外科医生离手术世界模型还有多远?首次提出SurgVeo基准,揭示AI生成手术视频的惊人差距
近年来,视频生成领域的基石模型展现出作为潜在"世界模型"模拟物理世界的惊人能力。谷歌的Veo等模型已经能够生成逼真的日常场景视频,让我们仿佛看到了通用物理世界模拟器的雏形。
然而,当这些技术被应用于外科手术这样高风险、需要深度专业知识的领域时,其表现如何?这是一个至关重要却尚未被深入探索的问题。
通用世界模型遭遇专业领域挑战
"世界模型"的核心是让机器建立关于世界如何运作的内部表征,理解环境演变和行为后果。但在外科手术领域,仅理解日常物理规则是远远不够的。
外科手术充满了需要"专家直觉"的知识------解剖学、生理学、生物力学。一个真正有用的"手术世界模型"必须理解手术刀切开不同组织时的反应,理解特定操作背后的战略意图。
为模拟"常识物理"而设计的模型,能否驾驭需要"专家知识"的手术领域?耶鲁大学、诺丁汉大学等机构的研究者们进行了一项开创性研究,试图回答这个问题。

论文链接:
Benchmark(未开源):
SurgVeo基准与手术合理性金字塔
研究者构建了完整的评测体系来解决这一挑战。他们提出了SurgVeo------首个由专家策划的、用于评估手术视频生成模型的基准,包含腹腔镜子宫切除术和内窥镜垂体手术两种代表性手术视频。

更重要的是,团队设计了一个新颖的四层评估框架------手术合理性金字塔,从四个层面系统评估生成内容的质量:
- 视觉感知合理性:评估最基本的画面质量,如清晰度、光照、组织纹理
