论文链接:https://arxiv.org/abs/2502.09956
代码链接:https://github.com/stair-lab/kg-gen
Abstract
近年来,构建知识图谱Knowledge graph(KG)基础模型的研究引起了广泛关注,但一个根本性的问题是:知识图谱数据相对稀缺。现有的高质量知识图谱大多由人工标注生成,通过模式匹配或早期自然语言处理技术提取而来。人工生成的知识图谱数量有限,而自动抽取的知识图谱往往质量堪忧。
本文提出了一种解决数据稀缺问题的新方法------一个文本到知识图谱(text-to-KG)生成器 KGGen 。该方法利用语言模型从纯文本中生成高质量的知识图谱。与其他知识图谱抽取器不同,KGGen 会对相关实体进行聚类,以减少生成图谱中的稀疏性。
KGGen 以 Python 库的形式发布(可通过 pip install kg-gen 安装),使所有研究者都能方便使用。与此同时,作者还发布了首个名为 MINE(Measure of Information in Nodes and Edges) 的基准,用于评估抽取器从纯文本中生成有用知识图谱的能力。我们将该工具与现有抽取器进行了对比实验,结果显示 KGGen 在性能上显著优于其他方法。
有点好奇之前读light rag 的时候就已经其实是直接用llm去提取文本了,这个到底有哪里特殊的呢?
Contribution
-
我们提出了 KGGen,一个使用语言模型(LMs)从纯文本中抽取高质量知识图谱(KGs)的开源工具包。该工具以 Python 库的形式提供。
-
我们开发了首个用于文本到知识图谱**(text-to-KG)抽取器的基准测试(benchmark)**,从而能够公平地比较现有方法的性能。
-
我们证明了 KGGen 在该基准测试上比现有的抽取方法高出 18%,展现了其利用语言模型生成功能性知识图谱的潜力。
这个基准值得重点关注
Related Works
OPENIE 开放信息抽取
开放信息抽取(Open Information Extraction,简称 OpenIE )由斯坦福大学的 CoreNLP 团队基于 Angeli 等人(2015)的研究实现。其基本流程是:首先利用 Stanford CoreNLP 流水线为每个句子生成"依存句法解析图"(dependency parse)。随后,一个经过训练的分类器会遍历依存解析图中的每一条边,判断是否应当创建(Yield) 、继续(Recurse)或 停止(Stop)处理当前子句。通过这些决策,复杂的句子被拆分为更短且语义完整的独立子句。
在此基础上,系统会从这些子句中生成三元组形式的结构化信息------(主语,关系,宾语) ,并为每个三元组分配一个置信度评分。
由于 OpenIE 不依赖输入文本的特定格式或领域结构,它能够处理几乎任何类型的文本。
Graph Rag
微软开发了 GraphRAG ,一种将基于图的知识检索 与语言模型(LMs)相结合的方法(Larson & Truitt, 2024)。作为第一步,GraphRAG 提供了从纯文本生成知识图谱(KG)的功能,用以构建其内部数据库。
