文章案例具体代码链接:https://github.com/whltaoin/hututu
提交版本:e67453a26f0bbe78ce075a550bafb01ba82aa9ff
简言
在后端开发中,API接口是服务间通信的核心载体,而数据存储与缓存策略则直接决定了接口的性能与稳定性。Spring框架凭借其强大的生态成为API开发的首选,MySQL作为关系型数据库提供了可靠的数据持久化支持。当系统并发量提升时,单一数据库架构易出现性能瓶颈,此时引入Redis(分布式缓存)与Caffeine(本地缓存)构建多级缓存体系,成为优化性能的关键方案。本文将从基础实现出发,深入探讨多级缓存的优势、劣势、适用场景及实践注意点。
文章目录
- 简言
- 一、基础架构:Spring+MySQL实现API接口
-
- [1.1 核心组件与依赖](#1.1 核心组件与依赖)
- [1.2 核心实现流程](#1.2 核心实现流程)
- 二、多级缓存:Redis+Caffeine的组合逻辑
-
- [2.1 组件特性对比](#2.1 组件特性对比)
- [2.2 多级缓存工作流程](#2.2 多级缓存工作流程)
- 三、多级缓存的优势与劣势
-
- [3.1 核心优势](#3.1 核心优势)
-
- [3.1.1 极致的性能提升](#3.1.1 极致的性能提升)
- [3.1.2 分布式场景适配](#3.1.2 分布式场景适配)
- [3.1.3 高可用性保障](#3.1.3 高可用性保障)
- [3.2 主要劣势](#3.2 主要劣势)
-
- [3.2.1 架构复杂度提升](#3.2.1 架构复杂度提升)
- [3.2.2 内存资源消耗增加](#3.2.2 内存资源消耗增加)
- [3.2.3 数据一致性风险](#3.2.3 数据一致性风险)
- 四、适用场景与实践注意点
-
- [4.1 核心适用场景](#4.1 核心适用场景)
-
- [4.1.1 高频读、低频写场景](#4.1.1 高频读、低频写场景)
- [4.1.2 分布式微服务架构](#4.1.2 分布式微服务架构)
- [4.1.3 高并发核心接口](#4.1.3 高并发核心接口)
- [4.2 关键实践注意点](#4.2 关键实践注意点)
-
- [4.2.1 合理配置缓存策略](#4.2.1 合理配置缓存策略)
- [4.2.2 保障数据一致性](#4.2.2 保障数据一致性)
- [4.2.3 避免缓存常见问题](#4.2.3 避免缓存常见问题)
- [4.2.4 监控与运维保障](#4.2.4 监控与运维保障)
- 五、总结
一、基础架构:Spring+MySQL实现API接口
Spring生态中,Spring Boot结合MyBatis/MyBatis-Plus可快速搭建基于MySQL的API接口服务。其核心逻辑是通过Spring MVC接收前端请求,Service层处理业务逻辑,Mapper层通过MyBatis操作MySQL数据库,最终将数据返回给调用方。
1.1 核心组件与依赖
实现该架构需引入以下核心依赖(以Maven为例):
xml
<!-- Spring Boot Web核心 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- MyBatis-Plus启动器 -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.3.1</version>
</dependency>
<!-- MySQL驱动 -->
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<scope>runtime</scope>
</dependency>
<!-- 数据库连接池 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.2.16</version>
</dependency>1.2 核心实现流程
- 配置数据库连接:在application.yml中配置MySQL地址、用户名、密码及连接池参数;
