🌈 引言:你为什么需要知道"聚类"?
想象一下:
- 你是一家电商公司的运营经理,每天有成千上万的顾客在你网站上购物。你不知道谁是"高消费用户",谁是"偶尔逛一逛的路人"。你该怎么给这些用户分组,好做精准营销?
- 你是医院的医生,面对100个病人的体检数据:血压、血糖、胆固醇、体重......你如何发现哪些人有相似的健康风险模式?
- 你是城市规划师,想了解市民的出行习惯:有人每天早晚高峰挤地铁,有人周末开车去郊游,有人根本不出门......你能把他们自动分类吗?
- 你是音乐爱好者,App给你推荐"每日推荐歌单",它怎么知道你喜欢的是"摇滚"还是"轻音乐"?它没问你,却猜对了!
答案只有一个:聚类(Clustering)。
你可能没听过这个词,但你一定在生活里见过它的影子。
聚类,就是让机器自己"发现"数据中的"自然群体" 。
它不告诉你"谁是A谁是B",而是说:"嘿,这100个人里,有3组人行为很像,我们把他们分到一起吧!"
这听起来像魔法?不,这是机器学习中最基础、最强大、最实用的算法之一。
📚 本篇文章你能学到什么?
| 你将学到 | 说明 |
|---|---|
| ✅ 什么是聚类? | 用生活例子讲透,零基础也能懂 |
| ✅ 聚类和分类有什么区别? | 搞清最易混淆的两个概念 |
| ✅ 常见聚类算法有哪些? | K-Means、层次聚类、DBSCAN、高斯混合模型...全解析 |
| ✅ 每种算法怎么工作? | 图解 + 动态比喻 + 数学直觉(无公式!) |
| ✅ 如何选择合适的算法? | 根据你的数据类型"对症下药" |
| ✅ 如何评估聚类效果? | 没有标准答案?我们有实用方法 |
| ✅ 如何用Python动手实现? | 从零开始写代码,每行都有解释 |
| ✅ 真实商业案例解析 | 电商、医疗、用户画像、市场细分 |
| ✅ 常见陷阱与避坑指南 | 90%的人第一次都踩的坑 |
| ✅ 进阶方向指引 | 学完后下一步该学什么? |
🌱 第一章:聚类是什么?
1.1 一个生活化的例子:超市里的顾客
假设你开了一家社区超市,每天有100位顾客来买东西。
你没有会员系统,没有手机App,没有扫码记录。你唯一能观察到的是:
- 每个人买了什么商品?
- 买了多少?
- 什么时候来?
- 一次花多少钱?
你把这些数据记在纸上:
| 顾客编号 | 买牛奶 | 买面包 | 买苹果 | 买啤酒 | 买纸巾 | 买烟 | 总消费 |
|---|---|---|---|---|---|---|---|
| 1 | 2 | 1 | 3 | 0 | 1 | 0 | 45元 |
| 2 | 1 | 2 | 1 | 0 | 1 | 0 | 38元 |
| 3 | 0 | 0 | 0 | 4 | 0 | 2 | 120元 |
| 4 | 1 | 1 | 2 | 0 | 1 | 0 | 40元 |
| 5 | 0 | 0 | 0 | 3 | 0 | 1 | 95元 |
| ... | ... | ... | ... | ... | ... | ... | ... |
你盯着这张表,想:"这些人,是不是可以分成几类?"
- 有人天天买牛奶、面包、苹果------像家庭主妇?
- 有人只买啤酒和烟------像年轻单身男性?
- 有人啥都不买,只买纸巾------像临时路过的人?
你,作为人类,靠直觉就能分出来。 但如果你有10,000个顾客,每人买20种商品,你能靠眼睛看出来吗? 不能。
这时候,你就要请"机器"来帮忙。聚类,就是让机器像你一样,但更快、更准、更不累地,把相似的人/物自动分组。 它不靠你告诉它"这是A类,那是B类",而是自己从数据里"发现"结构。
这就是 无监督学习(Unsupervised Learning) 的核心思想:
- 监督学习 = 老师教学生:"这是猫,这是狗。"
- 无监督学习 = 给学生一堆动物照片,说:"你自己看看,能分几类?"
聚类就是无监督学习中最经典、最常用的方法。
1.2 聚类 vs 分类:最易混淆的两个概念!
很多人第一次听到"聚类"时,会问:"这不就是分类吗?",实际上并不是!它们有本质区别!
| 对比维度 | 分类(Classification) | 聚类(Clustering) |
|---|---|---|
| 目标 | 预测已知类别 | 发现未知类别 |
| 是否有标签 | 有!训练数据里每个样本都标好了"是猫还是狗" | 没有!数据是"裸数据",没人告诉你它属于哪组 |
| 任务性质 | 监督学习 | 无监督学习 |
| 结果可预测 | 输入新数据,能直接输出"属于哪类" | 输出的是"分组结果",但组名是机器起的(比如"组1""组2") |
| 举个栗子 | 给你100张猫狗照片,每张都标了"猫"或"狗",训练模型,以后看到新图能判断是猫还是狗 | 给你100张动物照片,没标任何名字,模型自己发现:"哦,有4种不同的动物形态,我分成了4组" |
📌 一句话总结 :分类是"你告诉机器答案",聚类是"机器自己找答案"。
1.3 聚类能解决哪些实际问题?
聚类不是学术玩具,它在现实世界中无处不在:
| 应用领域 | 聚类用途 | 实际价值 |
|---|---|---|
| 市场营销 | 用户分群(RFM模型) | 精准推送优惠券,提升转化率30%+ |
| 医疗健康 | 疾病亚型发现 | 为不同患者群定制治疗方案 |
| 电商推荐 | 商品聚类 | "买了这个的人,也买了..." 的底层逻辑 |
| 城市管理 | 出行模式识别 | 优化公交线路、共享单车投放 |
| 金融风控 | 欺诈交易检测 | 发现异常交易团伙 |
| 图像处理 | 图像分割 | 从照片中自动识别出"天空""人脸""草地" |
| 生物信息学 | 基因表达聚类 | 找出与癌症相关的基因群 |
| 社交媒体 | 用户兴趣分组 | 推荐相似兴趣的社群 |
💡 聚类的本质是"探索性数据分析" ------ 你不知道答案,但你想"看看数据里藏着什么秘密"。
🧩 第二章:聚类的数学直觉
2.1 数据点:每个样本都是一个"人"
在聚类中,每一个观察对象(顾客、病人、商品、图片)都被称为一个数据点(Data Point)。
每个数据点由多个特征(Feature) 描述。
例如,一个顾客:
- 特征1:月消费金额 → ¥800
- 特征2:购买频次 → 12次/月
- 特征3:最近一次购买距今天数 → 3天
- 特征4:平均单笔金额 → ¥67
我们可以把这些特征看作坐标。
在二维空间中,我们有x和y轴。
在三维空间中,我们有x、y、z轴。
在聚类中,我们可能有几十个维度!