在该过程中,GraphRAG 通过 提示语言模型(prompting LMs)来提取节点(实体)及其之间的关系(边),从而生成初始图结构。为了提升抽取质量,系统使用了少样本提示(few-shot prompting) ,向语言模型提供高质量抽取的示例。
随后,GraphRAG 会将连接紧密的节点聚合为社群(communities),并为每个社群生成一段摘要,用以消除冗余信息。最终,图谱由这些社群构成节点,各社群间关系的摘要句子则作为边,从而形成一个结构化、语义浓缩的知识图谱。
Method
KGGen:从纯文本生成知识图谱
与大多数基于大型语言模型(LLM)的知识图谱(KG)抽取方法不同,我们采用一种multi-stage method(使用 GPT-4o),其主要步骤和Python 工具包 kg-gen对应的模块分别为:
-
从每个源文本中抽取实体和关系 ;"generate" 模块:负责从文本中进行初始抽取;
-
在多个来源之间聚合图结构 ;"aggregate" 模块:用于整合不同来源的图数据;
-
迭代地聚类实体和关系 。"cluster" 模块:用于动态地聚类实体并进行解析度调整。
在整个流程中,我们使用 DSPy 框架 来定义函数签名,以确保语言模型(LLM)的输出结果符合一致的 JSON 格式。在实验中,我们使用 GPT-4o,但该实现可适用于任何由 DSPy 支持的语言模型。
我们对 LLM 提示(prompting)施加了严格约束,以降低语义上相似但重复的实体出现的概率。(这个具体看看咋个回事)
此外,我们对抽取出的边与关系进行了多次遍历(multi-pass) ,以便将相似的实体进行聚类并减少关系类型的数量。这种整合与聚类 操作能有效防止生成稀疏的知识图谱,因为稀疏图可能会在标准嵌入算法(如 TransE)下产生无意义的图嵌入结果。
我们的抽取方法包含若干步骤,下面将对此进行概述。每个步骤所使用的具体提示词(prompt)可在 附录 A(Appendix A) 中找到,整体流程如 图 1(Figure 1) 所示。
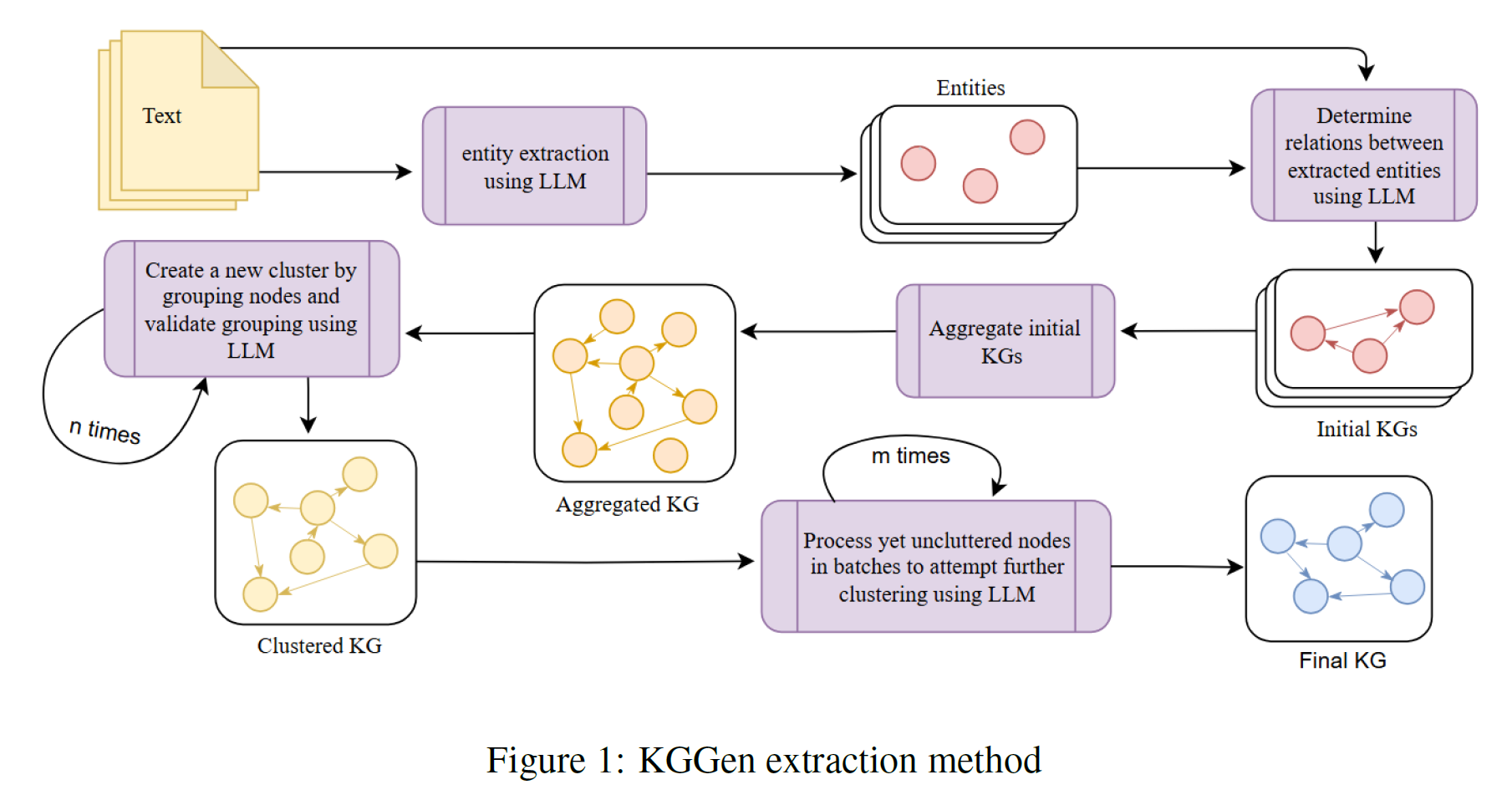
GENERATE -- ENTITY AND RELATION EXTRACTION
1) 以非结构化文本 作为输入,生成由三元组(triples)组成的初始知识图谱。
在这一过程中,我们通过 DSPy 签名(signature) 调用 GPT-4o 模型 ,指示模型以结构化格式输出检测到的实体(entities) 。(具体怎么结构化)
Prompt for extracting entities: Extract key entities from the given text. Extracted entities are nouns, verbs, or adjectives, particularly regarding sentiment. This is for an extraction task, please be thorough and accurate to the reference text.
