Claude Code 强在哪?详解这张 Tool-list,看 AI 如何通过搜索与执行,构建"感知-决策-行动"的完整闭环。
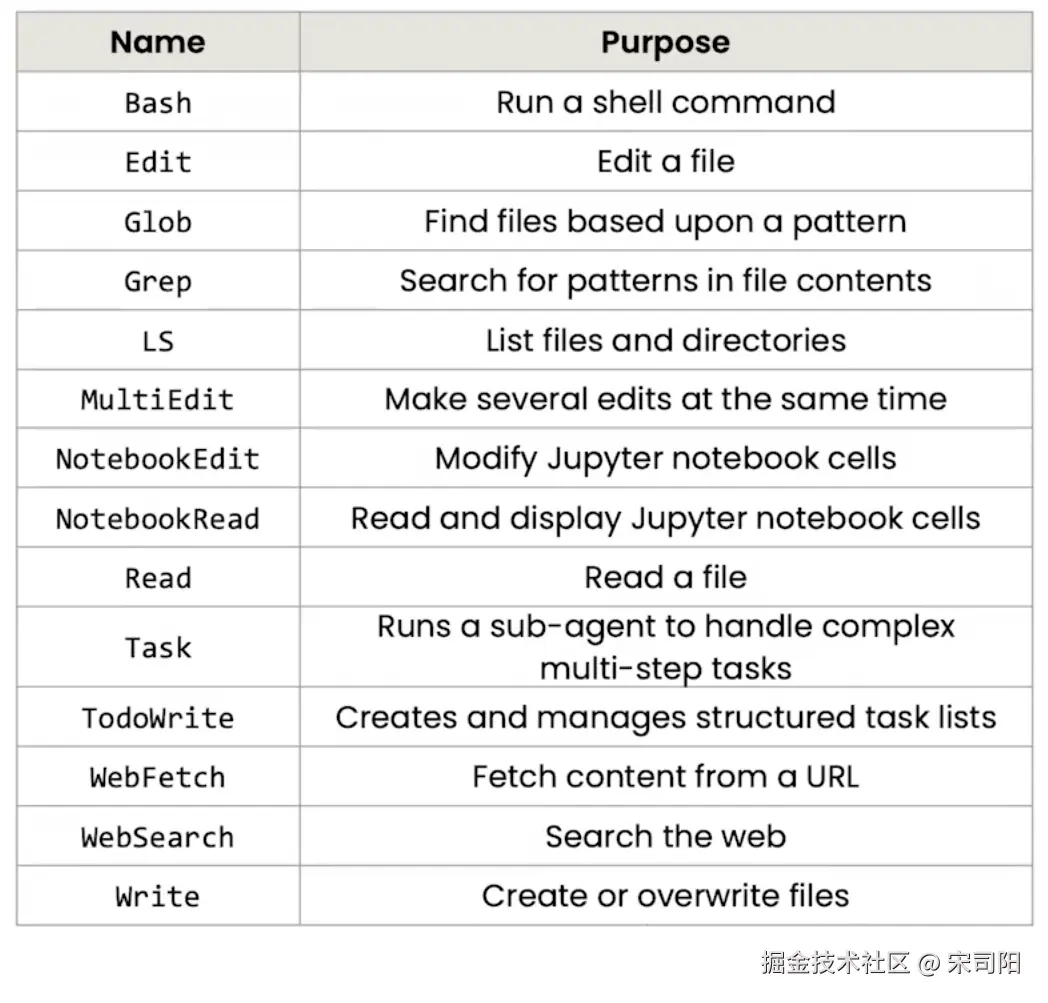 这张图表展示的不仅仅是"功能列表",它是Agentic AI(智能体)与操作系统交互的标准接口层(Interface Layer) 。在
这张图表展示的不仅仅是"功能列表",它是Agentic AI(智能体)与操作系统交互的标准接口层(Interface Layer) 。在Anthropic的设计哲学中,Model(模型)是大脑,Context(上下文)是短期记忆,而这些Tools(工具)则是Agent的手、眼和耳。
为了方便理解,我将这些工具分为四大模块来讲解:感知、交互、操作、编排、外部连接 。
一、感知(The "Eyes")
这一组工具(LS, Glob, Grep)不仅是为了"看",更是为了解决LLM的Context Window限制问题。我们不能把整个Git仓库的所有代码一次性喂给模型,它不能一次性把几百万行代码全部读入显存,必须让模型学会"按需检索"。
1.1 LS (List Files)
- 功能: 列出文件和目录。
相比于 Linux 原生的 ls,Claude Code 的 LS 做了严格的输出治理。它必须处理递归深度和文件数量的平衡,防止单纯的列举操作挤占推理空间。
如果说 LS 是看地图,Glob 和 Grep 就是指南针和显微镜。
1.2 Glob (Pattern Matching)
- 功能:基于模式查找文件(例如查找所有的 .py 文件)。
如果你的项目有 10,000 个文件,用 LS 遍历会瞬间撑爆 Context Window(上下文窗口)。Glob 允许模型使用通配符(如 **/*.test.ts)精准定位它关心的文件子集。这是一种Token 经济学的优化------只看该看的。
1.3 Grep (Pattern Search)
- 全称:Global Regular Expression Print
- 功能:在文件内容中搜索特定模式(关键词)。
这是调试的核心。当模型看到一个从未见过的函数 process_data() 时,它必须知道这个函数是在哪定义的。Grep 允许它在不读取所有文件内容的情况下,通过关键词搜索瞬间定位到定义处或引用处。
技术点 :这组工具的设计核心在于 Token Efficiency(Token 效率) 。让模型以最小的代价,定位到最关键的代码片段。
二、代码操作
2.1 Read 基础 I/O
通常包含"截断机制"。对于 package-lock.json 这种巨型文件,工具层会自动进行 Head/Tail 采样,防止 Context 溢出。(如"读取前100行"或"读取指定行号范围"的参数设计。)
2.2 Write 基础 I/O
这是破坏性操作。Agent 在调用前,内部往往会触发思维链(CoT)进行自我确认。确认文件不存在或需要覆盖。
2.3 Edit 最复杂的工具
- 行号的脆弱性:早期 Agent 喜欢用"第 10 行替换为...",但一旦文件变动,行号就会失效。
- 底层逻辑 :Claude Code 的 Edit 采用的是 "Search Block & Replace Block"(查找块与替换块) 机制。模型必须提供一段独一无二的上下文作为"查找锚点"。(不要告诉计算机"修改第 10 行",因为第 10 行可能已经被同事改成了第 12 行。要告诉计算机:"
找到这段代码(Search Block),把它换成那段代码(Replace Block)"。工具需要在全文中查找与Search Block完全匹配(或高度相似)的文本块。) - 模糊匹配算法 :在后台,工具会计算模型提供的锚点与源代码的 Fuzzy Match Score(模糊匹配分) 。这容忍了模型可能产生的细微幻觉(比如多了一个空格),大大提高了修改的成功率。
