么是多模态学习
多模态学习(Multimodal Learning)是指机器学习中同时处理和理解两种或两种以上不同模态数据的领域。这里的「模态」可以是文本、图像、音频、视频、传感器数据等。多模态学习的核心目标是通过整合不同模态的互补信息,提升模型对复杂场景的理解能力。
多模态AI与单模态AI的根本区别在于其对信息的处理方式:
| 特性 | 单模态AI | 多模态AI |
|---|---|---|
| 数据类型 | 单一(如纯文本或纯图像) | 多种(文本+图像+音频等) |
| 信息来源 | 单一渠道 | 多渠道互补 |
| 理解深度 | 表面层次理解 | 深度语义关联 |
| 应用场景 | 特定领域任务 | 复杂开放场景 |
| 容错能力 | 较低,依赖单一信息 | 较高,多源信息验证 |
1.2 多模态技术的发展历程
多模态技术的发展经历了从早期的简单融合到如今的深度协同学习的演进过程。以下是其主要发展阶段:
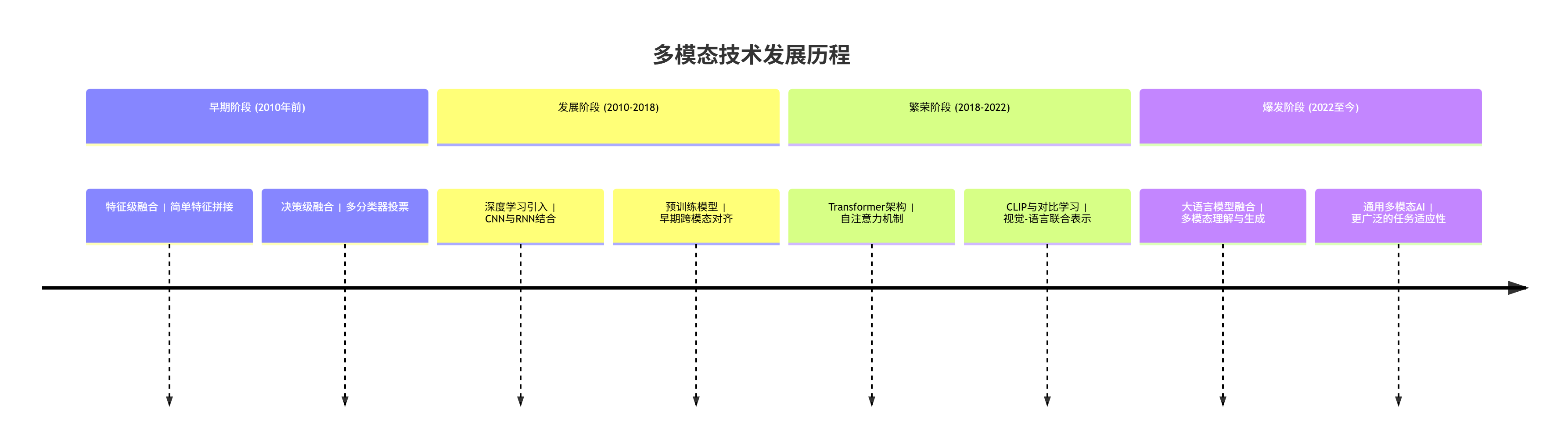
图1:多模态技术发展历程时间线
2. 多模态技术的理论基础
2.1 跨模态表示学习
跨模态表示学习是多模态技术的核心理论基础,其目标是将不同模态的信息映射到一个共享的语义空间中。在这个共享空间中,语义相似的内容会彼此靠近,而不论它们原始的数据类型是什么。
应用层 融合层 编码层 输入层 多模态理解 跨模态检索 多模态生成 跨模态注意力机制 共享表示空间 文本特征 视觉特征 音频特征 文本编码器 文本数据 视觉编码器 图像数据 音频编码器 音频数据
图2:跨模态表示学习架构图
2.2 模态间对齐技术
模态间对齐是确保不同模态信息能够正确关联的关键技术。主要包括以下几种对齐策略:
- 隐式对齐:通过联合训练让模型自动学习模态间的对应关系
- 显式对齐:使用额外的标注信息指导模态间的映射
- 对比学习对齐:基于对比损失函数将相同语义的不同模态表示拉近
3. 多模态模型架构
3.1 经典多模态架构
当前主流的多模态架构主要基于Transformer,采用编码器-解码器结构,并引入跨模态注意力机制实现不同模态信息的交互与融合。
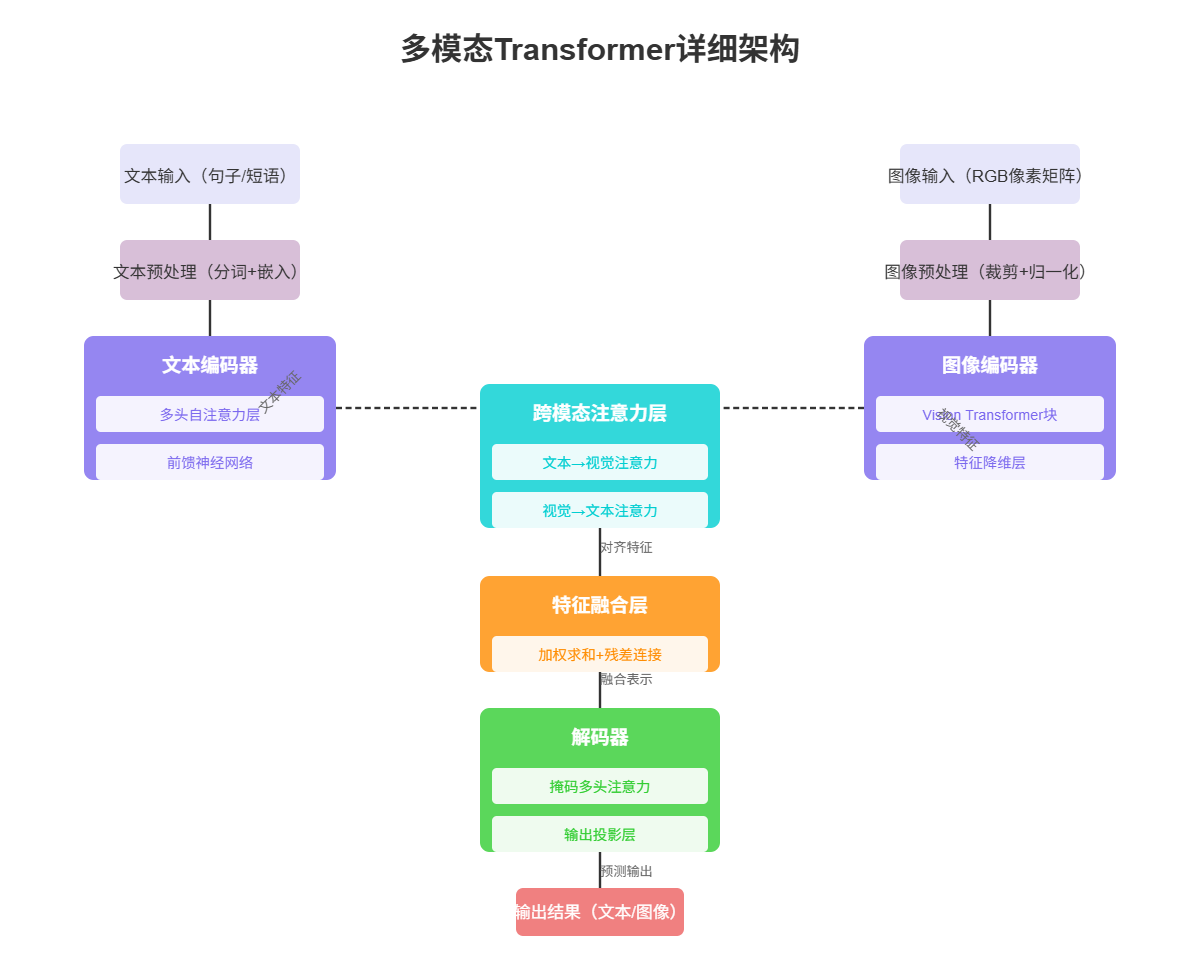
图3:多模态Transformer架构图
3.2 注意力机制在多模态融合中的应用
注意力机制是多模态融合的关键技术,它能够帮助模型关注不同模态中最相关的信息。以下是一个简化的注意力机制实现:
python
import torch
import torch.nn as nn
class CrossModalAttention(nn.Module):
def __init__(self, dim, num_heads=8, dropout=0.1):
super().__init__()
self.dim = dim
self.num_heads = num_heads
self.head_dim = dim // num_heads