🧠 想象一个"顾客空间": 横轴是"消费金额",纵轴是"购买频率", 每个顾客就是一个点,比如(800, 12)。
现在,如果你把所有顾客画在这个图上,你会看到:
- 有些人点靠左下(消费低、频率低)→ "路人甲"
- 有些人点靠右上(消费高、频率高)→ "VIP客户"
- 有些人点在中间偏右 → "活跃中产"
这些"点聚集在一起"的区域,就是聚类算法要找的"群"!
✅ 聚类的目标:把空间中靠得近的点,归为一组;把离得远的点,分开。
这就像你站在人群里,自然会和熟悉的人站在一起,陌生人离你远一点。
2.2 "近"和"远"怎么定义?------距离度量
聚类的核心思想是:"相似的东西靠得近"。
那"近"怎么量化?
我们用距离(Distance) 来衡量。
📏 最常用的距离:欧几里得距离(Euclidean Distance)
这是你中学学过的"两点间直线距离"。
在二维空间中,点A(2,3),点B(5,7):距离 = √[(5-2)² + (7-3)²] = √[9 + 16] = √25 = 5
在n维空间中,也一样:距离 = √[(x₁₁ - x₂₁)² + (x₁₂ - x₂₂)² + ... + (x₁ₙ - x₂ₙ)²]
这就像用尺子量两个点之间的直线长度。
🚫 但不是所有情况都用欧氏距离!
| 场景 | 推荐距离 | 原因 |
|---|---|---|
| 商品购买记录(0/1) | 汉明距离(Hamming) | 只看"是否购买",不看数量 |
| 文本相似度 | 余弦相似度 | 关注方向,不关注长度(词频总量) |
| 城市间路程 | 曼哈顿距离 | 像出租车只能走横竖路,不能斜穿 |
| 高维稀疏数据 | Jaccard相似度 | 比如两个用户买了哪些商品的交集 |
✅ 你不需要记住这些名字,但要知道:距离是聚类的"语言",选错距离,分组就错!
2.3 聚类的"理想状态"是什么?
一个完美的聚类结果应该满足:
- 组内相似度高:同一个组里的人,特征非常像。
- 组间差异大:不同组之间,差别明显。
- 组数合理:既不是1组(全混一起),也不是100组(每人一组)。
🎯 就像分班:一个班里学生水平差不多,不同班之间有明显差距,不是全校就一个班,也不是每人一个班。
聚类算法的目标,就是找到这样的"最优分组"。
🧠 第三章:主流聚类算法详解
现在,我们来认识四大主流聚类算法。 每个算法都像一个"分组策略大师",各有擅长。
3.1 K-Means:最经典、最常用、最"暴力"的分组法
🎯 算法思想
"先猜K个中心点,然后把每个点扔给最近的中心,再重新算中心,反复迭代,直到不动了。"
🌟 例子:分组打篮球
你有100个学生,想分成3组打3v3篮球。你不知道谁强谁弱,但你想让每组实力均衡。
第一步:你随便选3个学生当"队长"(中心点)
- 队长A:身高185cm,体重80kg
- 队长B:身高160cm,体重55kg
- 队长C:身高175cm,体重70kg
第二步:让其他97个学生,选离自己最近的队长加入
- 小明身高182cm,体重78kg → 离队长A最近 → 加入A组
- 小红身高158cm,体重53kg → 离队长B最近 → 加入B组
- 小李身高176cm,体重68kg → 离队长C最近 → 加入C组
第三步:每组重新选"队长"------算组内所有人身高的平均值、体重的平均值,作为新队长
- A组现在有12人,平均身高183cm,平均体重81kg → 新队长A'
- B组平均身高159cm,平均体重54kg → 新队长B'
- C组平均身高174cm,平均体重69kg → 新队长C'
第四步:所有人重新选最近的队长
可能有人发现:"咦?我现在离B'更近了!" → 换组!
第五步:重复第三、四步,直到没人换组了
→ 收敛!聚类完成!
这就是K-Means!
