第四章 大语言模型(LLM)详解
4.1 认识大语言模型(LLM)
在前三章中,我们从自然语言处理(NLP)的基础概念出发,逐步深入到注意力机制和Transformer架构------这些引发NLP领域革命性变革的核心技术。随着Transformer的出现,NLP领域进入了预训练-微调的全新范式,一系列基于Transformer的预训练语言模型不断刷新各类NLP任务的性能上限。
2022年底,ChatGPT的横空出世再次颠覆了人们对NLP技术的认知,大语言模型(Large Language Model,LLM)开始取代传统预训练语言模型(PLM)成为领域主流。这种以LLM为核心的新研究范式,正推动NLP领域迎来前所未有的变革。从2022年底至今,LLM的能力边界不断拓展,通用基座大模型数量呈指数级增长,相关概念和应用日新月异,标志着大模型时代的全面到来。
本章将结合前文介绍的模型架构知识,深入解析LLM的定义、特点和核心能力,揭示LLM与传统深度学习模型的本质区别,并详细阐述LLM的三阶段训练过程,为读者提供理解LLM工作原理的理论基础。
4.1.1 什么是LLM?
大语言模型(LLM)是指参数量更大、在更大规模语料上训练的语言模型。
我们在第一章已经介绍过语言模型的基本概念:通过预测下一个token(词元)来进行训练的NLP模型。LLM采用与传统预训练语言模型相似的架构和预训练任务(如基于Decoder-Only架构的因果语言模型任务),但凭借更庞大的参数规模和海量训练语料,展现出与传统模型截然不同的能力。
通常来说,LLM指参数量达到数百亿甚至更多 的语言模型,它们在数万亿token 的语料上通过分布式计算集群进行预训练,具备远超传统预训练模型的文本理解与生成能力。随着研究的深入,LLM的参数范围逐渐扩大,广义上的LLM已涵盖从十亿参数 (如Qwen-1.5B)到万亿参数 (如GPT-4)的各类大型语言模型。只要模型展现出涌现能力(即在复杂任务上表现出远超传统模型的性能),都可被视为LLM。
GPT-3(1750亿参数)通常被认为是LLM的开端,而基于GPT-3通过"预训练(Pretraining)→监督微调(SFT)→人类反馈强化学习(RLHF)"三阶段训练得到的ChatGPT,则真正开启了LLM时代。自2022年11月OpenAI发布ChatGPT以来,短短几年内已涌现出上百个各具特色的LLM。以下是2022年11月至2025年11月国内外部分代表性大模型的发展时间线:
| 时间 | 开源LLM | 闭源LLM |
|---|---|---|
| 2022.11 | - | OpenAI-ChatGPT |
| 2023.02 | Meta-LLaMA、复旦-MOSS | - |
| 2023.03 | 斯坦福-Alpaca、Vicuna、智谱-ChatGLM | OpenAI-GPT-4、百度-文心一言、Anthropic-Claude、Google-Bard |
| 2023.04 | 阿里-通义千问、Stability AI-StableLM | 商汤-日日新 |
| 2023.05 | 微软-Pi、TII-Falcon | 讯飞-星火大模型、Google-PaLM 2 |
| 2023.06 | 智谱-ChatGLM2、上海AI Lab-书生浦语、百川-BaiChuan、虎博-TigerBot | 360-智脑大模型 |
| 2023.07 | Meta-LLaMA 2 | Anthropic-Claude 2、华为-盘古大模型3 |
| 2023.08 | - | 字节-豆包 |
| 2023.09 | 百川-BaiChuan 2 | Google-Gemini、腾讯-混元大模型 |
| 2023.11 | 零一万物-Yi、幻方-DeepSeek | xAI-Grok |
| 2024.03 | Meta-LLaMA 3、Qwen-72B | OpenAI-GPT-4o |
| 2024.05 | 智谱-ChatGLM3、阿里-通义千问-MoE | Anthropic-Claude 3 |
