人工智能的三个层次
人工智能 AI 机器学习 ML 深度学习 DL 神经网络 NN
简单理解:
- 人工智能(AI):让机器表现出智能行为
- 机器学习(ML):让机器从数据中学习
- 深度学习(DL):使用多层神经网络进行学习
- 神经网络(NN):模拟人脑神经元的结构
类比:教小孩认猫
想象一下,你如何教一个小孩认识猫?
你(老师) 小孩(学习者) 展示很多猫的图片 观察猫的特征 记住:有毛、有尾巴、 尖耳朵、四条腿... 展示狗的图片 区分:这不是猫 学习:猫和狗的区别 展示新的猫图片 "这是猫!" 你(老师) 小孩(学习者)
神经网络的学习过程和这个过程非常相似:
- 你给机器看很多数据(猫的图片)
- 机器学习特征(如何识别猫)
- 机器学会后,就能识别新的猫
什么是机器学习?
传统编程 vs 机器学习
传统编程
输入数据 规则/程序 输出结果 需要人工编写规则
示例:识别手写数字
python
# 传统方法:需要写很多 if-else 规则
if 数字有圆形结构:
if 只有一个圆形:
return "0"
elif 有两个圆形:
return "8"
# ... 需要写无数条规则,而且很难覆盖所有情况机器学习
输入数据 训练数据 机器学习算法 学习到的模型 输出结果 机器自动学习规则
示例:识别手写数字
python
# 机器学习方法:给机器看很多数字的例子
训练数据 = [10000张手写数字图片, 对应的标签]
模型 = 机器学习算法(训练数据)
# 模型自动学会了如何识别数字机器学习的核心思想
让机器从数据中自动学习规律,而不是人工编写规则
什么是深度学习?
深度学习的"深度"是什么意思?
深度学习中的"深度"指的是神经网络的层数。
深度网络(深度学习) 浅层网络(传统机器学习) 隐藏层1 输入 隐藏层2 隐藏层3 ... 隐藏层N 输出 隐藏层1 输入 输出
为什么需要"深度"?
类比:理解一幅画

每一层理解不同层次的特征:
- 第1层:识别边缘、线条
- 第2层:识别形状(圆形、方形)
- 第3层:识别物体(眼睛、鼻子)
- 第4层:识别复杂模式(人脸、猫)
- 第5层:理解语义(表情、情感)
深度学习的优势
✅ 自动特征提取 :不需要人工设计特征
✅ 处理复杂数据 :图像、语音、文本等
✅ 强大的表达能力:可以学习非常复杂的模式
什么是神经网络?
生物神经元的启发
神经网络是受到人脑神经元的启发而设计的。
人工神经元 生物神经元 权重 w1 输入 x1 权重 w2 输入 x2 权重 w3 输入 x3 求和 激活函数 输出 y 细胞体 树突 轴突 突触 下一个神经元
人工神经元的结构
权重 w1 权重 w2 权重 w3 x1 Σ 求和 x2 x3 激活函数 f y 输出
数学表达:
输出 = f(w1×x1 + w2×x2 + w3×x3 + b)其中:
- x1, x2, x3:输入数据
- w1, w2, w3:权重(weights)
- b:偏置(bias)
- f:激活函数
神经网络的组成结构
1. 输入层(Input Layer)
作用:接收原始数据
示例:
- 图像识别:输入像素值
- 文本分类:输入词向量
- 语音识别:输入音频特征
原始数据 输入层 特征向量
2. 隐藏层(Hidden Layers)
作用:提取和组合特征
类比:就像工厂的生产线,每一层都在加工产品
输入层
原始数据 隐藏层1
提取简单特征 隐藏层2
组合成复杂特征 隐藏层3
更高级的特征 输出层
最终结果
每一层的作用:
- 隐藏层1:识别边缘、线条
- 隐藏层2:识别形状、纹理
- 隐藏层3:识别物体、模式
3. 输出层(Output Layer)
作用:产生最终结果
示例:
- 分类任务:输出各类别的概率
- 回归任务:输出数值
- 生成任务:生成新的数据
隐藏层输出 输出层 类别1: 0.02
类别2: 0.95
类别3: 0.03
4. 权重(Weights)
作用:控制信息传递的强度
类比:就像水管上的阀门,控制水流的大小
重要理解:
- 权重决定了每个输入的重要性
- 权重是通过学习得到的
- 学习的过程就是调整权重的过程
5. 偏置(Bias)
作用:调整神经元的激活阈值
类比:就像天平上的砝码,让结果偏向某个方向
输入加权和 加上偏置 b 激活函数 输出 偏置让模型更灵活
可以学习不同的模式
数学表达:
输出 = f(权重×输入 + 偏置)6. 激活函数(Activation Function)
作用:引入非线性,让网络能够学习复杂模式
为什么需要激活函数?
