近日,由Yann LeCun、李飞飞、Rob Fergus等AI领域顶级学者共同署名的论文《Cambrian-S: Towards Spatial Supersensing in Video》首次系统性地提出了"空间超感知"的概念,并指出:空间智能是AI实现真正多模态理解与通用智能的关键路径。无独有偶,李飞飞随后发表长文《从文字到世界:空间智能是AI的下一个前沿》,进一步阐述了空间智能的核心价值与世界模型的构建蓝图。本文将从论文出发,结合李飞飞的深度思考,带你深入理解这一AI新范式。
论文解读:从"语言理解"到"空间超感知"
- 反思现状:为什么说LLM是"空间盲人"?
三位作者指出,当前基于LLM的多模态系统存在根本性局限。LeCun多次公开表示,LLM技术无法通向AGI。谢赛宁在团队博客中坦言:在构建「超感知」之前,不可能真正构建出「超级智能」。
问题的核心在于:LLM虽然能处理文本和图像,却缺乏对3D空间的直觉理解。它们像是通过"钥匙孔"看世界------只能看到碎片化的2D画面,无法在脑海中构建连贯的3D场景。
这种缺陷暴露了莫拉维克悖论在AI领域的再现:对人类来说轻而易举的空间感知,对AI却难如登天。
- 什么是"空间超感知"?
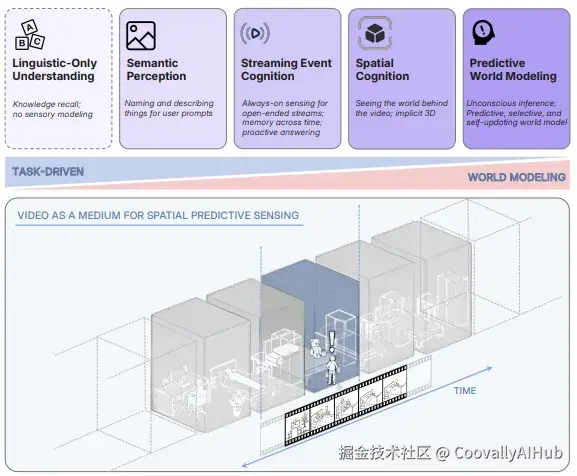
论文指出,当前的多模态大模型仍以语言为中心,缺乏对3D空间结构与动态的深层理解。为此,作者提出"空间超感知"的四个发展阶段:
- 语义感知: 识别物体、属性与关系
- 流事件认知: 处理连续、无界的视觉流
- 隐式3D空间认知: 理解视频背后的3D世界结构
- 预测性世界建模: 构建内部模型,预测未来状态并利用"惊讶"驱动学习与记忆
谢赛宁强调:"超感知不是更好的传感器,而是数字生命体验世界的方式。它是智能的一部分,正如眼睛是大脑触及外部世界的那一部分。"
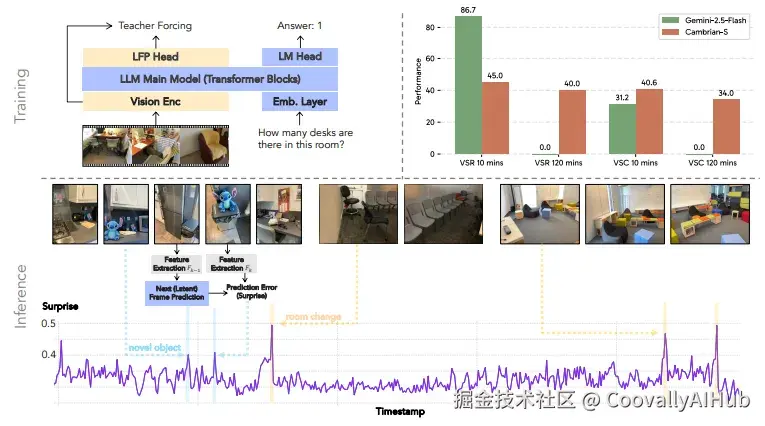
- 新基准:VSI-Super
为了评测空间超感知能力,作者提出了VSI-Super基准,包含两个极具挑战的任务:
- VSR(视觉空间回忆): 在长视频中回忆异常物体出现的位置与顺序

- VSC(连续视觉计数): 在跨场景、跨视角的视频中持续计数目标物体

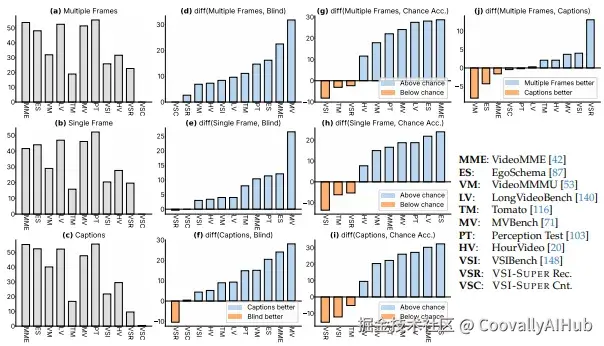
这两个任务都要求模型具备选择性感知、结构化记忆与跨时间推理能力,而非简单地扩展上下文窗口。
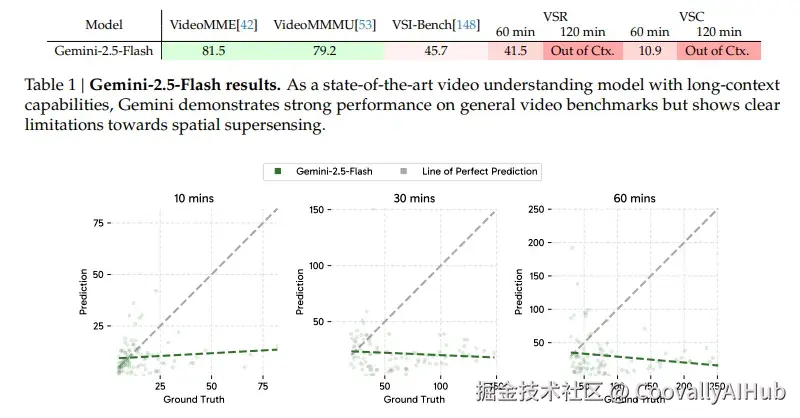
结果令人震惊:即使是最先进的Gemini 2.5模型也表现不佳。问题不在上下文长度------即使视频在模型处理能力范围内,性能仍然有限。
更关键的是,人类可以"无限计数",而模型的计数能力会在几十个对象后达到饱和,暴露了其训练数据的分布限制。
- Cambrian-S模型:数据驱动的空间认知突破

