本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。
AI发展日新月异,如果你还没搞懂RAG(检索增强生成) ,那可真的要掉队了!
简单说,RAG就是把 "信息查找" 和 "内容创作" 完美结合的技术。它让AI不再是"信口开河"的话痨,而是能查阅资料、给出靠谱答案的智能助手!
试想一下,让AI医生看病?你肯定希望它翻翻最新医学文献 再下诊断,而不是凭空瞎猜吧? 让AI客服解答问题?你肯定希望它查到你的订单信息再回答吧?
这就是RAG的核心价值------给AI装上"知识库引擎",让回答更可靠、更精准!
那么,这个神奇的技术到底是怎么工作的?别急,接下来就带你通过7大关键技术点,彻底搞懂这个正在改变AI应用格局的核心武器!
一、向量数据库--AI的"超级大脑"
- 传统数据库 :像严格的图书管理员,必须说出确切书名才能找到书。
- 向量数据库 :像善解人意的朋友,描述个大概意思,它就能懂你!
工作原理揭秘:
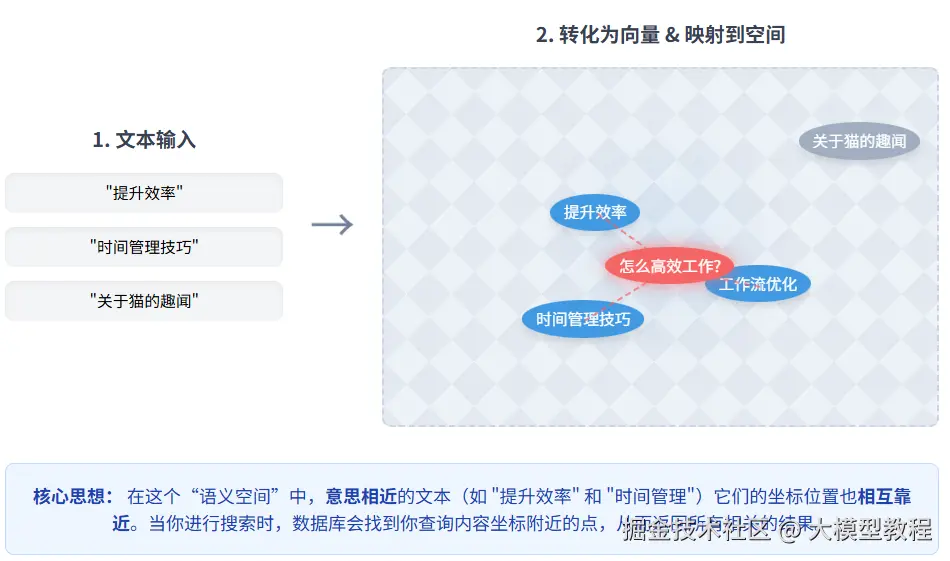
- 传统搜索 :搜"提升效率" → 只能找到标题精确包含这4个字的内容。
- 向量搜索 :搜"提升效率" → 能找到"时间管理"、"工作优化"、"生产力提升"等意思相关的内容。
为什么这么神奇? 因为它把所有文字都变成了数学向量!意思相近的词或句子,在向量空间里就"挨得近",就像把相关的想法都聚拢在一起。
举个栗子: 某公司智能客服,用户问"订单什么时候能到? "。向量数据库能理解这是在问"配送时间",从而精准匹配到物流信息,而不是死板地找"订单"、"时候"、"到"这几个词。
二、混合检索--速度与精度的"黄金搭档"
向量数据库虽然聪明,但也有"小脾气":
- 反应有时慢(计算向量相似度需要时间)。
- 用户有时就需要精确匹配(比如搜产品型号)。
解决方案?混合检索!鱼和熊掌我都要!
工作流程实战:
用户在电商平台搜"苹果手机iPhone 14":
- 关键词检索闪电出击:瞬间抓出所有标题包含"iPhone 14"的商品。
- 语义检索深度理解:捕捉用户可能也对"苹果手机"、"智能手机"、"最新款iPhone"感兴趣。
- 结果融合,双剑合璧 :既保证精准命中目标 ,又提供丰富的相关推荐,用户体验爽歪歪!

三、文档处理三步--分块、嵌入、索引
直接扔给AI一本《百科全书》?它肯定"消化不良"!RAG的秘诀是:化整为零,精细加工!
