想象一下:某一天,你家的机器人正待在客厅角落,突然听见孩子跟妈妈说"我渴了",妈妈回"冰箱里有橙汁和可乐",接着就传来孩子拖长音的"呃,橙汁......"------那语气里的抗拒,简直快从声音里溢出来了。这时候机器人要是愣着等指令,也太"不解风情"了吧?
但有了RoboOmni这个新框架就不一样了!它能像家里最懂你的长辈似的,听出孩子不爱喝酸橙汁,还会主动凑上去问:"那要不要给你拿罐可乐呀?"
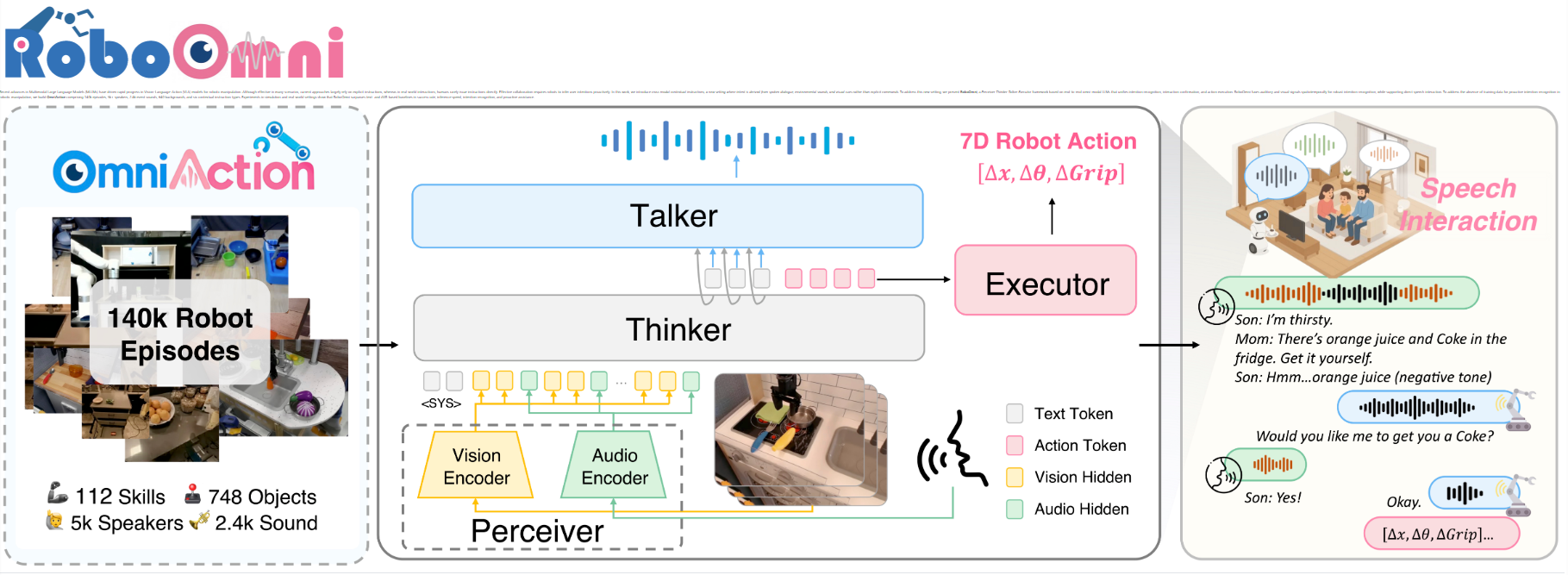
别以为这是编出来的温馨小剧场,这可是邱锡鹏研究团队,在论文里实实在在做的场景设计。简单说,以前的机器人得等你把指令说清清楚楚才干活,现在有了RoboOmni,它能"听语气、看反应",甚至捕捉家里的环境声音,主动猜你需要啥------就像突然拥有了"察言观色"的超能力,从"被动等命令"的工具人,变成了会主动搭把手的"贴心管家"~

目前该论文正在ICLR 2026 Under review中。
1. 【导读】

论文标题:ROBOOMNI: PROACTIVE ROBOT MANIPULATION IN OMNI-MODAL CONTEXT
作者:邱锡鹏团队
作者机构:复旦大学、上海创智学院及新加坡国立大学研究团队
论文来源:Under review as a conference paper at ICLR 2026
论文链接:https://openreview.net/pdf?id=OJh7oBCYhL
项目链接:https://anonymous.4open.science/r/openvla-357B
2. 【论文速读】
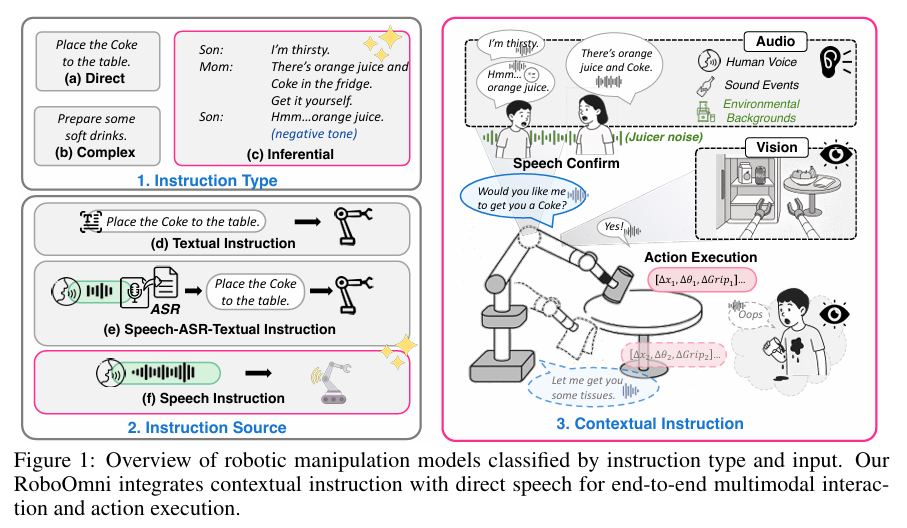
近年来,多模态大型语言模型(MLLMs) 的发展推动了机器人操作领域中视觉-语言-动作(VLA)模型 的快速进步,但现有方法多依赖明确指令,而现实场景中人类极少直接下达指令,有效协作需机器人主动推断用户意图。为此,研究团队提出跨模态上下文指令 这一新场景,即意图源于语音对话、环境声音和视觉线索而非明确命令,并针对性地提出RoboOmni框架 ------该框架基于端到端全模态LLMs,采用"感知器-思考器-对话器-执行器"结构,统一意图识别、交互确认与动作执行,能时空融合听觉和视觉信号实现鲁棒的意图识别,并支持直接语音交互。