| 2024.08 | 书生浦语2、DeepSeek-V2 | Google-Gemini Ultra、百度-文心一言4.0 |
| 2024.11 | LLaMA 4、Qwen-100B | OpenAI-GPT-5预览版 |
| 2025.03 | 百川-BaiChuan 3、智谱-ChatGLM4 | 腾讯-混元大模型2.0 |
| 2025.06 | 深度求索-DeepSeek-MoE | Anthropic-Claude 4、华为-盘古大模型4 |
| 2025.10 | Meta-LLaMA 5 | OpenAI-GPT-5、 Anthropic-Claude 4.5、GLM4.6 |
当前,全球科技企业和研究机构正持续推出性能更强的LLM,不断探索通往通用人工智能(AGI)的路径。
4.1.2 LLM的核心能力
(1)涌现能力(Emergent Abilities)
LLM与传统PLM最显著的区别在于其具备涌现能力。这种能力指的是:在相同架构和预训练任务下,某些能力在小型模型中不明显,但在达到一定规模的大型模型中会突然显现。这类似于物理学中的"相变"现象------随着模型规模增大,性能会突破临界点并迅速提升,实现"量变引起质变"。
涌现能力通常与复杂任务相关,但NLP领域更关注LLM展现出的通用能力------即能够应对各种不同NLP任务的综合能力。正是这种涌现能力,使得学界和业界对LLM抱有极高期待:尽管当前LLM与人类期待的通用人工智能仍有差距,但随着研究深入、高质量数据积累和更高效架构的出现,LLM有望逐步具备通用人工智能所需的核心能力,为人类生活带来根本性变革。
(2)上下文学习(In-context Learning)
上下文学习能力由GPT-3首次提出,指LLM能够在仅提供自然语言指令或少量任务示例的情况下,通过理解上下文生成相应输出,无需额外训练或参数更新。
传统PLM在完成高成本的预训练后,通常需要针对特定下游任务进行有监督微调。即使是参数量较小的模型(如BERT类模型,约0.5B参数),微调也需要10G以上显存,且需要1k至数万条人工标注数据,成本较高。而具备上下文学习能力的LLM,无需额外训练即可通过少量示例或调整指令处理大部分任务,大幅降低了算力和数据成本。
这种能力正引发NLP研究范式的变革:从传统的"预训练-微调"转向"提示工程(Prompt Engineering)"------通过设计合适的提示词激发LLM的能力。例如,目前大多数NLP任务通过优化提示词或提供1-5个示例,即可使GPT-4等模型达到甚至超过传统PLM微调的效果。
(3)指令遵循(Instruction Following)
通过使用自然语言描述的多任务数据进行微调(即指令微调),LLM能够在未见过的指令任务上表现良好。这意味着经过指令微调的LLM可以理解并遵循全新指令,无需事先见过类似示例,展现出强大的泛化能力。
指令遵循能力使我们无需为每个任务单独训练模型,只需在指令微调阶段混合多种任务类型训练其泛化能力,LLM就能处理绝大多数人类指令,灵活解决各种问题。这一点在ChatGPT上体现得尤为明显------它不再局限于学术研究,而是能广泛服务于各行各业:写作文、编程序、批改试卷、分析文档等。
这种能力使LLM能真正与多个行业结合,通过人工智能技术赋能人类生活的方方面面。无论是当前热门的智能代理(Agent)、工作流自动化(WorkFlow),还是未来可能出现的全能助理,其核心都依赖于LLM的指令遵循能力。
(4)逐步推理(Step by Step Reasoning)
逻辑推理(尤其是多步骤复杂推理)一直是NLP的难点,也是人工智能难以获得广泛认可的重要原因。传统NLP模型通常无法解决需要多步推理的复杂任务(如数学问题)。
而LLM通过采用"思维链(Chain-of-Thought,CoT)"推理策略,能够利用包含中间推理步骤的提示机制解决这些任务。研究表明,这种能力可能与模型训练中包含的代码数据有关------代码训练增强了模型的逻辑推理能力。