- 器械操作合理性:评估手术器械的运动轨迹是否符合手术规范
- 环境反馈合理性:评估组织、器官对器械操作的反应是否真实
- 手术意图合理性:评估系列动作是否展现出符合手术阶段的战略目标
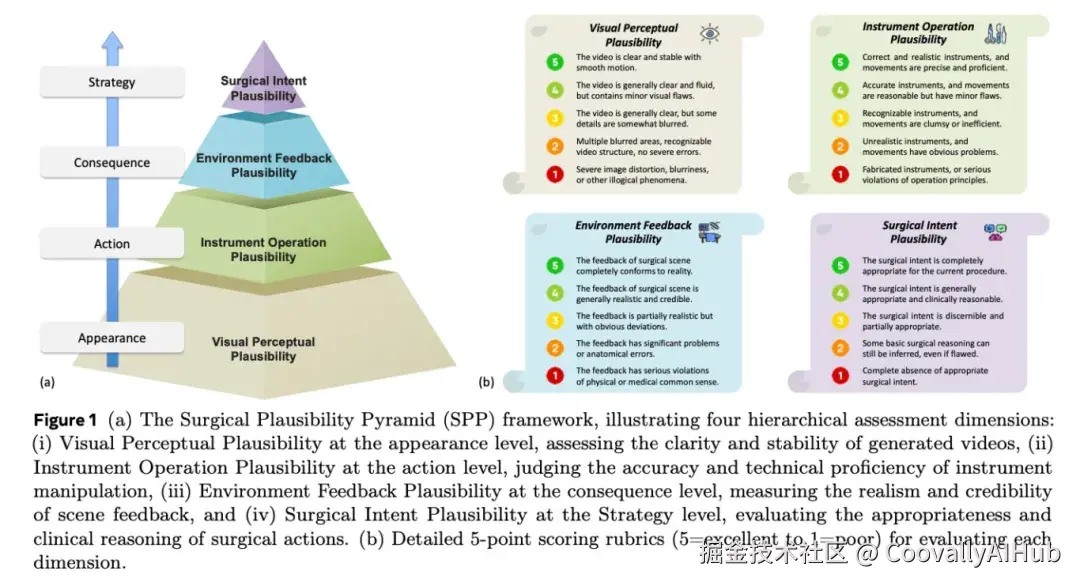
研究邀请了四位执业外科医生组成专家小组,使用SPP框架对Veo-3模型生成的视频进行打分。模型执行的是零样本预测任务:给定手术场景的起始帧和文本提示,生成接下来8秒的手术视频。
惊人的"合理性差距"
研究结果揭示了一个深刻的断层------"合理性差距":尽管模型在生成视觉上令人信服的手术场景方面表现出色,但在SPP框架的更高层级上却严重失败。
- 量化数据揭示的真相
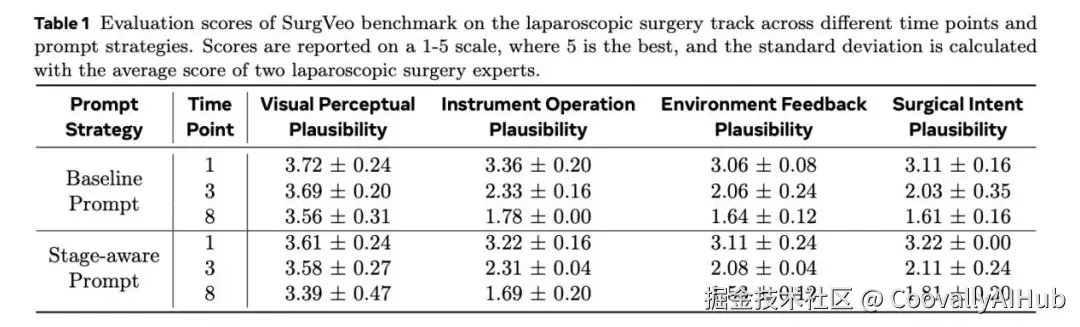
在腹腔镜手术中,视觉感知合理性的初始得分为3.72分(满分5分),表明生成的图像"清晰得惊人"。然而,分数在SPP金字塔的更高层级急剧下降:
环境反馈合理性从1秒时的3.06分骤降至8秒时的1.64分
手术意图合理性从2.83分降至1.52分
器械操作合理性从3.13分降至1.68分
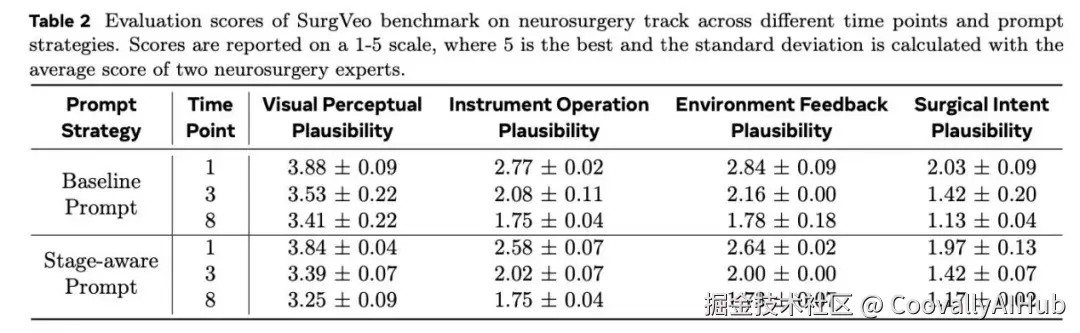
神经外科手术中也观察到同样的趋势,视觉感知得分3.88分,而其他维度得分均低于2.5分,且随时间推移迅速恶化。
- 典型失败案例触目惊心
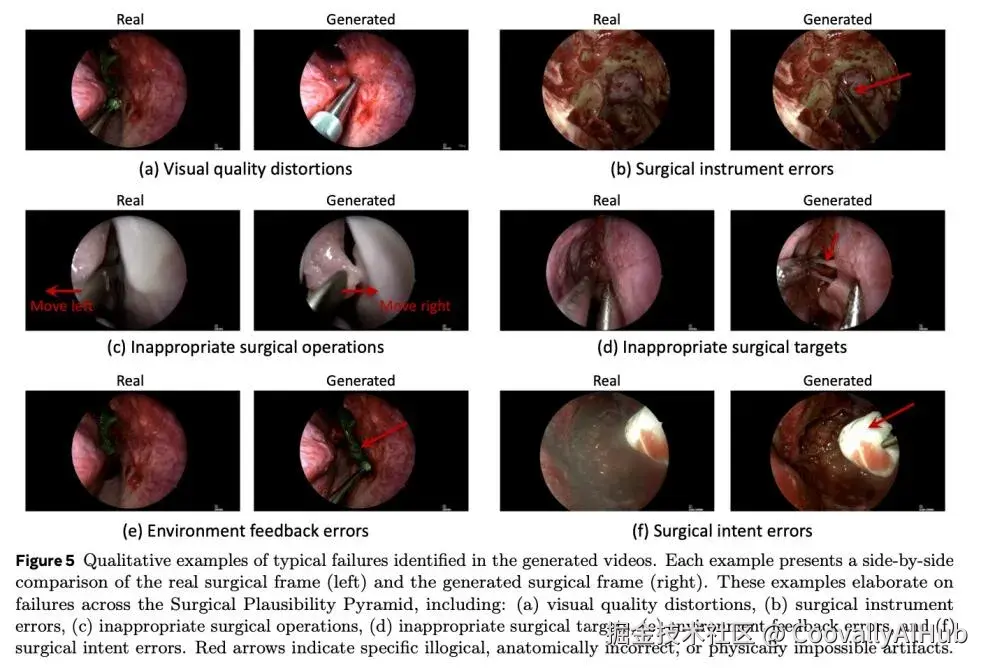
定性分析让这些数字变得更加直观:
- 视觉质量失真:生成的视频画面亮度发生突兀且不自然的变化
- 器械错误:模型"幻觉"出现实中不存在的手术器械
- 操作不当:真实操作需要向左移动,模型却生成了向右的错误动作
- 环境反馈错误:吸引器违反物理定律,像提拉固体一样将整块明胶海绵吸走
- 意图错误:真实意图是在硬脑膜上注射生物胶水,模型却预测用棉片擦拭
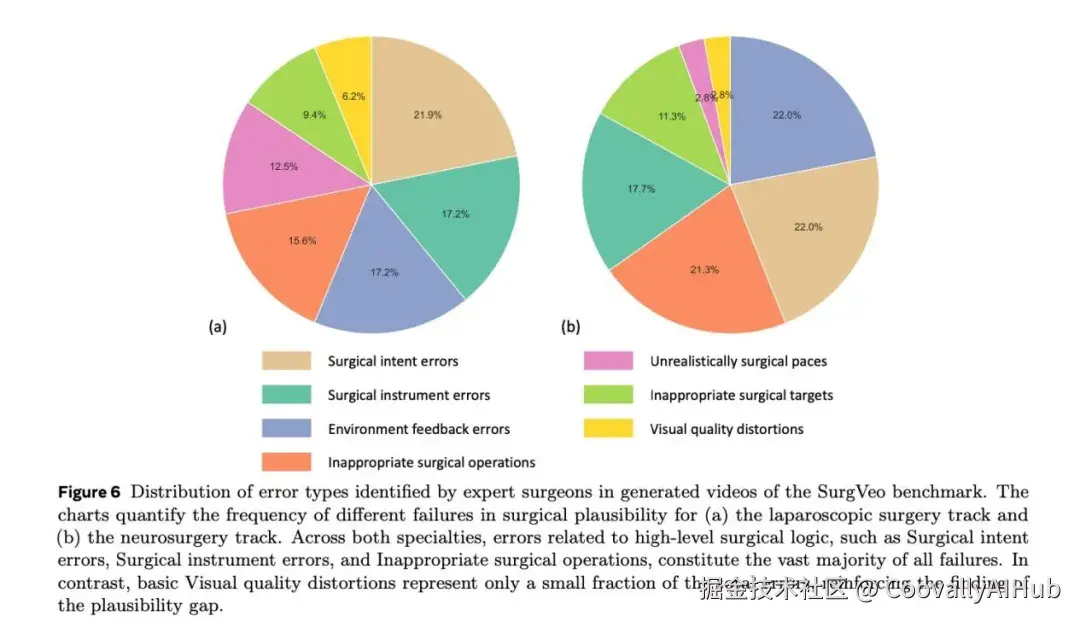
错误类型的量化分布显示,与高层手术逻辑相关的错误占了绝大多数(腹腔镜93.8%,神经外科97.2%),而底层视觉质量问题仅占一小部分。
研究意义与未来方向
这项研究首次提供了量化证据,揭示当前最先进视频生成模型在手术AI领域中,令人信服的视觉模仿与真正的因果理解之间存在巨大鸿沟。
研究发现,为模型提供更明确的"阶段感知"提示并不能显著改善表现,证明问题不在于缺少上下文信息,而在于模型根本无法理解和运用专业领域知识。
这项工作为未来研究指明了方向:仅仅依靠在通用数据上进行大规模训练,可能不足以让模型掌握专家领域的复杂规则。未来的"手术世界模型"可能需要新的架构范式,能够整合结构化的领域知识,并在生成过程中强制执行严格的物理和逻辑约束。
SurgVeo基准和SPP评估框架为开发真正可靠的手术AI系统奠定了重要基础。虽然通往真正的手术世界模型道阻且长,但这项研究无疑是迈出的清醒而关键的一步。
对于AI在医疗领域的发展,这项研究提醒我们:外观的逼真绝不等于内在的合理,在关乎人命的高风险领域,模型的深度理解比表面完美更为重要。