大型语言模型(LLMs)的能力在很大程度上受限于其能够同时处理的上下文窗口(Context Window)长度。传统的 Transformer 模型通常只能处理 4K 到 8K 的 Token 序列,这使其在处理长篇文档、法律合同或完整技术报告时显得力不从心。近年来,研究者通过引入位置编码外推、稀疏注意力、以及KV缓存压缩等一系列上下文窗口扩展技术,成功将 LLMs 的处理长度推至数万甚至十万 Token 级别。本文将深入解析这些技术背后的原理,阐述它们如何帮助模型理解复杂长文本,并探讨其在专业领域中的关键应用价值。
1. 传统模型的"短时记忆"困境
在深入了解扩展技术之前,我们必须理解标准 Transformer 架构在处理长文本时的两个核心障碍:
1.1 注意力机制的二次复杂度挑战
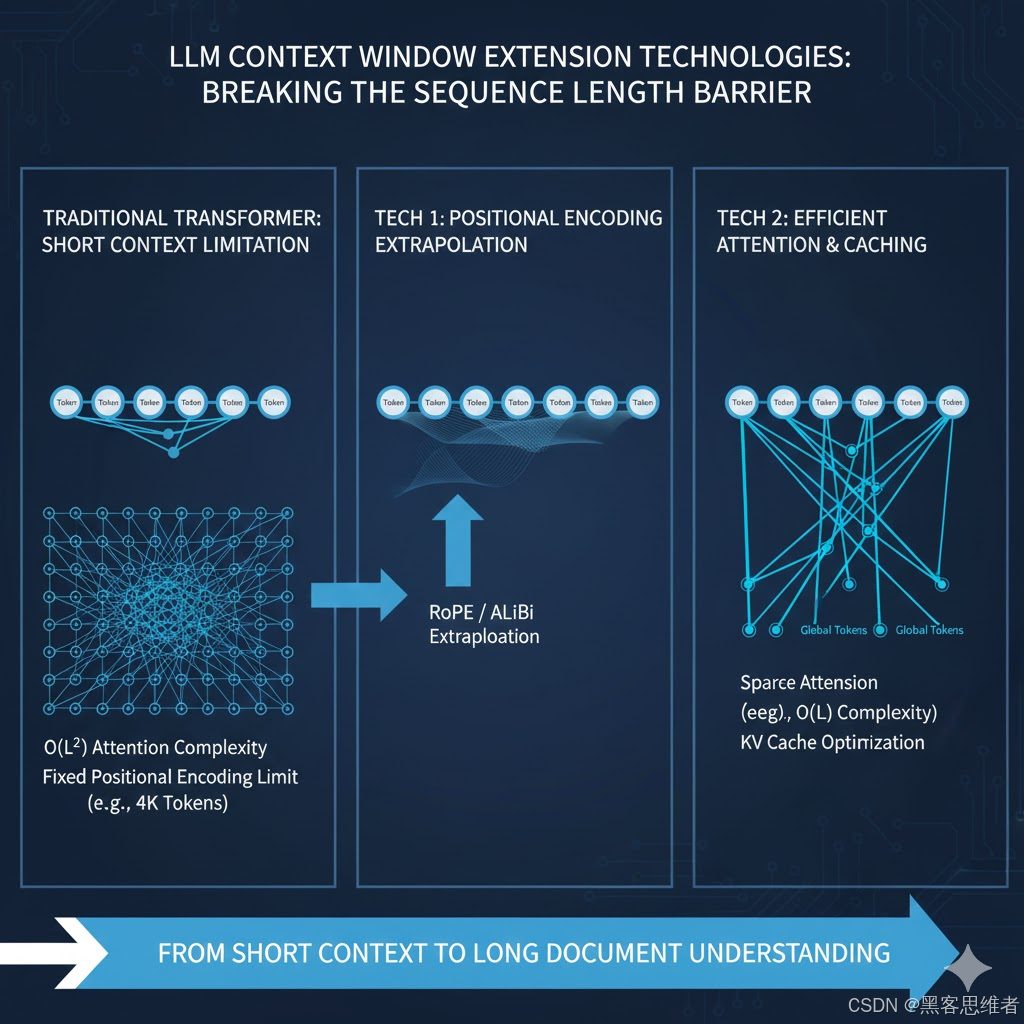
标准的自注意力机制(Self-Attention)需要计算序列中每对 Token 之间的关系 。如果序列长度为 LLL,计算复杂度为 O(L2)O(L^2)O(L2)。当 LLL 达到数万时,计算成本(时间和内存)将呈几何级数增长,使其在现有硬件上无法负担。
1.2 位置编码的长度限制
Transformer 使用位置编码(Positional Encoding)来赋予 Token 序列中的位置信息。然而,大多数经典位置编码方法(如 Sinusoidal 或 Rotary PE, RoPE)是在固定长度的序列上训练的。当输入序列长度远超训练时的最大长度时,位置编码就会失效,导致模型出现"注意力失焦",无法准确判断 Token 的相对和绝对位置。
2. 核心技术一:位置编码外推(Extrapolation)
解决长文本问题的首要任务是让模型知道它正在处理一个比训练时更长的序列,并能准确识别新位置。
2.1 ALiBi 与 RoPE 外推
传统的固定位置编码在超出训练长度后,往往表现出极差的泛化性。新的方法,例如 ALiBi (Attention with Linear Biases) 或对 RoPE (Rotary Positional Embedding) 进行的外推改进,解决了这一问题。
- RoPE 外推机制: 研究人员发现,通过简单的数学技巧(如插值或调整频率),可以使 RoPE 具备一定的外推能力。当输入长度增加时,模型能够基于训练期间学到的位置关系线性地预测新位置的编码,从而保持注意力的有效性。
2.2 价值体现:理解相对位置
通过外推技术,模型不再受限于固定长度,它能在 10 万 Token 的文档中,依然准确地判断"第 5000 个 Token"与"第 95000 个 Token"之间的相对距离和关系。这为后续所有的高级理解奠定了基础。