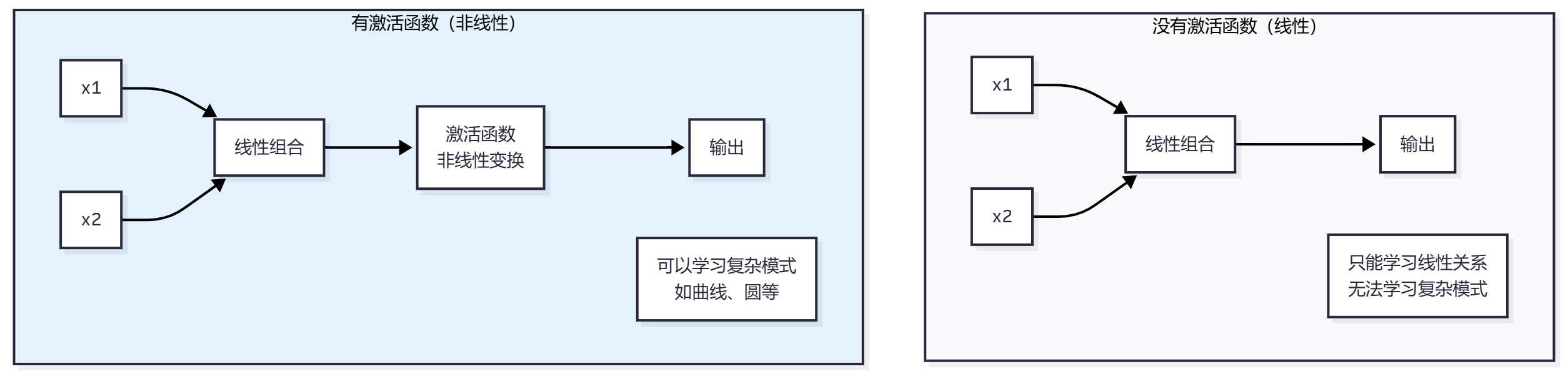
常见的激活函数:
ReLU(Rectified Linear Unit)
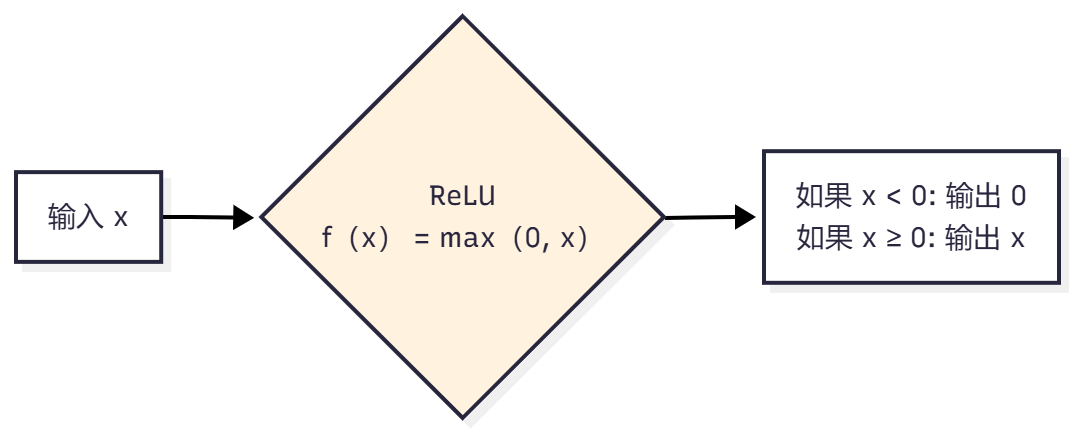
特点:
- ✅ 计算简单,速度快
- ✅ 解决梯度消失问题
- ✅ 最常用的激活函数
Sigmoid
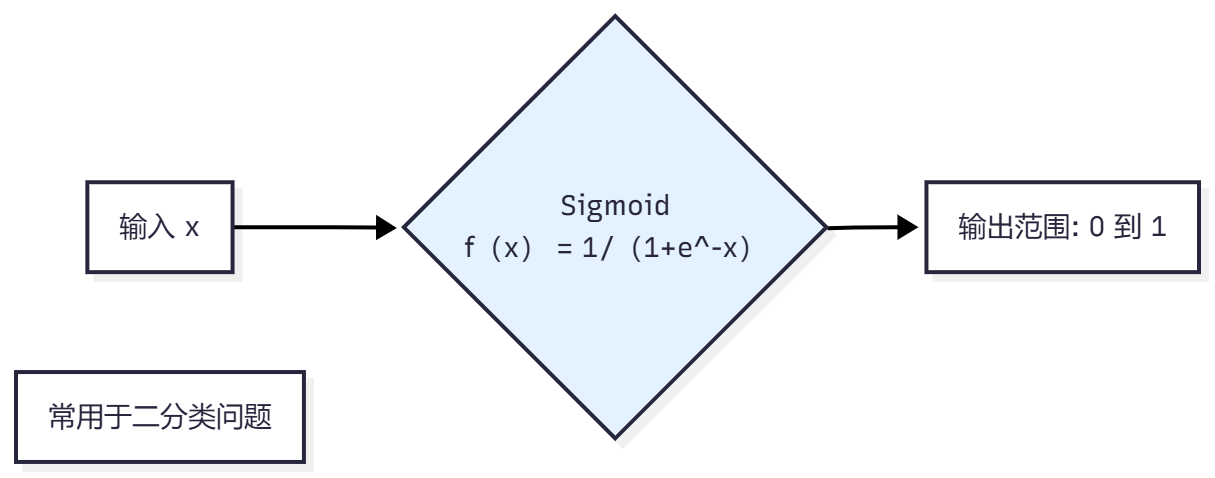
Tanh
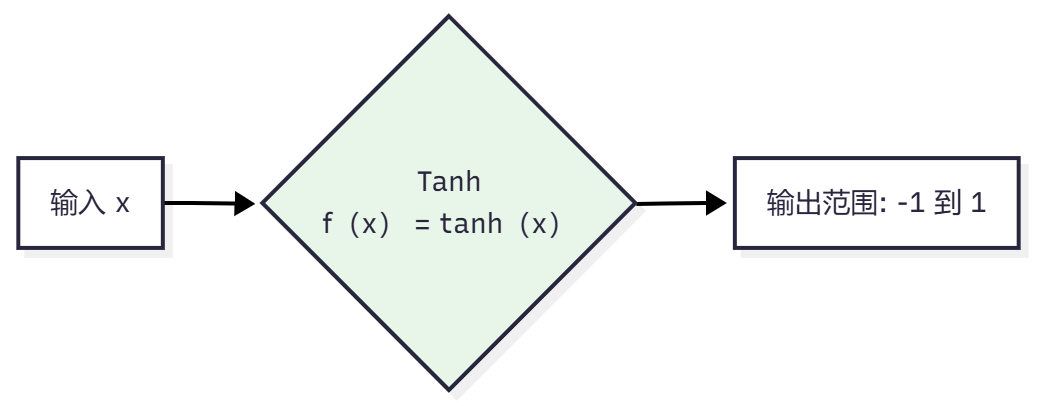
7. 损失函数(Loss Function)
作用:衡量预测结果和真实结果的差距
类比:就像考试评分,分数越低越好
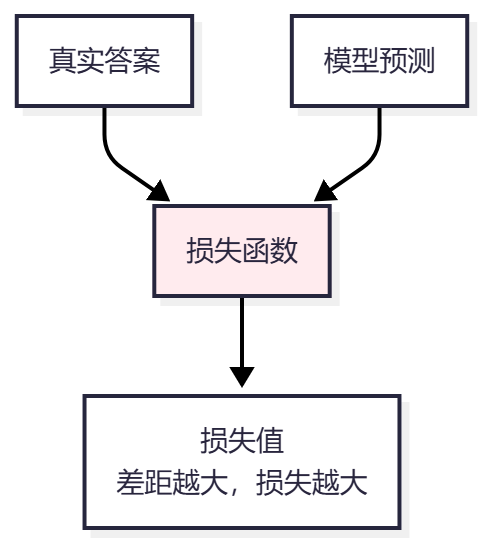
常见损失函数:
均方误差(MSE)
用于回归任务:
MSE = (1/n) × Σ(预测值 - 真实值)²交叉熵(Cross Entropy)
用于分类任务:
CrossEntropy = -Σ(真实标签 × log(预测概率))8. 优化器(Optimizer)
作用:决定如何更新权重以减小损失
核心算法:梯度下降(后面详细讲解)
当前权重 计算损失 计算梯度 更新权重 新的权重
神经网络是如何工作的?