# Query来自模态A,Key和Value来自模态B
self.q_proj = nn.Linear(dim, dim)
self.k_proj = nn.Linear(dim, dim)
self.v_proj = nn.Linear(dim, dim)
self.out_proj = nn.Linear(dim, dim)
self.dropout = nn.Dropout(dropout)
self.scale = self.head_dim ** -0.5
def forward(self, query, key, value, mask=None):
batch_size = query.size(0)
# 线性投影并多头化
q = self.q_proj(query).view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)
k = self.k_proj(key).view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)
v = self.v_proj(value).view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)
# 计算注意力权重
attn = (q @ k.transpose(-2, -1)) * self.scale
if mask is not None:
attn = attn.masked_fill(mask == 0, -1e9)
attn = attn.softmax(dim=-1)
attn = self.dropout(attn)
# 应用注意力
out = (attn @ v).transpose(1, 2).contiguous().view(batch_size, -1, self.dim)
out = self.out_proj(out)
return out在这段代码中,我们实现了一个基本的跨模态注意力机制,它允许一个模态(查询)关注另一个模态(键值对)中的相关信息。这种设计能够有效地促进不同模态间的信息交互。
4. 多模态技术的关键算法
4.1 对比学习(Contrastive Learning)
对比学习是当前多模态表示学习的主流方法之一,其核心思想是将语义相似的样本拉近,将语义不同的样本推开。在多模态领域,这种方法尤为有效:
python
import torch
import torch.nn.functional as F
def contrastive_loss(image_features, text_features, temperature=0.07):
# 标准化特征向量
image_features = F.normalize(image_features, dim=-1)
text_features = F.normalize(text_features, dim=-1)
# 计算图像-文本相似度矩阵
logits = image_features @ text_features.t() / temperature
