谷歌的新研究,让AI也能像人类一样持续学习而不遗忘了。
一般情况下,当我们学会一项新技能后,并不会忘记如何走路、说话这些基本能力。然而,这正是人工智能长期面临的困境。当AI学习新知识时,往往会像覆盖旧磁带一样,损害甚至完全抹去已经掌握的旧技能 ,这种现象被称为 "灾难性遗忘"。
现在,谷歌研究院带来了一项突破性解决方案。11月7日,谷歌正式发布了全新的机器学习范式------嵌套学习(Nested Learning) ,直指这个困扰AI领域数十年的根本性难题。

灾难性遗忘并非新问题。在传统机器学习中,模型在固定数据集上完成训练后便进入部署阶段。一旦需要学习新任务,模型往往需要重新训练或微调,而这极易导致旧知识被覆盖。
这就好比一个原本精通图像分类的AI系统,在学习目标检测后可能完全丧失原有的识别能力;或者一个语音助手在升级方言理解功能后,反而忘记了标准普通话的处理逻辑。
研究表明,在连续学习超过五个任务后,传统模型的平均性能下降幅度高达60%以上。这种局限性严重阻碍了AI在需要长期经验积累的领域应用,如医疗诊断、自动驾驶等。
嵌套学习:统一架构与算法的全新范式
谷歌提出的嵌套学习范式带来了根本性的变革。其核心理念是将模型架构与优化算法统一起来,将复杂模型视为一系列相互嵌套或并行的优化问题。
在嵌套学习框架下,模型中的每个组件都有自己的"上下文流"和更新速率。这就像人脑的学习机制------我们对眼前事物的瞬时记忆更新极快,为考试而进行的短期记忆更新速度次之,而构成世界观、价值观的长期知识则更新得非常缓慢。
谷歌研究团队基于这一范式开发了名为Hope的概念验证模型,它基于Titans架构的自修改循环网络,深度集成了连续体内存系统(CMS)。这种设计使模型能够通过自我参照机制优化自身内存结构,支持近乎无限层级的上下文学习。

技术突破:从深度优化器到连续内存系统
嵌套学习范式的创新体现在三个关键技术突破上。
首先,深度优化器将优化器本身作为可学习模块,改进了目标函数,提升了对不完美数据的鲁棒性。传统优化器如Adam中的动量项,在嵌套学习视角下可被看作是微型的关联记忆模块。
同时,连续体内存系统(CMS)构建了由不同更新频率模块组成的内存光谱,实现了从短期到长期记忆的平滑过渡。CMS由一系列神经网络块连接而成,每个块关联着特定的更新频率,彻底改变了传统AI模型中短期记忆和长期记忆的二元划分。
自修改架构则使模型能够根据任务动态调整自身的学习算法,包括注意力机制中的键、值、查询投影等关键部分。这让模型拥有了在使用过程中不断优化自己学习策略的能力。
实验结果
在实验评估中,Hope模型在语言建模与常识推理任务中表现出更低的困惑度和更高的准确性,优于现代循环模型和标准Transformer架构。
特别引人注目的是,在"大海捞针"测试中,Hope展示出了卓越的长文本记忆与检索能力,验证了CMS在处理超长序列信息中的有效性。这一测试结果证明了嵌套学习范式在解决灾难性遗忘问题上的潜力。
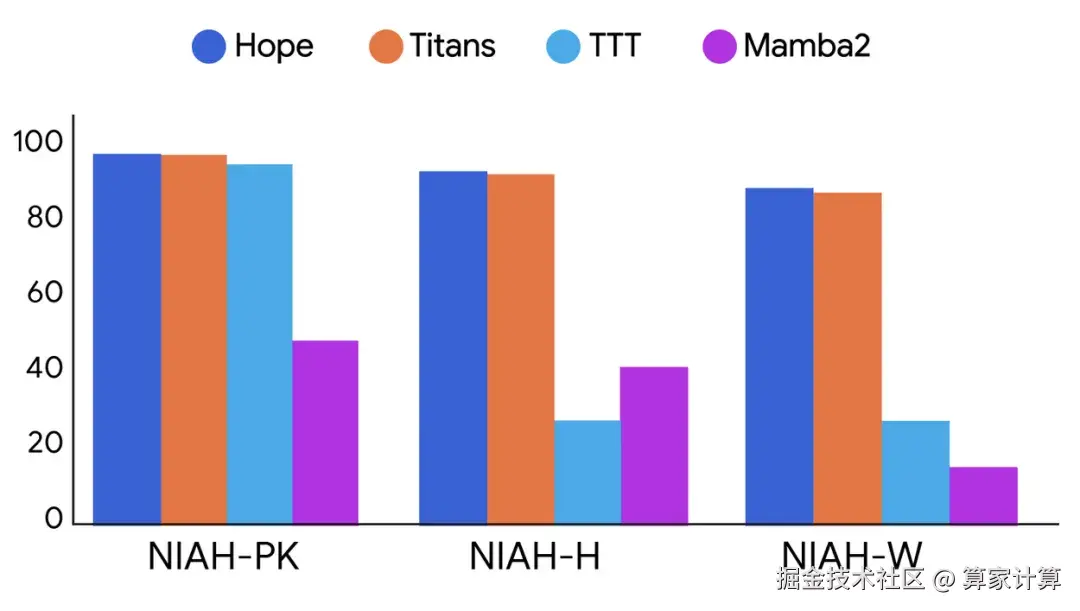
研究团队在340M、760M和1.3B三种参数规模的Hope模型上进行了全面测试,Hope的平均分超越了所有对比模型。这表明嵌套学习范式在不同规模的模型上都能发挥积极作用。
嵌套学习的意义远不止于技术层面的突破。它为实现持续学习的人工智能系统开辟了全新路径。
这一技术将可能很大程度上改变那些需要终身学习的应用领域,比如机器人、自动驾驶、个性化AI助手等。这些系统将不再需要昂贵的、从头开始的再训练,而是能够像人类一样,在保留已有知识的基础上,不断学习和成长。
正如谷歌研究人员所言:"我们相信嵌套学习范式为弥补当前大语言模型有限、易遗忘的特性与人脑卓越的持续学习能力之间的差距奠定了坚实基础。"
当然,这项研究仍在发展之中。研究人员指出,目前的工作主要聚焦于记忆的在线巩固过程,对类似人脑睡眠时的离线重放和整理机制探索有限。但这无疑让我们距离那个能像人类一样持续学习、不断进化的通用人工智能又近了一步。
大家怎么看?欢迎交流讨论~