前向传播(Forward Propagation)
过程:数据从输入层流向输出层
输入层 隐藏层1 隐藏层2 输出层 输入数据 × 权重1 加权求和 + 偏置 激活函数 输出 × 权重2 加权求和 + 偏置 激活函数 输出 × 权重3 最终输出 输入层 隐藏层1 隐藏层2 输出层
完整的前向传播示例
场景:识别图片是否是猫

数学过程:
python
# 伪代码示例
def forward_propagation(input_data):
# 第1层
layer1_input = input_data @ weights1 + bias1
layer1_output = relu(layer1_input)
# 第2层
layer2_input = layer1_output @ weights2 + bias2
layer2_output = relu(layer2_input)
# 第3层
layer3_input = layer2_output @ weights3 + bias3
layer3_output = relu(layer3_input)
# 输出层
output_input = layer3_output @ weights4 + bias4
output = sigmoid(output_input)
return output神经网络是如何学习的?
学习的本质
学习 = 调整权重和偏置,使预测结果越来越准确
否 是 初始化权重
随机值 训练数据 计算损失 调整权重 损失减小 损失足够小? 学习完成
学习的完整过程
否 是 1. 准备数据
训练数据 + 标签 2. 初始化权重
随机值 3. 前向传播
计算预测结果 4. 计算损失
预测 vs 真实 5. 反向传播
计算梯度 6. 更新权重
沿着梯度方向调整 7. 检查
是否收敛? 8. 训练完成
反向传播(Backpropagation)
作用:计算每个权重对损失函数的梯度
类比:就像找错误的原因,知道哪里错了,就知道该改哪里

数学原理:
使用链式法则计算梯度:
∂L/∂w = ∂L/∂y × ∂y/∂z × ∂z/∂w
其中:
L: 损失函数
y: 输出
z: 加权和
w: 权重权重更新的公式
python
# 梯度下降更新规则
new_weight = old_weight - learning_rate × gradient
# 其中:
# learning_rate: 学习率(步长)
# gradient: 梯度(损失对权重的导数)可视化理解:
当前位置
损失较大 计算梯度
方向 沿着梯度方向
移动一小步 新位置
损失较小 重复过程 到达最低点
损失最小
梯度下降:优化的核心
什么是梯度?