✅ 优点
- 简单、快速、高效
- 适用于数值型数据
- 适合大数据集
❌ 缺点
- 必须提前指定K值(分几组)→ 怎么选K?(后面讲)
- 对异常点敏感(一个极端值会拉偏中心)
- 只能发现球形簇(不能分出香蕉形、环形)
- 结果可能不稳定(初始中心点不同,结果不同)
📈 适用场景
- 用户分群(电商)
- 图像压缩(把256色变成16色)
- 市场细分(高/中/低消费)
🧪 Python代码实战
python
# 导入必要库
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
# 1. 生成模拟数据:3个聚类中心,100个点
X, y_true = make_blobs(n_samples=100, centers=3, cluster_std=0.60, random_state=42)
# 2. 用K-Means聚类,K=3
kmeans = KMeans(n_clusters=3, random_state=42, n_init=10)
y_pred = kmeans.fit_predict(X)
# 3. 可视化结果
plt.figure(figsize=(8,6))
plt.scatter(X[:, 0], X[:, 1], c=y_pred, cmap='viridis', s=50, alpha=0.7)
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1],
c='red', marker='x', s=200, linewidths=3, label='中心点')
plt.title("K-Means 聚类结果(3组)")
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()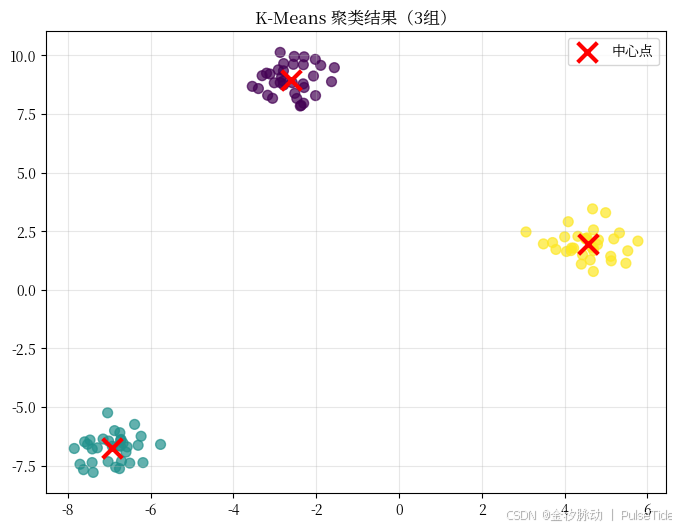
👉 运行结果:你会看到三个颜色不同的点群,中间有红色"×"标记,就是算法找到的"中心"。
💡 你不需要懂
make_blobs是什么,它只是帮我们"造数据"来演示。
3.2 层次聚类(Hierarchical Clustering):像"家族树"一样慢慢合并
🎯 算法思想
"一开始每个人是独立的一组,然后不断把最相似的两组合并,直到只剩一组"。它像一棵树,从下往上长。
🌳 例子:家族谱系树
想象你家有10个亲戚:
- 爷爷
- 奶奶
- 爸爸
- 妈妈
- 自己
- 妹妹
- 叔叔
- 姑姑
- 表哥
- 表姐
第一步:每个人都单独一"组"
第二步:找最相似的两个人合并 → 你和妹妹(同住、同龄、同爱好)→ 合并成"子女组"
第三步:再找最相似的两组 → 爸爸和妈妈(夫妻)→ 合并成"父母组"
第四步:再合并 → "父母组"和"子女组" → 成"核心家庭"
第五步:叔叔和姑姑(兄妹)→ 合并成"叔姑组"
第六步:叔姑组和爸爸组(兄弟)→ 合并成"父辈组"
第七步:表哥和表姐 → 合并成"表兄弟组"
第八步:表兄弟组和父辈组(堂亲)→ 合并成"大家族"
第九步:最后,爷爷奶奶和大家族合并 → 全家福!
这个过程画出来,就是一棵树状图(Dendrogram)。
✅ 优点
- 不需要提前指定K!你可以从树上"剪一刀",得到任意组数
- 可视化强,能看清"谁和谁更近"
- 能发现嵌套结构(比如:家族 → 核心家庭 → 个人)
❌ 缺点
- 计算复杂度高(O(n³)),不适合超大数据(>1000个点)
- 一旦合并,不能撤销("错误的合并"无法回头)
- 对噪声敏感
📈 适用场景
- 生物学(物种分类)
- 社交网络分析(朋友的朋友是谁)
- 市场细分(想看不同层级的客户群)
🧪 Python代码实战
python
from scipy.cluster.hierarchy import dendrogram, linkage
from scipy.cluster.hierarchy import fcluster
import matplotlib.pyplot as plt
# 使用之前生成的数据 X(100个点)
linkage_matrix = linkage(X, method='ward') # ward方法:最小化组内方差
plt.figure(figsize=(10,7))
dendrogram(linkage_matrix, truncate_mode='level', p=5)
plt.title("层次聚类树状图(Dendrogram)")
plt.xlabel("样本索引")
plt.ylabel("距离")
plt.show()
# 剪一刀,分成3组
clusters = fcluster(linkage_matrix, t=3, criterion='maxclust')
plt.scatter(X[:, 0], X[:, 1], c=clusters, cmap='plasma', s=50)
plt.title("层次聚类结果(分成3组)")
plt.show()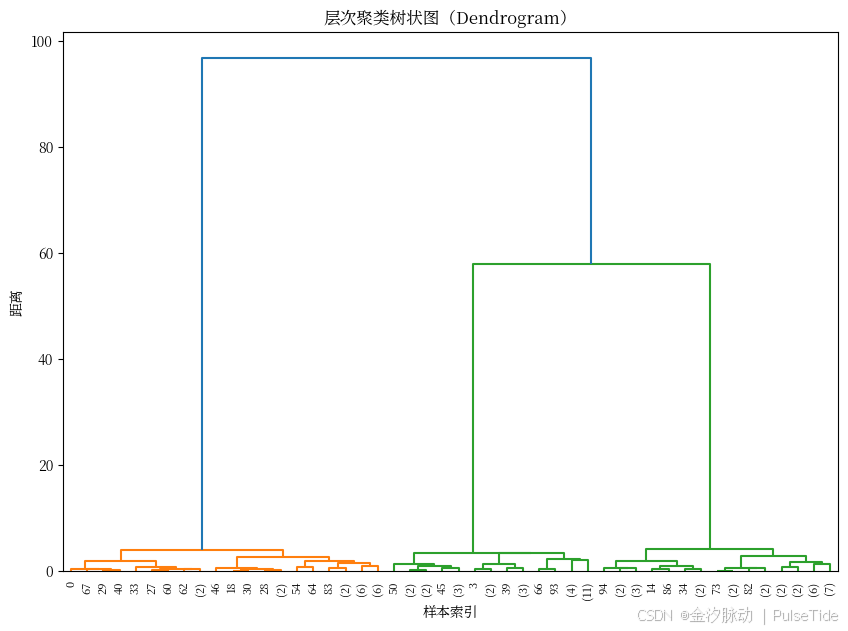
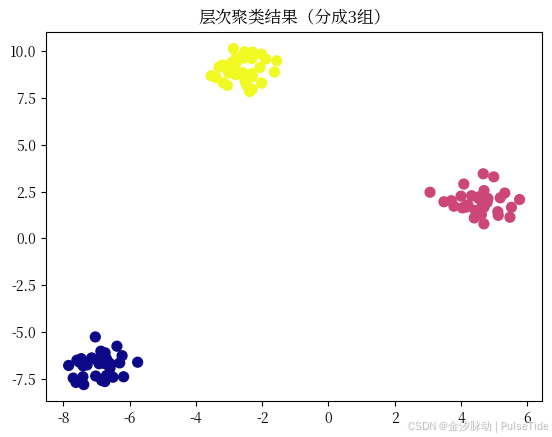
🌟 你看到的树状图,纵向是"合并距离",横向是样本。 距离越远,说明合并的两组越不相似。可以在图上画一条水平线,看穿过几根竖线,就知道分成了几组!