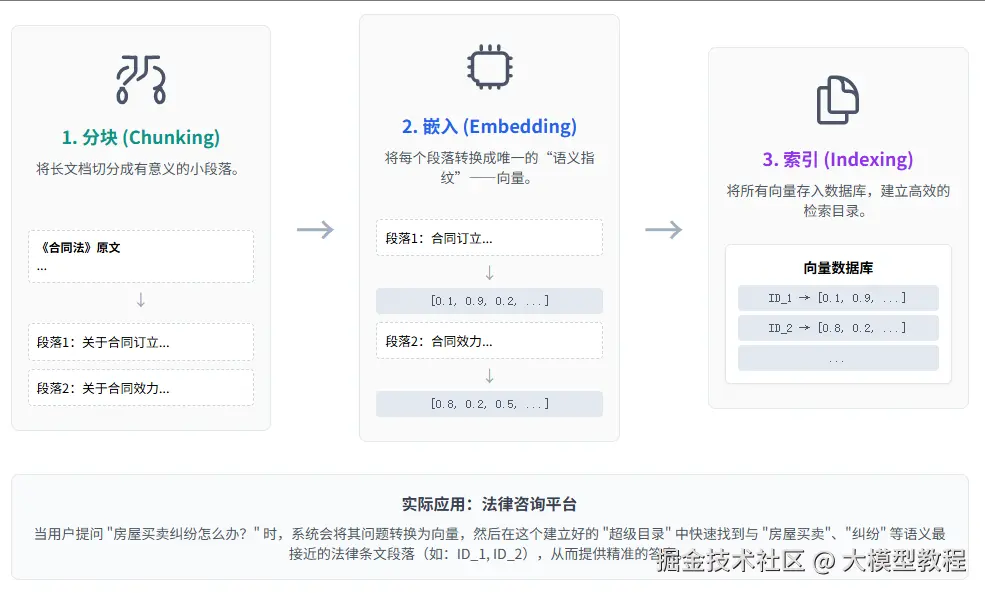
1. 分块(Chunking):
像把小说分章节,把长文档切成小段落 。 每段聚焦一个小主题,避免信息过载。
2. 嵌入(Embedding):
把每个文档块转换成向量 。 相当于给每个段落制作独一无二的 "DNA指纹" ,完整记录其内容特征。
3. 索引(Indexing):
建立高效的查找目录,让后续检索快到飞起!
实际应用:
法律咨询平台把厚厚的法条切成小块。用户问"房屋买卖纠纷 ",系统瞬间定位到《合同法》里关于"不动产交易违约"的具体段落,而不是甩给你整部法律!
四、重排序--从"海选"到"精选"
初步检索可能返回几十上百条结果,但并非都是"精华"。重排序就是严格的"质量评审官" !
核心任务:优中选优!
工作流程:
- 初步检索捞出100条"相关"结果。
- 重排序算法火眼金睛 ,根据与问题的真实相关性打分。
- 选出得分最高的Top 3-5条"尖子生"。
- 只把这些最精华的信息喂给AI生成答案。
相当于从海量简历中,精准筛选出最匹配岗位的几位候选人,确保AI拿到的是真干货!
五、上下文融合--拼出完整的"信息拼图"
单个信息片段往往不够全面。上下文融合就是信息"拼图大师" ,把碎片拼成完整背景!
实际场景:
用户问智能客服:"我的订单可以退货吗? " 系统需要智能融合:
- 你的订单:买的啥?啥时候买的?
- 商品退货政策:允许退吗?期限多久?有啥条件?
- 你的退货历史:是"退货狂魔"还是"佛系买家"?
- 当前退货流程:怎么操作?去哪寄?
只有把这些信息"拼"在一起 ,AI才能给出准确、靠谱、还贴心的回答!

六、评估标准--准确率与召回率的"微妙平衡"
RAG系统好不好?主要看两个关键指标:
准确率(Precision):
公式 :检索到的相关结果 / 检索到的总结果 人话 :你找到的结果里,有多少是真有用的? (宁缺毋滥!)
召回率(Recall):
公式 :检索到的相关结果 / 所有相关结果 人话 :所有有用的结果里,你找到了多少? (一个都不能少!)
电商栗子再出场: 搜索"运动鞋"
- 高准确率:返回的都是运动鞋! (没混进高跟鞋、皮鞋 )
- 高召回率:所有运动鞋都找到了! (没漏掉耐克、阿迪、李宁...)