3. 核心技术二:降低计算复杂度(稀疏注意力)
解决了位置编码问题后,我们必须解决 O(L2)O(L^2)O(L2) 的计算瓶颈。
3.1 稀疏注意力(Sparse Attention)
稀疏注意力策略放弃了计算所有 Token 对之间的注意力,只计算那些被认为最关键的连接。
- 案例:Longformer 的滑动窗口: Longformer 模型引入了滑动窗口注意力(Sliding Window Attention),即每个 Token 只关注其前后固定大小窗口内的 Token。同时,它保留了少数 Token(通常是关键的分类 Token)拥有**全局注意力(Global Attention)**的能力,可以关注序列中的任意 Token。
- 效果: 计算复杂度从 O(L2)O(L^2)O(L2) 有效降至 O(L)O(L)O(L) 或接近 O(L)O(L)O(L),显著减少了计算和内存需求,使得处理数万 Token 成为可能。
3.2 压缩表示(如 KV 缓存优化)
在生成任务中,模型的**键(Key)和值(Value)**矩阵(即 KV 缓存)会随着生成 Token 的增加而不断增长,占据大量的 GPU 显存。
- KV 缓存压缩: 通过量化(Quantization)或舍弃最旧的 KV 对等方法,模型可以在不显著牺牲生成质量的前提下,大幅减少 KV 缓存的内存占用。这使得在推理阶段能够维持更长的上下文,避免因内存溢出而中断生成。
4. 突破传统限制:专业领域的关键应用
上下文窗口扩展技术带来的"长时记忆"能力,彻底改变了 LLMs 在专业领域的应用潜力。
4.1 法律文书分析与合同审查
- 挑战: 一份复杂的法律合同或专利文档通常包含数万词,细节分散在不同条款中,传统模型必须依赖手动分块阅读,容易丢失全局联系。
- 扩展后的优势: 模型能够一次性摄入完整的合同文本,实现跨章节的依赖关系推理。例如,模型可以同时看到"定义条款"、"赔偿条款"和"终止条款",准确识别不同条款之间潜在的冲突或漏洞。
4.2 技术文档与学术研究
- 挑战: 阅读一份包含附录、图表和交叉引用的长篇技术报告。
- 扩展后的优势: 研究人员可以将一份完整的实验报告(包括方法论、实验数据和讨论)输入模型,要求模型生成总结、找出实验缺陷或与其它报告进行对比。这极大地提高了知识获取和研究效率。
总结
上下文窗口扩展技术是推动 LLMs 从"对话助手"迈向"专业知识处理器"的关键一步。通过解决位置编码外推和二次复杂度两大核心难题,模型获得了处理长达数十万 Token 文本的能力。这种能力的突破,不仅提升了模型的鲁棒性和理解深度,更是在金融、法律、科学研究等对文本长度和精度要求极高的领域,开启了全新的应用可能性。