目录
🐼Tcp服务器粘包问题
在上一节,我们的Tcp服务器是有一个bug的:
cpp
void HandlerIO(int sockfd, InetAddr client)
{
while (true)
{
char buff[1024];
ssize_t n = read(sockfd, buff, sizeof(buff) - 1); // bug
if (n < 0)
{
LOG(LogLevel::ERROR) << "read from: " << sockfd << " err";
continue;
}
else if (n == 0)
{
LOG(LogLevel::INFO) << "peer exit, me too!";
break;
}
else
{
// 更换这里的逻辑
buff[n] = 0;
std::string result = _cb(buff); // 回调到上层,访问上层业务
int m = write(sockfd, result.c_str(), result.size());
(void)m;
}
}
close(sockfd); // 必须关,防止文件描述符泄露
}我们直接读取对端给我们发来的请求,可能直接是一个命令请求,如"ls -l -a",但是这个命令请求一定是完整的吗?不一定。why?因为Tcp服务器是面向字节流的,Tcp可不管你发的是一个命令,它只当做8个一个普通的字符来处理。也就是Tcp也不知道这条报文给你发完整没,那如果这一次报文中只给你发了"ls -" , 下一次报文开头再给你发"l -a ...",也就是报文的交付可能是不完整的,那此时我们将"ls -" 交给上层处理,我们如果只取了这次报文,这显然是错误的。因为我们没有提取到一个报文真正的有效载荷。这种情况我们叫做粘包问题,需要自定义协议来解决。
🐼如何解决粘包问题
通过协议!将有效载荷提取出来!可是如何双方约定协议呢?双方使用同一个结构体字段。因为协议本质就是结构体!
如何将结构体发送给对方呢?
直接发送结构体变量可以吗?不完全可以!因为网络虚化了os系统之间的差异,但是如果直接发送结构体,这就会导致内存对齐问题,大小端问题,以及跨语言问题等,背道相驰。如果我们不需要考虑os系统之间的差异,还想把协议发给对方,一定不能直接发送结构体。
🐼如何解决发送协议问题
基于上面的内容,首先,我们需要约定协议。
其次,我们需要序列化和反序列化
定义结构体来表示我们需要交互的信息;
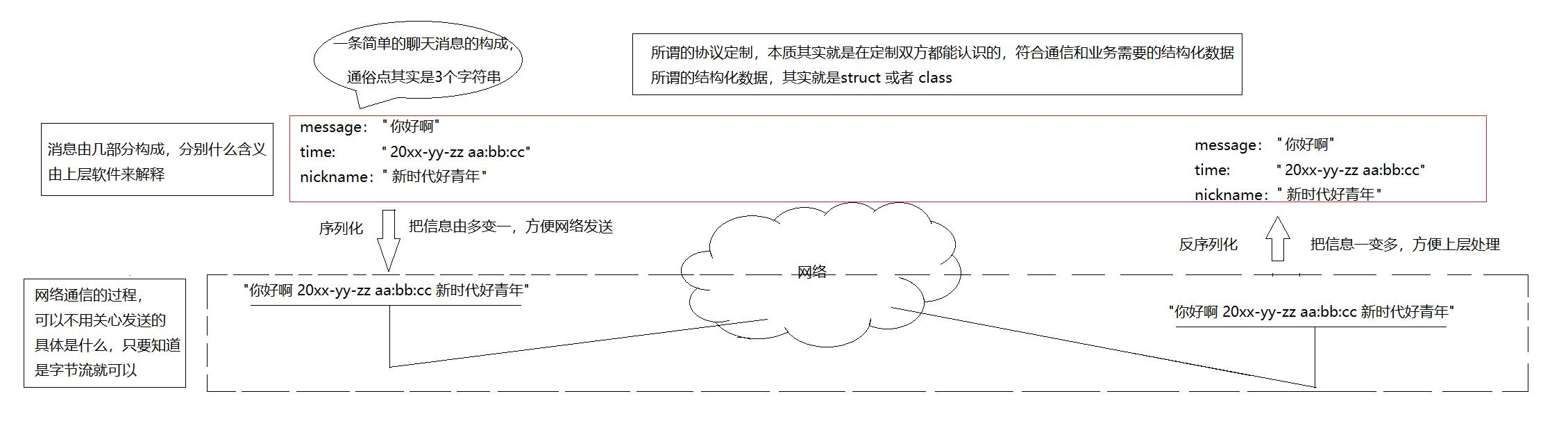
发送数据时将这个结构体按照一个规则转换成字符串, 接收到数据的时候再按照相同的规则把字符串转化回结构体;这个过程叫做 "序列化" 和 "反序列化,如图:
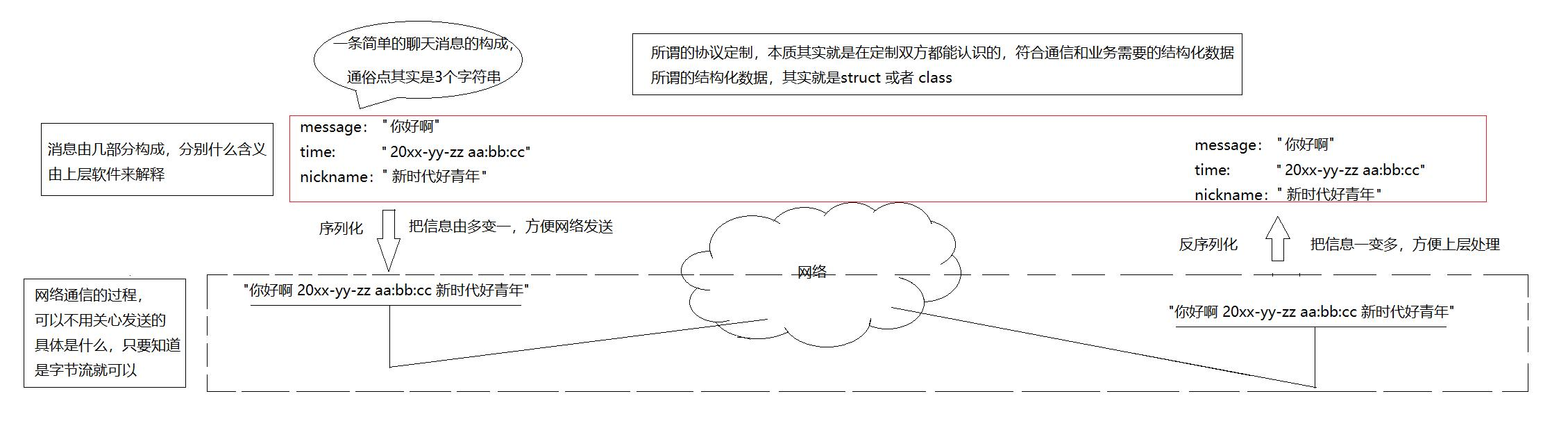
所以,为什么要使用序列化和反序列化?