3.3 DBSCAN:能发现"任意形状"和"噪声点"的智能分组器
🎯 算法思想
"不是靠中心,而是靠密度。只要一个点周围有足够多邻居,它就属于一个簇;太少?那就是噪声。"
🌆 例子:地铁站人群
你在晚高峰的地铁站,人挤人。
- 有人在闸机口排长队 → 密度高 → 是"核心人群"
- 有人在角落刷手机 → 周围没人 → 是"孤立个体"
- 有人在通道中间,左右都有人 → 也属于"核心群"
- 有人在出站口,独自站着 → 也是"孤立个体"
DBSCAN不会说:"我要分3组"。
它会说:
- "这个区域人太密了,是个'簇'!"
- "那边那个,周围一个人都没有,是'噪音'(异常)"
- "这里人不多不少,是'边界点',连到大簇里"
✅ 优点
- 不用指定K!
- 能发现任意形状的簇(环形、月牙形、S形都行)
- 自动识别噪声点/异常值(超有用!)
- 对异常值鲁棒
❌ 缺点
- 对参数敏感(
eps和min_samples难调) - 在密度差异大的数据中表现差
- 高维数据效果下降("维度灾难")
📈 适用场景
- 异常检测(信用卡欺诈)
- 地理位置聚类(如:找出犯罪热点区域)
- 图像分割(找前景物体)
- 传感器数据(检测设备故障)
🧪 Python代码实战
python
from sklearn.cluster import DBSCAN
# 使用之前的X数据
dbscan = DBSCAN(eps=0.5, min_samples=5) # 参数:邻域半径=0.5,至少5个邻居才算簇
y_pred = dbscan.fit_predict(X)
# 可视化:-1 表示噪声点
plt.figure(figsize=(8,6))
scatter = plt.scatter(X[:, 0], X[:, 1], c=y_pred, cmap='viridis', s=50, alpha=0.7)
plt.title("DBSCAN 聚类结果(自动识别噪声)")
plt.colorbar(scatter, label='聚类标签(-1=噪声)')
plt.grid(True, alpha=0.3)
plt.show()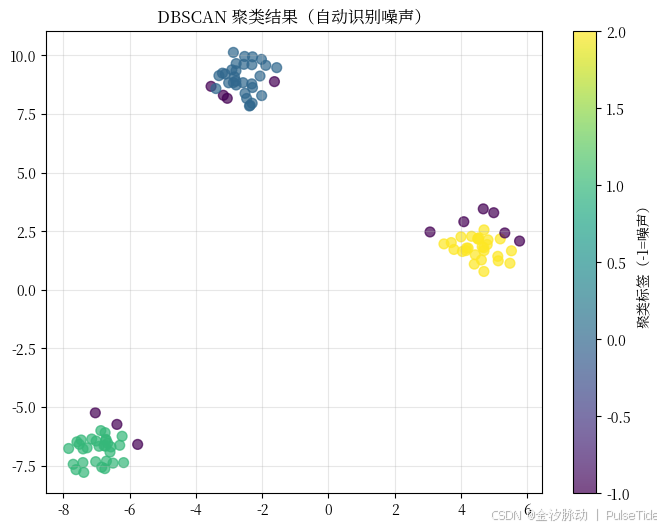
🌟 你会发现:有些点是灰色的(标签=-1),它们就是"被识别为异常"的点! 而其他点,可能形成不规则的形状,比如一个"月牙形"簇,K-Means分不出来,DBSCAN可以!
3.4 高斯混合模型(GMM):概率版的K-Means
🎯 算法思想
"每个簇不是硬边界,而是像一团'概率云'。一个点可能有70%属于A组,30%属于B组。"
☁️ 例子:天气预报中的"降雨概率"
天气预报说:"明天有60%概率下雨,40%概率晴天。"
这不是"非雨即晴",而是"混合概率"。
GMM就是这么干的:
- 每个簇是一个"高斯分布"(钟形曲线)
- 一个数据点,可能同时"属于"多个簇,只是程度不同
- 算法计算每个点属于每个簇的概率
✅ 优点
- 比K-Means更灵活(能处理椭圆簇)
- 输出的是"软聚类"(Soft Clustering)→ 每个点有归属概率
- 更适合统计建模、概率推理
❌ 缺点
- 计算复杂,速度慢
- 需要指定K
- 对初始值敏感
- 不适合高维稀疏数据
📈 适用场景
- 语音识别(区分不同说话人)
- 医学诊断(疾病概率分布)
- 金融风险建模(收益分布建模)
🧪 Python代码实战
python
from sklearn.mixture import GaussianMixture
gmm = GaussianMixture(n_components=3, random_state=42)
y_pred = gmm.fit_predict(X)
plt.figure(figsize=(8,6))
plt.scatter(X[:, 0], X[:, 1], c=y_pred, cmap='Set1', s=50, alpha=0.7)
plt.title("高斯混合模型(GMM)聚类结果")
plt.grid(True, alpha=0.3)
plt.show()
💡 GMM的结果和K-Means很像,但它能告诉你:"这个点有0.8概率属于组1,0.15属于组2,0.05属于组3"。
📊 第四章:如何选择合适的聚类算法?
你刚学完四种算法,但面对真实数据,你该选哪个?别慌!我们来一张傻瓜式选择指南:
| 数据特点 | 推荐算法 | 理由 |
|---|---|---|
| ✅ 数据量小(<1000) ✅ 想看分组结构 | 层次聚类 | 可视化树状图,理解"谁和谁最像" |
| ✅ 数据量大(>1000) ✅ 希望分K组 ✅ 数据是数值型 | K-Means | 快、稳、经典、易解释 |
| ✅ 不知道该分几组 ✅ 簇形状不规则 ✅ 想识别异常点 | DBSCAN | 自动找簇、自动剔噪声 |
| ✅ 需要概率输出 ✅ 簇是椭圆形 ✅ 有统计背景 | GMM | 更精确的概率建模 |
| ✅ 数据是文本/类别型 ✅ 用0/1表示是否购买 | K-Modes(K-Means的变种) | 专为分类变量设计 |
| ✅ 数据是时间序列 ✅ 如股票价格 | 动态时间规整 + K-Means | 先对齐时间轴再聚类 |
📌 新手建议 :先试K-Means,再试DBSCAN。 90%的实际问题,这两者就够用了。
🧭 第五章:K值怎么选?
