在布满尘埃的档案库房中,厚重的册籍与泛黄的表格静静沉睡,其中蕴藏的经营数据、人员信息、历史记录构成了一座座未被开采的"数据金矿"。然而,将这些非结构化的纸质表格转化为可计算、可分析的数字资产,始终是横亘在档案数字化面前的巨大挑战。中科逸视(北京)科技有限公司以其前沿的表格识别技术,正如同一位技艺高超的"数据炼金师",为破解这一难题提供了精准而高效的解决方案,彻底改变了传统档案管理的生态。
技术核心: 深度学习 驱动的智能解析原理
中科逸视的表格识别技术并非简单的图像转文本,而是一个融合了多种先进人工智能模型的复杂感知与理解系统。其核心技术原理可拆解为三个关键步骤:
1.表格检测与定位
- 首先,系统通过目标检测模型对扫描或拍摄的档案图像进行全局分析,精准定位出图像中所有表格的区域,并将其与周围的纯文本、图片等内容区分开来。这一步确保了系统能够"看到"表格。
2.表格结构分析与识别
这是表格识别技术的精髓所在。系统采用先进的深度学习分割网络对定位后的表格进行像素级分析。
- 线框检测与重建:能够智能识别并还原表格的横线、竖线,甚至处理虚线、残缺线等复杂情况,精确勾勒出表格的整体框架。
- 单元格分割与关联:在无框线或框线不完整的复杂表格中,技术能通过文本布局和视觉特征,智能推断出单元格的边界,并将每个单元格与正确的行、列位置进行关联,完美解决"跨行/列单元格"的识别难题。
- 逻辑结构理解:表格识别技术不仅能识别物理结构,还能理解逻辑结构,例如准确区分表头、表体、表尾,以及识别多层表头(合并单元格)。
3.文字识别与信息关联
在单元格定位完成后,集成的高精度OCR(光学字符识别)引擎会对每个单元格内的文字进行识别。此处,中科逸视的技术优势在于:
- 上下文纠错:利用自然语言处理技术,结合单元格所在行列的语义信息,对识别结果进行智能校正,有效提升手写体、模糊字、盖章覆盖等复杂场景的识别率。
- 结构化输出:最终,系统将识别出的文字信息严格按照分析出的表格结构进行重组,输出为可编辑的Excel、CSV或可直接存入数据库的JSON格式,完美保留原始表格的数据逻辑。
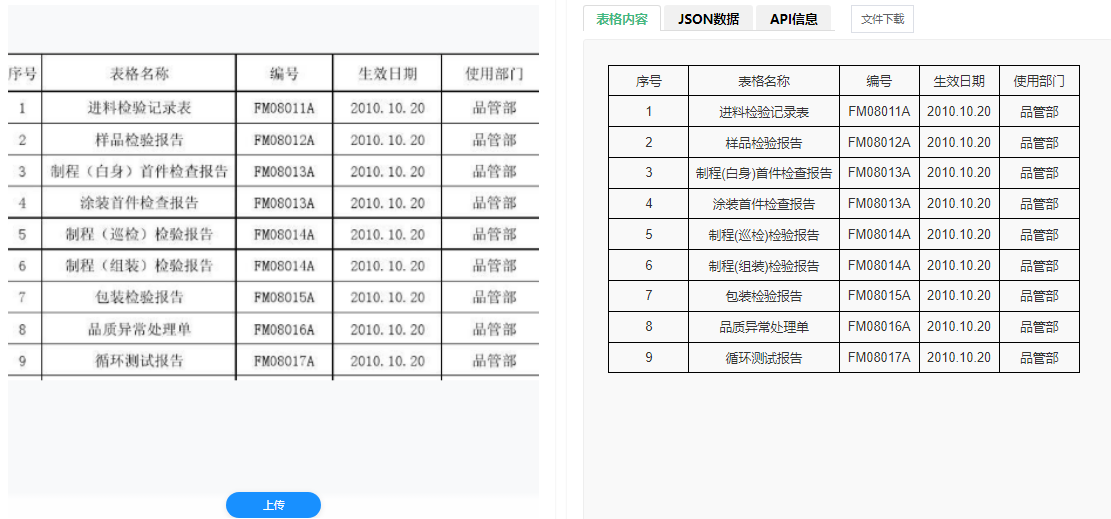
功能特点:精准、高效、全面的技术优势
基于上述先进原理,中科逸视的表格识别技术在档案管理应用中展现出四大核心功能特点:
- 高精度与高鲁棒性:技术对档案中常见的挑战应对自如。无论是因年代久远产生的纸张泛黄、污渍,还是印刷不清、字体多样,甚至是手写体表格,系统都能保持极高的识别准确率。其对复杂格式(如无线表、嵌套表)的强大解析能力,远超传统OCR软件。
- 全要素还原与结构化输出:不仅仅是文字,技术能够100%还原表格的所有要素,包括合并单元格、表格线、文字样式(加粗、倾斜)等。输出的不再是杂乱的文本,而是"所见即所得"的结构化数据,可直接用于后续的数据分析、查询和业务系统集成,极大地提升了数据的可用性。
- 批量化与自动化处理:表格识别技术可无缝集成到档案管理系统中,实现对海量档案表格的批量、自动化处理。用户只需将成批的档案扫描件导入系统,即可在短时间内获得全部的结构化数据,工作效率提升数十倍乃至上百倍,真正释放了人力。
- 强大的自适应与学习能力:系统内置的深度学习模型具备持续优化的能力。通过反馈学习机制,它可以针对特定行业(如金融报表、医疗档案、人事表格)的特定表格格式进行定向优化,越用越"聪明",识别精度和效率随时间推移而不断提升。
应用价值:重塑档案管理新范式
将中科逸视的表格识别技术应用于档案管理系统,带来的变革是颠覆性的:
- 从"库存"到"智库":将沉睡在档案室纸堆中的表格数据激活,转化为可检索、可分析的数字资产,构建企业或机构的"数据智库"。
- 业务流程再造:大幅缩短了数据查询和统计的时间,为审计、决策、历史研究等业务场景提供即时、准确的数据支持。
- 降本增效与合规保障:减少了大量人工投入,降低了人为错误风险,同时确保了数字化过程的准确性与一致性,满足日益严格的数据合规要求。
中科逸视(北京)科技有限公司的表格识别技术,以其深刻的技术原理和卓越的功能特点,正成为驱动档案管理系统迈向智能化时代的核心动力。它不仅仅是一项识别工具,更是一把开启档案数据宝藏的钥匙,助力各行各业在数字化转型的征程中,挖掘历史数据的深层价值,擘画未来发展的智慧蓝图。