为解决机器人主动意图识别训练数据缺失问题,团队构建OmniAction数据集(含14万段场景、5000余名说话者、2400种事件声音、640种背景及6类上下文指令类型)。仿真与真实场景实验表明,RoboOmni在成功率、推理速度、意图识别及主动协助方面均优于基于文本和语音识别(ASR)的基线模型,且所有数据集、代码及真实场景演示视频将公开。
3. 机器人"学察言观色"的素材库:OmniAction数据集构建
3.1 核心定位:填补主动意图识别数据缺口
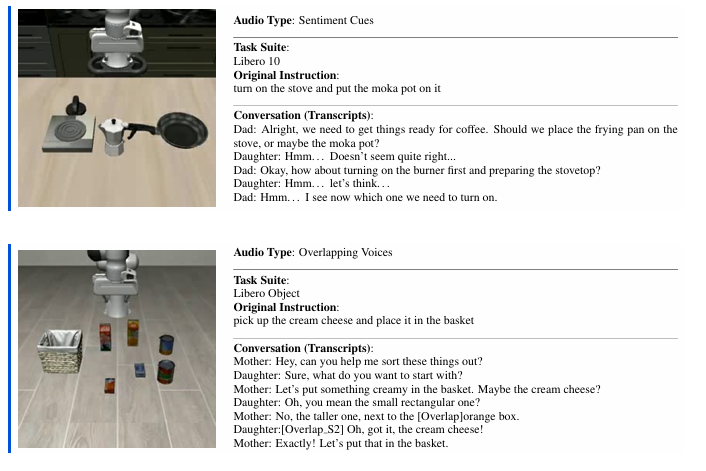
针对现有数据集缺乏多模态(尤其音频)与推断式指令的问题,构建OmniAction大规模语料库,将隐藏意图与语音、环境音、视觉绑定,覆盖6类上下文指令(情感/重叠语音/非语言线索等)和3类非语音声音,支撑机器人主动识意。
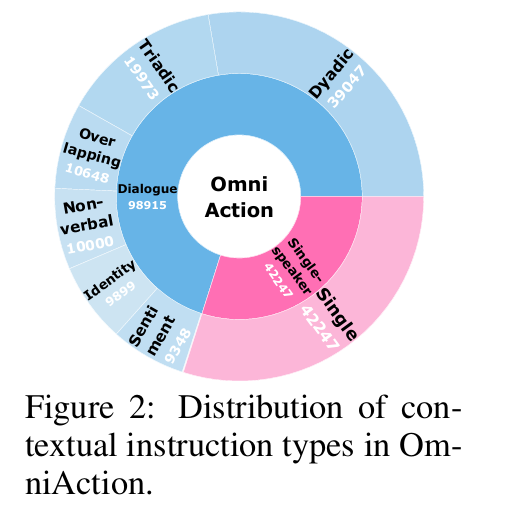
3.2 核心构成:还原真实场景的丰富细节
- 指令与声音:6类上下文指令(如双人/三人对话)、5096种说话人音色、2482种事件音(雷声等)、640种环境音(流水声等)。
- 数据规模 :14.1万+多模态场景,含112种技能、748种物体;单样本以"对话+视觉+动作轨迹"三元组呈现。
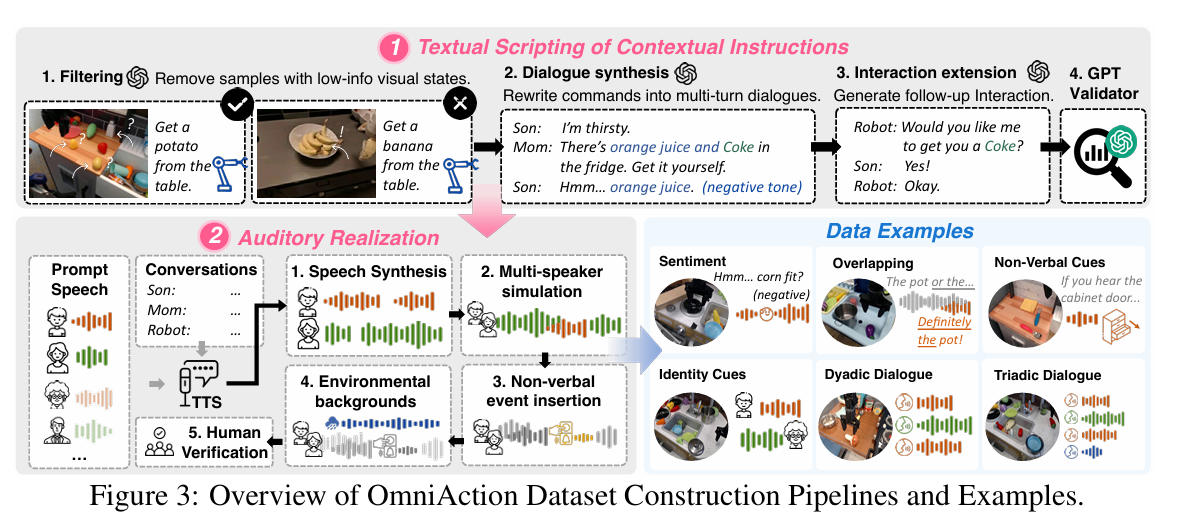
3.3 三步构建:从文本到可用数据
- 文本脚本:从Open-X选任务,用GPT-4o将指令转成家庭对话,过滤低质样本、补人机交互内容并验证意图。
- 听觉实现:多TTS引擎合成语音,模拟多说话者重叠,插入事件音与环境音。
- 人工验证:抽样评估确保意图可还原,一致性达98.7%。
3.4 仿真配套:OmniAction-LIBERO
- TTS版:给LIBERO的40个任务各生成6类指令变种,共240个评估任务。
- Real版 :10名志愿者录制真实环境语音,测试模型真实语音适配性。
4. 机器人"思考-行动"指南:RoboOmni的全模态方法论
RoboOmni采用"感知器-思考器-对话器-执行器"(Perceiver-Thinker-Talker-Executor)架构,是基于端到端全模态LLM的机器人操作框架,能将语音、环境音、视觉与机器人动作统一到单一自回归模型中,通过统一 token 化将所有模态编码到共享语义空间,实现"感知到动作"的无缝生成。