逐步推理能力使LLM能够处理复杂逻辑任务,解决日常生活中需要逻辑判断的问题,向"可靠的智能助理"迈出了关键一步。
正是这些独特能力,使LLM成为解决复杂问题和跨领域应用的强大工具,也让研究人员相信LLM是迈向通用人工智能、推动人类社会生产力变革的重要途径。目前已有众多基于LLM的应用落地,如微软基于GPT-4的Copilot,通过代码补全、提示和编写等功能,显著提升了程序员的工作效率。
4.1.3 LLM的主要特点
除上述核心能力外,LLM还有一些值得关注的特点,这些也是当前研究的重要方向:
(1)多语言支持
LLM由于训练语料的海量性和多样性,天生具备多语言处理能力,但其在不同语言上的表现受训练语料和指令微调影响较大。目前英文高质量语料仍占多数,因此以GPT-4为代表的多数模型在英文上表现优于中文。而针对中文优化的国内模型(如文心一言、通义千问等)则在中文场景中更具优势。
(2)长文本处理
上下文长度是影响LLM能力的重要因素,因此LLM比传统PLM更注重长文本处理能力。传统PLM(如BERT、T5)通常限制在512 token,而LLM通过优化训练策略,已能支持4k、8k甚至32k的上下文长度。
多数LLM采用旋转位置编码(RoPE)或AliBi等具有"长度外推能力"的位置编码方式,使其在推理时能处理远超训练长度的文本。例如,InternLM在32k长度上预训练,但通过RoPE可处理200k长度的文本。长文本处理能力增强了LLM的信息阅读和总结能力,使其能完成"阅读《红楼梦》并撰写高考作文"这类复杂任务。
(3)多模态拓展
LLM的强大能力为跨模态应用奠定了基础。通过增加额外参数处理图像表示,结合Adapter层和图像编码器,并在图文数据上进行微调,可构建支持文字-图像双模态的模型,实现图文问答和生成等功能。未来,如何更好地对齐文本与图像表示,打造更强大的多模态大模型,是重要研究方向。
(4)幻觉问题
幻觉指LLM根据提示生成虚假或错误信息的现象(如捏造不存在的学术论文引用)。这是LLM的固有缺陷,也是应用中的重大挑战------在医疗、金融等对准确性要求极高的领域,幻觉可能导致严重后果。
目前缓解幻觉的方法包括提示词限制、检索增强生成(RAG)等,但都只能在一定程度上减轻问题,无法彻底根除。幻觉问题仍是LLM研究的重要课题。
此外,LLM的三阶段训练流程、自我反思能力等也是值得研究的特点,我们将在后续章节详细讨论。
4.2 LLM的训练流程
上一节介绍了LLM的定义和核心能力------通过大规模参数和海量语料获得的涌现能力,以及由此衍生的上下文学习、指令遵循和逐步推理能力,这些共同推动了NLP领域的变革。那么,如何训练出具备这些能力的LLM?LLM的训练与传统预训练模型有何区别?
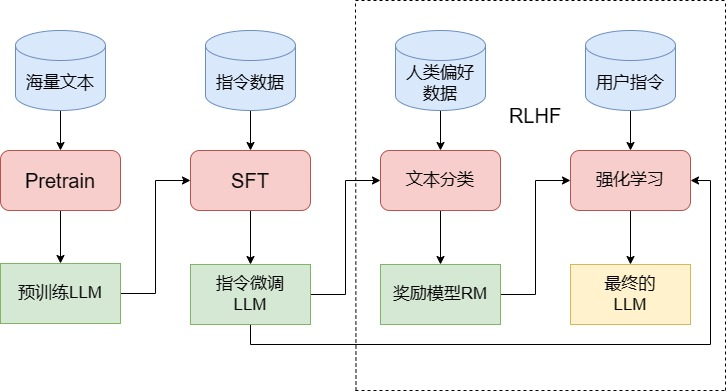
图4.1 LLM训练的三个阶段
通常,训练一个完整的LLM需要经过三个阶段:预训练(Pretrain)、监督微调(SFT)和人类反馈强化学习(RLHF)。本节将详细讲解每个阶段的过程、核心难点和注意事项,帮助读者从理论上理解LLM的训练流程。
4.2.1 预训练(Pretrain)
预训练是LLM训练中最核心、工程量最大的第一步。LLM的预训练与传统预训练模型类似,都是使用海量无监督文本对随机初始化的模型参数进行训练。如第三章所述,当前主流LLM几乎都采用Decoder-Only的类GPT架构(如LLaMA架构),预训练任务也沿用了GPT的经典任务------因果语言模型(Causal Language Model,CLM)。
因果语言模型的核心是"预测下一个token"------给定上文,让模型预测接下来的token。LLM预训练与传统模型的核心差异在于体量和资源消耗。
根据定义,LLM的参数量远超传统预训练模型。传统模型如BERT-base(110M参数)和BERT-large(340M参数)已被视为大型模型,但LLM通常具有数百亿甚至上千亿参数,即使是小型LLM也有十亿级参数(如Qwen-1.8B)。