# 构建标签(对角线元素为正样本)
batch_size = image_features.size(0)
labels = torch.arange(batch_size, device=image_features.device)
# 双向损失:图像到文本和文本到图像
loss_i2t = F.cross_entropy(logits, labels)
loss_t2i = F.cross_entropy(logits.t(), labels)
# 总损失
loss = (loss_i2t + loss_t2i) / 2
return loss这段代码实现了CLIP模型中的对比损失函数,它通过最大化匹配的图像-文本对之间的相似度,同时最小化不匹配对之间的相似度,从而学习到统一的多模态表示。
4.2 多模态预训练策略
多模态预训练是提升模型泛化能力的关键。目前主流的预训练策略包括:
- 掩码语言建模(MLM):随机掩码文本中的部分token,要求模型预测
- 掩码图像建模(MIM):随机掩码图像中的部分区域,要求模型重建
- 图文匹配(ITM):判断图像和文本是否匹配
- 图像文本生成(ITG):从图像生成描述或从文本生成图像
5. 多模态技术的应用场景
5.1 图文检索
图文检索是多模态技术的经典应用,允许用户使用图片搜索相关文本,或使用文本搜索相关图片。
结果展示层 特征匹配层 用户交互层 文本 图像 排序检索结果 返回匹配项 查询特征向量 与数据库向量计算相似度 查询类型 用户输入查询 文本编码器 图像编码器
图4:图文检索系统流程图
5.2 多模态内容生成
多模态内容生成包括从文本生成图像(如DALL-E)、从图像生成文本(如图像描述)、从文本生成视频等多种任务。
5.3 视觉问答(VQA)
视觉问答任务要求模型根据图像内容回答自然语言问题,是检验多模态理解能力的重要基准。
6. 多模态技术的挑战与解决方案
6.1 模态间异质性挑战
不同模态的数据具有本质差异(如文本是离散的,图像是连续的),这给有效融合带来挑战。
解决方案包括:
- 使用投影层将不同模态映射到相同维度的空间
- 设计专门的跨模态注意力机制
- 采用对比学习实现隐式对齐
6.2 数据稀疏性与质量问题
高质量的多模态数据集相对稀缺,且标注成本高昂。
解决方案包括:
- 利用弱监督或自监督学习减少标注依赖
- 采用数据增强技术扩充数据集
- 开发跨数据集迁移学习方法
7. 多模态技术的未来发展
7.1 技术趋势预测
多模态技术的未来发展将呈现以下趋势:
35% 25% 20% 15% 5% 多模态技术未来发展趋势分布 更大规模的模型 更细粒度的模态理解 实时多模态交互 低资源场景适配 领域特化优化
图5:多模态技术未来发展趋势分布饼图
7.2 新兴应用方向
随着技术的成熟,多模态AI将在更多领域发挥重要作用:
- 智能医疗:结合医学影像和电子病历的诊断辅助
- 自动驾驶:融合视觉、雷达、激光雷达等多源数据