1.方便网络发送,把多个字段打包序列化成一个字符串!
2.方便上层协议的可扩展性和可维护性!(这个怎么理解呢,当我们的结构体字段增多时,或者修改,会影响Tcp吗,不会!因为Tcp是面向字节流的。而使用序列和反序列化,无非就是这个字符串大一点点,长一点点,序列和反序列化修改某个字段即可。所以方便上层处理)
只要保证, 一端发送时构造的数据,在另一端能够正确的进行解析, 就是ok 的. 这种约定, 就是应用层协议。下面我们手搓一个网络版本计算机。来理解协议和序列化和反序列化的过程化。
🐼序列化和反序列化
在写网络版本计算机之前,我们先使用jsoncpp来学会使用序列化和反序列化。
首先,你得保证你的机器有jsoncpp库,可以通过**find /usr/include -name "json"**查找一下。如果没有,自行安装。
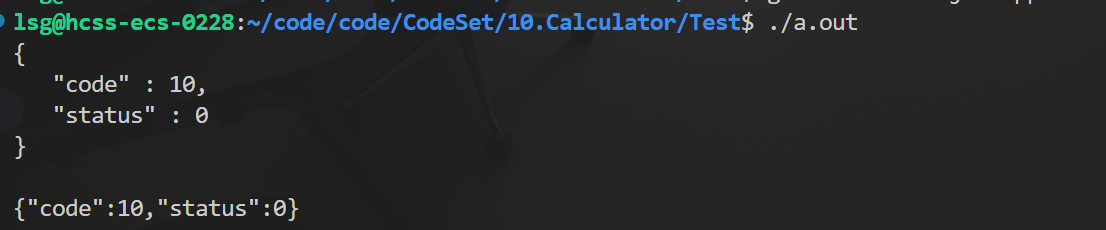
序列化:
cpp
int main()
{
// 序列化
Json::Value root;
root["code"] = 10;
root["status"] = 0;
// 使用有格式
Json::StyledWriter writer;
std::string json_result = writer.write(root); // 把多个字段打包序列化成一个字符串
std::cout << json_result << std::endl;
// 适合网络发送
Json::FastWriter fwriter;
std::string json_fresult = fwriter.write(root); // 把多个字段打包序列化成一个字符串
std::cout << json_fresult << std::endl;
return 0;
}两种序列化格式,第一种是给用户看的,第二种适合网络发送。
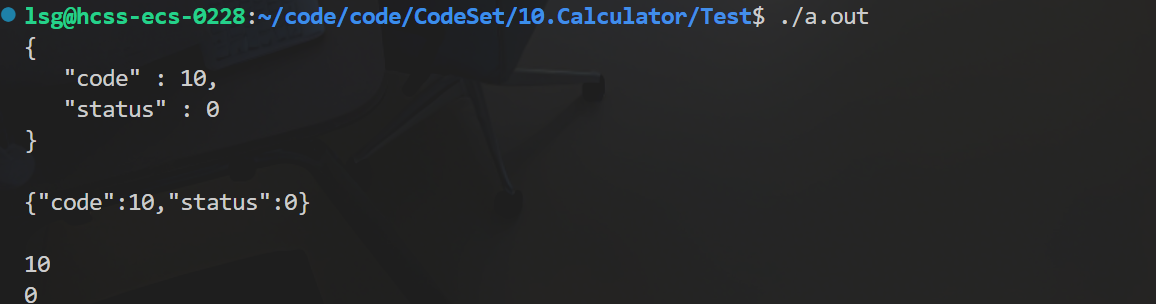
将上面字段反序列化:
cpp
int main()
{
// 序列化
Json::Value root;
root["code"] = 10;
root["status"] = 0;
// 使用有格式
Json::StyledWriter writer;
std::string json_result = writer.write(root); // 把多个字段打包序列化成一个字符串
std::cout << json_result << std::endl;
// 适合网络发送
Json::FastWriter fwriter;
std::string json_fresult = fwriter.write(root); // 把多个字段打包序列化成一个字符串
std::cout << json_fresult << std::endl;
// 反序列化
Json::Value droot;
Json::Reader reader;
reader.parse(json_result, droot); // 将json_result进行反序列化到droot
// 提取各个字段
int code = droot["code"].asInt();
int status = droot["status"].asInt();
std::cout << code << std::endl;
std::cout << status << std::endl;
return 0;
}
最后在说一下,我们左手有了协议,右手有了序列化和反序列化,那么凭什么说协议+序列化和反序列化就能解决Tcp数据包粘包问题,也就是可能一个报文不完整的问题。其实不是说能解决Tcp数据包粘包问题,而是说如果你给我发的报文不完整,我就不交给上层处理。所以,就能一定将一个完整的有效载荷交给上层逻辑处理!
而我们之前将数据直接读上来交给上层,这种逻辑本身就是错误的!