| 模型 | 隐藏层数量 | 隐藏层维度 | 注意力头数 | 参数量 | 预训练数据量 |
|---|---|---|---|---|---|
| BERT-base | 12 | 768 | 12 | 0.1B | 3B token |
| BERT-large | 24 | 1024 | 16 | 0.3B | 3B token |
| Qwen-1.8B | 24 | 2048 | 16 | 1.8B | 2.2T token |
| LLaMA-7B | 32 | 4096 | 32 | 7B | 1T token |
| GPT-3 | 96 | 12288 | 96 | 175B | 300B token |
| GPT-4 | - | - | - | ~1.8T | ~10T token |
更重要的是,LLM需要更大规模的预训练语料。根据OpenAI提出的Scaling Law(C ~ 6ND,其中C为计算量,N为模型参数,D为训练token数),训练token数应约为模型参数的1.7倍(如175B参数的GPT-3需要300B token)。而LLaMA的研究则表明,使用20倍于参数的token数训练可达到最优效果(175B参数模型需3.5T token)。
如此庞大的参数和数据量,使得LLM预训练需要巨大的算力资源。即使是训练1B参数的模型,也需要多卡分布式GPU集群,通过分布式框架对模型参数、中间结果和数据进行切分,耗时以天为单位。通常,百亿级LLM需要1024张A100训练一个多月,十亿级模型也需要256张A100训练数天,计算成本极高。
因此,分布式训练框架成为LLM训练的必备工具,其核心思想是数据并行 和模型并行:
-
数据并行:当模型可被单张GPU容纳但数据量过大时,将数据分配到不同GPU,每张GPU运行相同模型但处理不同批次数据,训练中同步梯度并更新参数。总批次大小为各卡批次大小之和。
-
模型并行 :当模型参数量超过单张GPU内存时,将模型拆分到多个GPU,每张GPU存储不同层或组件,协作完成计算。
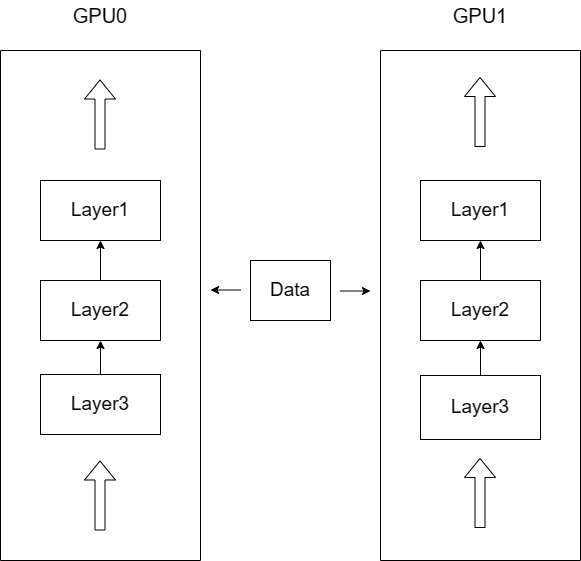
图4.2 模型并行与数据并行示意图
在这两种并行方式基础上,衍生出了更高效的分布式策略,如张量并行、3D并行和零冗余优化器(ZeRO)等。当前主流分布式框架包括Deepspeed、Megatron-LM和ColossalAI,其中Deepspeed应用最广泛。
Deepspeed的核心是ZeRO和CPU-offload技术。ZeRO通过优化数据并行时的显存占用,支持更大规模模型:
- ZeRO-1:对优化器(如Adam)状态参数进行分片,每张卡仅存储1/N的参数
- ZeRO-2:进一步对模型梯度进行分片,每张卡存储1/N的梯度和优化器状态
- ZeRO-3:将模型参数也进行分片,每张卡仅存储1/N的模型参数、梯度和优化器状态
分片程度越高,单卡显存占用越少,但通信开销越大。实际使用中需根据资源和模型规模动态选择策略。
除计算资源外,训练数据是预训练的另一大挑战。LLM的知识主要来自预训练语料,因此需涵盖多种来源并合理配比。主流开源语料包括CommonCrawl、C4、Github、Wikipedia等,不同LLM会在此基础上加入私有高质量语料并调整配比------数据配比是影响模型性能的关键因素之一。例如LLaMA的预训练数据配比为:
| 数据集 | 占比 | 磁盘大小 |
|---|---|---|
| CommonCrawl | 67.0% | 3.3 TB |
| C4 | 15.0% | 783 GB |
| Github | 4.5% | 328 GB |
| Wikipedia | 4.5% | 83 GB |
| Books | 4.5% | 85 GB |
| ArXiv | 2.5% | 92 GB |
| StackExchange | 2.0% | 78 GB |