- 定义实体类:对应MySQL数据表结构,使用MyBatis-Plus注解简化配置;
- 编写Mapper接口:继承BaseMapper实现CRUD操作,无需手动编写SQL;
- Service层封装业务:调用Mapper接口处理业务逻辑,如数据校验、权限控制;
- Controller暴露接口:通过@RestController、@RequestMapping等注解定义API路径,接收请求并返回结果。
该架构的优势是开发效率高、数据一致性强,但当并发请求量超过MySQL承载能力时,会出现查询延迟、连接池耗尽等问题,此时缓存的引入至关重要。
二、多级缓存:Redis+Caffeine的组合逻辑
多级缓存的核心思路是"近缓存优先",将访问频率高的数据存储在距离应用更近的缓存中,减少网络开销和数据库压力。Caffeine作为本地缓存(进程内缓存),Redis作为分布式缓存(独立服务),二者结合可兼顾性能与分布式一致性。
xml
<!-- 分布式缓存: redis-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!-- 本地缓存:caffeine(注意:3.x版本java版本至少要在11以上)-->
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>3.1.8</version>
</dependency>2.1 组件特性对比
| 特性 | Caffeine | Redis |
|---|---|---|
| 存储位置 | 应用进程内 | 独立服务器/集群 |
| 访问延迟 | 微秒级(极快) | 毫秒级(较快) |
| 分布式支持 | 不支持(进程隔离) | 支持(集群部署) |
| 存储容量 | 受JVM内存限制 | 支持大容量(GB/TB级) |
| 持久化 | 不支持(进程重启丢失) | 支持(RDB/AOF) |
2.2 多级缓存工作流程
基于Spring Cache抽象,可快速整合Caffeine与Redis,核心流程如下:
- 查询缓存:请求到达后,先查询Caffeine本地缓存,若命中直接返回数据;
- 分布式缓存查询:若Caffeine未命中,查询Redis分布式缓存,若命中则将数据同步到Caffeine后返回;
- 数据库查询:若Redis也未命中,查询MySQL数据库,将查询结果同步到Redis和Caffeine后返回;
- 缓存更新/失效:当数据发生修改时,先更新数据库,再删除对应Redis和Caffeine缓存(避免缓存与数据库不一致)。
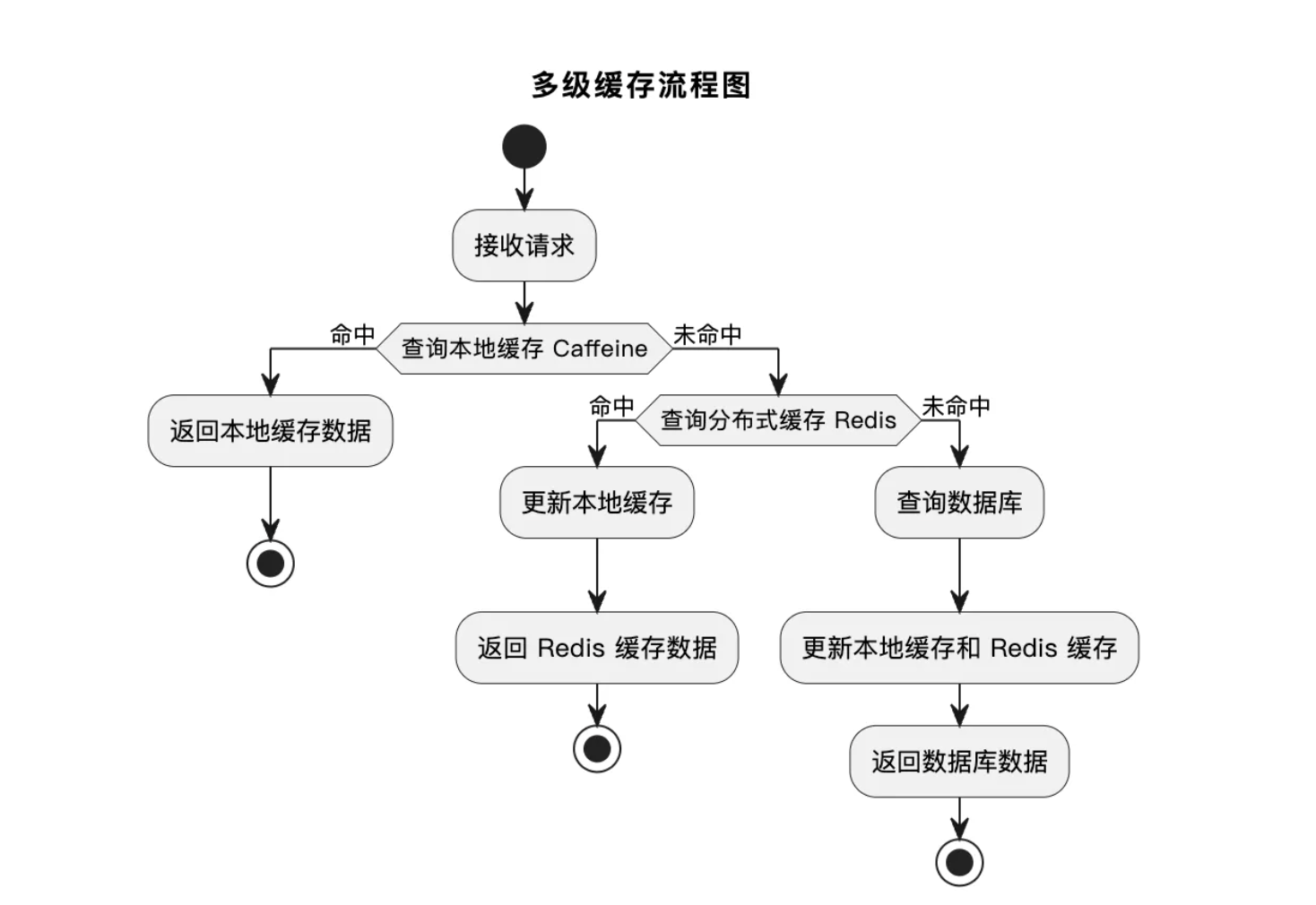
弧图图项目中的一个分页列表接口示例:
java
/**
* 采用多级缓存,先查询本地缓存,如果本地缓存查询不到,在查询分布式缓存,如果再没有再从数据库中查询
* @param pictureQueryRequest
* @param request
* @return
*/
@Resource
private ValueOperations<String, String> stringValueWithRedisTemplate;
@Resource
private Cache<String,String> localCacheWithCaffeine;
@ApiOperation(value = "分页图片列表VO多级缓存")
@PostMapping("/list/page/vo/multi-level")
public BaseResponse<Page<PictureVo>> listPictureVOByPageWithMultiLevel(@RequestBody PictureQueryRequest pictureQueryRequest,HttpServletRequest request) {
int current = pictureQueryRequest.getCurrent();
int pageSize = pictureQueryRequest.getPageSize();
ThrowUtil.throwIf(pageSize > 20, ResponseCode.PARAMS_ERROR);