1) 我们进行第二次基于 DSPy 的语言模型调用,指示模型根据已识别的实体集合和源文本,输出相应的主语--谓语--宾语(subject--predicate--object)关系 。
实验结果表明,这种两步式(2-step)抽取方法能够更好地确保实体之间的一致性。
Prompt for extracting relations: Extract subject-predicate-object triples from the assistant message. A predicate (1-3 words) defines the relationship between the subject and object. Relationship may be fact or sentiment based on assistant's message. Subject and object are entities. Entities provided are from the assistant message and
prior conversation history, though you may not need all of them. This is for an extraction task, please be thorough, accurate, and faithful to the reference text.
AGGREGATE -- AGGREGATION
在从每个源文本中抽取出三元组之后,我们将所有来源中的唯一实体与边(entities and edges)收集起来,并合并为一个统一的图结构 。
在此过程中,所有实体与边的字符串均被标准化为小写形式 ,以消除大小写差异带来的重复。
该聚合步骤的主要作用是减少知识图谱中的冗余 。
聚合阶段不依赖语言模型(LLM),其运算完全在结构层面完成。
CLUSTER -- ENTITY AND EDGE CLUSTERING
在完成抽取与聚合后,初始图通常仍包含大量重复或同义实体 以及可能冗余的边 。
因此,聚类阶段是我们知识图谱抽取方法中的核心创新点 ,其目标是合并那些代表相同现实世界实体或概念的节点与边。
我们采用一种基于语言模型的迭代式聚类方法(iterative LLM-based clustering) ,灵感来源于"人类群体通过讨论逐步达成术语统一"的过程。
与一次性解决全部聚类问题(在大规模实体集上难以实现)不同,KGGen 采用逐步顺序聚类,具体过程如下:
-
将整个实体列表输入语言模型上下文中,要求模型提取一个潜在的聚类。