现实很骨感: 这俩指标常常"打架"!
- 想要更精准?可能漏掉一些边缘相关的结果(召回率↓)。
- 想要更全面?可能混进一些不太相关的结果(准确率↓)。
怎么办? 我们需要一个平衡指标 (如F1值),像调节天平一样,找到业务场景下的最佳平衡点!
F1 值的计算公式是:F1= 2*(准确率*召回率)/(准确率+召回率)。
在这个公式中,当准确率或者召回率中的任何一个非常低时,F1 值也会相应地降低。
七、知识图谱--构建智慧的"关系网络"
知识图谱就像一张巨大的 "概念关系网" 。它不仅知道知识点,更知道知识点之间的联系!
核心超能力:
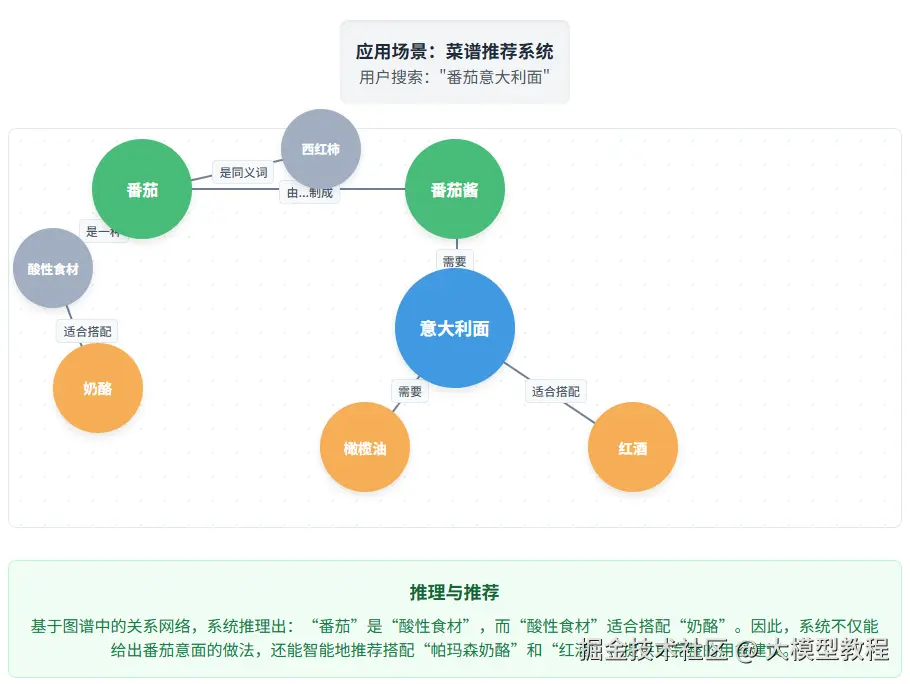
- 关系推理:知道"番茄"就是"西红柿","CEO"是"公司"的"管理者"。
- 扩展检索:搜"意大利面",能联想到"番茄酱"、"橄榄油"、"帕尔马奶酪"。
- 语境理解:精准判断"苹果"是指水果还是手机品牌。
美味应用:
- 用户搜"番茄意大利面"。
- 知识图谱启动:番茄 → 是酸性食材 → 适合搭配奶制品(如奶酪)。
- 系统不仅给做法,还贴心推荐:"试试搭配帕尔马干酪,再来杯基安蒂红酒更完美哦!"
总结
一个强大的RAG系统是这样运转的:
- 建好向量数据库,知识仓库就绪。
- 文档分块、嵌入向量、建立索引(三部曲)。
- 构建知识图谱,理解概念关联。
- 混合检索出击(关键词+语义),又快又准。
- 重排序把关,只留最相关的精华信息。
- 上下文融合,提供完整背景信息。
- 用准确率、召回率等指标评估效果,不断优化!
RAG技术正在深刻改变我们与AI的互动方式:
- 从泛泛而谈 到专业问答。
- 从通用聊天 到领域专家。
- 让AI的回答有据可依,值得信赖!
掌握RAG,就是握住了AI时代智能应用的核心竞争力! 无论你是开发者、产品经理,还是AI探索者,理解RAG的奥秘,都能让你在AI浪潮中看得更清,走得更远。
学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。