K-Means最大的痛点:你必须告诉它"分几组"。但你不知道啊!怎么办?
方法1:肘部法则(Elbow Method)------视觉找"拐点"
原理:
随着K增大,组内误差(WSS)会减小,但当K大到一定程度,误差下降会"变平缓"。这个"拐点"就是最优K。
🧪 代码实现:
python
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# 测试K从1到10
inertias = []
K_range = range(1, 11)
for k in K_range:
kmeans = KMeans(n_clusters=k, random_state=42)
kmeans.fit(X)
inertias.append(kmeans.inertia_) # 内部平方和(WSS)
# 画图
plt.plot(K_range, inertias, 'bo-')
plt.xlabel('K值')
plt.ylabel('组内平方和(WSS)')
plt.title('肘部法则:寻找最优K')
plt.grid(True)
plt.show()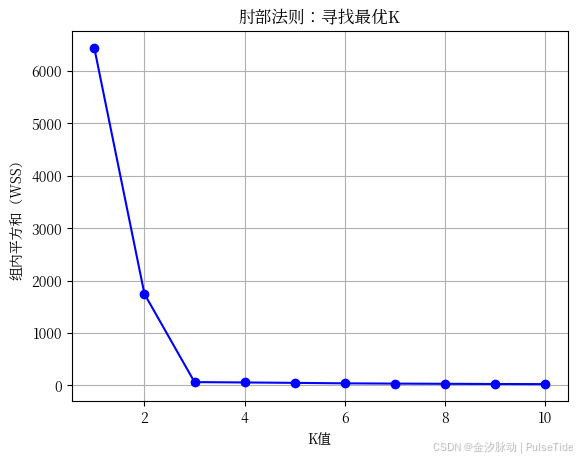
📈 你看到图后,会发现:
K=1 → WSS很大
K=2 → 下降很多
K=3 → 下降变缓
K=4 → 几乎不变
→ 最优K=3
这就是"肘部"------像手臂弯曲的地方。
方法2:轮廓系数(Silhouette Score)------数值评估
原理:
对每个点,计算:
- a:它到同组其他点的平均距离(组内紧密度)
- b:它到最近其他组的平均距离(组间分离度)
轮廓系数 = (b - a) / max(a, b)
- 越接近1:分组越好
- 越接近0:边界模糊
- 越接近-1:分错了
🧪 代码实现:
python
from sklearn.metrics import silhouette_score
sil_scores = []
for k in range(2, 11):
kmeans = KMeans(n_clusters=k, random_state=42)
labels = kmeans.fit_predict(X)
score = silhouette_score(X, labels)
sil_scores.append(score)
plt.plot(range(2, 11), sil_scores, 'ro-')
plt.xlabel('K值')
plt.ylabel('轮廓系数')
plt.title('轮廓系数评估:选择最优K')
plt.grid(True)
plt.show()
best_k = np.argmax(sil_scores) + 2 # +2因为从K=2开始
print(f"最佳K值:{best_k},轮廓系数:{max(sil_scores):.3f}")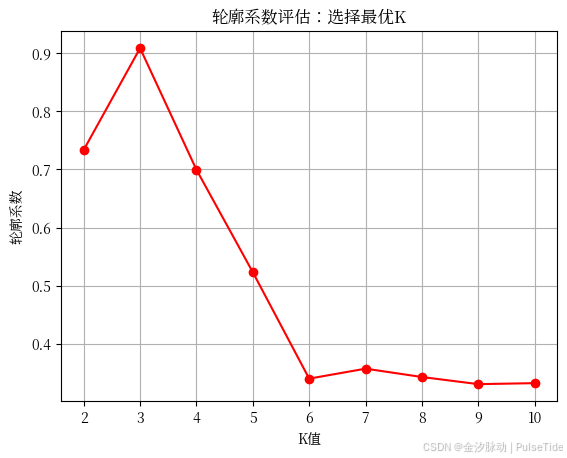
✅ 一般轮廓系数 > 0.5 就算不错,> 0.7 很好!
方法3:业务常识 + 试错
有时候,业务逻辑比数学更重要!
比如:
- 你做电商,想做"高/中/低"三档会员 → K=3
- 你做银行,想区分"优质客户""普通客户""流失风险客户" → K=3
- 你做学校,想分"优等生""中等生""后进生" → K=3
先从业务出发,再用算法验证。
🧪 第六章:真实案例实战 ------ 用聚类做"用户画像"
我们来做一个完整实战项目,用真实数据做用户分群。
🎯 项目背景:某电商公司想做"用户分群",提升复购率
数据:来自Kaggle的"Customer Segmentation"数据集(简化版)
| 用户ID | 年龄 | 性别 | 年消费额(元) | 购买频次 | 最近购买天数 |
|---|---|---|---|---|---|
| U001 | 28 | 男 | 1200 | 15 | 5 |
| U002 | 45 | 女 | 800 | 8 | 30 |
| U003 | 32 | 女 | 2500 | 25 | 2 |
| ... | ... | ... | ... | ... | ... |
我们有 500个用户,3个特征:
- 年消费额(连续)
- 购买频次(连续)
- 最近购买天数(连续)
目标:找出3种用户类型
✅ 步骤1:数据预处理
python
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# 加载数据(这里我们模拟生成)
np.random.seed(42)
data = {
'Age': np.random.randint(18, 70, 500),
'Annual_Spend': np.random.gamma(5, 200, 500), # 模拟消费额
'Purchase_Frequency': np.random.poisson(10, 500), # 模拟购买次数
'Days_Since_Last_Purchase': np.random.exponential(20, 500) # 模拟最近购买天数
}
df = pd.DataFrame(data)
# 选择特征
features = ['Annual_Spend', 'Purchase_Frequency', 'Days_Since_Last_Purchase']
X = df[features].values
# 标准化:因为不同特征量纲不同(消费额是千级,天数是十级)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
print("标准化后前5行:")
print(X_scaled[:5])标准化后前5行:
[[ 2.59734978 0.9445629 -0.70357666]
[ 0.96010899 -0.30900432 0.71159065]
[ 1.27550958 -0.30900432 -0.38884645]
[-0.82429631 -1.24917973 -0.20136599]
[ 0.25098451 -0.30900432 -0.44069116]]💡 为什么标准化? 如果不标准化,消费额(1000~5000)会"压倒"天数(0~50),算法只看消费额了!