🐼模版方法类
在写网络版本计算机之前,我们引入一个设计模块,模版方法类。
我们已经学习了Udp套接字和Tcp套接字,**我们发现初始化一个服务器的方法好像是一成不变的并且为了扩展性,此时我们可以使用这个设计模式。创建一个基类,里面的方法都是仅仅是纯虚类,作为抽象类,而完全为子类服务,其中定义方法集,当子类调用时,里面的方法通过子类方法重写都调用子类的方法,这也倒逼着子类必须实现,**Socket.hpp
cpp
#pragma once
#include <iostream>
#include <string>
#include <cstdio>
#include <sys/socket.h>
#include <sys/types.h>
#include <arpa/inet.h>
#include <netinet/in.h>
#include "Logger.hpp"
#include "Comm.cc"
#include "InetAddr.hpp"
// 设计方式。模版方法类
const static int gbacklog = 128;
class Socket
{
public:
virtual ~Socket() = default; // 基类析构函数定义为虚函数,方便后续基类指针指向子类,析构子类对象
virtual void CreateSocketOrDie() = 0;
virtual void BindSocketOrDie(uint16_t port) = 0;
virtual void ListenSocketOrDie(int backlog = gbacklog) = 0;
virtual bool ConnectSocketOrDie(InetAddr &server) = 0;
virtual std::shared_ptr<Socket> Accept(InetAddr *client) = 0;
virtual int SockFd() = 0;
virtual ssize_t Recv(std::string *out) = 0;
virtual ssize_t Send(const std::string &in) = 0;
virtual void Close(int sockfd) = 0;
// 固有步骤,使用模版方法,当子类对象调用方法时,调用子类的方法
// TcpServer
void BuildTcpServerSocketMethod(uint16_t port)
{
CreateSocketOrDie();
BindSocketOrDie(port);
ListenSocketOrDie();
}
// UdpServer
void BuildUdpSocketMethod(uint16_t port)
{
CreateSocketOrDie();
BindSocketOrDie(port);
}
};
const static int gdeflistenfd = -1;
class TcpSocket : public Socket
{
public:
// 给listen套接字
TcpSocket() : _sockfd(gdeflistenfd)
{
}
// 给accept接受上来的套接字
TcpSocket(int sockfd) : _sockfd(sockfd)
{
}
void CreateSocketOrDie() override
{
_sockfd = socket(AF_INET, SOCK_STREAM, 0);
if (_sockfd < 0)
{
LOG(LogLevel::FATAL) << "create a socket err";
exit(SOCKET_CREATE_ERR);
}
LOG(LogLevel::INFO) << "create a socket success,sockfd: " << _sockfd;
}
void BindSocketOrDie(uint16_t port) override
{
InetAddr local(port);
int n = bind(_sockfd, (const sockaddr *)local.Addr(), local.len()); // 写入内核
if (n < 0)
{
LOG(LogLevel::FATAL) << "bind a name for socket err: " << strerror(errno);
exit(SOCKET_BIND_ERR);
}
LOG(LogLevel::INFO) << "bind a name for socket success";
}
void ListenSocketOrDie(int backlog) override
{
int m = listen(_sockfd, backlog);
if (m < 0)
{
LOG(LogLevel::FATAL) << "listen for connections on a socket err";
exit(SOCKET_LISTEN_ERR);
}
LOG(LogLevel::INFO) << "listen for connections on a socket success";
}
std::shared_ptr<Socket> Accept(InetAddr *client) override
{
struct sockaddr_in peer;
socklen_t len = sizeof peer;
int sockfd = accept(_sockfd, (sockaddr *)&peer, &len);
client->Init(peer);
if (sockfd < 0)
{
LOG(LogLevel::WARNING) << "listen for connections on a socket err," << client->SocketToString();
return nullptr;
}
return std::make_shared<TcpSocket>(sockfd);
}
int SockFd() override
{
return _sockfd;
}
ssize_t Recv(std::string *out) override
{
char buff[1024];
ssize_t m = recv(_sockfd, buff, sizeof(buff) - 1, 0);
if (m > 0)
{
// 为什么用+=, 因为Tcp是面向字节流的。这一次将数据读上来,可能并不是一个完整的有效载荷。
// 保存前一次的数据,保证能读到一个完整的有效载荷。
// 使用 += 可以累积多次接收的数据,直到组成完整的应用层消息:
buff[m] = 0;
*out += buff;
}
return m;
}
ssize_t Send(const std::string &in) override
{
ssize_t m = send(_sockfd, in.c_str(), in.size(), 0);
return m; // 略
}
void Close(int sockfd) override
{
close(sockfd);
}
bool ConnectSocketOrDie(InetAddr &server)
{
int n = connect(_sockfd, (const sockaddr *)server.Addr(), server.len());
if (n < 0)
{
LOG(LogLevel::FATAL) << "initiate a connection on a socket err";
exit(SOCKET_CONNET_ERR);
}
LOG(LogLevel::INFO) << "initiate a connection on a socket success";
return true;
}
~TcpSocket()
{
}
private:
int _sockfd;
};🐼网络版本计算器
什么是网络版本计算机器? 我们需要实现一个服务器版的加法器. 我们需要客户端把要计算的两个加数发过去, 然后由服务器的上层进行计算, 最后再把结果返回给客户端.我们重点感受我们自定义协议和序列化和反序列化的过程。
重点代码:
Protocol.hpp(自定义协议)
cpp
#pragma once
#include <iostream>
#include <string>
#include <jsoncpp/json/json.h>
// 这不就是我们自已定协议吗,序列和反序列化,根据我们的要求解析
class Request
{
public:
Request() : _x(0), _y(0), _oper(0) // 暂时????
