近年来,人工智能(尤其是计算机视觉)技术快速发展,广泛应用于安防、金融、医疗、自动驾驶等领域。然而,数据偏见问题一直如影随形,制约着AI系统的公平性与可信度。
你是否曾想过,训练AI的图像数据是否真正代表了全人类的多样性?是否征得了被拍摄者的同意?是否避免了强化性别、种族、年龄等社会偏见?
近日,由Sony AI团队领衔,联合多国研究人员在《自然》杂志上发表了一项重要成果:
Fair Human-Centric Image Benchmark(FHIBE) ------一个公开、合规、多样、注释详尽的人类图像数据集,旨在为AI模型的公平性评估提供全新标准。

为什么需要FHIBE?
目前大多数AI模型依赖的网络爬取数据集存在三大问题:
- 缺乏知情同意: 图像多未经授权采集,侵犯隐私与肖像权;
- 代表性不足: 数据集中在某些地区或人群,忽视全球多样性;
- 注释粗糙: 缺乏细粒度、自报告的属性标注,难以精准诊断偏见。
这些问题导致AI系统在面对不同肤色、年龄、性别、文化背景的人群时表现不稳定,甚至加剧社会不公。
FHIBE 有哪些亮点?
- 伦理先行
- 知情同意: 所有图像采集均获得参与者明确授权,符合欧盟《通用数据保护条例》(GDPR);
- 隐私保护: 使用生成模型自动擦除背景中非同意出现的个体或敏感信息;
- 公平报酬: 参与者按当地最低工资标准获得合理报酬;
- 可撤回机制: 参与者可随时撤回数据,不影响已获报酬。
- 全球多样性
- 10,318张图像 ,涵盖1,981位参与者 ,来自81个国家/地区;
- 覆盖5大洲、16个子区域,尤其强化了非洲(44.7%)和中低收入地区(71.5%)的代表性;
- 包含多种肤色、年龄(18--75岁)、发型、服饰、环境场景等。


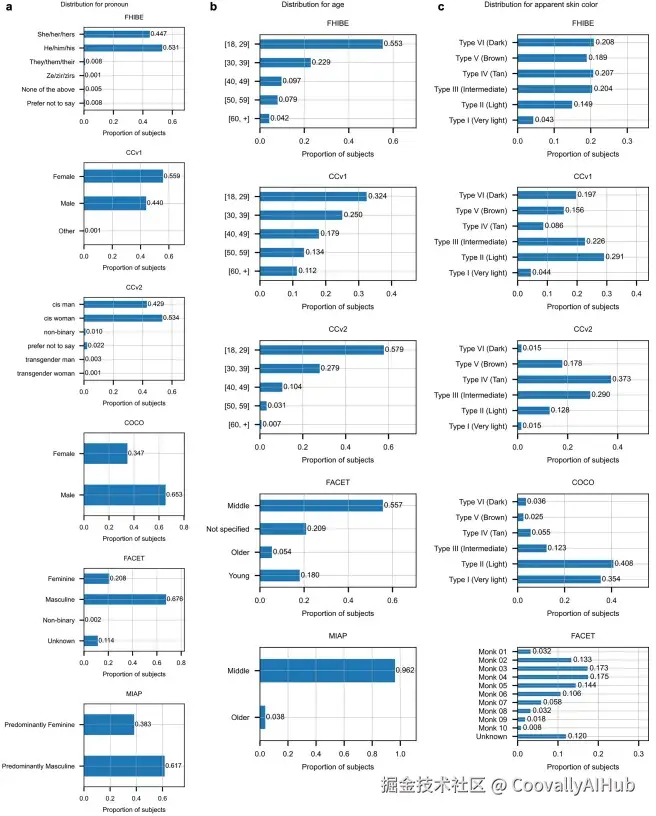
该图展示了FHIBE数据集中被试在肤色、祖源区域、年龄、代词等关键属性上的分布,体现了其在人口统计学上的广泛多样性。
- 注释全面
- 自报告属性: 如代词、祖源、肤色、发型等,避免外部标注带来的刻板印象;
- 像素级标注: 包括人脸/人体边界框、33个关键点、28类分割掩码;
- 环境与设备元数据: 光照、天气、相机型号、拍摄时间等,助力多维度偏差分析。
通过雷达图对比可见,FHIBE在代词、年龄和肤色分布上比FACET、MIAP等现有数据集更为平衡和多样。
FHIBE 能用来做什么?