4.1 核心架构组件:四大模块各司其职
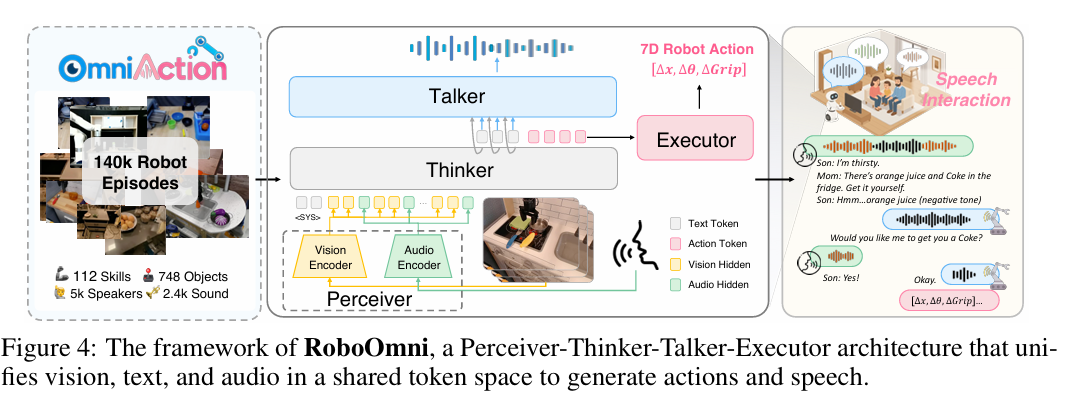
4.1.1 感知器(Perceiver):多模态输入编码
负责将异质输入模态编码到统一嵌入空间,遵循Qwen2.5-Omni的多模态处理流程,对文本、音频、视觉输入进行编码,得到隐藏表示。
在时刻ttt,给定视觉观测ItI_{t}It和音频片段xtx_{t}xt,通过视觉编码器得到视觉嵌入vt=fv(It)v_{t}=f_{v}(I_{t})vt=fv(It),通过音频编码器得到音频嵌入st=fs(xt)s_{t}=f_{s}(x_{t})st=fs(xt);再结合文本上下文ctc_{t}ct,共同构成统一输入表示,作为"思考器"的输入。
4.1.2 思考器(Thinker):全模态推理核心
作为中心推理引擎,基于LLM骨干网络构建,处理来自"感知器"的统一多模态表示,在联合词汇空间ν∪A\nu \cup Aν∪A(ν\nuν为文本词汇,AAA为动作token集)中生成符合上下文的输出。
采用自回归方式生成序列,无缝交错文本token、语音表示与动作token,实现感知、语言、机器人控制的统一推理。
4.1.3 对话器(Talker):语音生成交互
通过分层架构设计,让系统生成自然语音响应。接收来自"思考器"的高层语义表示与文本token,将其转换为语音波形,支持机器人场景下的无缝语音交互。
4.1.4 执行器(Executor):动作生成与解码
为实现机器人控制与语言模型框架的无缝集成,扩展"思考器"的词汇表,引入FAST+ tokenizer定义的2048个离散动作token集AAA。
不同于将每个动作维度映射到单独token,FAST+用短序列离散符号rt⊂Ar_{t} \subset Art⊂A表示连续动作向量at∈R7a_{t} \in \mathbb{R}^{7}at∈R7(如7自由度控制),使模型能从联合空间V∪AV \cup AV∪A自回归生成,无缝衔接语言理解与机器人控制;最终"执行器"将这些动作token解码为可执行的机器人指令。
4.2 双模式生成:对话与动作的自回归生成
4.2.1 文本与语音生成
用于对话响应,"思考器"以自回归方式生成文本token序列y1:L=(y1,y2,...,yL)y_{1: L}=(y_{1}, y_{2}, ..., y_{L})y1:L=(y1,y2,...,yL),生成概率公式为:
pθ(y1:L∣Xt)=∏ℓ=1Lpθ(yℓ∣Xt,y<ℓ)p_{\theta}(y_{1: L} | X_{t})=\prod_{\ell=1}^{L} p_{\theta}(y_{\ell} | X_{t}, y_{<\ell})pθ(y1:L∣Xt)=∏ℓ=1Lpθ(yℓ∣Xt,y<ℓ)
生成的文本可通过"对话器"模块转换为语音,该模块接收来自"思考器"的离散文本token与高层语义表示,完成语音波形生成。
4.2.2 动作生成
用于机器人控制,"思考器"自回归预测长度为NNN的离散动作token序列rt:t+Nr_{t: t+N}rt:t+N,再通过逆变换解码为连续动作at:t+Na_{t: t+N}at:t+N,概率公式与动作解码关系为:
at:t+N=Executor(rt:t+N),pθ(rt:t+N∣Xt)=∏i=0Npθ(rt+i∣Xt,rt:t+i−1)a_{t: t+N}=Executor(r_{t: t+N}), p_{\theta}(r_{t: t+N} | X_{t})=\prod_{i=0}^{N} p_{\theta}(r_{t+i} | X_{t}, r_{t: t+i-1})at:t+N=Executor(rt:t+N),pθ(rt:t+N∣Xt)=∏i=0Npθ(rt+i∣Xt,rt:t+i−1)
4.3 训练范式:统一自回归目标
采用统一自回归目标函数,在同一框架内同时训练对话与操作能力。给定训练场景,模型接收多模态输入xtx_{t}xt,学习生成合适响应(对话场景生成对话回复,操作场景生成动作序列);训练仅更新"思考器","对话器"保持冻结以保留语音合成能力。
4.3.1 对话任务损失(Lchat\mathcal{L}_{chat}Lchat)
优化在多模态上下文下生成合适文本响应y1:Ly_{1: L}y1:L的可能性,公式为:
Lchat(θ)=−E∑ℓ=1Llogpθ(yℓ∣Xt,y<ℓ)\mathcal{L}{chat }(\theta)=-\mathbb{E} \sum{\ell=1}^{L} \log p_{\theta}(y_{\ell} | X_{t}, y_{<\ell})Lchat(θ)=−E∑ℓ=1Llogpθ(yℓ∣Xt,y<ℓ)
4.3.2 动作生成损失(Lact\mathcal{L}_{act}Lact)