{
}
// 序列化
void Serialize(std::string *out) // client
{
Json::Value root;
root["x"] = _x;
root["y"] = _y;
root["oper"] = _oper;
Json::FastWriter writer;
*out = writer.write(root);
}
// 反序列化
bool DeSerialize(const std::string &in_json) // server
{
Json::Value droot;
Json::Reader reader;
if(!reader.parse(in_json, droot))
return false;
_x = droot["x"].asInt();
_y = droot["y"].asInt();
_oper = droot["oper"].asInt();
return true;
}
int X() { return _x; }
int Y() { return _y; }
char Oper() { return _oper; }
void SetX(int x) { _x = x; }
void SetY(int y) { _y = y; }
void SetOper(char oper) { _oper = oper; }
~Request()
{
}
private:
int _x;
int _y;
char _oper;
};
class Response
{
public:
Response() : _result(0), _code(0)
{
}
void Serialize(std::string *out) // server
{
Json::Value root;
root["result"] = _result;
root["code"] = _code;
Json::FastWriter writer;
*out = writer.write(root);
}
bool DeSerialize(const std::string &in_json) // 客户端
{
Json::Value droot;
Json::Reader reader;
if (!reader.parse(in_json, droot))
return false;
_result = droot["result"].asInt();
_code = droot["code"].asInt();
return true;
}
void SetResult(int result) { _result = result; }
void SetCode(int code) { _code = code; }
void Print()
{
std::cout << "result: " << _result << std::endl;
std::cout << "code[" << _code << "]" << std::endl;
}
~Response() {}
private:
int _result; // 运行结果
int _code; // 表示运行错误码
};
// 规定 发来的协议以"len/r/njson/r/n开头"
const static std::string sep = "/r/n";
class Protocol
{
private:
static bool IsSafety(const std::string &str)
{
for (int i = 0; i < str.size(); i++)
{
if (!(str[i] >= '0' && str[i] <= '9'))
{
return false;
}
}
return true;
}
public:
static std::string Pack(const std::string &in_json)
{
if (in_json.empty())
return std::string();
std::string len = std::to_string(in_json.size());
return len + sep + in_json + sep;
}
// /r/n
// len/r/n
// len/r/njson
// len/r/njson/r/n
// len/r/njson/r/nlen/r/njson/r/n
// len/r/njson/
// len/r/
// len/
// 0表示解包未完成 -1表示client发送的数据报错误 >0表示实际解包的字节个数
static int UnPack(std::string &recv_string, std::string *out_json)
{
if (recv_string.empty() || out_json == nullptr)
{
return 0;
}
size_t pos = recv_string.find(sep);
if (pos == std::string::npos)
{
return 0;
}
// 获取 json串长度
std::string len_string = recv_string.substr(0, pos);
if (!IsSafety(len_string))
{
return -1;
}
// 如果我得到了当前报文的长度
// 根据协议,我可以推测出,一个完整报文的长度是多少
// 得到整个串长度
size_t json_len = std::stoi(len_string);
int total_len = len_string.size() + 2 * sep.size() + json_len; // 整个串的长度
// 没有一个完整的报文
if (recv_string.size() < total_len)
{
return 0;
}
*out_json = recv_string.substr(len_string.size() + sep.size(), json_len);
recv_string.erase(0, total_len);
return json_len;
}
};TcpServer.hpp
cpp
#pragma once
#include <iostream>
#include <memory>
#include <functional>
#include <unistd.h>
#include <sys/types.h>
#include <signal.h>
#include "Socket.hpp"
using callback_t = std::function<std::string(std::string &)>;
class TcpServer
{
public:
TcpServer(uint16_t port, callback_t cb) : _tcpsockfd(std::make_unique<TcpSocket>()),
_port(port),
_cb(cb)
{
_tcpsockfd->BuildTcpServerSocketMethod(_port);
}
void Run()
{
signal(SIGCHLD, SIG_IGN);
while (true)
{
InetAddr client;
std::shared_ptr<Socket> sockfd = _tcpsockfd->Accept(&client);
if (sockfd < 0)
continue; // 暂时
LOG(LogLevel::DEBUG) << "获取一个新连接: " << client.SocketToString()
<< ", sockfd : " << sockfd->SockFd();
pid_t id = fork();
if (id < 0)
{
LOG(LogLevel::FATAL) << "资源不足,请赶紧检查";
continue;
}
else if (id == 0)
{
// 子进程
sockfd->Close(_tcpsockfd->SockFd()); // 防止误操作
HandlerIO(sockfd);
exit(OK);
}
// 父进程
_tcpsockfd->Close(sockfd->SockFd()); // 防止误操作
}
}
void HandlerIO(std::shared_ptr<Socket> &sockfd)
{
std::string recv_json; // 保存每个Tcp长连接的报文,可能一次并没有读完整,可能需要多次拼接
// 长连接
while (true)
{
ssize_t n = sockfd->Recv(&recv_json);
if (n < 0)
{
LOG(LogLevel::WARNING) << "recv err";
break;
}
else if (n == 0)
{
LOG(LogLevel::INFO) << "对端已经关闭连接,me too";
break;
}
else
{
// 交给上层
std::string result = _cb(recv_json);
if(!result.empty())
{
sockfd->Send(result);
}
}
}
sockfd->Close(sockfd->SockFd()); // 必须关闭,防止文件描述符泄露
}
~TcpServer()
{
_tcpsockfd->Close(_tcpsockfd->SockFd());
}
private:
std::unique_ptr<Socket> _tcpsockfd;
uint16_t _port;
callback_t _cb;
