目录
需求:获取起点中文网中的某一个分区(案例以玄幻为例)的本周强推的十本小说的已经更新的章节并且保存下来(小说名为文件名,每一个章节存一个txt文件(章节名为文件名))。
目标网站:https://www.qidian.com/(起点中文网)
1、了解网站流程
首先我们先对网站进行初步的了解,方便我们使用RPA。
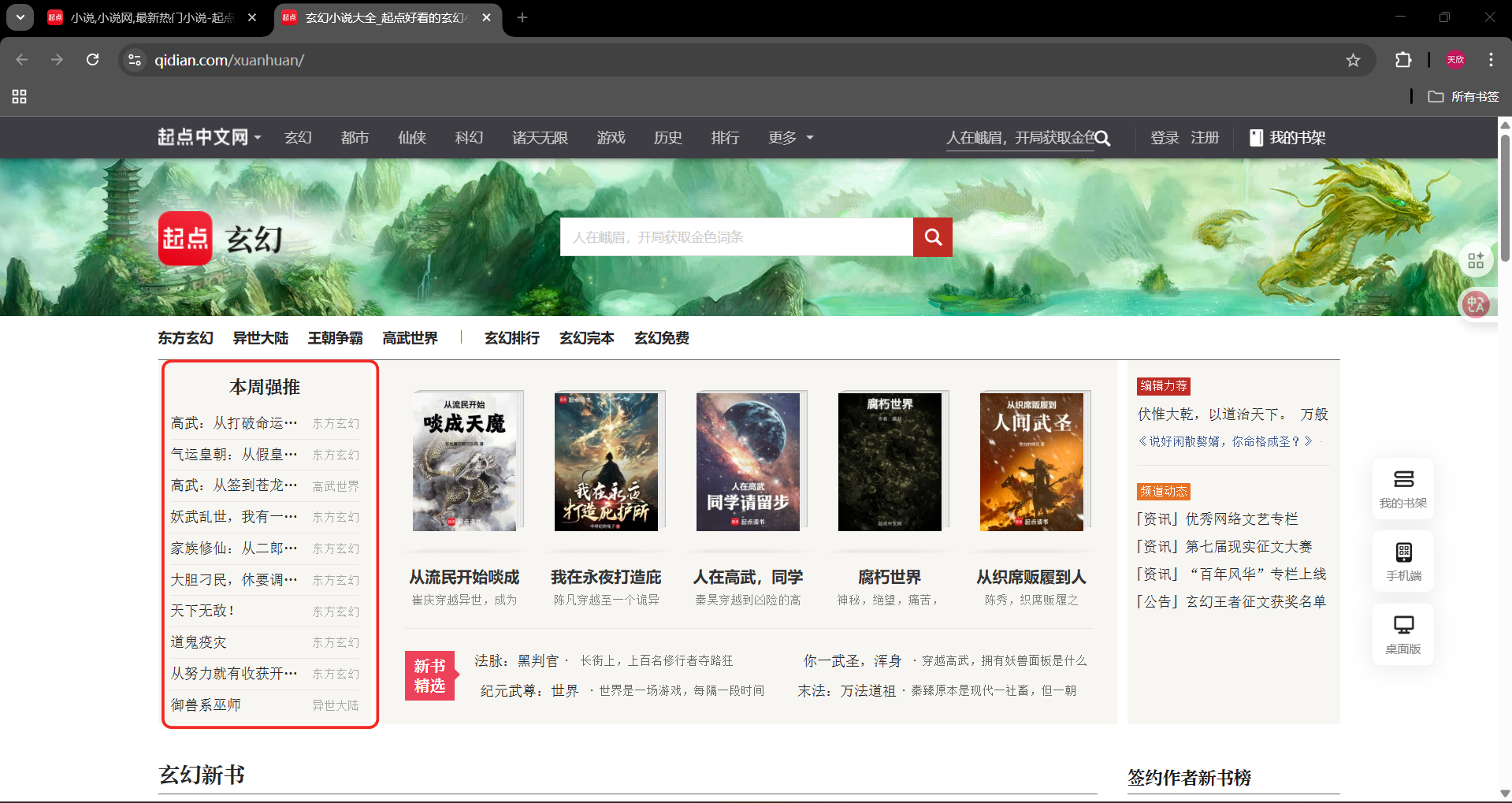
在该网站的首页,我们需要先点击玄幻分区。
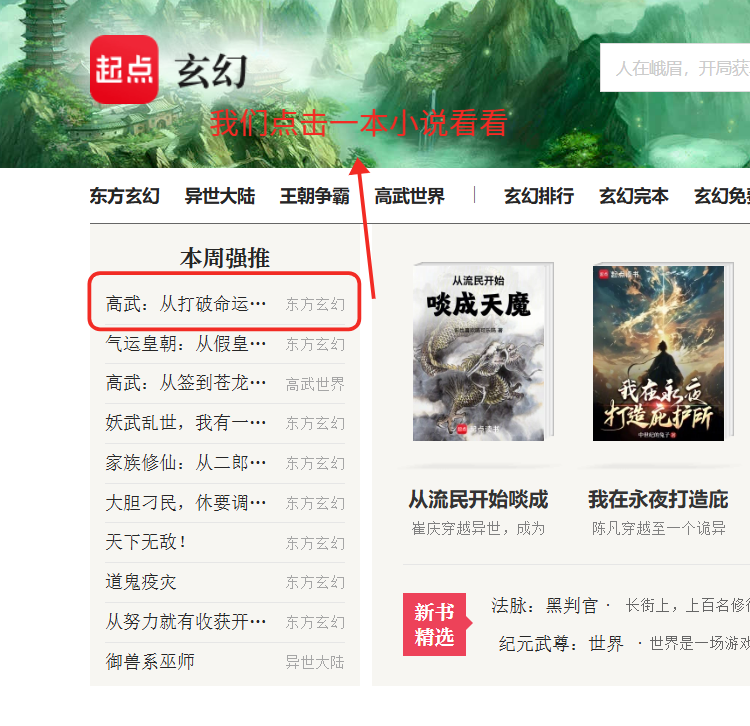
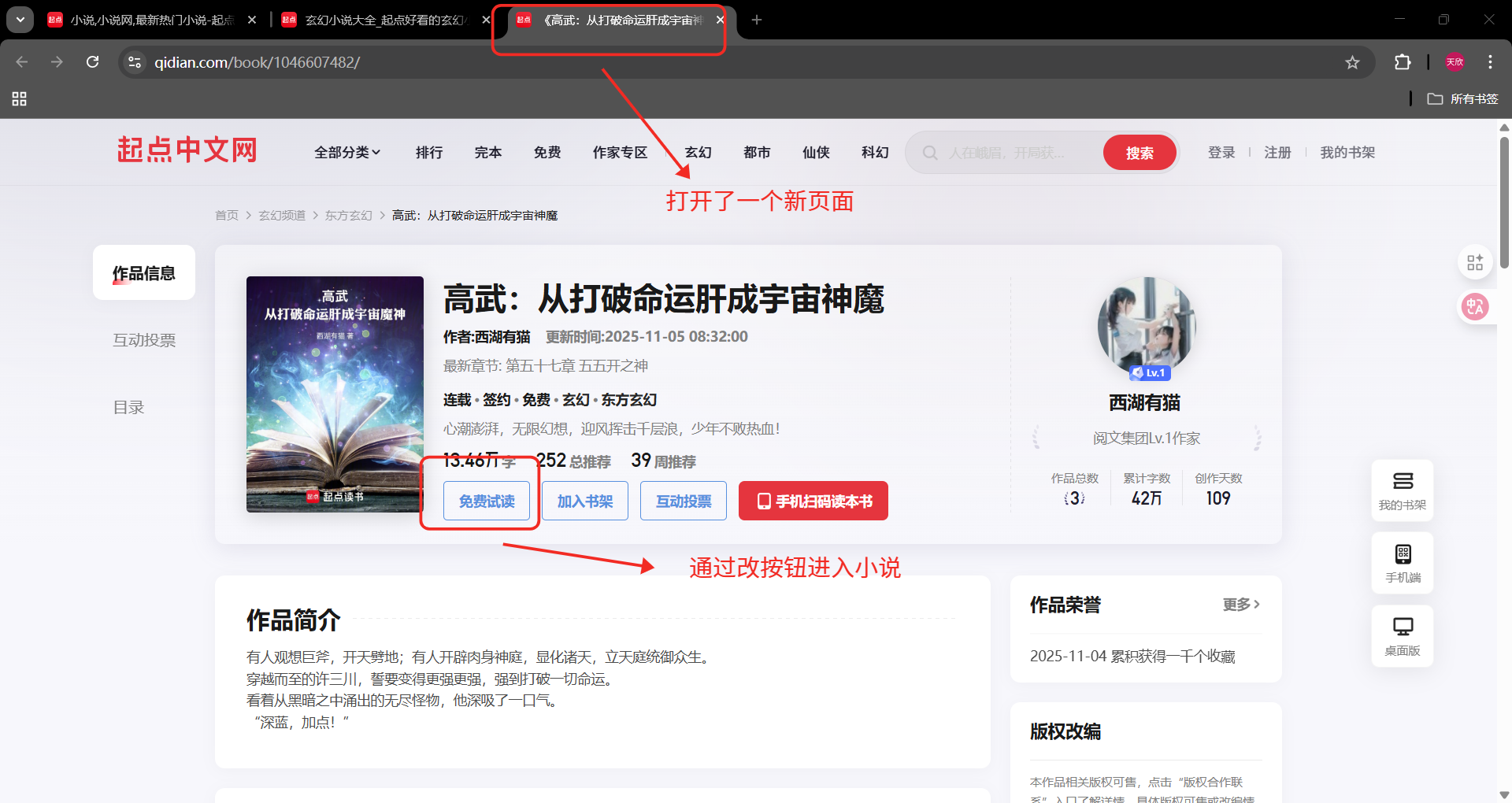
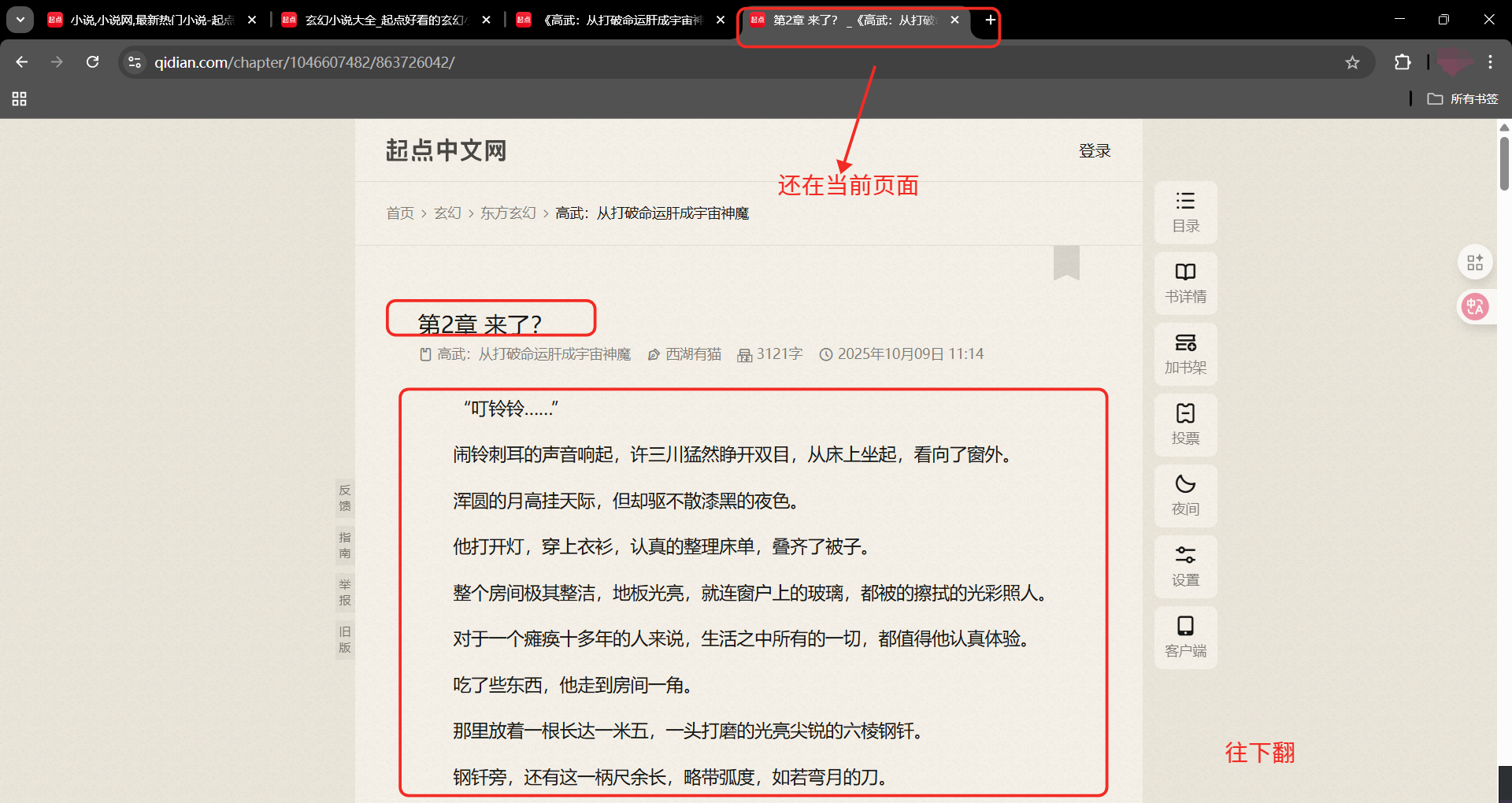
我们点击玄幻这一个分区,进入了一个新页面(玄幻分区页面),网站首页还存在。
OK,以上就是一本小说的相关流程,先尝试写一下吧

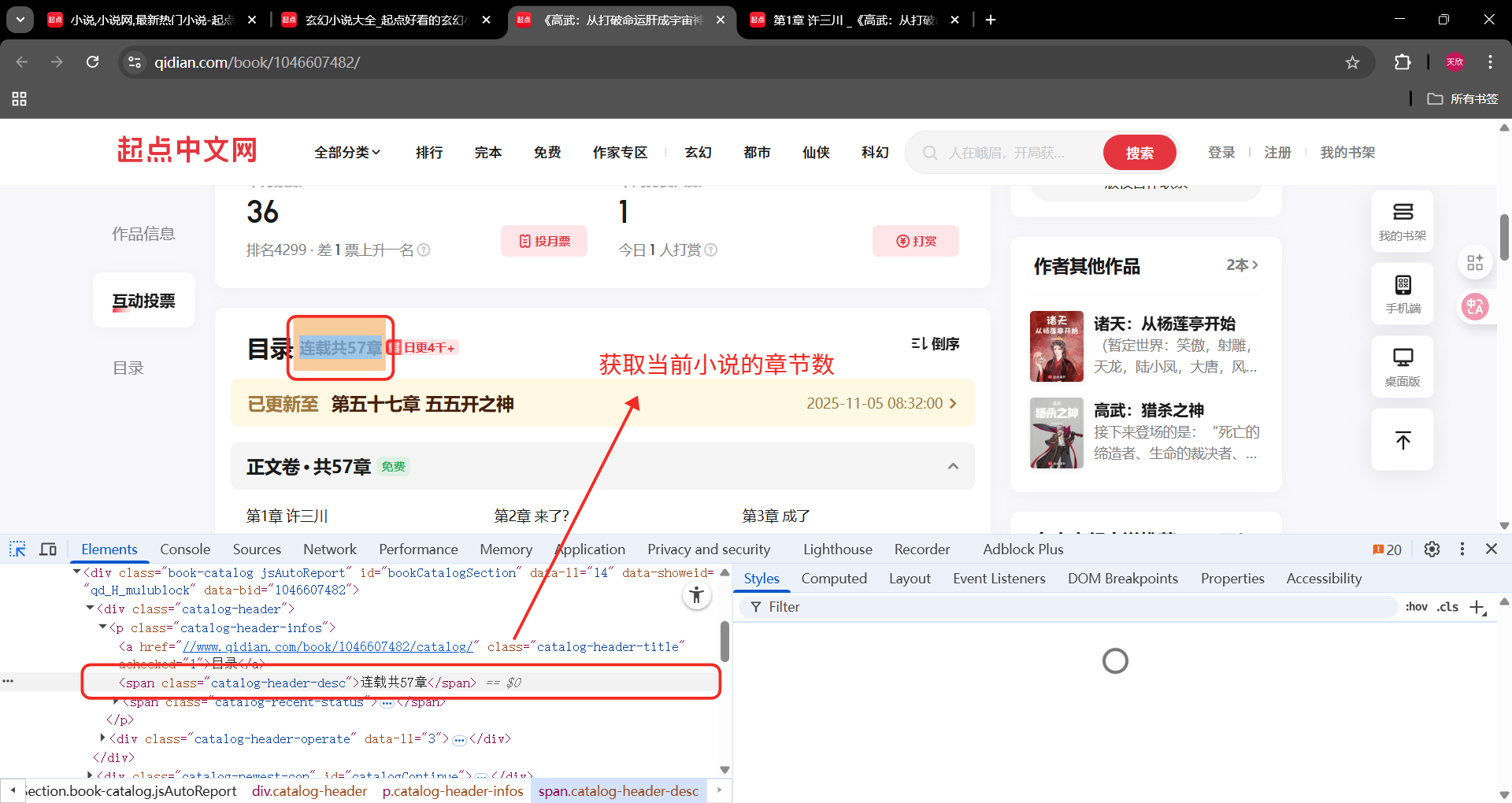
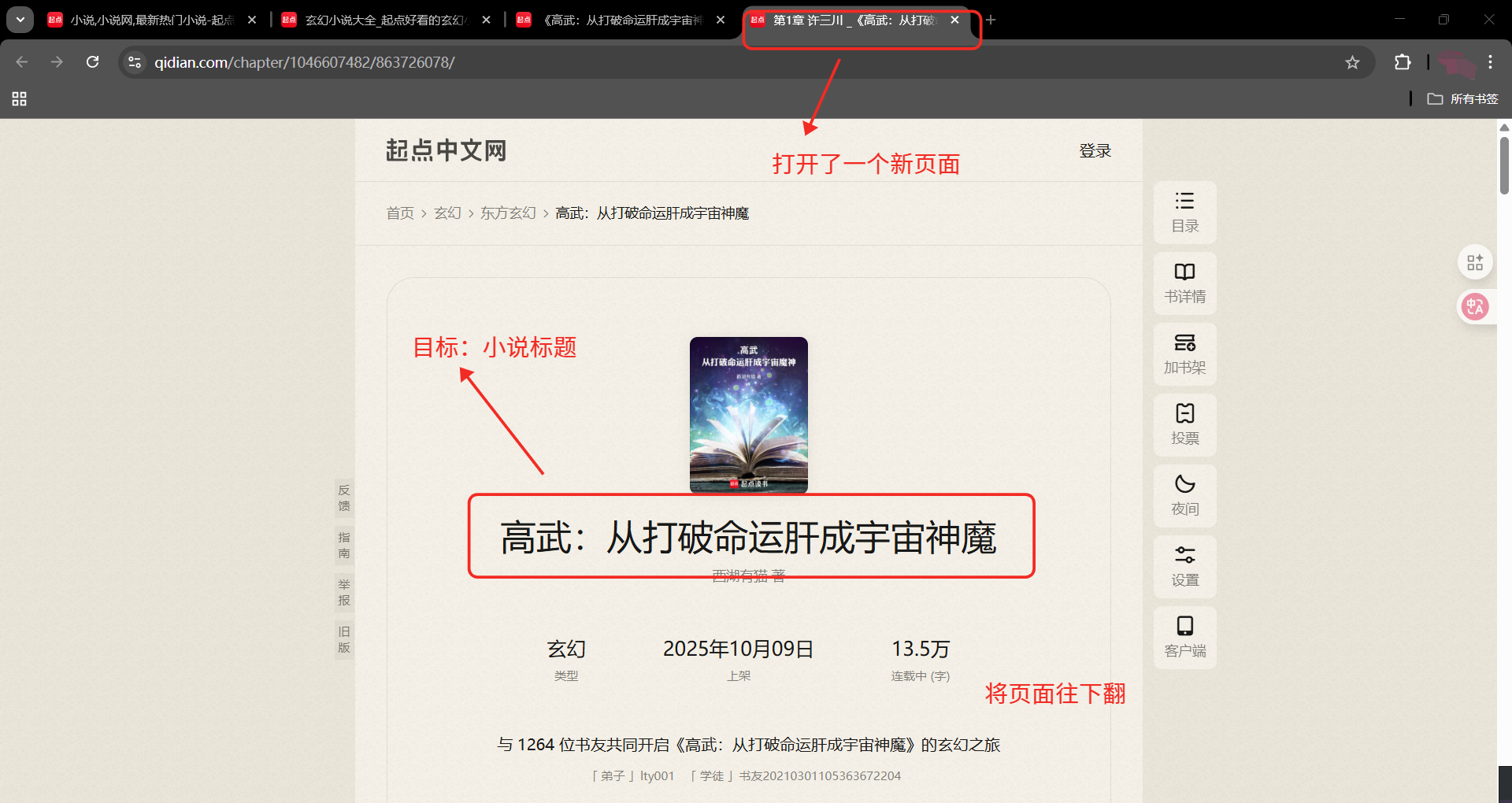
2、xpath分析
(提醒如果鼠标不能右键继续操作,就按F12进入开发者模式)
在下面只需要重复操作的部分的代码
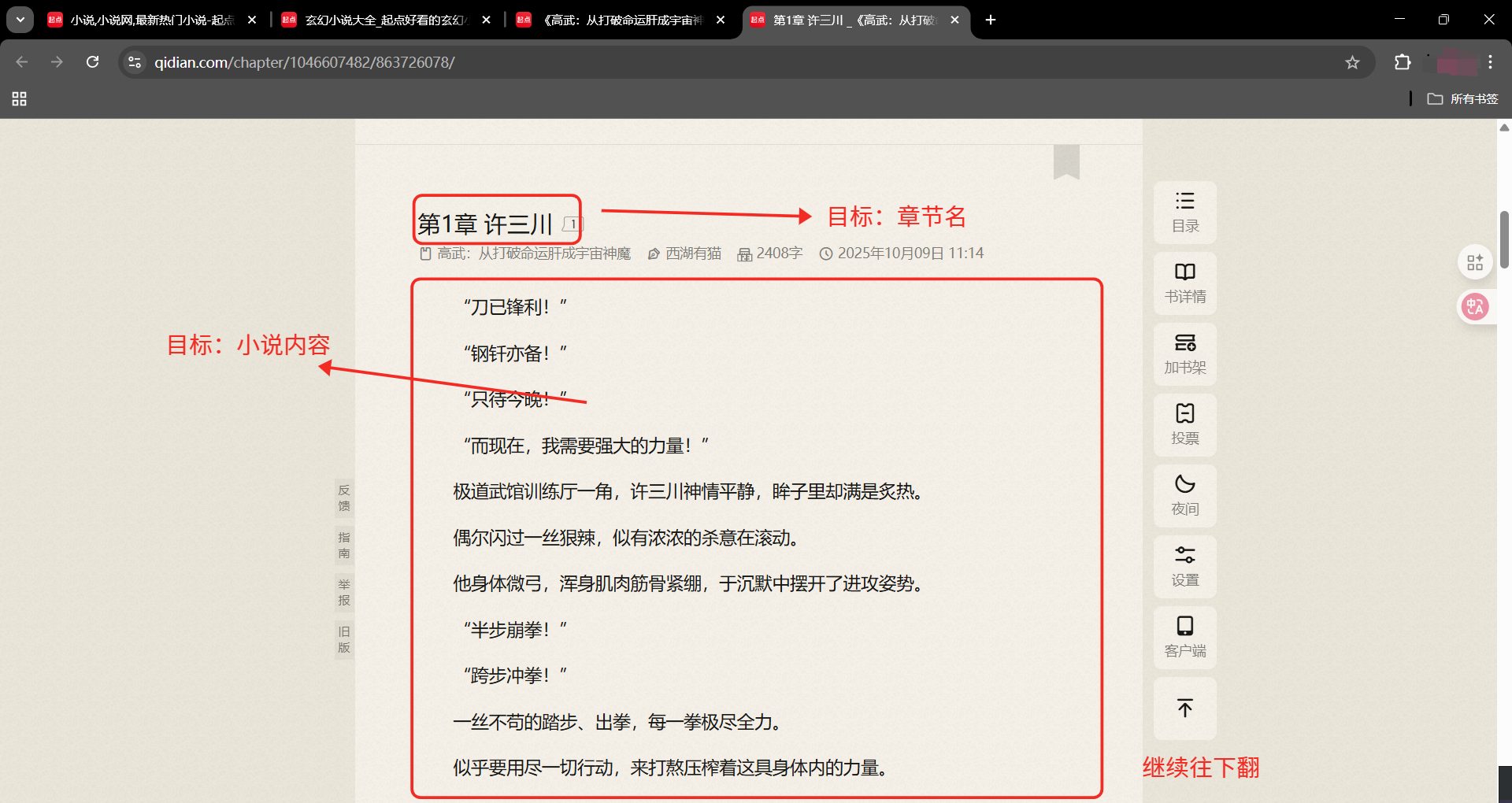
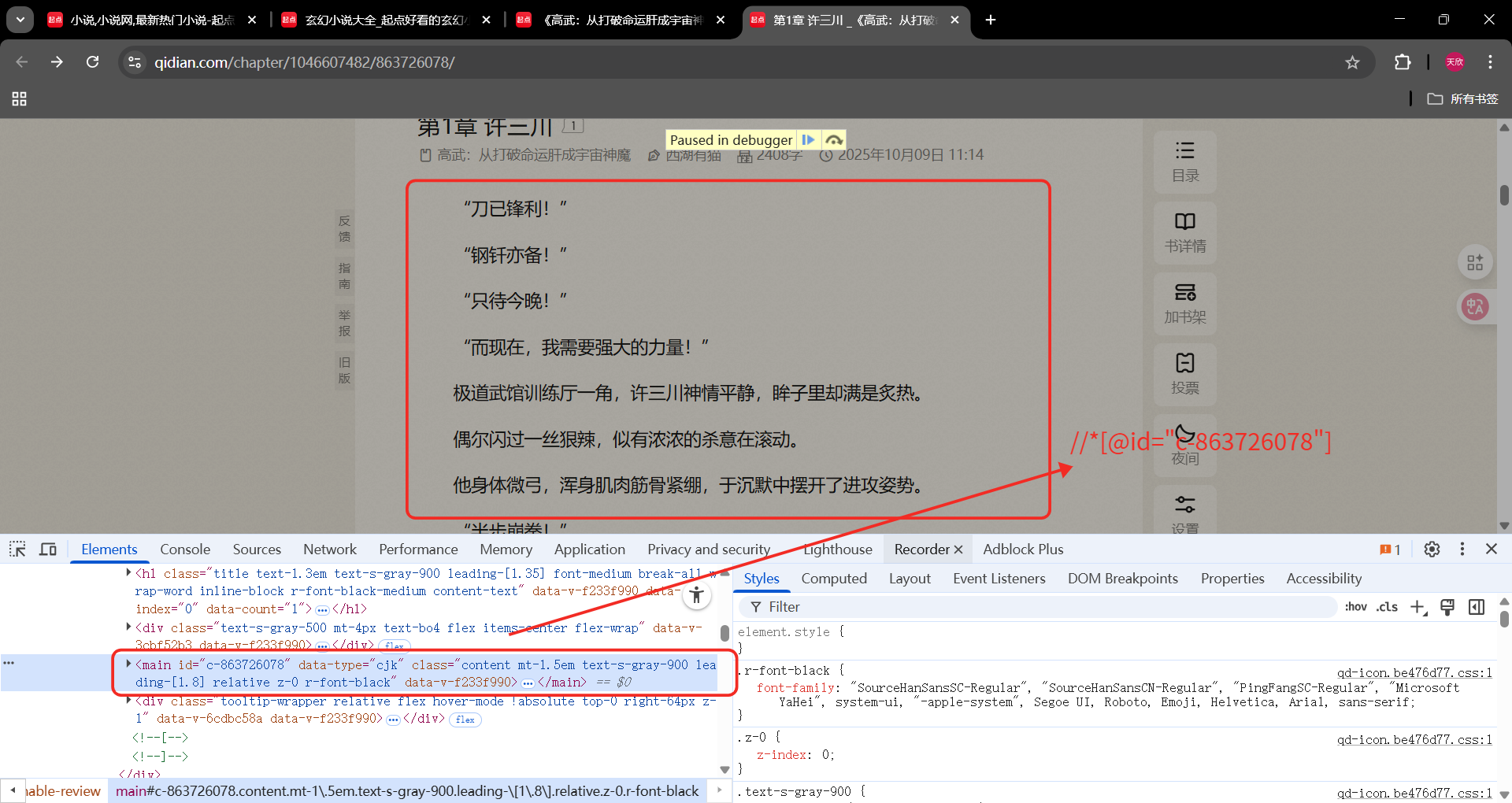
第一章页面
章节名xpath:
//*@id="reader-content"/div/div/div2/div/h1
小说内容:
//*@id="c-863726078"
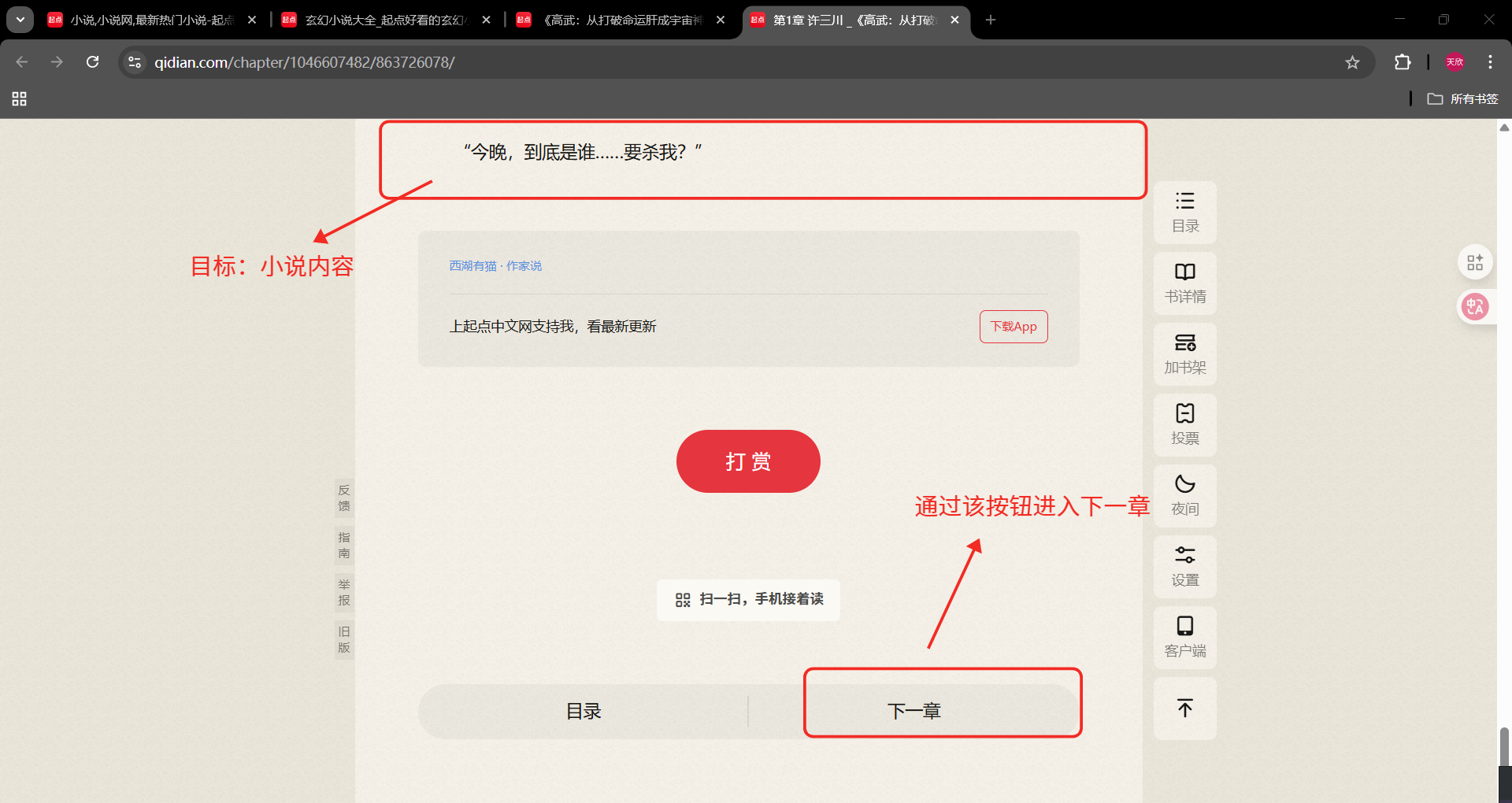