梯度:函数在某点的斜率,指向函数值增长最快的方向
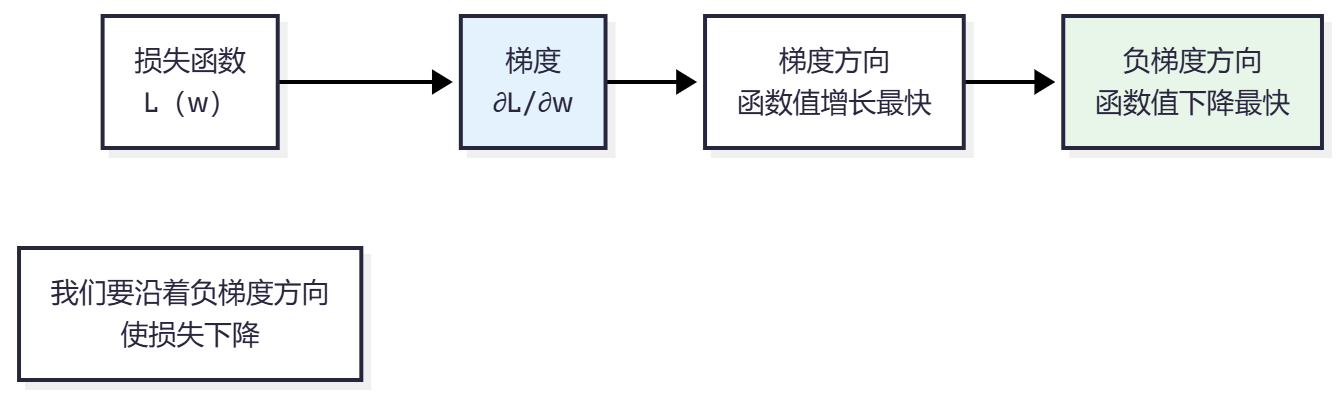
梯度下降的直观理解
类比:盲人下山
盲人(模型) 损失函数 站在山顶(初始位置) 用脚感知坡度(计算梯度) 找到最陡的下坡方向(梯度方向) 沿着这个方向走一小步(更新权重) 重复感知和移动 到达山谷底部(损失最小) 盲人(模型) 损失函数
梯度下降的类型
1. 批量梯度下降(Batch Gradient Descent)
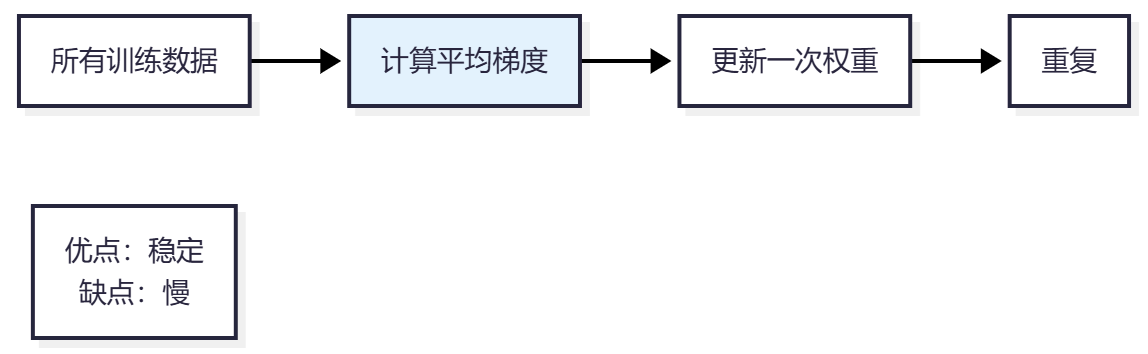
特点:
- 使用所有数据计算梯度
- 每次更新需要遍历所有数据
- 收敛稳定,但速度慢
2. 随机梯度下降(SGD)
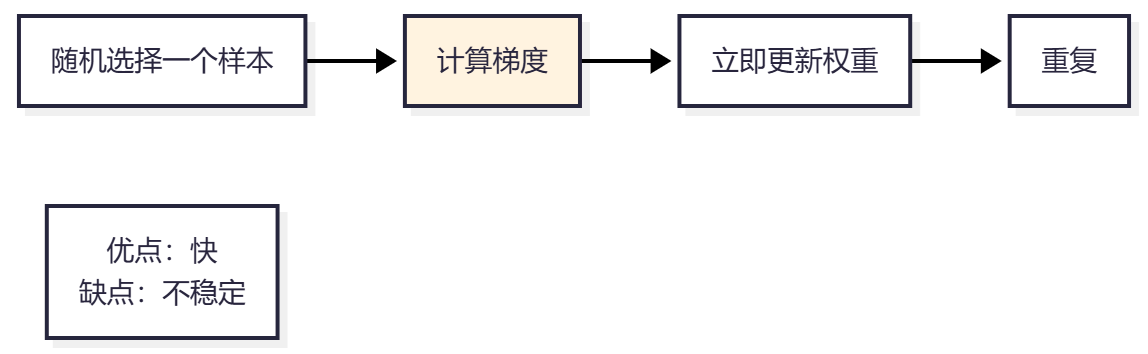
特点:
- 每次只用一个样本
- 更新频繁,速度快
- 可能震荡,不够稳定
3. 小批量梯度下降(Mini-batch SGD)
随机选择一批样本
如32个 计算平均梯度 更新权重 重复 平衡速度和稳定性
最常用
特点:
- 使用一小批数据(如32、64、128个样本)
- 平衡了速度和稳定性
- 最常用的方法
学习率(Learning Rate)
作用:控制每次更新的步长
太小 合适 太大 当前位置 学习率 更新太慢
需要很多步 更新适中
快速收敛 更新太大
可能跳过最优解
常见学习率设置:
- 初始值:0.01, 0.001, 0.0001
- 可以动态调整(学习率衰减)
学习后的数据存储在哪里?
模型参数的存储
学习后的数据就是模型的参数:权重和偏置
训练完成 模型参数 所有权重矩阵
W1, W2, W3, ... 所有偏置向量
b1, b2, b3, ... 保存到文件
.pth, .ckpt, .h5
参数存储示例