};Parse.hpp
cpp
#pragma once
#include <iostream>
#include <string>
#include <functional>
#include "Protocol.hpp"
#include "Logger.hpp"
#include "Comm.cc"
using handler = std::function<Response(Request &)>;
class Parser
{
private:
handler _handler;
public:
Parser(handler handler) : _handler(handler)
{
}
Parser() {}
std::string Parse(std::string &recv_str)
{
std::string send_str; // 发回报文
LOG(LogLevel::DEBUG) << "收到请求:" << recv_str;
while (true)
{
std::string json_str;
// 1.解析报文
int ret = Protocol::UnPack(recv_str, &json_str);
if (ret < 0)
{
LOG(LogLevel::WARNING) << "非法报文";
exit(OK); // 子进程停止服务
}
else if (ret == 0)
{
LOG(LogLevel::DEBUG) << "本次解析完毕,已经解析到没有一个完整报文了";
break; // 没有一个完整报文了
}
else
{
// 成功解析到一个完整报文,一定有一个完整报文等着处理
LOG(LogLevel::DEBUG) << "成功解析到一个完整报文: "<< json_str;
// 2.反序列化
Request req;
if(!req.DeSerialize(json_str))
{
LOG(LogLevel::WARNING) << "反序列化,json: " << json_str
<< ", err,reason: illegal json";
exit(OK) ;
}
Response resp = _handler(req); // 交给上层处理,得到应答-
// 3.将应答报文反序化
std::string temp_str;
resp.Serialize(&temp_str);
// 4.打包
send_str += Protocol::Pack(temp_str); // 面向字节流。全部处理完统一发回
}
}
LOG(LogLevel::DEBUG) << "等待发回: " << send_str;
return send_str;
}
};Calculator.hpp
cpp
#pragma once
#include "Protocol.hpp"
class Calculator
{
public:
Calculator()
{
}
Response Exec(Request &req)
{
int x = req.X();
int y = req.Y();
Response resp;
switch (req.Oper())
{
case '+':
resp.SetResult(x + y);
resp.SetCode(0);
break;
case '-':
resp.SetResult(x - y);
resp.SetCode(0);
break;
case '*':
resp.SetResult(x * y);
resp.SetCode(0);
break;
case '/':
if (y == 0)
{
resp.SetCode(-1);
}
else
{
resp.SetResult(x / y);
resp.SetCode(0);
}
break;
case '&':
resp.SetResult(x & y);
resp.SetCode(0);
break;
default:
resp.SetCode(-2); // 表示未知错误
break;
}
return resp;
}
~Calculator() {}
};
cpp
#include "calculator.hpp" // 应用层
#include "Parser.hpp" // 表示层
#include "TcpServer.hpp" // 会话层
#include "Socket.hpp"
#include <memory>
void Usage(const std::string& msg)
{
printf("Usage: %s + port\n", msg.c_str());
}
int main(int argc, char* argv[])
{
// 1. 启动日志
EnableConsoleLogStrategy();
if(argc != 2)
{
Usage(argv[0]);
exit(0);
}
uint16_t port = std::stoi(argv[1]);
// 2.启动计算机服务
std::unique_ptr<Calculator> cal = std::make_unique<Calculator>();
// 3.开启解析服务
std::unique_ptr<Parser> parser = std::make_unique<Parser>([&cal](Request &req){
return cal->Exec(req);
});
// 4.启动服务器
std::unique_ptr<TcpServer> tsvr = std::make_unique<TcpServer>(port, [&parser](std::string& recv_json)->std::string{
return parser->Parse(recv_json);
});
tsvr->Run();
return 0;
}✅细节一:我们定的协议在哪里?len/r/njson/r/n就是我们定的协议。而Json也就是根据双方的"共识"Request和Response的字段完成的。
✅细节二:为什么OSI协议定的特别好。我们从代码角度就能理解了,当服务器收到一个报文Json串(会话层),是先需要解析(表示层)的,再交给上层calculator(网络层)。一路调上去,最后返回来。
✅细节三:那这么写,凭什么就一定能获得一个完整报文? 因为都保存在recv_string中,通过+= 操作,通过循环读取和字符串拼接,将一个TCP连接上可能被TCP协议拆分的多个数据包(或一个被分多次送达的应用层报文)在应用层缓冲区中重新组装,从而保证了最终能获取到一个完整的应用层报文。在应用层,我们有责任将从同一个TCP连接上多次接收到的数据块拼接起来,直到组成一个完整的、有业务意义的消息单元。代码中的recv_string变量就扮演了应用层接收缓冲区的角色。这样,我就敢保证,我每次读取到了一个完整的有效载荷交给上层处理!!!比如:
第一次读取 :可能只收到了报文的前半部分,recv_string的内容是不完整的。
第二次及后续读取 :程序会继续读取网络数据,并将新到的数据块拼接到recv_string的后面。
在应用层,我们都要提供一种能力,将报头和有效载荷分离的能力(解包)通过UnPack(我们自已定的协议 "len/r/njson/r/n")
几乎任何层的协议, 都要在报头中提供,决定将自己的有效载荷交付给上层哪一个协议的能力(分用),我们也做到了
✅细节四:解耦工作如何做的?这样做的好处?通过回调函数,这样做保证了各个层之间互不影响。并且如果替换每一层的服务代码改动也是很内聚的。
🐼守护进程
首先为什么要有守护进程,因为我们的服务器随时可以使用crtl+c杀掉!获取当我们关闭xshell时,我们的网络服务就终止了!
下面先介绍什么是前台进程和后台进程,比如sleep 100就是前台进程,在这期间,不处理用户的输入。而sleep 100&就是后台进程,不影响bash,用户可以在进程运行期间,继续访问Linux,所以我们一般把一些耗时的任务放到后台 。前台进程后后台进程的关键在于谁拥有键盘文件!!
我们可以使用jobs查看后台进程,可以使用fg 任务号将后台进程放到前台,使用crtl+z将前台进程在放到后台。为什么后台进程杀不掉?因为后台进程不拥有键盘文件,不能从键盘文件中获取数据,而当我们将后台进程通过fg提到前台,就能杀掉了!
所以前后台,都可以向终端文件写入,但只有前台进程,能够从标准输入(终端文件)获取数据
一次会话,只允许一个前台进程组(任务),可以允许多个后台进程组(任务)同时运行why?因为标准输入只有一个。
什么是一个进程组?
sleep 1000 | sleep 2000 | sleep 3000 &
这就属于一个进程组,它们被创建出来的目的就是完成一个共同的任务。进程组有时也被称为一个作业(Job) ,是一个或多个进程的集合。这些进程通常关联在一起,共同完成一项任务,并且可以由 Shell 作为一个整体来进行管理(比如同时发送信号、同时放到前台或后台)。

所以,创建进程组不是目的,完成任务才是目的。
什么是进程组ID?

进程组ID默认是第一个被创建出来的进程(老大哥),当杀掉这个老大哥,这个进程组ID不变,因为任务还没有完成。我们在操作命令的时候,启动一个进程组(至少是一个进程),来完成某种任务。
什么是Session(会话):
每当一个用户登录的就是 默认就会形成一个session, 一个 Session 是用户从登录系统到注销期间所建立的一次交互周期的环境集合。它代表了用户与系统进行交互的整个工作上下文。
在xhell,我们每登录一次,就是创建了一个会话。 而在每一个会话中,会有多个进程组,比如下载任务的进程组,处理后端任务的进程组,bash进程组...