训练中文LLM面临更大的数据挑战------高质量中文语料相对匮乏。英文在Wikipedia、Arxiv等数据集中占主导地位,而开源中文预训练数据(如SkyPile-150B、yayi2_pretrain_data)规模仍落后于英文数据集。国内模型(如ChatGLM、Baichuan)的预训练数据多未开源。
数据处理与清洗同样关键,研究表明数据质量比数量更重要。预训练数据处理通常包括:
- 文档准备:从互联网爬取内容,进行URL过滤(去除有害内容)、文本提取(从HTML中提取纯文本)和语言筛选。
- 语料过滤:去除低质量内容(乱码、广告等),可通过模型分类器或人工定义的质量指标实现。
- 语料去重:删除高相似度文档(基于hash算法或子串匹配),避免重复内容影响模型泛化能力。
目前已有多个高质量预处理语料和工具,如RedPajama-1T、SlimPajama-627B等,其中627B的SlimPajama通过精选去重,效果优于1T的RedPajama。
4.2.2 监督微调(SFT)
预训练是LLM能力的基础,模型的大部分知识都来自预训练阶段。但预训练仅赋予模型能力,还需通过第二步------监督微调(Supervised Fine-Tuning,SFT)将其激发出来。
经过预训练的LLM类似"博览群书却不求甚解的书生"------能流畅续写文本,却未必理解内容含义,因为其预训练任务仅是预测下一个token,未针对下游任务或用户指令进行优化。
SFT的作用就是"教这个书生如何运用知识"。与传统PLM针对特定任务微调不同,LLM的SFT通常通过指令微调实现,目标是训练模型的"通用指令遵循能力"。
指令微调的输入是各类用户指令,输出是期望模型做出的回复。例如:
input: 告诉我今天的天气预报?
output: 根据天气预报,今天晴转多云,最高温度26℃,最低温度9℃,昼夜温差大,请注意保暖。SFT的核心是让模型从多种指令中学习泛化的指令遵循能力,因此数据质量和配比至关重要:
- 数据量与覆盖范围:单个任务500-1000样本即可取得不错效果,但为实现泛化,需覆盖多种任务类型,总数据量通常达数亿token。
- 数据配比:不同类型指令的配比影响模型表现。OpenAI的InstructGPT使用了10种指令类型,其中文本生成占45.6%,开放域问答占12.4%,头脑风暴占11.2%等。
高质量指令数据获取难度大------不同于预训练的无监督语料,SFT需要有监督的指令-回复对,需设计多样化指令并进行高质量人工标注(成本极高)。为降低成本,研究人员提出用LLM生成指令数据,如Alpaca数据集就是通过种子提示让ChatGPT生成更多指令及回复构建的。
SFT数据通常包含三个字段:
json
{
"instruction": "用户指令",
"input": "执行指令所需的补充信息(可选)",
"output": "模型应生成的回复"
}例如翻译任务可表示为:
json
{
"instruction": "将下列文本翻译成英文:",
"input": "今天天气真好",
"output": "Today is a nice day!"
}为使模型适应新范式,SFT常采用特定格式。例如LLaMA的微调格式为:
Instruction:{{content}} Response:其中content是指令与输入的拼接(完整指令)。上述翻译任务在LLaMA中的输入为:
Instruction:将下列文本翻译成英文:今天天气真好Response:模型需生成的完整输出为:
Instruction:将下列文本翻译成英文:今天天气真好 Response:Today is a nice day!注意,指令微调本质仍是CLM训练(预测下一个token),只是输入格式引导模型生成符合指令的回复。输入部分通常不参与损失计算,仅优化回复部分。
随着LLM发展,多轮对话能力日益重要------模型需参考历史对话生成回复。例如:
用户:你好,我是Datawhale成员。
模型:您好,请问有什么可以帮助您的?
用户:你知道Datawhale是什么吗?