(可选)可通过传递"聚类指令字符串(cluster-instruction string)"来指导聚类方式。
默认指令会考虑近义词、时态差异及单复数变化等因素。
-
使用 LLM-as-a-Judge 调用对聚类进行验证,模型以**二元(是/否)**形式回应验证结果。若聚类通过验证,则将其加入聚类集合,并从实体列表中移除已聚类的实体。
-
为聚类分配一个标签,用以最准确地表示该聚类中实体的共同含义。
-
重复步骤 1--3,直到连续 n 次循环未成功生成新的聚类为止。
-
对剩余未聚类的实体按批次(batch size = b)进行检查,判断它们是否应当加入已有的聚类。
-
每当有新实体被加入某个聚类时,再次使用 LLM-as-a-Judge 进行验证。
-
重复步骤 5--6,直到没有剩余实体需要检查为止。
对于**边(edges)**的聚类,我们使用相同的流程,但在提示(prompt)上做了轻微调整以适配关系结构。
该聚类过程使我们能够生成更加稠密(dense)且具有语义一致性的知识图谱 ,从而利于后续生成有意义的图嵌入(embeddings)。
举一个实际例子,在我们的某个原始知识图谱中,出现了"vulnerabilities(漏洞)"、"vulnerable(脆弱的)"和"weaknesses(弱点)"这几个实体。
尽管它们在表面形式上不同,但语义上高度相似,因此在我们的图谱中应被视为等价实体并合并为一类。
一个用于评估抽取表现的Benchmark
虽然目前已有一些方法尝试从纯文本中抽取知识图谱(KGs),但由于缺乏标准化的评测基准,该领域的研究进展难以客观衡量 。
为了解决这一问题,我们提出了 MINE(Measure of Information in Nodes and Edges) ------第一个用于评估知识图谱抽取器性能的基准测试。
MINE 衡量抽取器将文本内容转化并提炼为知识图谱的能力。
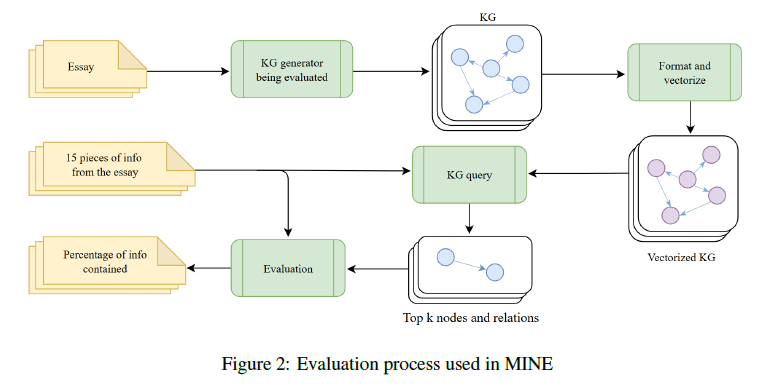
MINE 的构建过程包括为 100 篇文章 生成对应的知识图谱,每篇文章代表一个独立的文本数据来源。
每篇文章约 1000 字 ,由语言模型(LLM)根据 100 个不同主题 生成,主题范围涵盖历史、艺术、科学、伦理学与心理学等多个领域。
为了评估生成知识图谱的质量,我们设计了一种度量方法,用以衡量生成的知识图谱在多大程度上能够捕获文章中的关键信息。
从每篇文章中,我们通过语言模型(使用附录 C 中的抽取提示)抽取出 15 条事实性陈述(facts) 。
这些事实被定义为文章中明示的信息,并由人工验证其真实性与来源的准确性。