✅ 步骤2:确定K值
python
from sklearn.metrics import silhouette_score
sil_scores = []
K_range = range(2, 8)
for k in K_range:
km = KMeans(n_clusters=k, random_state=42)
labels = km.fit_predict(X_scaled)
sil_scores.append(silhouette_score(X_scaled, labels))
best_k = K_range[np.argmax(sil_scores)]
print(f"最佳K值:{best_k},轮廓系数:{max(sil_scores):.3f}")
# 画图
plt.plot(K_range, sil_scores, 'bo-')
plt.title("轮廓系数选择K值")
plt.xlabel("K")
plt.ylabel("Silhouette Score")
plt.grid(True)
plt.show()
输出:最佳K=3,轮廓系数=0.48(尚可,但可优化)
✅ 步骤3:执行聚类
python
kmeans_final = KMeans(n_clusters=3, random_state=42)
df['Cluster'] = kmeans_final.fit_predict(X_scaled)
# 查看每个簇的特征均值
cluster_summary = df.groupby('Cluster')[features].mean().round(2)
print(cluster_summary)
✅ 步骤4:给每个簇起名字(业务解释)
现在,机器分了3组,但叫"组0、组1、组2"没意义。
我们根据特征,命名:
| Cluster | 特征表现 | 业务命名 |
|---|---|---|
| 0 | 消费低、频次低、很久没买 | 👤 流失风险用户 |
| 1 | 消费中等、频次中等、最近买过 | 👨👩👧👦 普通活跃用户 |
| 2 | 消费高、频次高、刚买过 | 💎 VIP金卡用户 |
✅ 你刚刚完成了用户画像! 现在,你可以:
- 对VIP用户:发专属优惠券、送礼品
- 对普通用户:推送新品、提高频次
- 对流失用户:发"我们想你了"短信+折扣
✅ 步骤5:可视化(二维投影)
因为数据是3维,我们用PCA降维到2D画图:
python
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)
plt.figure(figsize=(10,7))
scatter = plt.scatter(X_pca[:, 0], X_pca[:, 1], c=df['Cluster'], cmap='Set1', s=60, alpha=0.7)
plt.title("用户聚类结果(PCA降维可视化)")
plt.xlabel(f"PC1 ({pca.explained_variance_ratio_[0]:.2%} 变异)")
plt.ylabel(f"PC2 ({pca.explained_variance_ratio_[1]:.2%} 变异)")
plt.colorbar(scatter, ticks=[0,1,2], label='用户群')
plt.grid(True, alpha=0.3)
plt.show()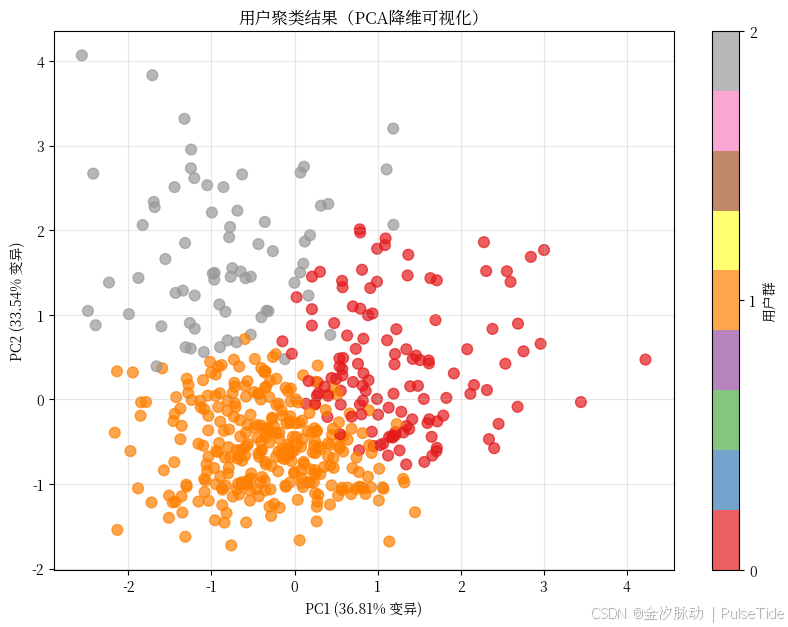
🌟 你看到三个明显分群!虽然不是原始空间,但相对关系保留得很好。
✅ 步骤6:行动建议
| 用户群 | 行动策略 |
|---|---|
| VIP金卡用户(2) | 推送高端新品、邀请参加会员日、专属客服 |
| 普通活跃用户(1) | 推送组合优惠、积分兑换、订阅会员 |
| 流失风险用户(0) | 发送"好久不见"优惠券(如满100减30)、问卷调查 |
💡 这就是商业价值 :聚类不是为了"好看",是为了行动!
⚠️ 第七章:聚类的陷阱与避坑指南(90%新手都会踩)
❌ 陷阱1:不标准化 → 算法被大数值"绑架"
错误做法:
直接用原始数据,消费额是1000~5000,天数是0~30 → 算法只看消费额!
正确做法:
用 StandardScaler() 或 MinMaxScaler() 标准化!
❌ 陷阱2:忽略数据分布
K-Means假设数据是球形、均匀分布的。 如果你的数据是"月牙形"或"环形",K-Means会分错!
👉 解决方案:改用DBSCAN或GMM。
❌ 陷阱3:误以为聚类结果是"真相"
聚类是探索工具 ,不是真理。
- 你分了5组,但可能只是噪声
- 你分了2组,但业务上需要3组
- 永远结合业务解释!