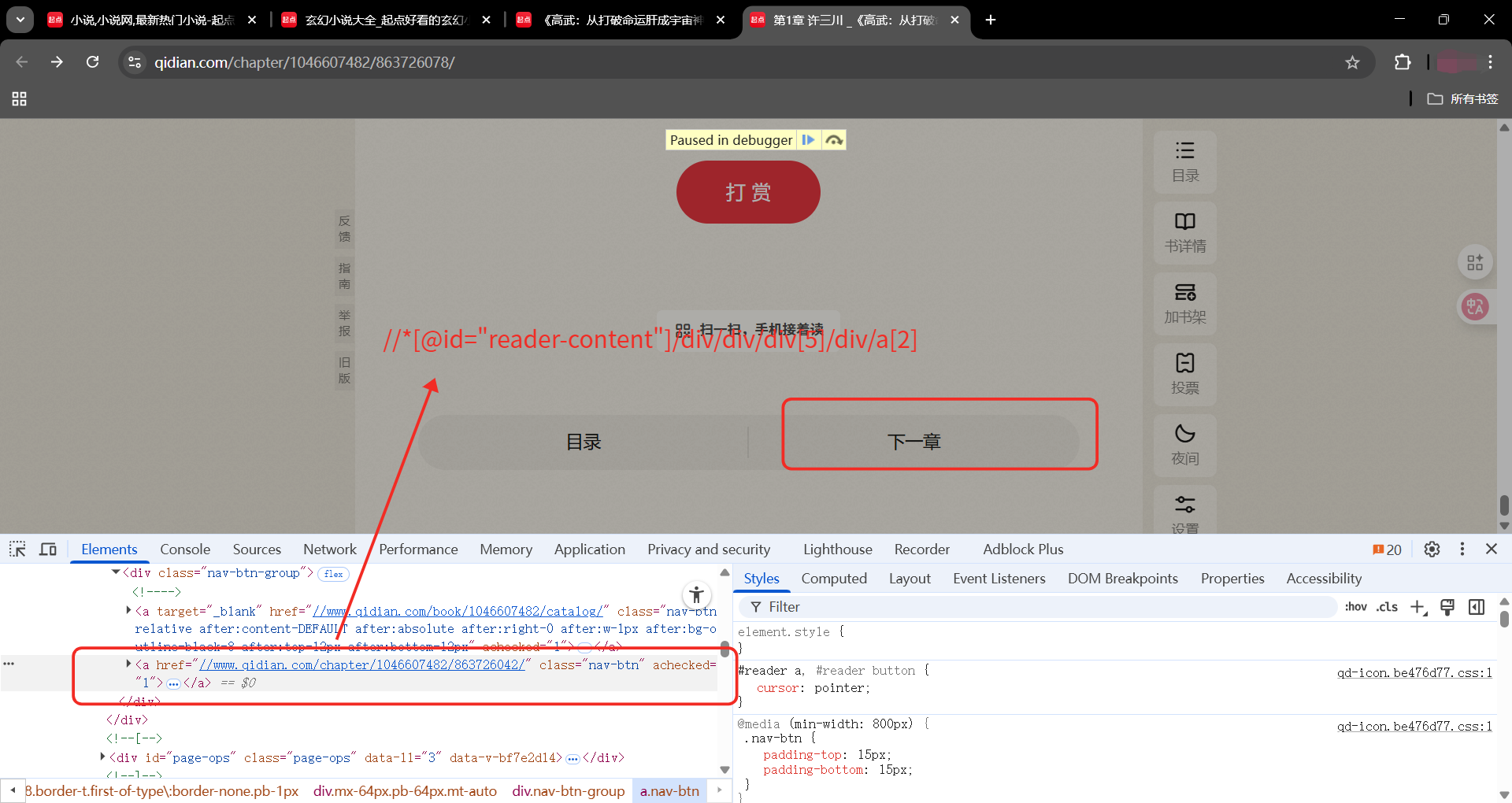
下一章按钮:
//*@id="reader-content"/div/div/div5/div/a2
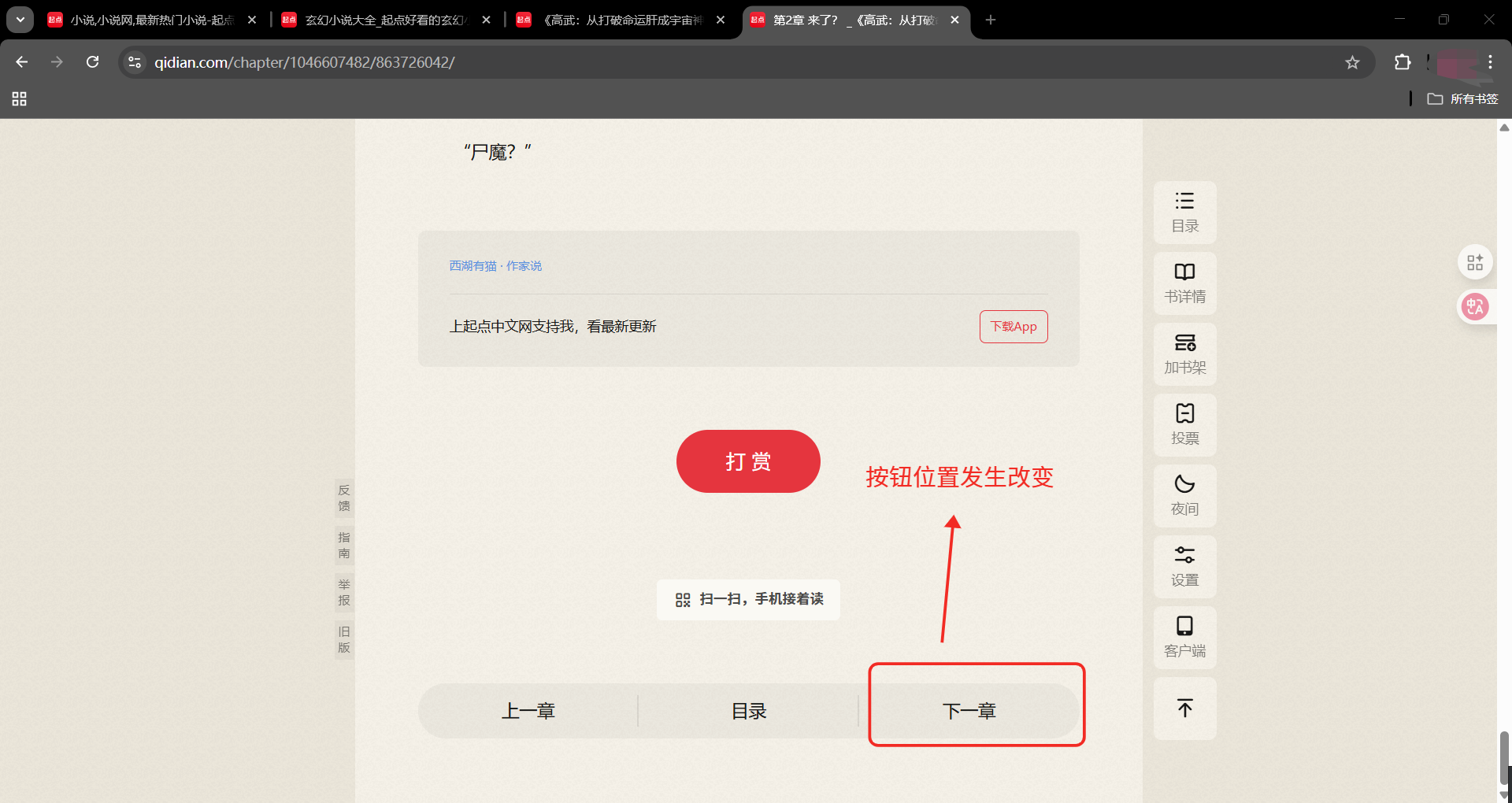
第二章页面
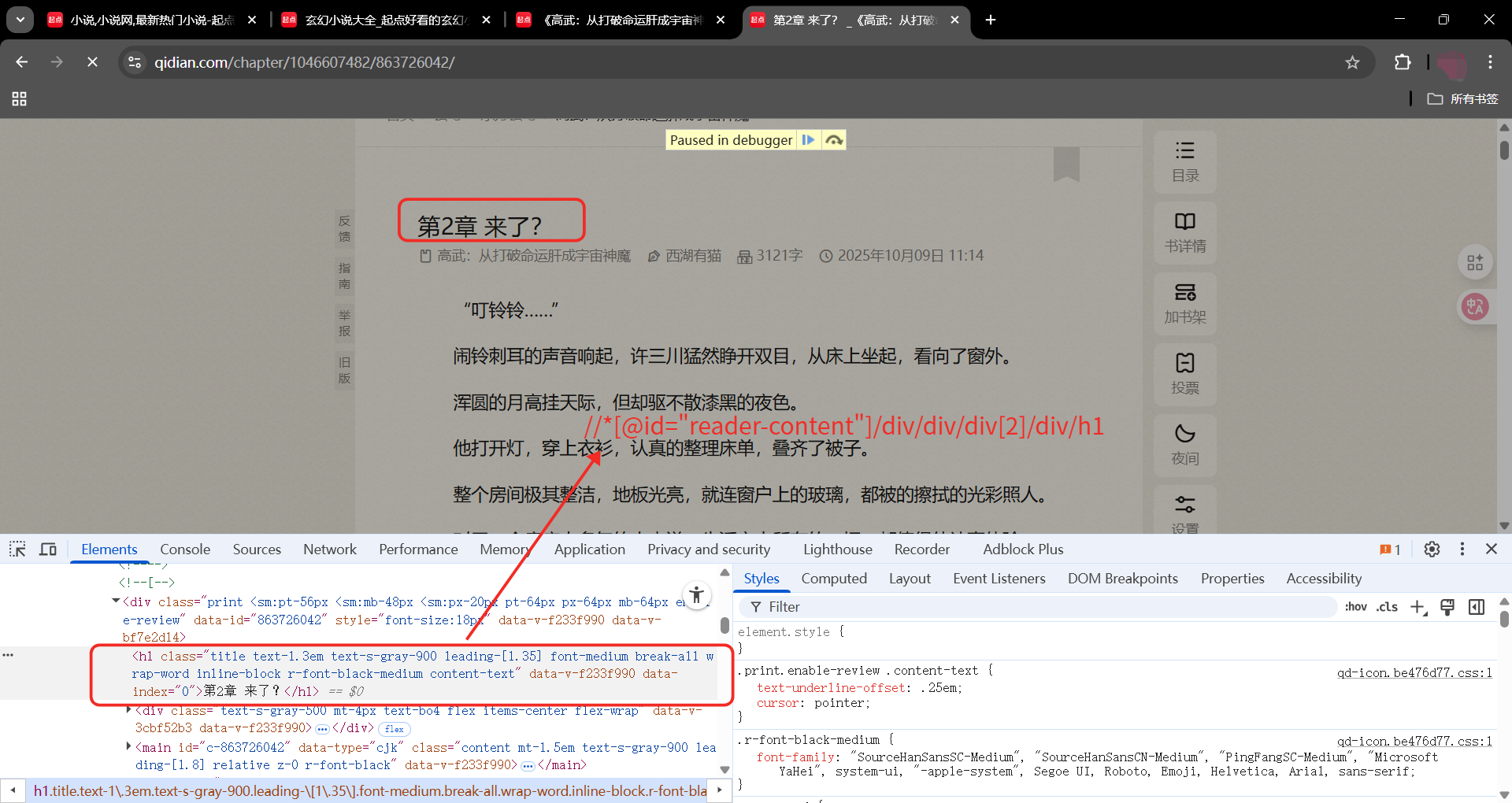
章节名xpath
//*@id="reader-content"/div/div/div2/div/h1
小说内容xpath
//*@id="c-863726042"
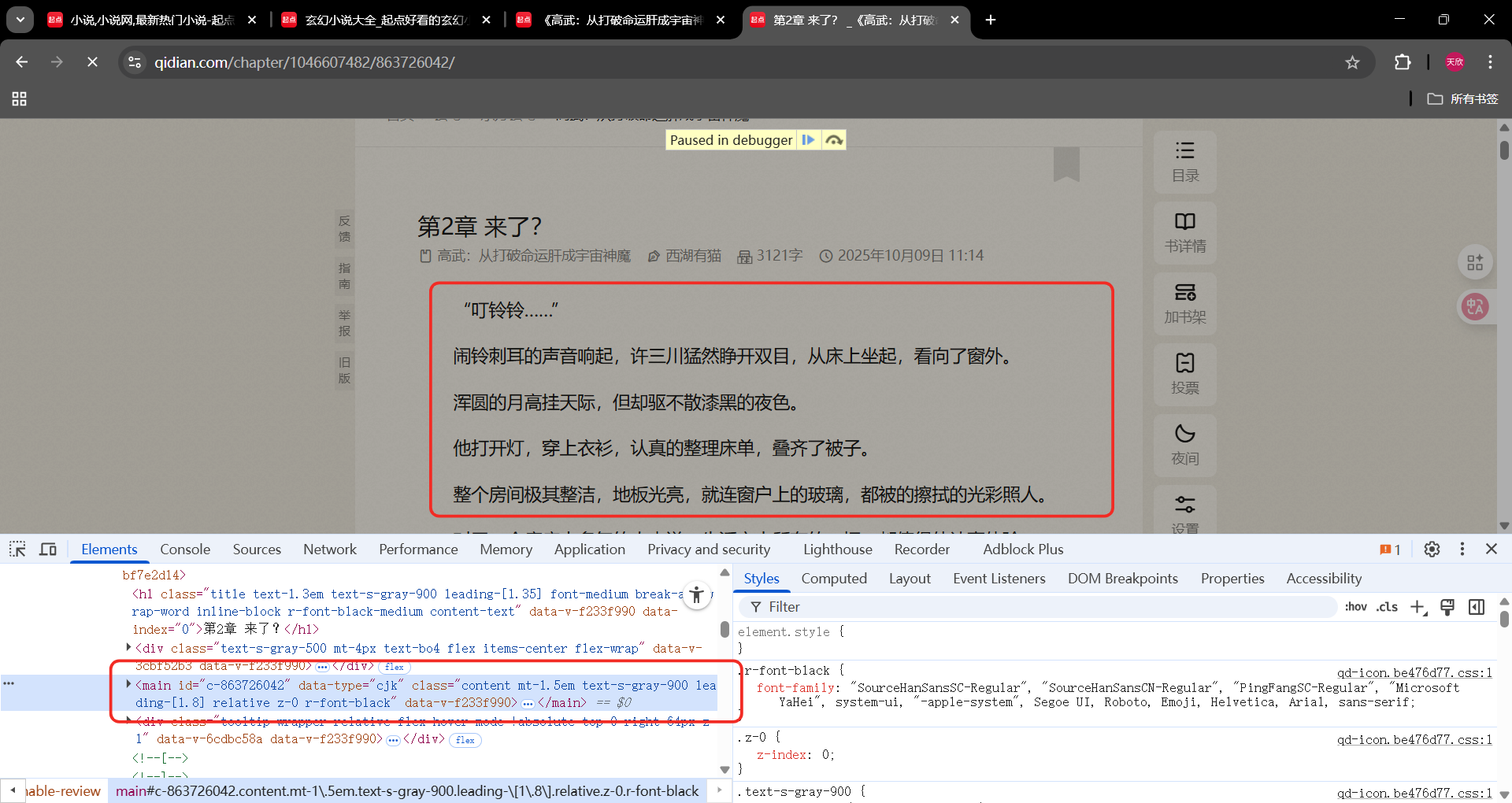
下一章按钮xpath
//*@id="reader-content"/div/div/div5/div/a3
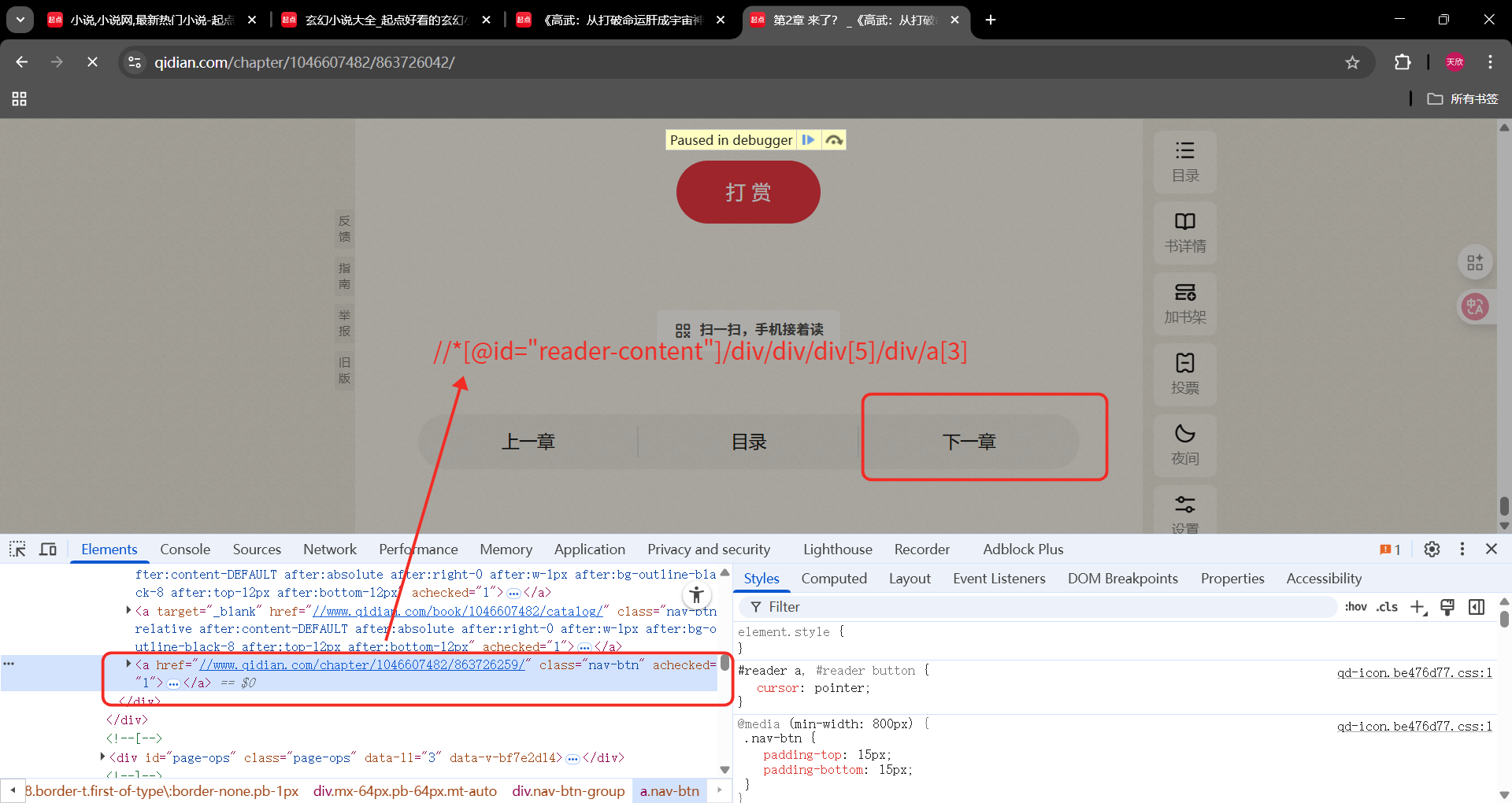
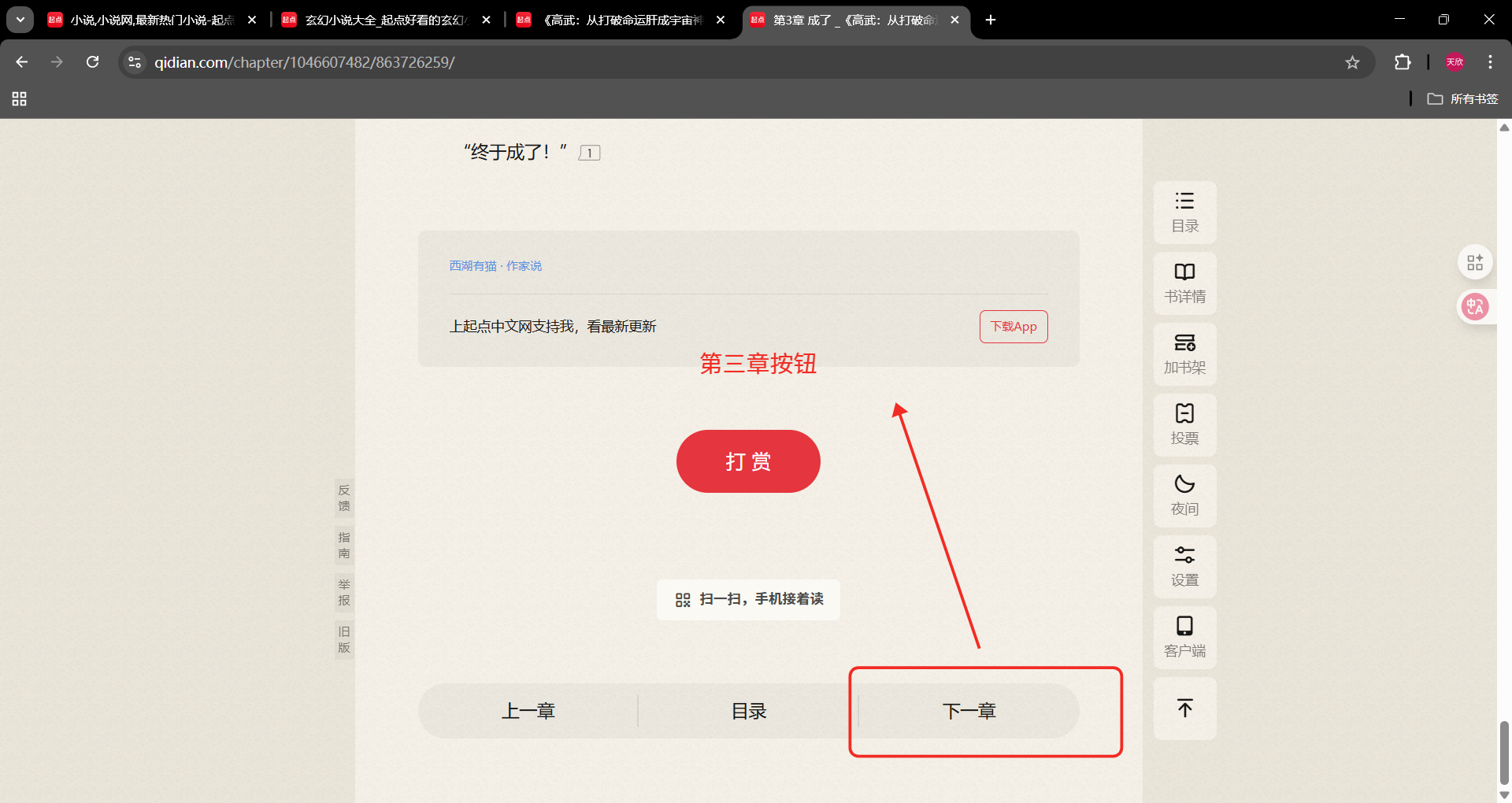
第三章页面
下一章按钮xpath
//*@id="reader-content"/div/div/div5/div/a3
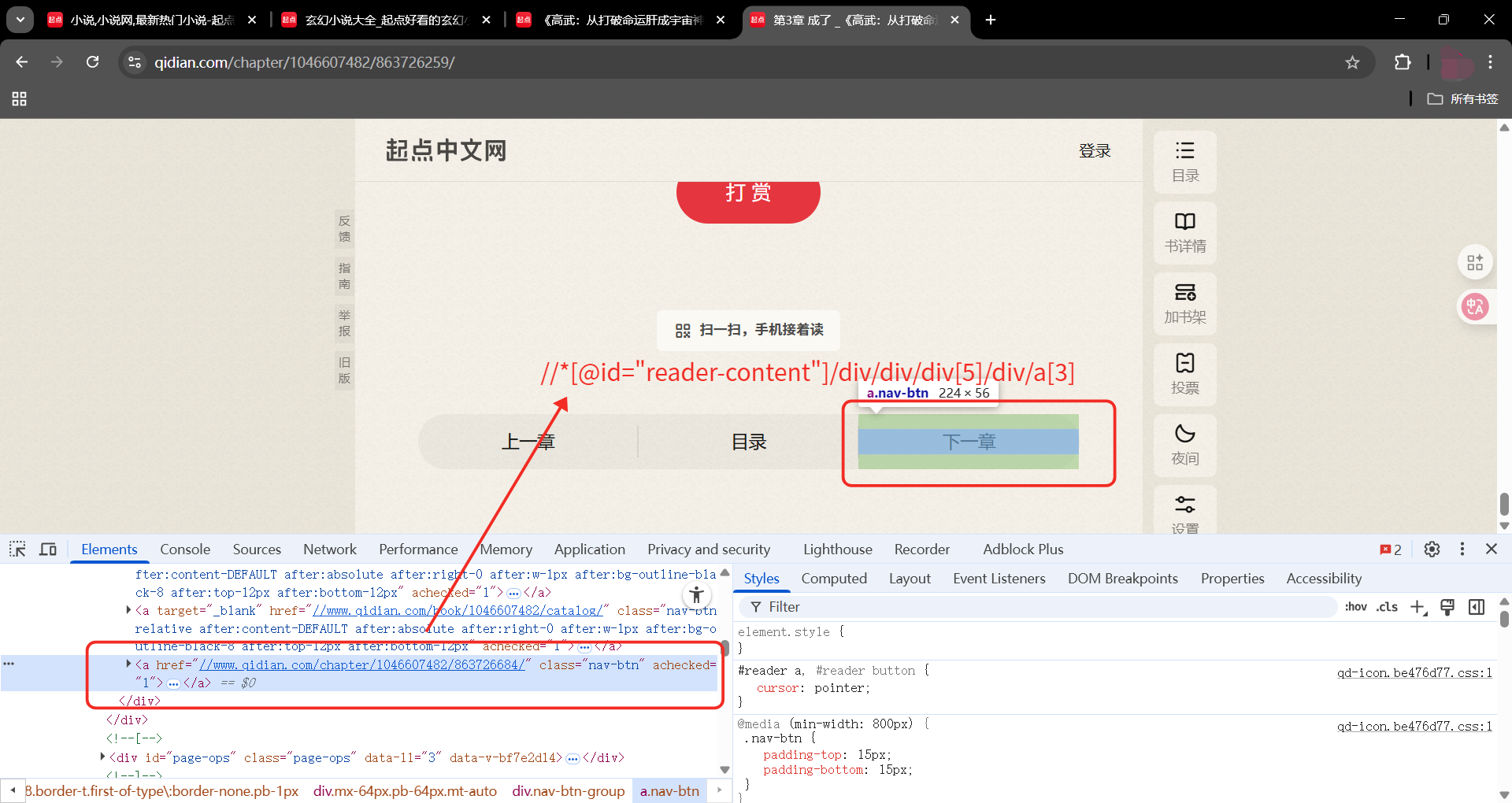
总结
章节名:
//*@id="reader-content"/div/div/div2/div/h1
//*@id="reader-content"/div/div/div2/div/h1
小说内容:
//*@id="c-863726078"
//*@id="c-863726042"
下一章按钮:
//*@id="reader-content"/div/div/div5/div/a2
//*@id="reader-content"/div/div/div5/div/a3