// 只有审核过的图片可以在主页显示
pictureQueryRequest.setReviewStatus(ReviewStatusEnum.PASS.getValue());
Page<Picture> picturePage = pictureService.page(new Page<>(current, pageSize)
,
pictureService.getQueryWrapper(pictureQueryRequest));
// 1. 构造key
String queryCondition = JSONUtil.toJsonStr(pictureQueryRequest);
// 查询条件加密
queryCondition = DigestUtils.md5DigestAsHex(queryCondition.getBytes());
String cacheKey = String.format("hututu:listPictureVOByPageWithCache:%s", queryCondition);
// 2. 先查询本地缓存
String cacheValue = localCacheWithCaffeine.getIfPresent(cacheKey);
Page<PictureVo> pictureVOPage= null;
if(cacheValue != null) {
pictureVOPage= JSONUtil.toBean(cacheValue,Page.class);
return ResponseUtil.success(pictureVOPage);
}
// 3 查询redis缓存
cacheValue = stringValueWithRedisTemplate.get(cacheKey);
if(cacheValue != null) {
pictureVOPage = JSONUtil.toBean(cacheValue,Page.class);
return ResponseUtil.success(pictureVOPage);
}
// 4. 查询mysql
pictureVOPage = pictureService.getPictureVOPage(picturePage, request);
// 5 存储本地缓存和redis缓存
localCacheWithCaffeine.put(cacheKey, JSONUtil.toJsonStr(pictureVOPage));
stringValueWithRedisTemplate.set(cacheValue, JSONUtil.toJsonStr(pictureVOPage),300+ RandomUtil.randomInt(0,300), TimeUnit.SECONDS);
return ResponseUtil.success(pictureVOPage);
}实现前端效果:
在这里插入图片描述
三、多级缓存的优势与劣势
任何技术方案都有其适用场景,多级缓存的优劣需结合业务场景客观评估。
3.1 核心优势
3.1.1 极致的性能提升
Caffeine的微秒级访问延迟可覆盖大部分高频查询场景,减少对Redis的网络调用;Redis则承接跨服务的缓存需求,二者结合使缓存命中率大幅提升,数据库查询压力显著降低。实测显示,在商品详情查询场景中,引入多级缓存后接口响应时间可从50-100ms降至1-5ms,并发承载能力提升10倍以上。
3.1.2 分布式场景适配
在微服务架构中,Caffeine的本地缓存可减少服务间对Redis的竞争,而Redis确保了不同服务实例间的缓存一致性。例如,用户登录状态缓存可存储在Redis中供所有服务访问,而服务本地的高频配置数据可存储在Caffeine中,兼顾一致性与性能。
3.1.3 高可用性保障
当Redis集群因网络故障或节点宕机暂时不可用时,Caffeine本地缓存可作为"兜底缓存",保障核心接口的可用性;反之,若单个服务实例故障,Redis中的缓存数据可被其他实例复用,避免缓存雪崩。