MINE 评估的核心在于:一个文本到知识图谱(text-to-KG)抽取器能否在其生成的知识图谱中捕获并表达这 15 条事实。
对于每篇文章,使用被测试的文本生成对应的 KG。
生成后的 KG 节点使用 SentenceTransformers 库中的 all-MiniLM-L6-v2 模型 进行向量化,使得我们能够通过**余弦相似度(cosine similarity)**计算每个节点与事实句子的语义相似性。
接着,对于每种知识图谱生成方法,我们在每篇文章的 KG 上执行以下评测步骤:
-
对于每条事实,找到与其语义最相近的 前 k 个节点(top-k nodes);
-
对每个 top-k 节点,进一步找出与其通过两条关系以内相连的所有节点;
-
将这些节点及其关系作为查询结果返回。
然后,我们使用语言模型(LLM)对这些查询结果进行评估。
模型会接收特定的提示(详见附录 C),并输出二元判定结果:
-
若仅依据查询到的节点与关系即可推断出该事实,则输出 1;
-
否则输出 0。
对于每篇文章的每个知识图谱生成器,其最终的 MINE 得分 定义为 15 次评估中输出为 1 的比例 。
这种系统化的评估方法能够客观比较不同方法在从文本中捕获与检索信息方面的准确性与有效性。
整个评测流程如 图 2(Figure 2) 所示。
Experiment
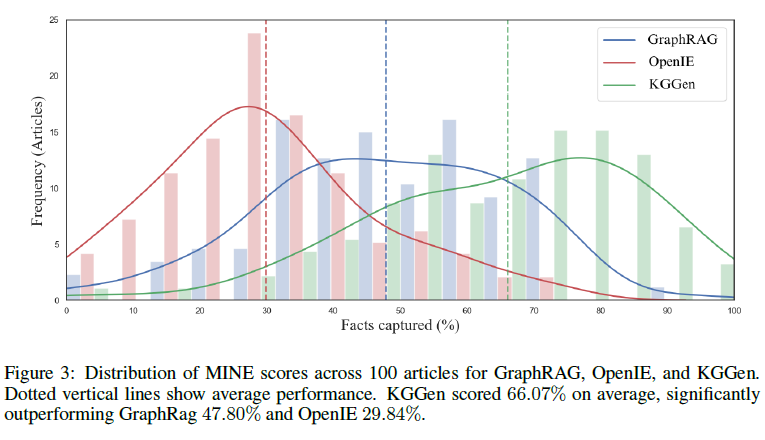

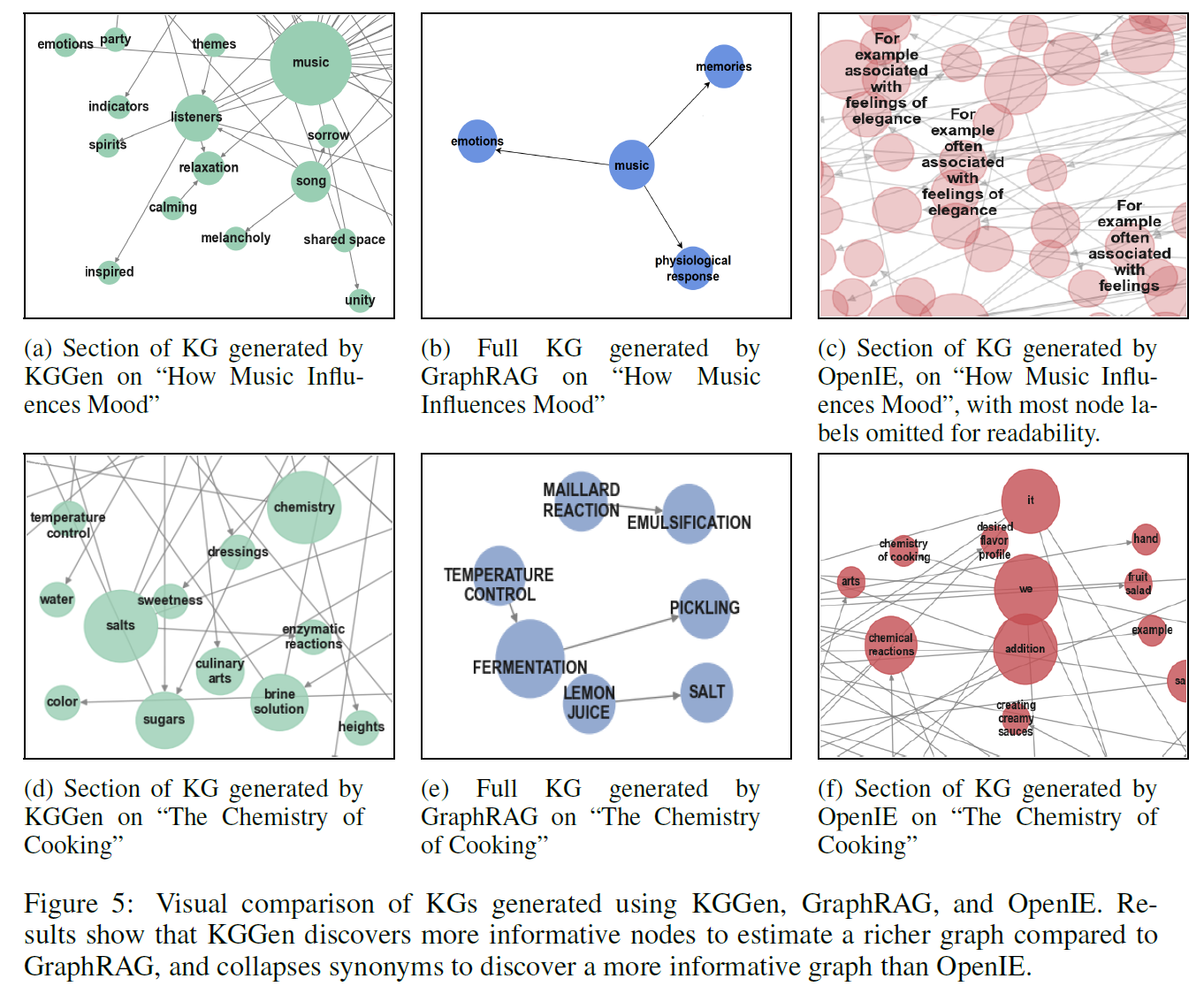
Future
我们提出了 MINE ------首个用于从纯文本中抽取知识图谱(KG)的评测基准。
为了解决阻碍基于图的基础模型发展的数据稀缺问题 ,我们还提出了 KGGen ,一种从纯文本生成知识图谱的抽取器,其在 MINE 基准上比现有方法提升了最高达 18% 的性能。
尽管 KGGen 已在性能上显著优于现有方法,但生成的知识图谱仍存在一些问题,例如过度聚类(over-clustering)或聚类不足(under-clustering) 。
因此,未来的研究可以针对更高质量的聚类方法展开,以进一步提升知识图谱的准确性与语义一致性。
此外,我们当前的评测基准 MINE 主要用于衡量抽取器在相对较短的语料 上的表现,而知识图谱在实际应用中往往用于高效处理海量信息 。这个倒是真的,所以其实图谱的层次性和多跳图谱可能挺重要的,有一说一不应该所有实体都在同一个维度上
未来,MINE 的扩展方向可包括:
在更大规模的语料库上进行评测,以更好地反映不同抽取技术在真实场景下的实用性与可扩展性。