假设一个简单的神经网络:
python
# 网络结构
输入层: 784个神经元(28×28图像)
隐藏层1: 512个神经元
隐藏层2: 256个神经元
输出层: 10个神经元(10个类别)
# 存储的参数
权重矩阵1: 784 × 512 = 401,408个参数
偏置向量1: 512个参数
权重矩阵2: 512 × 256 = 131,072个参数
偏置向量2: 256个参数
权重矩阵3: 256 × 10 = 2,560个参数
偏置向量3: 10个参数
总计: 535,786个参数参数存储的位置
训练过程 参数存储在内存 训练完成后 保存到磁盘 模型文件
.pth, .ckpt等 推理时加载 参数加载到内存 使用参数进行预测
模型文件的结构
python
# PyTorch 模型文件示例
model_state = {
'layer1.weight': tensor([[0.1, 0.2, ...], ...]),
'layer1.bias': tensor([0.05, 0.03, ...]),
'layer2.weight': tensor([[0.15, 0.25, ...], ...]),
'layer2.bias': tensor([0.02, 0.01, ...]),
...
}
# 保存和加载
torch.save(model_state, 'model.pth')
model.load_state_dict(torch.load('model.pth'))为什么参数就是"知识"?
类比:就像人脑的记忆
学习过程 调整权重 权重记住模式 新的输入 权重提取记忆 给出答案
理解:
- 权重不是存储具体的图片或文字
- 而是存储如何识别和处理 这些数据的模式
- 就像人记住"如何识别猫",而不是记住所有见过的猫的图片
为什么通过学习就能回答问题?