- 增强现实:实现真实世界与虚拟信息的无缝融合
- 教育科技:提供个性化、多感官的学习体验
8. 多模态模型实践指南
8.1 模型选择与调优
选择合适的多模态模型并进行有效的调优是实际应用中的关键步骤:
- 小规模应用:可选择轻量级模型如MobileCLIP
- 中等规模应用:ViLT、CLIP等平衡性能与效率的模型
- 大规模应用:GPT-4V、Flamingo等最先进的大模型
8.2 性能优化技巧
在实际部署中,多模态模型的性能优化至关重要:
python
# 模型量化示例 - 减少模型大小和推理时间
import torch
from transformers import AutoModel, AutoProcessor
# 加载原始模型
model = AutoModel.from_pretrained("openai/clip-vit-base-patch32")
processor = AutoProcessor.from_pretrained("openai/clip-vit-base-patch32")
# 进行INT8量化
quantized_model = torch.quantization.quantize_dynamic(
model,
{torch.nn.Linear},
dtype=torch.qint8
)
# 保存量化后的模型
torch.save(quantized_model.state_dict(), "quantized_clip_model.pth")这段代码展示了如何使用PyTorch的动态量化功能减小CLIP模型的大小并加速推理,这在资源受限的环境中尤为重要。
总结
作为一名长期关注AI前沿发展的技术探索者,我深刻体会到多模态技术正在引领人工智能进入一个全新的发展阶段。通过融合不同模态的信息,AI系统能够更全面、更准确地理解我们周围的世界,为各种应用场景提供更强大的支持。从技术实现角度看,跨模态表示学习、注意力机制、对比学习等关键技术的成熟,为多模态AI的快速发展奠定了坚实基础。未来,随着模型规模的扩大、计算效率的提升以及应用场景的拓展,多模态技术必将在更多领域发挥关键作用。
在实际应用中,我们需要根据具体场景选择合适的模型架构和训练策略,并关注性能优化和实际部署中的各种挑战。同时,也要密切关注学术前沿的最新进展,不断更新我们的技术栈和方法论。作为技术社区的一员,我期待与大家共同推动多模态技术的发展,探索人工智能的无限可能。
多模态技术的发展之路才刚刚开始,让我们保持好奇心和探索精神,在这条充满机遇与挑战的道路上不断前行!

■ 我是蒋星熠Jaxonic!如果这篇文章在你的技术成长路上留下了印记
■ 👁 【关注】与我一起探索技术的无限可能,见证每一次突破
■ 👍 【点赞】为优质技术内容点亮明灯,传递知识的力量
■ 🔖 【收藏】将精华内容珍藏,随时回顾技术要点
■ 💬 【评论】分享你的独特见解,让思维碰撞出智慧火花
■ 🗳 【投票】用你的选择为技术社区贡献一份力量
■ 技术路漫漫,让我们携手前行,在代码的世界里摘取属于程序员的那片星辰大海!