3.2 主要劣势
3.2.1 架构复杂度提升
引入多级缓存后,需额外维护Caffeine的本地缓存配置(如容量、过期时间、淘汰策略)和Redis的集群部署、持久化策略;同时需处理缓存一致性问题(如更新/删除时的缓存同步),增加了开发和运维成本。
3.2.2 内存资源消耗增加
Caffeine缓存占用JVM堆内存,若配置不当(如容量过大、淘汰策略不合理),易导致JVM内存溢出(OOM);Redis集群则需独立的服务器资源,增加了硬件成本。
3.2.3 数据一致性风险
多级缓存存在"缓存不一致"的天然风险:例如,服务A更新数据后删除了自身Caffeine缓存和Redis缓存,但服务B的Caffeine缓存中仍有旧数据,直到过期才会更新。虽可通过发布订阅机制(如Redis Pub/Sub)触发全量服务的本地缓存失效,但会增加系统复杂度。
四、适用场景与实践注意点
4.1 核心适用场景
4.1.1 高频读、低频写场景
如商品详情、新闻资讯、字典配置等数据,查询频率远高于更新频率,多级缓存可最大化发挥性能优势。例如,电商平台的商品列表查询,90%以上的请求可通过Caffeine命中,剩余请求通过Redis命中,仅极少数请求需查询数据库。
4.1.2 分布式微服务架构
微服务间的接口调用频繁,多级缓存可减少跨服务依赖和网络开销。例如,订单服务查询用户信息时,先查本地Caffeine缓存,未命中再查Redis缓存,最后调用用户服务接口并同步缓存,降低服务间的耦合度。
4.1.3 高并发核心接口
如秒杀活动、限时优惠等场景,并发量可达数万QPS,单一数据库或Redis无法承载。多级缓存可通过Caffeine承接大部分瞬时请求,Redis保障分布式一致性,数据库仅处理最终的下单逻辑。
4.2 关键实践注意点
4.2.1 合理配置缓存策略
- Caffeine配置:建议设置最大容量(如10000条)、过期时间(如5分钟),采用LRU(最近最少使用)或LFU(最不经常使用)淘汰策略;避免缓存超大对象(如超过1MB),防止JVM内存碎片化。
- Redis配置:采用集群部署(如3主3从)保障高可用,开启AOF持久化避免数据丢失;针对热点数据设置合理的过期时间(如10分钟),并通过"热点Key"防护机制避免缓存击穿。
4.2.2 保障数据一致性
采用"先更新数据库,再删除缓存"的策略(避免更新缓存失败导致不一致);对于强一致性需求场景,可引入Redis Pub/Sub机制,当数据更新时,发布缓存失效消息,所有服务实例接收消息后删除本地Caffeine缓存;对于弱一致性场景,可依赖缓存过期机制自然失效。
4.2.3 避免缓存常见问题
- 缓存穿透 :请求不存在的数据
- 对不存在的Key,在Redis中缓存空值(设置短过期时间,如10秒),并结合布隆过滤器过滤无效Key;
- 缓存击穿 :请求不存在的热点数据
- 对热点Key设置"永不过期",通过后台线程定期更新;或采用互斥锁机制,确保同一时间仅一个请求查询数据库;
- 缓存雪崩 :大量缓存同时过期
- 将缓存过期时间设置为"基础时间+随机偏移"(如10分钟±30秒),避免大量缓存同时失效;Redis集群采用多区域部署,避免单点故障。
4.2.4 监控与运维保障
通过Spring Boot Actuator监控Caffeine缓存命中率、容量使用情况;通过Redis监控工具(如Redis Insight)监控Redis的命中率、内存占用、集群状态;设置告警机制,当缓存命中率低于阈值(如80%)或Redis内存使用率超过阈值(如80%)时及时预警。
五、总结
Spring+MySQL是API接口开发的基础架构,而Redis+Caffeine多级缓存则是应对高并发场景的"性能利器"。其核心价值在于通过"本地缓存+分布式缓存"的组合,兼顾了性能、一致性与可用性,但同时也带来了架构复杂度和资源消耗的提升。
在实践中,需结合业务场景选择是否引入多级缓存:对于低频请求、强一致性需求的接口,单一数据库或Redis缓存即可满足需求;对于高频读、低频写的核心接口,多级缓存则能带来显著的性能提升。同时,需通过合理的缓存配置、一致性策略和监控机制,规避潜在风险,确保系统稳定运行。