作者构建了大规模空间指令调优数据集VSI-590K,并训练了Cambrian-S系列模型。该模型在VSI-Bench等空间理解任务上取得了SOTA表现,甚至超越Gemini-2.5-Pro等闭源模型。
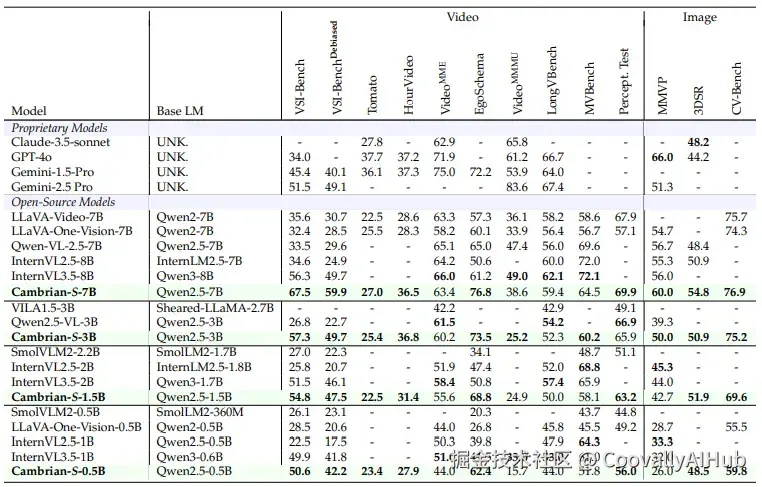
然而,Cambrian-S在VSI-Super上表现仍有限,说明仅靠数据与规模无法实现真正的空间超感知。
团队得出结论:沿着LLM的老路构建多模态模型,并非通往超感知的终极之道。
- 新范式:预测性感知
论文提出 *"预测性感知" *作为下一代模型的核心能力。通过自监督的"下一帧潜在预测"模型,利用预测误差(即"惊讶")来:
- 管理记忆: 选择性保留重要信息
- 分割事件: 将连续视频流划分为有意义的片段
实验表明,该方法在VSI-Super上显著优于Gemini-2.5等强基线,展示了预测机制在处理长视频与空间任务上的潜力。
- 开源与展望
团队将论文、代码、模型、数据和基准全面开源,并同步发布:
ruby
论文地址:https://arxiv.org/pdf/2511.04670
Website:https://cambrian-mllm.github.io
Code:https://github.com/cambrian-mllm/cambrian-s
Cambrian-S Models:https://hf.co/collections/nyu-visionx/cambrian-s
VSI-590K:https://hf.co/datasets/nyu-visionx/vsi-590k
VSI-SUPER:https://hf.co/collections/nyu-visionx/vsi-super关于消除基准中语言偏见的研究
使用模拟器收集空间感知视频的经验总结
谢赛宁表示:"我不敢说我们的方法就是正确道路,但我确信当前范式远远不够。开放科学才是唯一的出路。"
李飞飞长文深度解读:从文字到世界

在李飞飞最新发表的文章中,她进一步系统化地阐述了"空间智能"与"世界模型"的核心理念:
- LLM是"空间盲人",缺乏世界根基
李飞飞在文章中犀利地指出,当前的LLM本质上是"黑暗中的文字匠"------能言善辩却无经验,知识丰富却缺乏根基。
它们能处理和生成文本,甚至分析和生成图像、视频,却无法在脑海中构建一个连贯、立体、符合物理规律的3D世界。估算距离、方向、大小,心智旋转物体,在迷宫中导航,预测基本物理规律------这些对人类而言轻而易举的空间认知任务,对最先进的AI来说却难如登天。
这揭示了莫拉维克悖论在AI时代的再现:对人类和动物来说最低级、最无需思考的感知和运动技能,对AI而言反而是最困难的挑战。
- 空间智能:人类认知的"脚手架"
李飞飞指出,空间智能是人类理解、交互与创造世界的基础能力。从停车、接钥匙,到消防员在火场中决策,再到科学家通过几何推理发现地球周长,空间智能贯穿于人类的直觉、推理与创造之中。