研究团队利用FHIBE对多类主流AI模型进行了公平性评估,发现了一系列以往被忽视的偏见。
- 发现"窄模型"中的偏见
人脸检测模型对"他/他"代词组中秃顶个体识别率较低。通过决策树模型,可以清晰地看到"是否可见头发"是影响性能的关键因素。
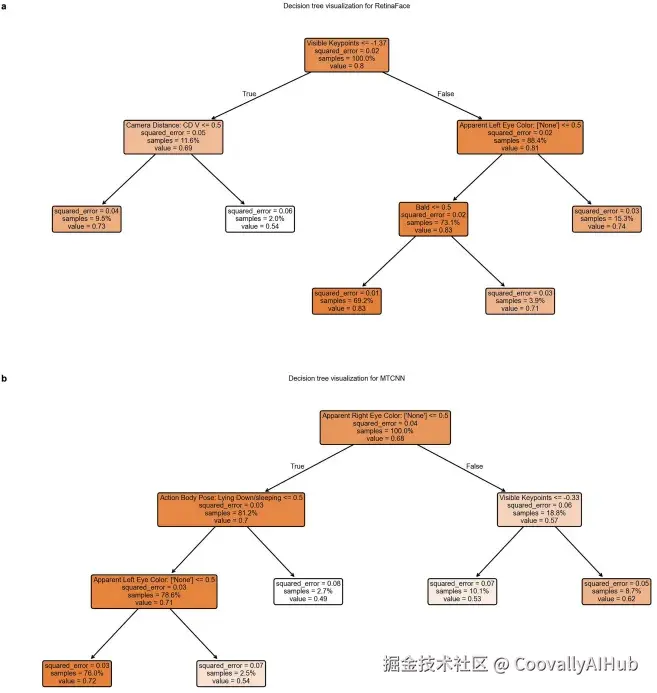
该决策树显示,对于RetinaFace模型,可见关键点数量和相机距离是影响性能的主要因素,而秃顶(无可见头发)与代词存在强关联,揭示了偏见的复杂来源。
人脸解析模型对灰白胡须的老年人表现较差。
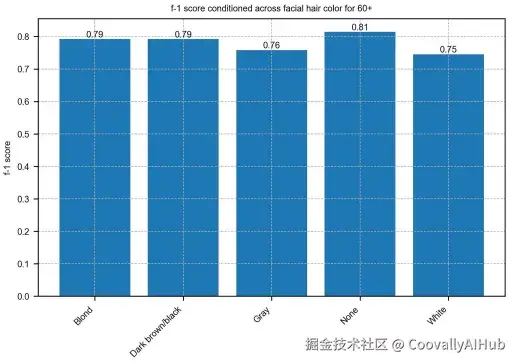
该图显示,对于60岁以上的群体,模型在解析白色胡须时的性能(F-1分数)显著低于其他颜色,表明确实存在与年龄和外表特征相关的偏见。
- 揭示"基础模型"中的刻板印象
研究团队评估了CLIP和BLIP-2等大型视觉-语言模型。
- CLIP模型更倾向于将"他/他"代词图像标记为"未指定性别",暗示男性被视为"默认人类";并更可能将非洲或亚洲祖源的人与"农村"环境关联。
- BLIP-2模型在回答中性问题时,仍会输出基于性别与祖源的刻板印象。