这些进程组同属于同一个会话。SID

而一个会话会打开一个命令终端,0,1,2。

所以这也就是为什么我们在当前会话默认打开0,1,2的原因。是因为这个会话帮我们打开的。
一次会话:
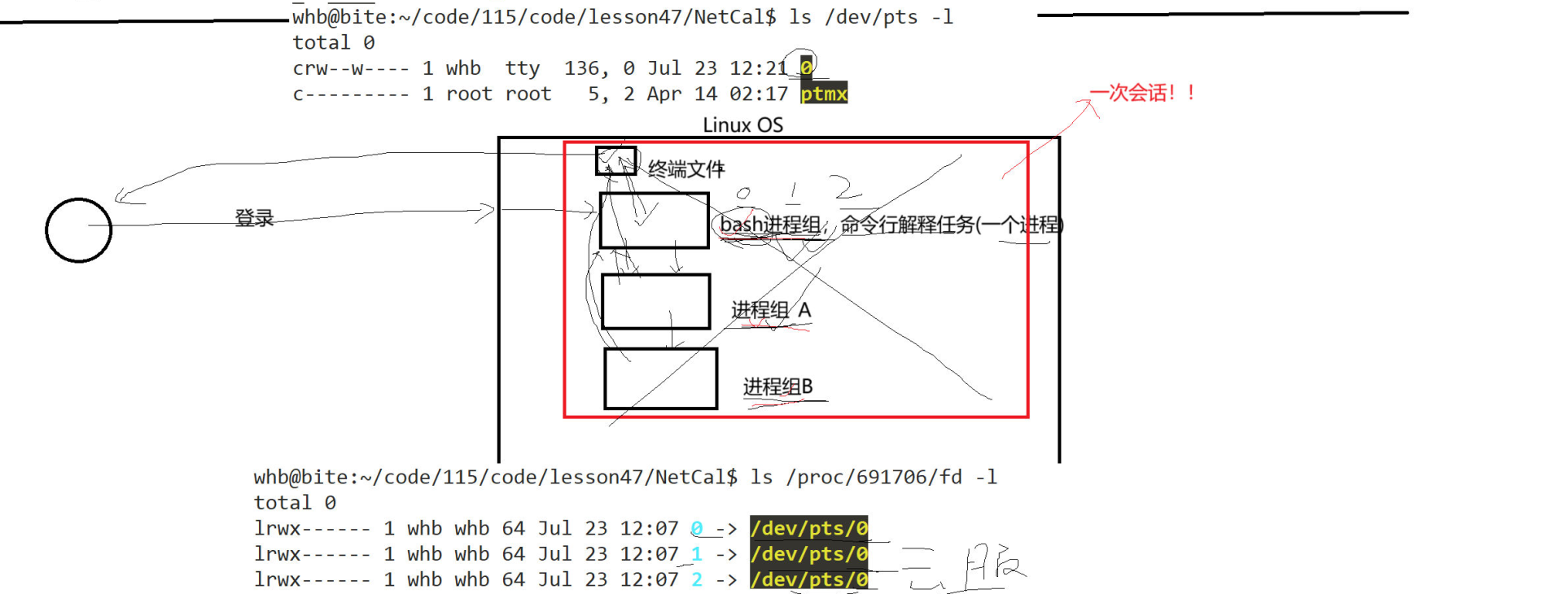
如果有多个用户登录,就会给每一个用户分配一个会话,比如,现在两个用户登录。就会有两个bash,它们的会话ID不同,表示是不同的会话。
而我们的网络服务,本质就是一个会话内的一个进程组,为了完成一个网络服务,以进程组的形式。那这是不是意味着?当我们的会话退出时,我们的服务就会挂掉?是的,会受登录和注销的影响!所以我们要让我们的网络服务形成一个独立的会话!这个过程就是守护进程!
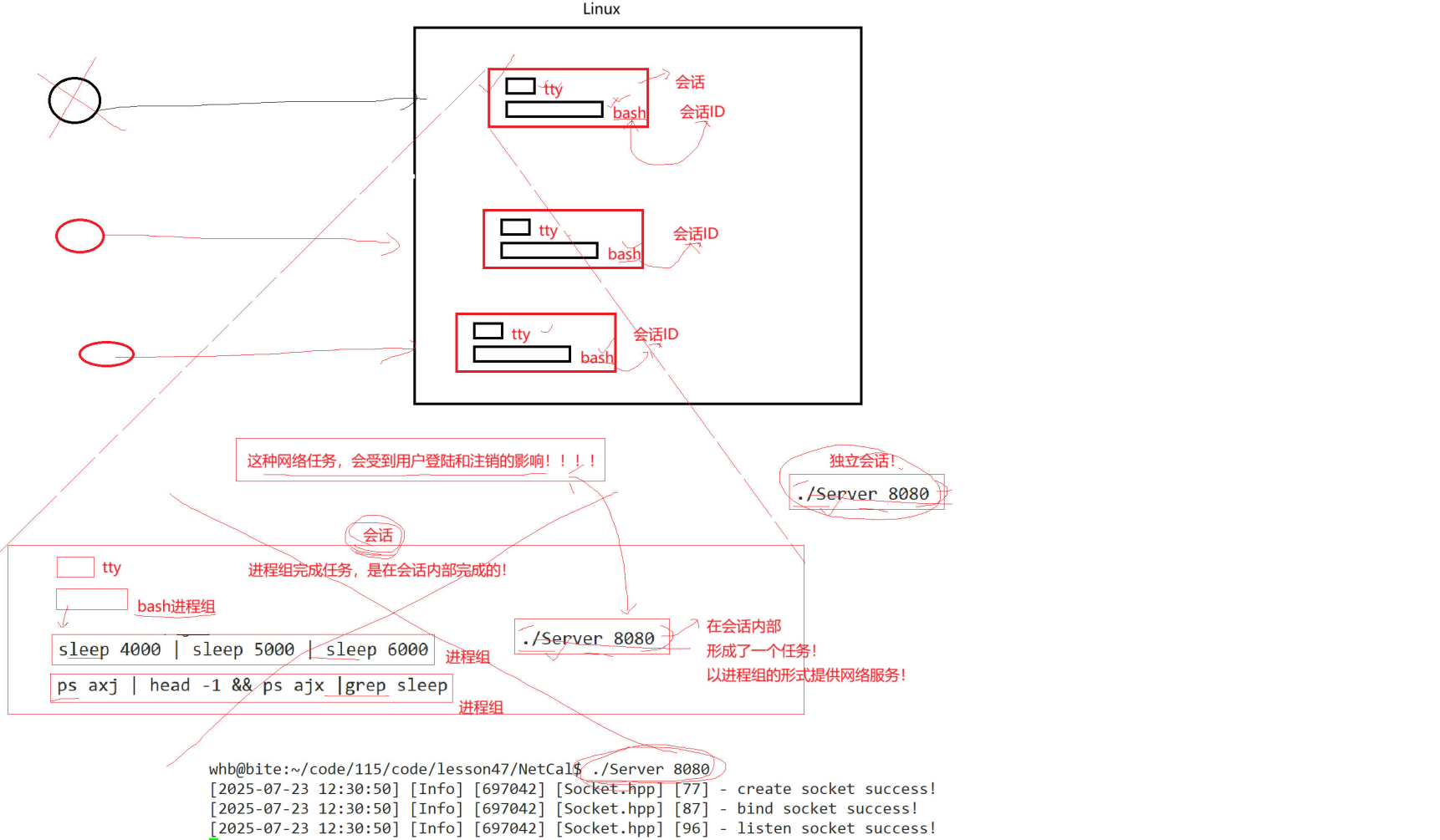
所以什么是守护进程?自成进程组,自成会话的进程组,或者作业,叫做守护进程。
所以如何让我的进程,一个进程成为守护进程呢?