学习的本质:模式识别
神经网络学习的是数据的模式和规律
输入问题 神经网络提取特征 匹配学习到的模式 找到对应的答案模式 输出答案
具体示例:识别猫
训练阶段
训练数据 神经网络 学习过程 重复 输入:猫的图片 提取特征(边缘、形状等) 调整权重 学习:有这些特征→是猫 输入:狗的图片 提取特征 调整权重 学习:有这些特征→是狗 重复很多次 权重记住了猫和狗的模式 训练数据 神经网络 学习过程 重复
推理阶段
用户 训练好的网络 学习到的权重 输入新图片:"这是什么?" 提取特征(边缘、形状、纹理) 匹配学习到的模式 匹配到"猫"的模式 输出:这是猫 "这是猫!" 用户 训练好的网络 学习到的权重
为什么能回答问题的原理
1. 特征提取
神经网络通过多层结构,逐层提取越来越抽象的特征:

2. 模式匹配
训练好的权重包含了学习到的模式,新的输入会与这些模式匹配:
新输入的特征 模式匹配 学习到的模式1
猫的模式 学习到的模式2
狗的模式 学习到的模式N
... 找到最匹配的模式 输出对应答案
3. 概率分布
神经网络输出的是概率分布,选择概率最高的作为答案:

类比:医生诊断
医生(神经网络) 医学知识(训练权重) 病人(新输入) 学习医学知识 症状A + 症状B = 疾病X 描述症状 提取关键症状 匹配学习到的知识 找到对应疾病 诊断结果 医生(神经网络) 医学知识(训练权重) 病人(新输入)
神经网络就像医生:
- 训练 = 学习医学知识
- 权重 = 记住的知识
- 推理 = 用知识诊断新病人
完整的学习流程示例
场景:训练一个识别手写数字的神经网络
步骤 1:准备数据

步骤 2:设计网络结构

步骤 3:初始化权重
python
# 伪代码
weights1 = random_normal(784, 512) # 随机初始化
weights2 = random_normal(512, 256)
weights3 = random_normal(256, 10)
bias1 = zeros(512)
bias2 = zeros(256)
bias3 = zeros(10)步骤 4:训练循环

步骤 5:训练过程可视化
Epoch 1
准确率: 10%
损失: 2.3 Epoch 10
准确率: 45%
损失: 1.2 Epoch 50
准确率: 85%
损失: 0.5 Epoch 100
准确率: 98%
损失: 0.05
步骤 6:保存模型
python
# 保存训练好的权重
torch.save({
'weights1': weights1,
'weights2': weights2,
'weights3': weights3,
'bias1': bias1,
'bias2': bias2,
'bias3': bias3,
}, 'digit_classifier.pth')步骤 7:使用模型进行预测
用户 训练好的模型 学习到的权重 输入:新的手写数字图片 前向传播 使用学习到的权重 提取特征,匹配模式 输出:这是数字 7 (概率:0.95) 用户 训练好的模型 学习到的权重
神经网络的类型
1. 全连接神经网络(Fully Connected NN)
特点:每一层的神经元都与下一层的所有神经元连接
输入层 隐藏层1 隐藏层2 输出层 每层之间全连接
应用:分类、回归任务
2. 卷积神经网络(CNN)
特点:使用卷积层提取局部特征,适合图像处理
输入图像 卷积层
提取特征 池化层
降维 卷积层 池化层 全连接层 输出
应用:图像分类、目标检测
3. 循环神经网络(RNN)
特点:处理序列数据,有记忆能力
X_t RNN Y_t 延迟 X_t+1
应用:文本生成、语音识别
4. Transformer
特点:使用注意力机制,并行处理
输入序列 多头注意力 前馈网络 输出序列
应用:语言模型、翻译、GPT、BERT
总结与思考
核心概念总结
| 概念 | 作用 | 类比 |
|---|---|---|
| 神经元 | 基本计算单元 | 大脑中的神经细胞 |
| 权重 | 控制信息传递强度 | 水管上的阀门 |
| 偏置 | 调整激活阈值 | 天平的砝码 |
| 激活函数 | 引入非线性 | 开关 |
| 损失函数 | 衡量预测误差 | 考试的评分 |
| 梯度下降 | 优化方法 | 下山找最低点 |
| 反向传播 | 计算梯度 | 找错误的原因 |
学习的关键步骤
否 是 1. 准备数据 2. 设计网络 3. 初始化权重 4. 前向传播 5. 计算损失 6. 反向传播 7. 更新权重 8. 收敛? 9. 保存模型
常见误区
❌ 误区1 :神经网络是"黑盒",无法理解
✅ 事实:我们可以理解每一层在做什么,只是整体复杂
❌ 误区2 :数据越多越好
✅ 事实:质量比数量更重要,需要高质量的标注数据
❌ 误区3 :网络越深越好
✅ 事实:需要根据任务选择合适的深度,太深可能过拟合
❌ 误区4 :训练时间越长越好
✅ 事实:需要监控验证集,防止过拟合