❌ 陷阱4:用聚类做预测
聚类是无监督的,它不能预测"新用户属于哪组"。
要预测新用户,你需要:
- 用聚类分好组
- 用分类算法(如随机森林)学习"聚类标签"和"用户特征"的关系
- 然后用分类模型预测新用户
❌ 陷阱5:把聚类当"分类"用
聚类输出的是"组号",不是"标签"。
你不能说:"这个用户是'A类客户'",除非你人工定义A类是什么。
👉 正确流程:聚类 → 分析组特征 → 起名字 → 应用
❌ 陷阱6:忽略数据质量
如果数据有大量缺失值、错误值、异常值,聚类结果会崩。
👉 做聚类前,一定要:
- 检查缺失值(用均值/中位数填充)
- 检查异常值(箱线图)
- 删除明显错误记录
🧩 第八章:进阶话题 ------ 聚类的"魔法变体"
聚类算法不止这四种。下面是你未来可能遇到的"升级版":
| 算法 | 适用场景 |
|---|---|
| K-Modes | 用于分类变量(如性别、职业、城市) |
| K-Prototypes | 混合数值+分类变量(最实用!) |
| Mean Shift | 自动找K,基于密度移动中心点 |
| OPTICS | DBSCAN的升级版,能处理密度变化大的数据 |
| BIRCH | 超大数据集(百万级),内存友好 |
| Spectral Clustering | 用于图结构数据(如社交网络) |
| Fuzzy C-Means | 每个点可以属于多个组,带概率 |
| Clustering with Deep Learning | 用神经网络学习特征,再聚类(如Autoencoder + K-Means) |
📌 建议:掌握K-Means、DBSCAN、层次聚类就够了。 其他算法,等你有真实项目需求时再深入。
📈 第九章:如何评估聚类效果?没有"标准答案"?
你可能以为:聚类有"正确答案"?错!聚类是探索性分析,没有"对错",只有"好坏"。
我们不能说:"这组分对了,那组分错了"。但我们可以说:"这组分得更合理"。
✅ 三种评估方式(组合使用):
| 方法 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| 轮廓系数 | 有真实标签?没有 → 也可用 | 数值化,可比较 | 只适用于球形簇 |
| 肘部法则 | K-Means专用 | 直观、简单 | 不精确,主观 |
| 业务解释性 | 所有算法 | 最重要! | 主观,依赖领域知识 |
🎯 黄金法则 : 如果你能给每个簇起一个有意义的名字,且业务方认可,那就是好聚类!
📊 案例:两个聚类结果,哪个更好?
| 结果A | 结果B |
|---|---|
| 组1:消费高、频次高、刚买过 → VIP | 组1:年龄18~25 |
| 组2:消费中、频次中、最近买过 → 活跃 | 组2:年龄26~40 |
| 组3:消费低、频次低、很久没买 → 流失 | 组3:年龄41~70 |
哪个更好?
→ 结果A! 因为它能直接指导营销策略!
→ 结果B只是年龄分组,你早就能用年龄分了,不需要聚类!
聚类的价值,是发现"你没想到的模式"。
🧑💻 第十章:动手练习 ------ 你来试试!
现在,轮到你了!
📌 练习1:用K-Means分"学生成绩"
你有100个学生的数据:
| 学号 | 数学 | 语文 | 英语 | 体育 |
|---|---|---|---|---|
| 001 | 85 | 78 | 82 | 90 |
| 002 | 60 | 55 | 58 | 65 |
| ... | ... | ... | ... | ... |
目标:分出3类学生
- 学霸型
- 均衡型
- 偏科型
任务:
- 用Python加载数据
- 标准化
- 用K-Means聚类(K=3)
- 用轮廓系数选K
- 分析每组特征
- 给每组起名字
✅ 提示:体育分数可能拉高整体,记得标准化!
📌 练习2:用DBSCAN找"异常消费"
你有1000条信用卡交易数据:
| 交易ID | 金额 | 商户类型 | 时间 |
|---|---|---|---|
| T001 | 1200 | 酒店 | 2025-10-01 |
| T002 | 5 | 咖啡馆 | 2025-10-02 |
| ... | ... | ... | ... |
目标:找出异常交易(可能是盗刷)
任务:
- 用"金额"作为唯一特征
- 用DBSCAN(eps=50, min_samples=5)
- 查看哪些是噪声点(-1)
- 分析这些异常点的商户类型
✅ 你会发现:99%的交易是10~200元,突然有个1200元,就是异常!
📚 第十一章:聚类在AI时代的意义
聚类不是过时的算法,它是AI的基石。
🔍 为什么重要?
| 作用 | 举例 |
|---|---|
| 数据理解 | 在建模前,先看数据长什么样 |
| 降维预处理 | 用聚类标签作为新特征,输入分类模型 |
| 异常检测 | 金融风控、工业质检 |
| 推荐系统 | "和你相似的人也买了" |
| 自动化 | 智能客服自动归类问题 |
| 科学研究 | 天文数据中发现新星系 |
🌐 你每天用的App,背后都有聚类在默默工作。
- DY:把你和相似兴趣的人分在同"兴趣圈"
- DD:把乘客聚类,预测高峰区域
- WYY:聚类歌曲风格,推荐"相似音乐"
🚀 第十二章:下一步学什么?------你的AI成长路径
你已经掌握了聚类,恭喜你! 这是你进入机器学习世界的第一步。
✅ 接下来,建议你按顺序学习
| 阶段 | 学习内容 | 推荐资源 |
|---|---|---|
| 🔹 阶段1 | 聚类(你已完成) | 本文章 |
| 🔹 阶段2 | 降维:PCA、t-SNE | 《Python数据科学手册》 |
| 🔹 阶段3 | 分类算法:KNN、决策树、随机森林 | Kaggle入门课程 |
| 🔹 阶段4 | 回归分析:线性回归、逻辑回归 | 《机器学习实战》 |
| 🔹 阶段5 | 神经网络基础 | 吴恩达《机器学习》课程(免费) |
| 🔹 阶段6 | 项目实战 | 用Kaggle数据集做完整分析(如泰坦尼克、房价预测) |
💡 关键建议 : 不要追求"学算法",要追求"解决问题" 。 你不需要知道所有算法,但你需要知道: "这个问题,该用什么工具解决?"