学习生成与专家轨迹对应的动作token序列rt:t+Nr_{t: t+N}rt:t+N,公式为:
Lact(θ)=−E∑i=0Nlogpθ(rt+i∣Xt,rt:t+i−1)\mathcal{L}{act }(\theta)=-\mathbb{E} \sum{i=0}^{N} \log p_{\theta}(r_{t+i} | X_{t}, r_{t: t+i-1})Lact(θ)=−E∑i=0Nlogpθ(rt+i∣Xt,rt:t+i−1)
4.3.3 总训练目标
通过批次交错融合两种模态的损失,总目标公式为:
L(θ)=Lchat(θ)+Lact(θ)=−E∑k=1Klogpθ(zk∣Xt,z<k)\mathcal{L}(\theta)=\mathcal{L}{chat }(\theta)+\mathcal{L}{act }(\theta)=-\mathbb{E} \sum_{k=1}^{K} \log p_{\theta}(z_{k} | X_{t}, z_{<k})L(θ)=Lchat(θ)+Lact(θ)=−E∑k=1Klogpθ(zk∣Xt,z<k)
其中zk∈V∪Az_{k} \in \mathcal{V} \cup \mathcal{A}zk∈V∪A,表明对话与动作监督最终都归结为在统一token空间上的自回归最大似然目标。
5. 机器人"考试"成绩单:RoboOmni的实验表现
5.1 实验准备:基准模型与参数设置
5.1.1 基准模型选择
针对现有VLA模型多依赖文本输入的局限,设置两类基准范式:
- 「真值文本提示」:将语音指令的预标注转录文本直接输入VLA模型;
- 「语音-ASR-文本提示」:用Whisper large-v3模型将语音转文本后输入VLA模型。
对比4个代表性VLA基准模型:OpenVLA、OpenVLA-OFT、π0\pi_{0}π0、NORA。
5.1.2 核心参数
- 输入规格:图像分辨率224×224、音频采样率16,000 Hz、动作块大小6;
- 训练配置:大规模预训练用64张A100 GPU训练10天(共15,360 A100小时),批次大小512,学习率5×10−55×10^{-5}5×10−5(前1k步热身);下游微调用8张A100 GPU训练10-30k步,学习率5×10−55×10^{-5}5×10−5。