成为一个守护进程,比如先成为一个独立的会话。如何成为一个独立的会话?通过setsid这个系统调用。

setsid有一个规定,就是如果你要将这个进程设置成会话,那么就不能是组长 ,可是当我们的进程启动时,就是一个进程组的组长,所以如何做?父进程创建子进程,然后自已退出,子进程执行后续代码,那么子进程就不是组长了!所以,守护进程本质就是一种孤儿进程。
cpp
// 让自已不要成为组长,交给子进程
if (fork() > 0)
{
exit(0);
}
// 设置为会话
setsid();可是这样还没有完成一个真正的守护进程,最佳实践:
cpp
static void Daemon()
{
// 1.忽略掉导致进程意外终止的信号
signal(SIGCHLD, SIG_IGN);
signal(SIGPIPE, SIG_IGN); // 避免对端客户端已经关闭,服务端还在写,导致错误
// 2.让自已不要成为组长,交给子进程
if (fork() > 0)
{
exit(0);
}
// 3.更改所在路径为根目录
chdir("/");
// 4.设置为会话
setsid();
// 5.将stdin, stdout, stderr重定向到"无底洞"
int fd = open("/dev/null", O_RDWR); // 读写方式打开
if (fd > 0)
{
dup2(fd, 0);
dup2(fd, 1);
dup2(fd, 2);
}
}下面我们来解释一下,1. 为了守护进程不会因为意外的进程而退出,比如当你的服务器向一个已经关闭的连接写入数据时,会产生 SIGPIPE 信号,并且希望忽略子进程退出的信号,让内核回收。