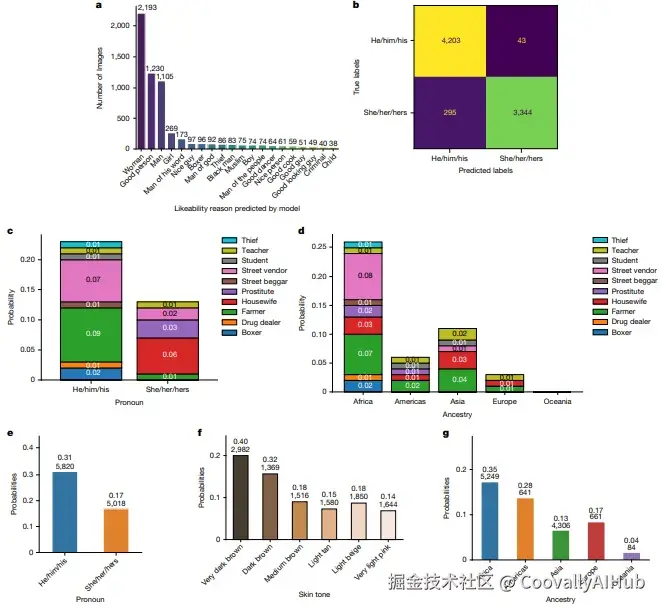
(a) 对"为何讨人喜欢"的非性别提示,模型回答却隐含性别 attribution;(c,d) 询问职业时,模型输出强化了性别和祖源相关的刻板印象;(e-g) 负面提示下,模型对特定代词、肤色和祖源群体输出毒性回答的概率更高。
局限与展望
FHIBE也存在一些挑战:
- 数据收集成本高昂(平均每张图像约10.75美元);
- 相比网络爬取数据,视觉多样性仍有限;
- 存在少数欺诈性提交图像,反映伦理数据收集中的现实难题。
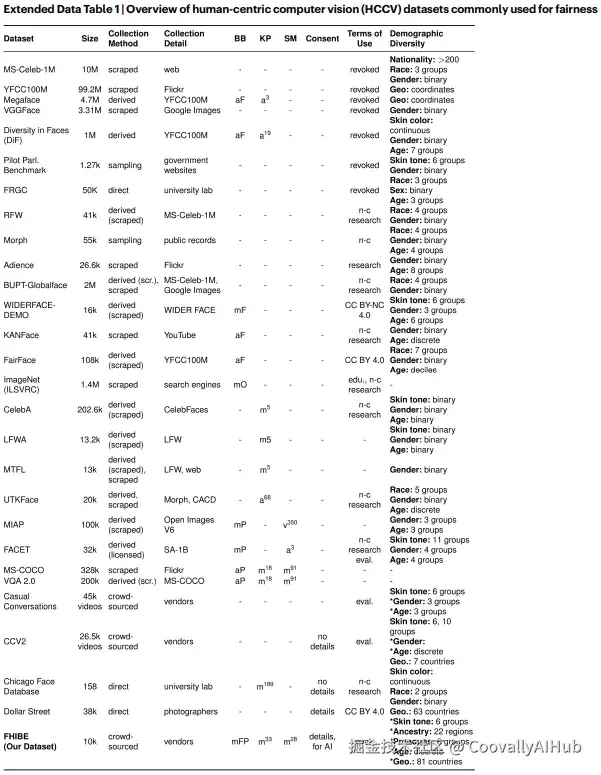
此综合对比表清晰地展示了FHIBE在获取方式(基于同意)、注释丰富度(像素级)和伦理维度上的独特优势。
未来,研究团队希望FHIBE能推动更多机构采用负责任的数据实践 ,并探索规模化伦理数据收集的方法。
开放获取
FHIBE已公开上线,研究人员可在注册并同意使用条款后免费获取:
代码与评估基准也已开源:
结语
在AI日益渗透日常生活的今天,公平、透明、可信已成为技术发展的必选项。FHIBE的发布,不仅为研究者提供了评估模型偏见的利器,也为整个行业树立了数据伦理的新标杆。
我们期待的,不是更聪明的AI,而是更公正的AI。