2.4 MultiEdit 事务的原子性
软件工程中,很多修改是联动的(比如重命名函数)。MultiEdit 引入了数据库中 Transaction(事务) 的概念:要么所有文件都改对,要么全部回滚。这防止了代码库处于"改了一半"的不可编译状态。 比如当你重构代码,需要把一个变量名在 5 个文件里全部改掉,MultiEdit 允许 AI 一次性完成,保证一致性。
三、环境交互
Bash
- 全称: Bourne Again SHell
- 功能: 运行 Shell 命令。
- 解读 : 这是最强大的权限 。意味着 AI 可以执行
pip install安装依赖,运行pytest进行测试,使用git commit提交代码,甚至重启服务。这让它具备了"手"。
四、任务编排
4.1 Task 递归的艺术
- 功能: 运行一个子代理(Sub-agent)来处理复杂的多步骤任务。
- 解读 : 这是"代理(Agentic)"能力的体现。如果你给它的任务太难(比如"重构整个后端架构"),单一的Context Window无法承载。于是它可以自己拆解任务,生成一个小弟(子进程)去专门研究某个模块,然后汇报结果。
- 底层逻辑 : 递归代理(Recursive Agent) 。主Agent调用 Task 工具,实际上是启动了一个新的Claude实例(Sub-agent),赋予它特定的Goal和独立的Context。子Agent完成后返回结果,父Agent继续。这是一个 分治算法(Divide and Conquer) 在Agent领域的应用。
4.2 TodoWrite 外部存储器
- 全称: Todo List Management
- 功能: 创建和管理结构化的任务清单。
- 解读 : 随着对话进行,前面的Context会被截断(Sliding Window)。Agent需要一个持久化的外部存储来记住"我都做了什么"和"还需要做什么"。类似于人类程序员写 TODO 列表。AI 用它来保持"记忆"和"上下文",防止在处理长任务时忘记自己做到了哪一步。
- 底层逻辑: 维护一个结构化的状态文件(如 scratchpad.md 或内存中的JSON对象)。每次行动后,Agent显式更新这个列表。这不仅是记忆,更是**自我规划(Self-Planning)**的具象化。
五、外部连接(网络连接工具)
5.1 WebSearch
功能:通过网络搜索获取最新文档、库版本更新、报错解决方案。
5.2 WebFetch
WebSearch 只是给了链接,WebFetch 才是真正的"阅读"。但是,直接用 curl 或 Python 的 requests.get() 下载网页,对 LLM 来说通常是灾难。(因为现代网页充满了JavaScript和广告,冗余太多)
- 解读 (关键) : 现代网页充满了JavaScript和广告。WebFetch 的核心竞争力在于 "HTML to Markdown" 的清洗算法(如使用 Mozilla 的 Readability 库)。它必须剥离导航栏、广告、弹窗,只把核心文本喂给模型,以节省Token并减少噪声干扰。
总之,WebFetch 的核心竞争力不在于"下载",而在于清洗。它使用类似 Mozilla Readability 的算法,剥离 DOM 树中的噪音,将网页转化为高密度的 Markdown 喂给模型。这是对互联网信息的"语义提取"。
六、总结
如果我们站在系统论的角度看,Claude Code 的这套工具链完美复现了 OODA 循环:
- Observe (观察) : 使用 LS, Grep, Read 收集信息。
- Orient (调整) : 使用 TodoWrite 更新状态,构建环境认知。
- Decide (决策) : 模型内部推理,选择工具。
- Act (行动) : 使用 Edit, Bash 执行操作,并根据反馈进入下一轮循环。