模型:Datawhale是一个开源组织。多轮对话能力完全来自SFT阶段,需将训练数据构造成多轮格式。假设对话为<prompt_1><completion_1><prompt_2><completion_2><prompt_3><completion_3>,构造样本的三种方式:
- 仅拟合最后一轮回复:
input=<prompt_1><completion_1><prompt_2><completion_2><prompt_3>,output=[MASK]*N<completion_3>(丢失中间信息) - 拆分为N个样本:每轮对话单独构成样本(重复计算多)
- 预测每轮输出:
input=<prompt_1><completion_1><prompt_2><completion_2><prompt_3><completion_3>,output=[MASK]<completion_1>[MASK]<completion_2>[MASK]<completion_3>(最优方式,利用CLM的单向注意力特性)
目前主流LLM均采用第三种方式进行多轮对话SFT。
4.2.3 人类反馈强化学习(RLHF)
RLHF(Reinforcement Learning from Human Feedback)是利用强化学习优化LLM的关键步骤。相较于GPT-3已具备的SFT雏形,RLHF被认为是ChatGPT超越GPT-3的核心突破。
从功能上看,LLM训练可分为预训练 和对齐(alignment) 两个阶段:预训练赋予模型知识,对齐则使模型与人类价值观一致,输出符合人类期望的内容。其中SFT实现模型与指令对齐,而RLHF则从更深层次实现与人类价值观对齐,确保模型安全、有用且无害。
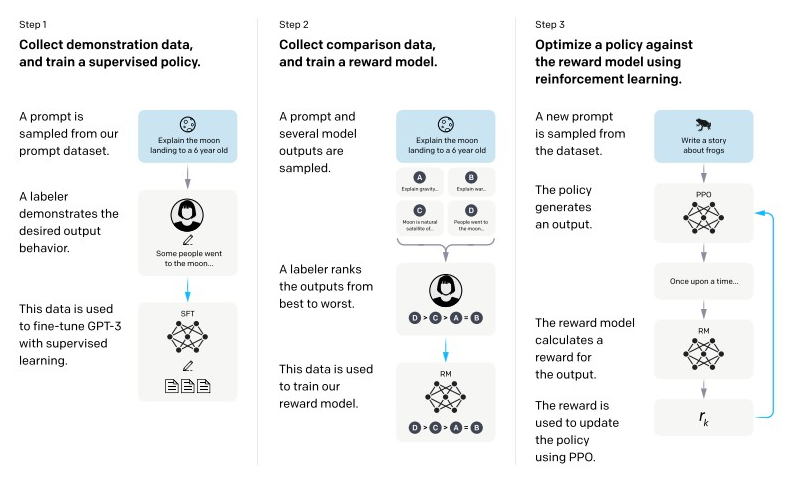
图4.3 ChatGPT的训练三阶段
RLHF的核心思路是引入强化学习技术,通过人类反馈引导LLM生成更符合人类偏好的回复。强化学习研究智能体如何在环境中通过行动获取反馈,进而优化策略以最大化奖励。应用到LLM中,就是让LLM生成回复,由人工标注员评估反馈,使模型逐渐学会生成人类偏好的内容。
可以类比为学生练习过程:预训练是学习基础知识,SFT是学习解题方法,RLHF则是通过大量练习和老师批改,不断优化解题策略。
如图4.3所示,RLHF包含两个关键步骤:训练奖励模型(RM)和PPO训练。
(1)训练奖励模型(Reward Model)
奖励模型用于量化评估LLM回复的质量------给定输入和多个候选回复,奖励模型输出每个回复的评分(奖励值),反映人类偏好。
训练过程:
- 让经过SFT的模型对同一输入生成多个不同回复
- 人工标注员对这些回复进行排序(或直接打分),形成偏好数据
- 用这些偏好数据训练奖励模型,使其学会预测人类偏好
奖励模型的输入是完整的对话历史(输入+回复),输出是一个标量分数,代表该回复的质量。
(2)PPO训练
PPO(Proximal Policy Optimization)是一种强化学习算法,用于优化LLM的生成策略,使其生成的回复能获得奖励模型的高分。
训练过程:
- 基于SFT模型初始化策略模型(待优化的LLM)
- 策略模型对输入生成回复,由奖励模型给出评分
- PPO算法根据奖励值更新策略模型,使模型更倾向于生成高分回复
- 为避免模型过度优化奖励模型而偏离原始知识,通常会引入"KL散度惩罚项",限制新策略与SFT模型的差异
通过RLHF,LLM能更好地理解人类偏好(如回复的相关性、安全性、有用性等),生成更符合人类期望的内容。这一步骤是ChatGPT等模型实现自然交互能力的关键。
综上,LLM的三阶段训练流程环环相扣:预训练奠定知识基础,SFT实现指令对齐,RLHF实现价值观对齐。这一流程共同塑造了LLM的强大能力,使其从"知识存储库"转变为"智能助手"。