5. 在我们的服务器中,会有大量的输出,如果我们直接将输出关闭,可能太粗暴了。所以,我们采取了一种温柔的处理方式,我们的服务器可以输出内容,但是都输出到/dev/null中,它就像个无底洞,可以吞噬我们的所有输入,所以,这种方式的好处就是,不是不让你输出,而是保证你不会因为关闭输出而导致的意外错误。既然标准输出被吞噬,我们将日志策略设置为文件策略
4.为什么要更改路径为根目录呢?假设我们当前服务已经完成了,目录结构为这样:
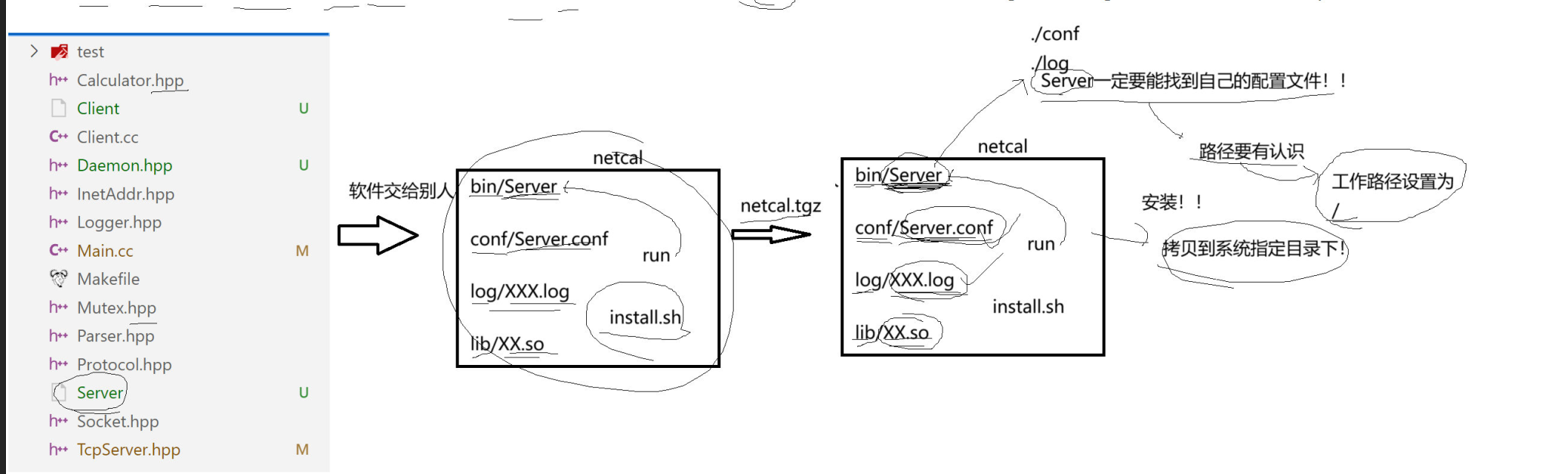
如果我们将我们的软件网络服务打包给别人,是不是要求我们的server能够找到自已的配置文件,如果不是根目录,那么就是相对路径,如果打包的软件不在同一个目录下, 那么就会导致Server找不到自已的配置文件导致的错误;而设置为"/",那么就是绝对路径了,保证了Server一定能找到自已的工作路径。我们可以将日志文件的文件位置放到系统日志目录下。

自此,守护进程神功已成~
下面我们来启动我们的守护进程,测试,:
1.验证:变成后台的孤儿进程

2.验证:stdout,stderr,stderr是否重定向
3.验证:工作路径是否修改了
这是要加sudo,因为工作路径已经更改成了"/",不然,普通用户可能隐藏了
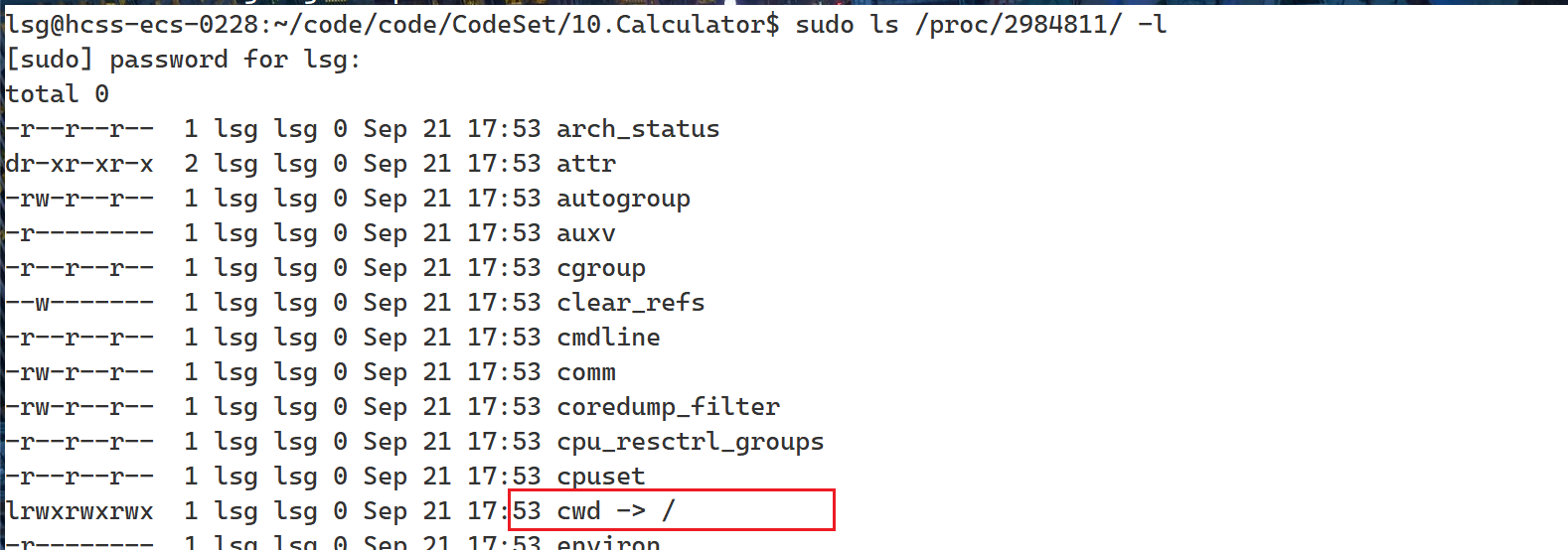
4.验证:验证日志是否在/var/log下创建
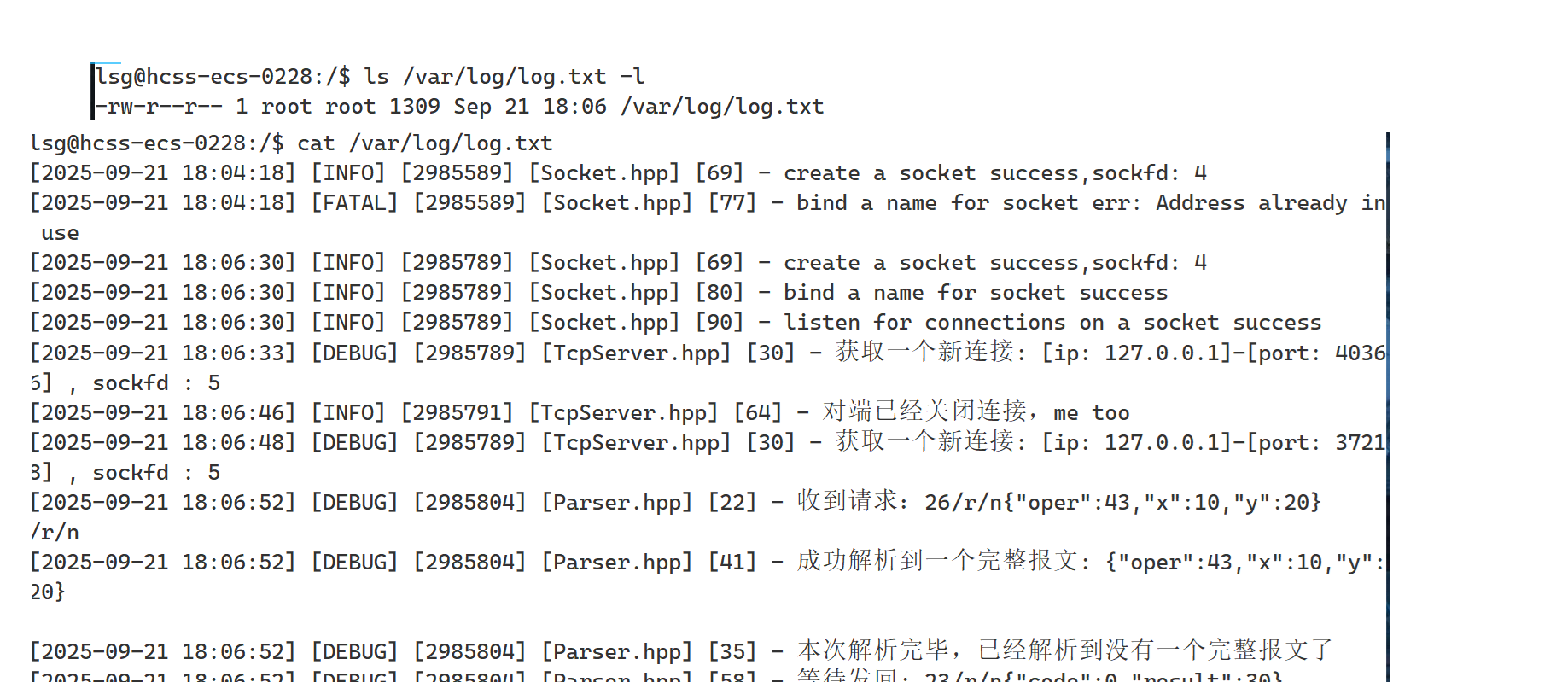
现在,我们的守护进程启动了,如果我们想杀掉守护进程,可以使用killall 守护进程
如果我们想把我们的服务发布出去,可以看看动静态库制作
最后在说一下,Linux有一个函数daemon,也可以实现守护进程的效果,但是没有我们的最佳实践灵活