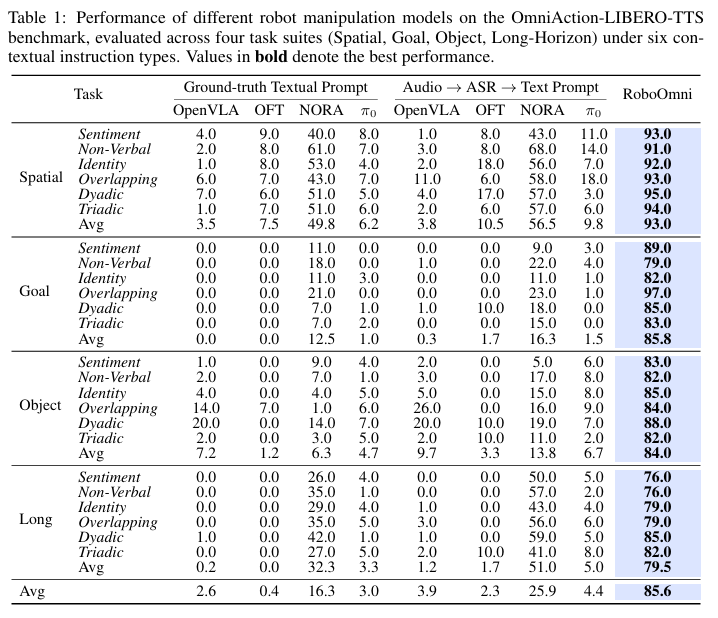
5.2 跨模态上下文指令测试:模拟场景夺冠
在OmniAction-LIBERO数据集(4类任务套件+6类音频变体)上,RoboOmni整体成功率达85.6%,大幅超越最强基准NORA(25.9%)及其他级联方法(均低于10%),关键发现包括:
- 端到端听觉融合是关键:文本类模型(含ASR转写)无法捕捉语调、重叠语音等副语言线索,最优成绩仅25.9%,而RoboOmni所有指令类型成功率均超76%;
- 语义模糊场景仍稳健:目标(Goal)和物体(Object)任务因可选物体/动作多,基准模型平均成功率仅16.3%、13.8%,RoboOmni仍保持85.8%、84.0%的高表现;
- 指令难度影响认知需求:双人对话、重叠语音任务较易(平均88%),非语言指令最难(82%,需结合多模态线索),其余任务平均~85%。
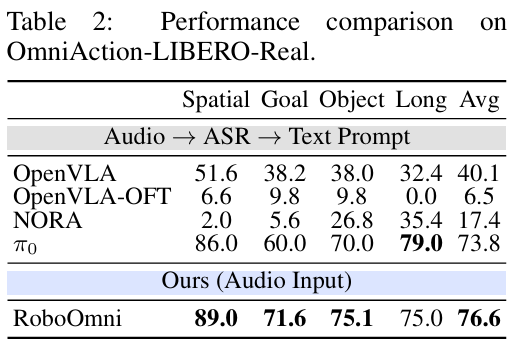
5.3 真实人类语音测试:抗干扰能力更强
在OmniAction-LIBERO-Real基准(10名志愿者真实环境录制语音)中,RoboOmni平均成功率76.6% ,超越文本类VLA模型:π0\pi_{0}π0(73.8%)、OpenVLA(40.1%)、NORA(17.4%)。
优势原因:ASR类模型易受口音、背景噪音影响,微小转写误差会大幅降低性能;而RoboOmni直接处理语音,且经多样本预训练,对声学变化和副语言线索的鲁棒性更强。
5.4 真实机器人实验:落地能力验证
在WidowX 250S机械臂上微调预训练模型(用10名志愿者真实语音演示数据),RoboOmni展现三大核心能力:
- 精准意图识别:结合视觉(如识别容器为锅)和听觉线索(如对话偏好)推断意图;
- 自然交互确认:推断潜在意图后主动提问(如"需要我XXX吗?"),获确认后执行;
- 可靠动作执行:成功完成确认后的操作任务,无偏差执行。

5.5 主动协助能力评估:意图识别与交互双优
5.5.1 意图识别准确率
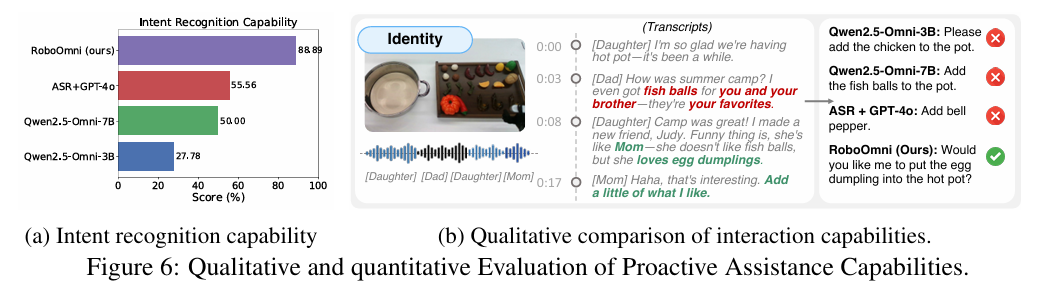
RoboOmni意图识别准确率达88.9%,显著高于Qwen2.5-Omni-3B(27.8%)、Qwen2.5-Omni-7B(50.0%)及ASR+GPT-4o(55.6%),印证端到端语音-动作建模对保留上下文和副语言线索的优势。