"对AI而言,世界不止于语言,"李飞飞写道,"空间智能代表着超越语言的前沿。" 它是连接想象、感知与行动的关键,是机器真正融入并增强人类生活的基石。
- 当前AI的局限:语言≠世界
尽管当前的大语言模型在文本、图像、视频生成上表现惊人,但它们仍缺乏对物理世界的几何一致性、物理规律与动态交互的理解。李飞飞称之为"黑暗中的文字匠"。
- 世界模型的三大核心能力与三大技术挑战
如何实现空间智能?李飞飞提出了比LLM更具雄心的体系:世界模型。
她提出,真正具备空间智能的世界模型应具备以下能力:
- 生成性: 能生成符合物理与几何规律的世界
- 多模态: 能处理图像、视频、动作等多种输入
- 交互性: 能预测世界在动作影响下的下一个状态
构建世界模型巨大挑战:
李飞飞分享了World Labs在此方向的探索:
- 新训练目标: 需要找到像LLM的"下一个词预测"一样优雅的通用目标函数。
- 大规模数据: 需从互联网2D视觉数据中有效提取3D空间信息,并利用合成数据。
- 新模型架构: 需超越当前将数据视为1D/2D序列的Transformer和扩散模型范式。应用前景:从创造力到机器人,从科学到教育
- 实践探索:从Marble平台到预测性感知
李飞飞透露,其初创公司World Labs已在此方向取得进展。其Marble平台是全球首个能通过多模态输入生成并保持一致性3D环境的世界模型,已向部分创作者开放。
与此同时,在开源的《Cambrian-S》论文中,LeCun、李飞飞、谢赛宁团队实践了"预测性感知"这一新范式。他们受认知科学启发,在模型中引入"下一帧潜在预测"模块,利用预测误差("惊异度")来驱动记忆管理和事件分割。这个简化的世界模型原型,已让小模型在极具挑战性的空间推理基准VSI-Super上超越了Gemini 2.5等强大基线。
- 未来展望
空间智能的世界模型将如何改变世界?李飞飞描绘了清晰的图景:
- 创造力: 如Marble平台,让创作者快速构建、编辑3D世界
- 机器人: 通过世界模型仿真训练,实现泛化与协作
科学、医疗、教育:加速药物发现、提升诊断精度、构建沉浸式学习环境
总结
无论是LeCun、李飞飞等人的论文,还是李飞飞的深度长文,都指向同一个结论:空间智能是AI迈向通用智能的必经之路。当前以LLM为核心的范式已触及瓶颈,而融合生成、多模态与交互能力的世界模型,将成为下一代AI系统的核心。AI的发展路径正在从"通过文本来理解世界"的迂回策略,转向"直接感知与建模世界"的正面突破。
这不仅是技术的升级,更是一次认知的回归。它提醒我们,人类智能的辉煌,始于我们与这个三维空间世界的每一次互动、每一次预测和每一次创造。
我们正在为机器装上"空间感",这或许是赋予它们"常识"的第一步,也是走向真正通用人工智能最关键的一步。 从文字到世界的旅程已经启航,而它的终点,将是一个人类与智能机器共同理解、共同创造的美好未来。