//*@id="reader-content"/div/div/div5/div/a3
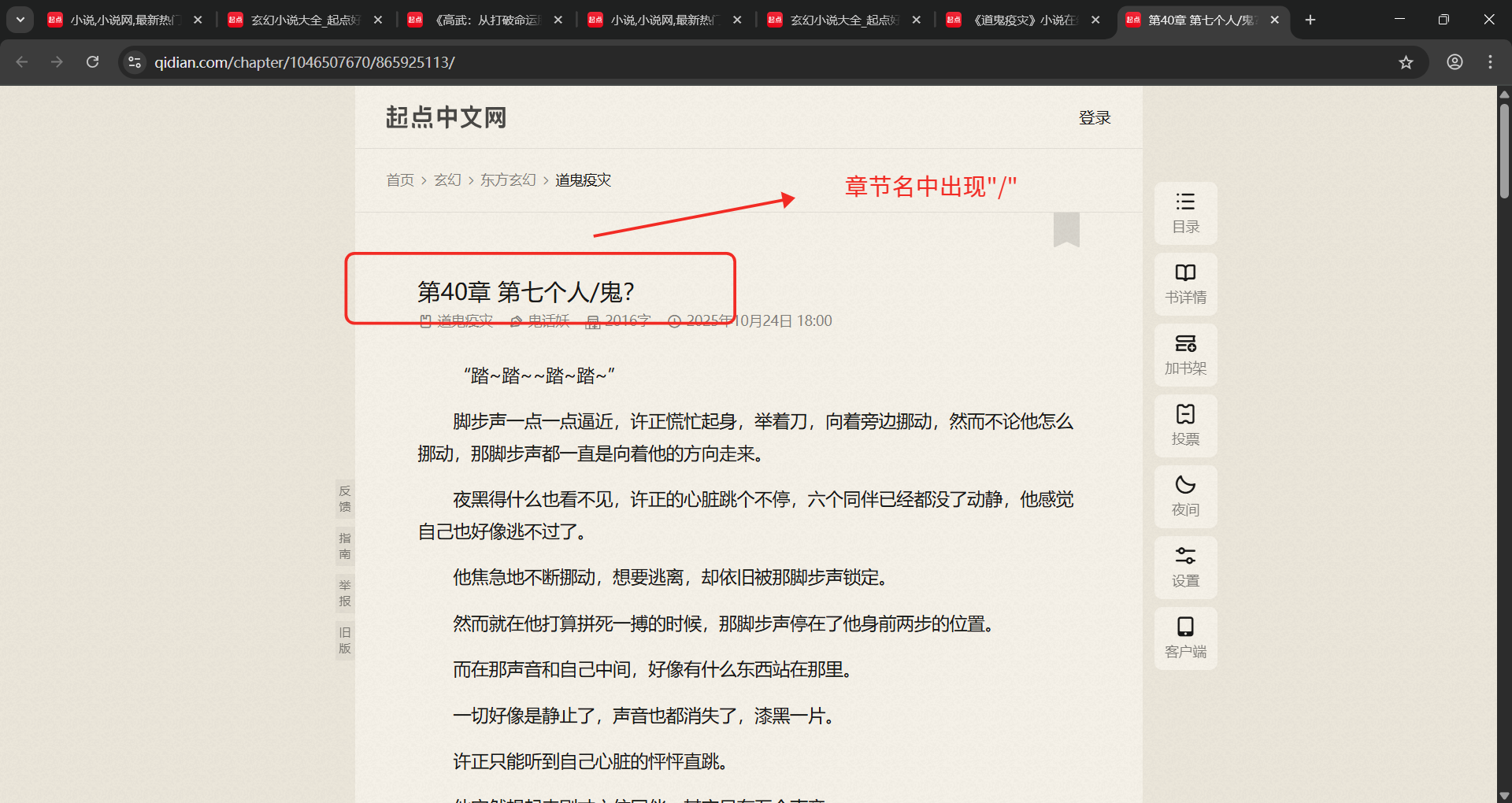
章节名没变化可以直接使用,按钮第一页和其它页不同,其它页相同。
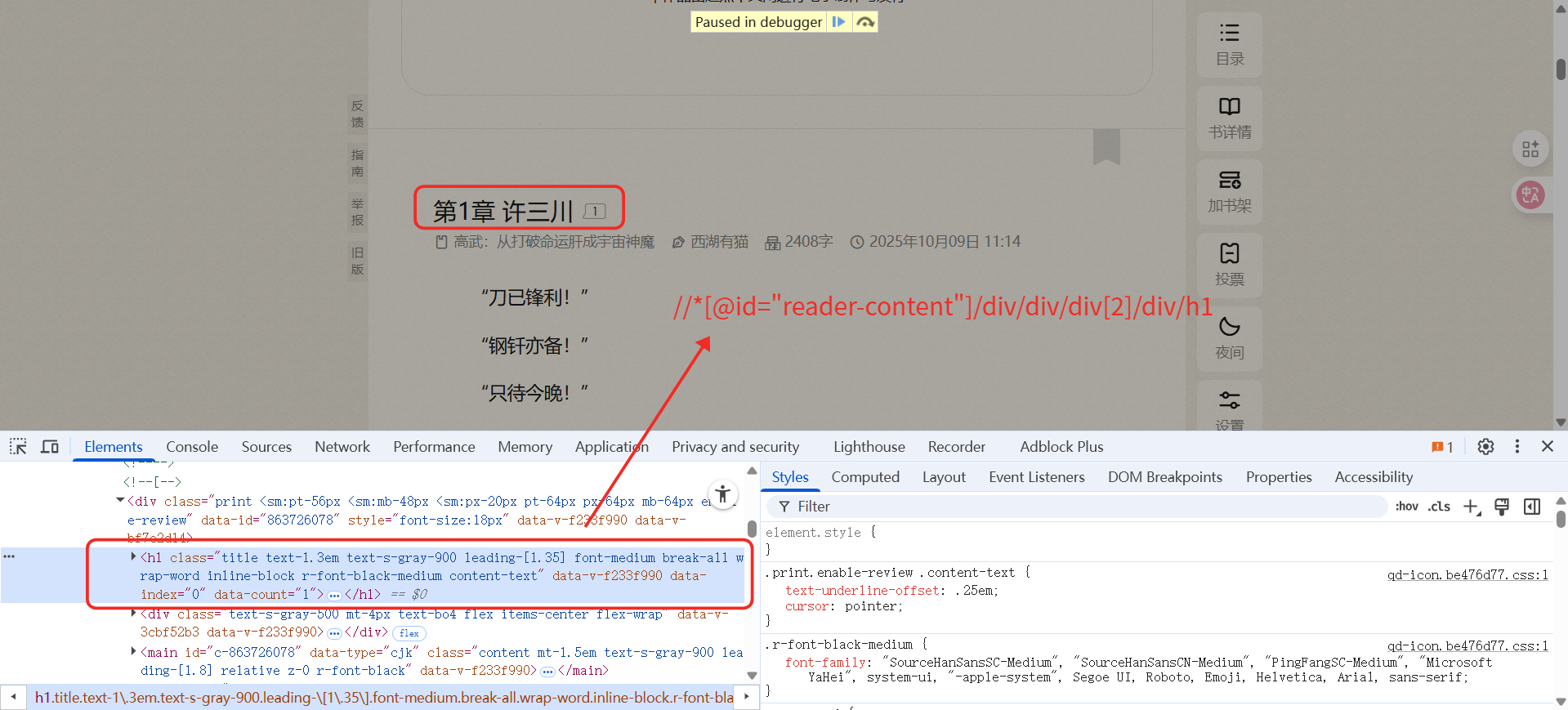
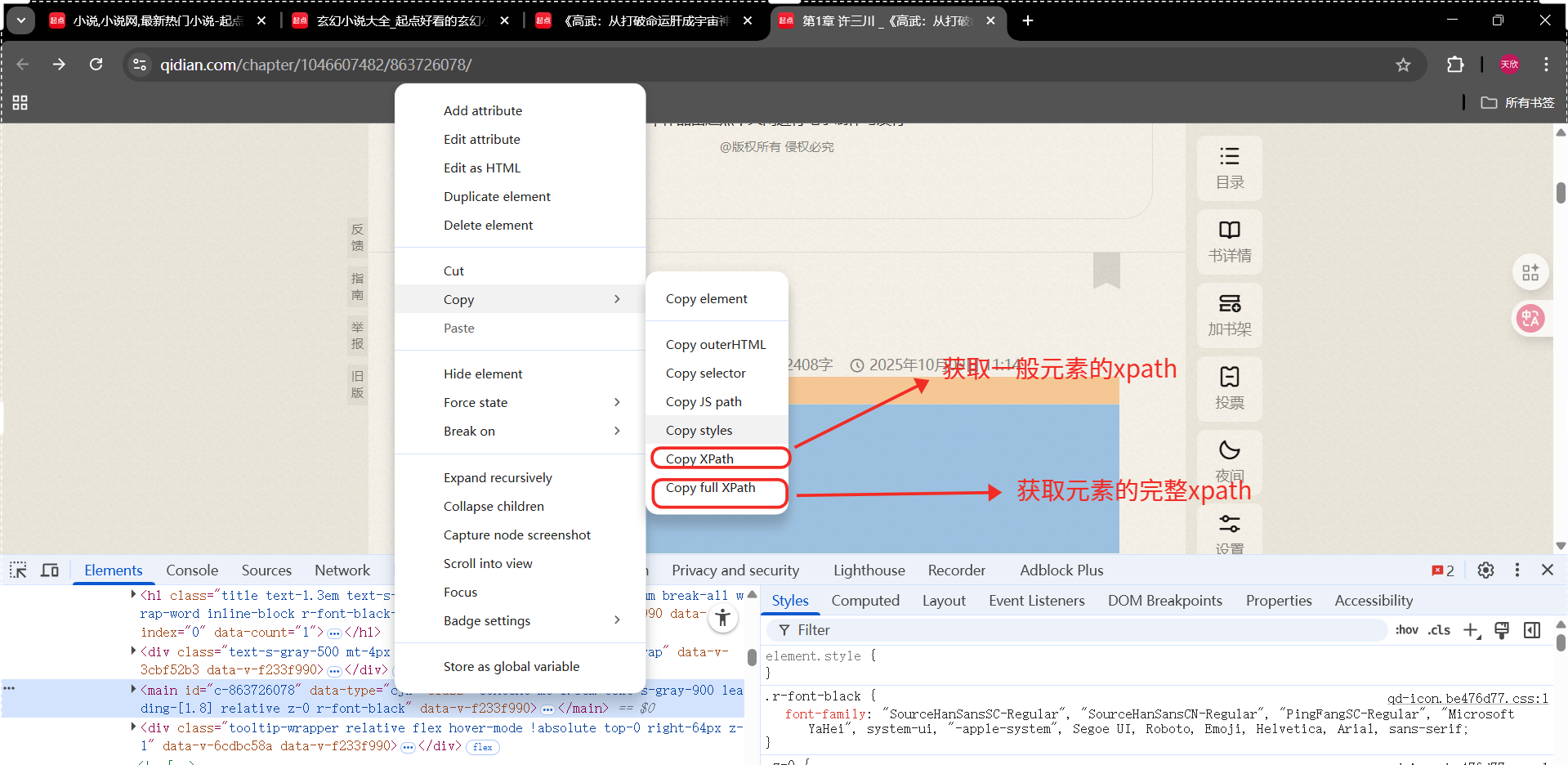
因为小说内容的xpath不同(前端结构相同),我们可以采取获取当前元素的完整xpath的方法解决。(动态页面也可以用这种方法)
小说内容完整xpath
第一页:/html/body/div1/div/div2/div/div/div2/div/main
第二页:/html/body/div1/div/div2/div/div/div2/div/main
......
3、获取一本小说
代码如下:
python# 导入相关包 from DrissionPage import Chromium import os # 创建小说文件夹 os.makedirs('小说',exist_ok=True) page = Chromium() tab = page.get_tab() tab.get('https://www.qidian.com/',timeout=10) # 作品分类(玄幻按钮xpath) xuanhuan_btn = tab.ele('xpath://*[@id="classify-list"]/dl/dd[1]/a') # 点击 xuanhuan_btn.click() # 获取新页面(玄幻小说分区页面) tab1 = page.latest_tab # 因为强推小说的xpath结构类似,可以采用字符串拼接的方法用循环便利 s = 'xpath:/html/body/div[1]/div[4]/div[2]/div[1]/div/ul/li[1]/em/h2/a' # xpath定位当前的强推小说 tuaijian_btn = tab1.ele(s) # 点击当前的强推小说 tuaijian_btn.click() # 获取小说页面 tab2 = page.latest_tab # 获取小说的连载章节数,用字符串replace方法进行替换只保留章节数 a = tab2.ele('xpath://*[@id="bookCatalogSection"]/div[1]/p/span[1]').text.replace('连载共', '').replace('章', '') # 将章节数转换为int类型 a = int(a) # 点击阅读小说 tab2.ele('xpath://*[@id="readBtn"]').click() # 定义空字符变量,用来保存小说名,用来后面的保存路径中 xiaoshuo_name = '' # 获取小说页面 tab3 = page.latest_tab # 通过循环来获取每一章的小说内容 for i in range(a): # 小说第一章 if i == 0: # 小说名字 name = tab3.ele('xpath://*[@id="r-titlePage"]/div/h1') xiaoshuo_name = name.text # 创建小说目录 os.makedirs(f'小说/{name.text}', exist_ok=True) # xpath定位小说章节名 zhangjie = tab3.ele('xpath://*[@id="reader-content"]/div/div/div[2]/div/h1') # xpath定位小说章节内容 t = tab3.ele('xpath:/html/body/div[1]/div/div[2]/div/div/div[2]/div/main') # 保存该章节的小说 open(f'小说/{name.text}/{zhangjie.text}.txt', 'w', encoding='utf-8').write(t.text) # xpath定位下一章按钮并点击 tab3.ele('xpath://*[@id="reader-content"]/div/div/div[5]/div/a[2]').click() # 小说其余章 else: # 小说章节名 zhangjie = tab3.ele('xpath://*[@id="reader-content"]/div/div/div[2]/div/h1') # 小说章节内容 t = tab3.ele('xpath:/html/body/div[1]/div/div[2]/div/div/div[2]/div/main') # 小说章节名中可能重新"/"这样会影响txt文件的保存 # 根据小说章节名中是否会出现"/"来进行不同的保存操作 if zhangjie.text.find('/') == -1: open(f'小说/{xiaoshuo_name}/{zhangjie.text}.txt', 'w', encoding='utf-8').write(t.text) else: # 将"/"替换为"/" p = zhangjie.text.replace('/','') open(f'小说/{xiaoshuo_name}/{p}.txt', 'w', encoding='utf-8').write(t.text) # 点击下一章按钮 tab3.ele('xpath://*[@id="reader-content"]/div/div/div[5]/div/a[3]').click() page.quit()
4、获取强推的10本小说
在之前的博客中有相关方法的介绍在这了不详细讲解,完整代码如下:
python# 导入相关包 from DrissionPage import Chromium import os # 创建小说文件夹 os.makedirs('小说',exist_ok=True) page = Chromium() tab = page.get_tab() tab.get('https://www.qidian.com/',timeout=10) # 作品分类(玄幻按钮xpath) xuanhuan_btn = tab.ele('xpath://*[@id="classify-list"]/dl/dd[1]/a') # 点击 xuanhuan_btn.click() # 获取新页面(玄幻小说分区页面) tab1 = page.latest_tab for i in range(1,11): # 因为强推小说的xpath结构类似,可以采用字符串拼接的方法用循环便利 s = 'xpath:/html/body/div[1]/div[4]/div[2]/div[1]/div/ul/li[' + str(i) + ']/em/h2/a' # xpath定位当前的强推小说 tuaijian_btn = tab1.ele(s) # 点击当前的强推小说 tuaijian_btn.click() # 