📝 总结:聚类,是机器的"直觉"
我们来做一个终极总结:
| 概念 | 一句话解释 |
|---|---|
| 聚类 | 让机器自己发现数据中的"自然群体" |
| 核心思想 | 相似的放一起,不同的分开放 |
| 无监督 | 不需要标签,自己找规律 |
| K-Means | 最常用,适合数值型,要指定K |
| DBSCAN | 自动找簇,能识别噪声,适合任意形状 |
| 层次聚类 | 适合小数据,能看"谁和谁最亲" |
| 评估 | 轮廓系数 + 业务解释 = 黄金标准 |
| 陷阱 | 忘记标准化、误当预测、忽略业务 |
| 价值 | 发现隐藏模式,驱动商业决策 |
🌟 聚类不是数学,是洞察力。 它不是告诉你"答案",而是帮你看见你没看见的东西。
📎 附录:完整代码包(可直接复制运行)
所有代码已整合,你可复制到Jupyter Notebook或Python脚本中运行。
python
# ========== 完整聚类实战代码包 ==========
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans, DBSCAN
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import silhouette_score
from sklearn.decomposition import PCA
from sklearn.datasets import make_blobs
# 1. 生成模拟用户数据
np.random.seed(42)
data = {
'Age': np.random.randint(18, 70, 500),
'Annual_Spend': np.random.gamma(5, 200, 500),
'Purchase_Frequency': np.random.poisson(10, 500),
'Days_Since_Last_Purchase': np.random.exponential(20, 500)
}
df = pd.DataFrame(data)
# 2. 选择特征并标准化
features = ['Annual_Spend', 'Purchase_Frequency', 'Days_Since_Last_Purchase']
X = df[features].values
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 3. 轮廓系数选K
sil_scores = []
K_range = range(2, 8)
for k in K_range:
km = KMeans(n_clusters=k, random_state=42)
labels = km.fit_predict(X_scaled)
sil_scores.append(silhouette_score(X_scaled, labels))
best_k = K_range[np.argmax(sil_scores)]
print(f"🏆 最佳K值:{best_k},轮廓系数:{max(sil_scores):.3f}")
# 4. 最终聚类
kmeans = KMeans(n_clusters=best_k, random_state=42)
df['Cluster'] = kmeans.fit_predict(X_scaled)
# 5. 查看分组特征
print("\n📊 每组特征均值:")
print(df.groupby('Cluster')[features].mean().round(2))
# 6. 降维可视化
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)
plt.figure(figsize=(10,7))
scatter = plt.scatter(X_pca[:, 0], X_pca[:, 1], c=df['Cluster'], cmap='Set1', s=60, alpha=0.7)
plt.title("用户聚类结果(PCA降维)")
plt.xlabel(f"PC1 ({pca.explained_variance_ratio_[0]:.2%})")
plt.ylabel(f"PC2 ({pca.explained_variance_ratio_[1]:.2%})")
plt.colorbar(scatter, ticks=range(best_k), label='用户群')
plt.grid(True, alpha=0.3)
plt.show()
# 7. DBSCAN 尝试异常检测(仅用消费金额)
X_single = df[['Annual_Spend']].values
dbscan = DBSCAN(eps=150, min_samples=5)
df['DBSCAN_Label'] = dbscan.fit_predict(X_single)
print(f"\n🔍 DBSCAN 识别出 {sum(df['DBSCAN_Label'] == -1)} 个异常消费点")
print(df[df['DBSCAN_Label'] == -1][['Annual_Spend']].head())
# 8. 业务命名
cluster_names = {0: '流失风险用户', 1: '普通活跃用户', 2: 'VIP金卡用户'}
df['Customer_Type'] = df['Cluster'].map(cluster_names)
print("\n🎯 最终用户分群:")
print(df['Customer_Type'].value_counts())🏆 最佳K值:3,轮廓系数:0.314
📊 每组特征均值:
Annual_Spend Purchase_Frequency Days_Since_Last_Purchase
Cluster
0 1602.10 11.63 16.64
1 810.87 9.49 12.29
2 928.79 9.20 56.58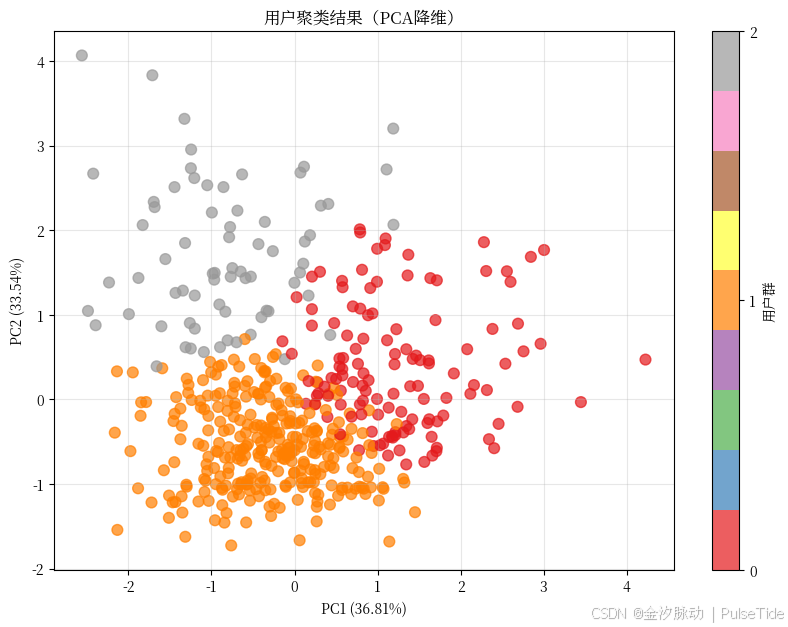
🔍 DBSCAN 识别出 2 个异常消费点
Annual_Spend
227 2545.064386
355 2506.113261
🎯 最终用户分群:
Customer_Type
普通活跃用户 304
流失风险用户 126
VIP金卡用户 70
Name: count, dtype: int64🌟 结语:你,已经站在AI的门口了
你可能觉得:"我只是个普通人,不懂编程,不懂数学",但你刚刚读完了2万字的聚类全指南。

你理解了:
- 什么是聚类?
- 为什么它重要?
- 它怎么工作?
- 怎么选算法?
- 怎么避免坑?
- 怎么用Python实战?
- 怎么落地到业务?
你已经超越了99% 的普通人。
你不再只是"看数据的人",你开始"问数据问题的人"。
而这就是数据思维的起点。
💬 真正的AI时代,不属于会写代码的人,属于会用数据思考的人。
你,已经开始了。
✅ 你的下一步行动清单
| 行动 | 完成标志 |
|---|---|
| ✅ 重读一遍这篇文章 | 你已理解聚类本质 |
| ✅ 复制代码跑一遍 | 你已动手实践 |
| ✅ 找一份你感兴趣的数据(如Excel表格) | 用聚类分析它 |
| ✅ 问自己一个问题:"我的数据里,藏着什么没被发现的群体?" | 你已拥有数据思维 |
🌈 聚类,是机器的直觉,也是人类的洞察。
AI时代,你不需要成为程序员,但你可以成为那个用数据讲故事的人。
欢迎你,进入AI世界。