5.5.2 交互能力表现
RoboOmni在模糊指令(如"蛋饺"未明确指令)时主动澄清、融合多模态信号(如门铃+对话)、保持协作式对话(用"需要我XXX吗?"尊重人类主导权),而基准模型常盲目执行或忽略关键线索。
5.6 进一步分析:效率与架构优势
5.6.1 OmniAction预训练提升效率
预训练+微调模型在空间(Spatial)任务上,2k步内准确率近90%;从零训练模型20k步仅达~30%,30k步还出现性能下降,说明OmniAction提供的通用先验可加速适配。

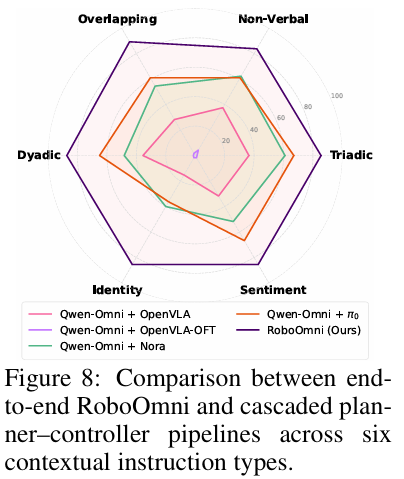
5.6.2 端到端架构优于级联管道
对比"Qwen2.5-Omni-3B(规划器)+文本VLA(控制器)"的级联管道,RoboOmni全场景表现更优:级联管道因规划器与控制器未协同训练,易出现语义偏移(生成不可执行指令),且无法捕捉副语言线索,在身份(Identity)指令上表现最差。
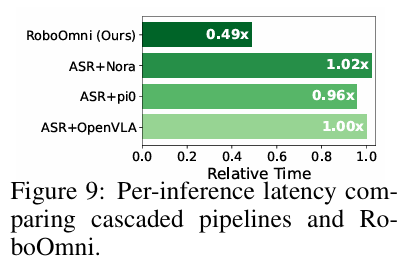
5.6.3 推理速度更快
在单RTX 4090 GPU上,以ASR+OpenVLA为基准(1.0×),RoboOmni推理延迟仅0.49× ,级联管道(ASR+NORA:1.02×、ASR+π0\pi_{0}π0:0.96×)因ASR占主导计算,效率无优势;RoboOmni省去ASR环节,大幅提升运行效率。
6. 机器人"进化"小结与未来蓝图
6.1 总结
研究提出"跨模态上下文指令"新范式,让机器人从语音、环境音、视觉多模态中主动推断用户意图,而非等待明确指令;并针对性设计RoboOmni框架,以"感知器-思考器-对话器-执行器"结构实现端到端全模态融合,统一意图识别、交互确认与动作执行。同时构建OmniAction大规模数据集(14万段场景、5000+说话者等)解决数据稀缺问题,仿真与真实实验均证明,RoboOmni在成功率、推理速度、主动协助等方面显著优于文本及ASR类基准模型。
6.2 展望
未来可进一步拓展场景复杂度,如多机器人协作、动态环境适应;还可深化认知能力,如结合用户长期偏好、复杂任务规划;此外,需持续优化隐私保护方案,在提升机器人交互自然度的同时,确保用户语音、对话等数据的安全合规,推动技术更广泛落地于家庭、医疗等真实场景。