获取小说页面 tab2 = page.latest_tab # 获取小说的连载章节数,用字符串replace方法进行替换只保留章节数 a = tab2.ele('xpath://*[@id="bookCatalogSection"]/div[1]/p/span[1]').text.replace('连载共', '').replace('章', '') # 将章节数转换为int类型 a = int(a) # 点击阅读小说 tab2.ele('xpath://*[@id="readBtn"]').click() # 定义空字符变量,用来保存小说名,用来后面的保存路径中 xiaoshuo_name = '' # 获取小说页面 tab3 = page.latest_tab # 通过循环来获取每一章的小说内容 for i in range(a): # 小说第一章 if i == 0: # 小说名字 name = tab3.ele('xpath://*[@id="r-titlePage"]/div/h1') xiaoshuo_name = name.text # 创建小说目录 os.makedirs(f'小说/{name.text}', exist_ok=True) # xpath定位小说章节名 zhangjie = tab3.ele('xpath://*[@id="reader-content"]/div/div/div[2]/div/h1') # xpath定位小说章节内容 t = tab3.ele('xpath:/html/body/div[1]/div/div[2]/div/div/div[2]/div/main') # 保存该章节的小说 open(f'小说/{name.text}/{zhangjie.text}.txt', 'w', encoding='utf-8').write(t.text) # xpath定位下一章按钮并点击 tab3.ele('xpath://*[@id="reader-content"]/div/div/div[5]/div/a[2]').click() # 小说其余章 else: # 小说章节名 zhangjie = tab3.ele('xpath://*[@id="reader-content"]/div/div/div[2]/div/h1') # 小说章节内容 t = tab3.ele('xpath:/html/body/div[1]/div/div[2]/div/div/div[2]/div/main') # 小说章节名中可能重新"/"这样会影响txt文件的保存 # 根据小说章节名中是否会出现"/"来进行不同的保存操作 if zhangjie.text.find('/') == -1: open(f'小说/{xiaoshuo_name}/{zhangjie.text}.txt', 'w', encoding='utf-8').write(t.text) else: # 将"/"替换为"/" p = zhangjie.text.replace('/','') open(f'小说/{xiaoshuo_name}/{p}.txt', 'w', encoding='utf-8').write(t.text) # 点击下一章按钮 tab3.ele('xpath://*[@id="reader-content"]/div/div/div[5]/div/a[3]').click() tab3.close() tab2.close() page.quit()