目录
[🚗 为什么要有 prev 指针?因为生活不能只有"向前看"](#🚗 为什么要有 prev 指针?因为生活不能只有“向前看”)
[🧱 结构体定义:别忘了给 prev 留个位置!](#🧱 结构体定义:别忘了给 prev 留个位置!)
[🛠️ 核心操作:指针的"四手联弹",顺序错了全完蛋!](#🛠️ 核心操作:指针的“四手联弹”,顺序错了全完蛋!)
[✅ 头插法:给链表加个"新门面"](#✅ 头插法:给链表加个“新门面”)
[✅ 任意位置插入:指针的"精密手术"](#✅ 任意位置插入:指针的“精密手术”)
[✅ 删除节点:优雅地"送别"](#✅ 删除节点:优雅地“送别”)
[🎵 小项目实战:做一个"上一首/下一首"的播放列表](#🎵 小项目实战:做一个“上一首/下一首”的播放列表)
[🤔 延伸思考:不止于此](#🤔 延伸思考:不止于此)
[💬 最后聊两句](#💬 最后聊两句)

引言
上一篇博客我们学习了单链表和循环列表,已经掌握了"动态存储"的精髓,那么这篇博客来讲讲双向链表。
说实话,双向链表刚学的时候,我觉得它有点"多余"。
单链表不是挺好吗?加个 prev 指针,代码多了,逻辑复杂了,指针还容易乱。
直到我试着写一个"能返回上一步"的功能,才发现:有些路,必须能往回走。
后来我才明白,双向链表不是炫技,而是对"自由"的一种妥协------
用多一个指针的空间,换任意位置 O(1) 的删除能力,换反向遍历的可能性,换逻辑上的对称与优雅。
这篇笔记,是我啃完教材、调完 bug、画了许多张指针图之后的总结。
没有花哨术语,只有最朴素的实现、最容易栽的坑,和一段能跑起来的代码。
如果你也刚接触双向链表,希望它能帮你少熬一个夜。

🚗 为什么要有 prev 指针?因为生活不能只有"向前看"
单链表的痛,谁懂啊?
"老板,我要删除第 6 个节点的前一个节点!" "行,我先从头开始数到第 4 个,再让第 4 个指向第 6 个......哦对了,我还得记住第 5 个是谁,不然删不了。"
单链表就是如此,想要查找上一个节点,最坏的时间复杂度为**O(n) ,**这效率,简直是在用算盘打代码。为了克服这样的"单向孤独",双向链表就出来了。
"老板,删第 6 个节点的前一个节点!" "好嘞,那是第5个节点,第 5 个自己知道前面是第 4 个,后面是第 6 个,它俩一牵手,第 5 个就可以光荣退休了。"
这就是 prev 指针的灵魂所在:它让你能"反向导航",把 O(n) 的查找时间,直接压缩到 O(1)。
💡 顿悟时刻 :双向链表不是为了"炫技",而是为了解决"逆向操作"的刚需。比如你写个播放器,"上一首"功能,没有 prev 指针,你得从头开始遍历,用户早把你骂死了。
🧱 结构体定义:别忘了给 prev 留个位置!
typedef struct DulNode {
int data; // 数据域
struct DulNode *prior; // 👈 这就是你的"后视镜"!指向直接前驱
struct DulNode *next; // 👈 这就是你的"方向盘"!指向直接后继
} DulNode, *DulLinkList;双向链表的循环带头结点的空链表如图所示:

非空循环带头结点的双向链表如图所示:

⚠️ 新手常犯错误 :只写了 next,忘了 prior。结果插入删除的时候,链表直接"断片",变成了一堆孤零零的节点。
🛠️ 核心操作:指针的"四手联弹",顺序错了全完蛋!
✅ 头插法:给链表加个"新门面"
想象一下,你要在队伍最前面插队。你得先:
-
把新节点的
next指向原来的第一个节点。 -
把新节点的
prior指向NULL(因为你是头)。 -
把原来第一个节点的
prior指向你。 -
最后,更新头指针,让它指向你!
void InsertAtHead(DulLinkList *L, int e) {
DulNode s = (DulNode)malloc(sizeof(DulNode));
s->data = e;s->next = (*L)->next; // ① 新节点的next指向原第一个节点 s->prior = NULL; // ② 新节点的prior指向NULL if ((*L)->next != NULL) { // 如果原链表非空 (*L)->next->prior = s; // ③ 原第一个节点的prior指向新节点 } (*L)->next = s; // ④ 更新头指针,指向新节点}
🚨 致命错误 :如果先执行 (*L)->next = s;,再改 (*L)->next->prior = s;,你会发现 (*L)->next 已经是你自己了,你是在给自己改 prior,完全没用!顺序必须是 ①→②→③→④!
✅ 任意位置插入:指针的"精密手术"
这是教材里那个经典图解,我当初看了三遍才明白。核心思想是:先连好新节点的"手脚",再让它"认亲"。
假设我们要在节点 p 和 p->next 之间插入节点 s。
// 插入节点s到p和p->next之间
s->prior = p; // ① s的前驱是p
s->next = p->next; // ② s的后继是p->next
if (p->next != NULL) { // 如果p不是最后一个节点
p->next->prior = s; // ③ p->next的前驱现在是s
}
p->next = s; // ④ p的后继现在是s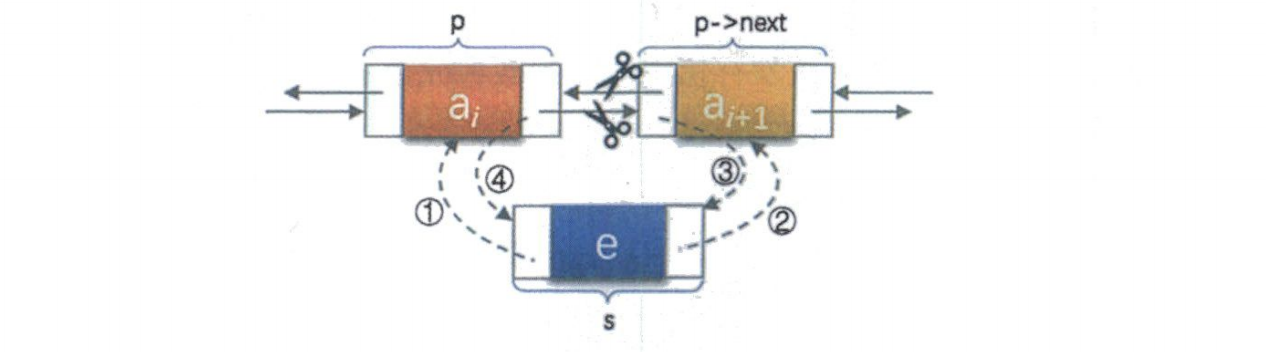
💡 记忆口诀 :"先安家,再认亲"。先把 s 自己的 prior 和 next 安排好(①②),再让它的邻居们认识它(③④)。顺序绝对不能乱!
❌ 血泪教训 :我曾经把 p->next = s; 放在最前面,结果 p->next 变成了 s,后面的 p->next->prior = s; 就变成了 s->prior = s;,把自己指向了自己,链表直接"精神分裂"。
✅ 删除节点:优雅地"送别"
删除比插入简单,但更容易忘记"善后"。
要删除节点 p,只需要:
-
让
p的前驱节点的next指向p的后继。 -
让
p的后继节点的prior指向p的前驱。 -
free(p),释放内存。void DeleteNode(DulLinkList *L, DulNode *p) {
if (p == NULL) return;if (p->prior != NULL) { p->prior->next = p->next; // ① 前驱的next指向后继 } else { (*L)->next = p->next; // 如果p是头节点,更新头指针 } if (p->next != NULL) { p->next->prior = p->prior; // ② 后继的prior指向前驱 } free(p); // ③ 释放内存 p = NULL; // ⚠️ 非常重要!防止野指针!}

🚨 超级大坑:
- 忘记更新头指针:如果删的是第一个节点,
*L还指着旧地址,后面操作全崩。 free(p)后没置空:p变成野指针,下次不小心用了,程序直接"壮烈牺牲"。
🎵 小项目实战:做一个"上一首/下一首"的播放列表
学以致用才是王道!我们来实现一个简易的音乐播放器。
// 定义一个播放列表节点
typedef struct MusicNode {
char name[50]; // 歌曲名
struct MusicNode *prior;
struct MusicNode *next;
} MusicNode, *MusicList;
MusicList currentSong; // 当前播放的歌曲指针
// 上一首
void PrevSong() {
if (currentSong && currentSong->prior) {
currentSong = currentSong->prior;
printf("正在播放: %s\n", currentSong->name);
} else {
printf("已经是第一首歌啦!\n");
}
}
// 下一首
void NextSong() {
if (currentSong && currentSong->next) {
currentSong = currentSong->next;
printf("正在播放: %s\n", currentSong->name);
} else {
printf("已经是最后一首歌啦!\n");
}
}看,有了 prev 和 next,实现"上一首/下一首"是不是轻松加愉快?这就是双向链表的魔力!
🤔 延伸思考:不止于此
- 循环双向链表:把头尾连起来,形成一个环。好处是无论从哪开始,都能无死角遍历。想想约瑟夫问题,用这个结构就很爽。
- STL list :C++ 里的
std::list底层就是双向链表,所以它支持高效的插入删除,但不支持随机访问。 - LRU 缓存:最经典的"最近最少使用"算法,核心思想就是用双向链表维护访问顺序,新访问的放头部,淘汰尾部的。这也是双向链表的高光时刻!
💬 最后聊两句
兄弟们,双向链表的核心就一个字:对称 。你改了 next,就得改 prior;你连了左边,就得连右边。记住这个"对称美",你就不会迷路。
别怕指针,它们就像乐高积木,只要按说明书(也就是逻辑顺序)拼,就能搭出漂亮的大楼。
动手试试吧! 给你的双向链表加个"从尾到头打印"的功能,或者实现一个简单的"撤销/重做"栈(用双向链表模拟历史记录),你会发现自己真的"开窍"了!
评论区等你分享你的"踩坑故事"和"顿悟瞬间",咱们一起进步!💪

那到此,线性表的知识就介绍完了

下篇博客,待我学完栈和队列后更新,可以期待一下哦
