论文标题: TempRetinex: Retinex-based Unsupervised Enhancement for Low-light Video Under Diverse Lighting Conditions
发表日期: 2025年11月
作者: Yini Li, Nantheera Anantrasirichai
发表单位: Visual Information Laboratory, University of Bristol
原文链接: https://arxiv.org/pdf/2511.09609v1.pdf
开源代码链接: https://github.com/ XXXX/TempRetinex

低光视频增强的三大挑战亟待解决
**挑战一:数据"饥荒"**想用深度学习模型?首先得有大量"暗光-正常光"的成对视频数据来训练。但现实是,这种高质量配对数据极其稀缺。你总不能为了做数据集,把同一个场景用不同亮度拍几百遍吧?这成本和时间都耗不起。所以,很多监督学习方法(需要配对数据)在这里就"巧妇难为无米之炊"了。
挑战二:"时间线"的丢失 视频不是一堆图片的简单堆砌,帧与帧之间有着丰富的++时间信息++和关联。很多方法偷懒,直接把处理单张图片的模型套用到视频的每一帧上。结果呢?每一帧都"各自为政",增强出来的亮度、颜色可能都不一样,连起来播放就成了"灯光秀"------疯狂闪烁,毫无连贯性可言。
挑战三:光照的"千变万化" 现实世界的光照条件可不是一成不变的。从10%亮度的"伸手不见五指"到20%亮度的"依稀可辨",相机参数(ISO、曝光时间)会动态调整,导致视频本身的特性(亮度分布、噪声水平)差异巨大。这让模型训练起来非常困难,很容易在某种特定亮度上"过拟合",换个亮一点或暗一点的场景,效果就崩了,缺乏++泛化能力++。
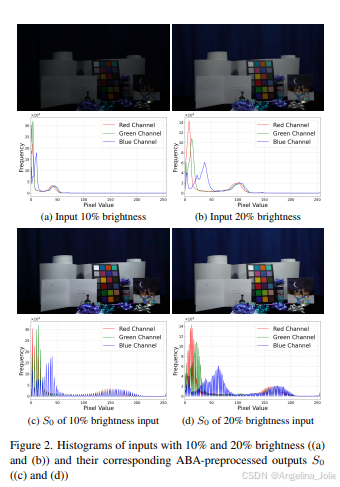
图2:10%和20%亮度输入的直方图((a)和(b))及其对应的ABA预处理输出S0的直方图((c)和(d))。可以看到,经过ABA预处理后,不同亮度输入的分布变得非常相似。
面对这三大难题,布里斯托大学的研究者们没有选择"硬刚"数据,而是另辟蹊径,提出了一个无监督 的解决方案。这意味着,模型训练++不需要任何成对的"暗光-正常光"视频++,仅靠暗光视频本身就能学会如何增强!是不是很神奇?接下来我们就看看它的核心思想。
从Retinex理论出发:TempRetinex的核心思想
TempRetinex这个名字,已经透露了它的两大基石:Temporal(时间) 和 Retinex(视网膜理论)。
首先,什么是++Retinex理论++ ?这是一个仿生学理论,简单来说,它认为人眼看到的图像(I)可以分解为两个部分的乘积:反射分量(R) 和 光照分量(S)。
反射分量 R :代表物体本身的属性,比如颜色、纹理。理论上,不管在阳光下还是烛光下,苹果的红色(反射属性)是不变的。
光照分量 S:代表照射在物体上的光线强度。白天阳光强,S值大;夜晚灯光弱,S值小。
所以,低光图像之所以暗,主要是因为光照分量 S 太弱 。增强的思路就很清晰了:我们想办法++估计出反射分量 R 和弱光照 S++ ,然后增强 S(比如把它乘上一个系数),再和 R 乘回去,就得到了亮度提升后的图像。这个过程中,保持 R 的清晰和准确至关重要,因为它包含了所有细节。
但现实更骨感!相机在暗光下会引入大量噪声。因此,TempRetinex将模型扩展为:
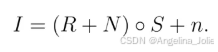
这里,N 是附着在反射分量上的传感器噪声,n 是加性噪声。"∘"代表逐元素相乘。所以,任务变成了:从嘈杂的低光图像 I 中,同时估计出干净的反射 R、光照 S,并去掉两种噪声 N 和 n。
而Temporal部分,就是利用视频帧之间的时间关联性来帮助完成这个艰巨的任务。比如,利用前一帧已经增强好的信息,来引导当前帧的处理,让结果在时间上更连贯。
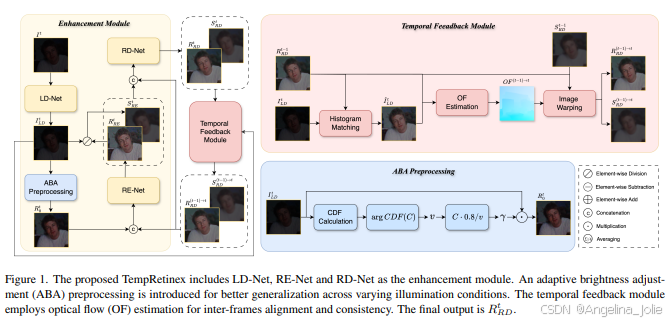
图1:提出的TempRetinex框架整体架构。主要包括增强模块(LD-Net, RE-Net, RD-Net)和时间反馈模块。引入了自适应亮度调整(ABA)预处理以适应不同光照条件。时间反馈模块利用光流(OF)估计进行帧间对齐和一致性保持。最终输出是 R_RD^t。
自适应亮度调整(ABA):让模型"见多识广"的预处理秘诀
还记得我们说的第三个挑战吗?光照条件千变万化,模型容易"偏科"。现有的无监督方法,在训练时看到的亮度分布比较单一,一旦遇到比训练数据更亮或更暗的输入,就容易"翻车"。

图3:Zero-TIG方法在不同亮度级别下的增强结果,说明了泛化问题。输入非常暗时输出欠曝,输入比训练数据均值亮时输出过曝。其他无监督方法也存在类似退化。
TempRetinex的解决思路非常巧妙,而且完全不需要训练 !它提出了一个叫**自适应亮度调整(Adaptive Brightness Adjustment, ABA)**的预处理步骤。
核心思想基于Retinex理论:++反射分量 R 是物体的固有属性,应该在不同光照下保持统计分布的一致性++。那么,与其让网络直接去啃亮度差异巨大的原始图像,不如我们先手动把不同亮度的图像"拉"到同一个亮度水平线上,生成一个初步的、分布相对统一的反射分量估计 R0,然后再交给后续网络去细化。
ABA具体怎么做呢?就三步,全是简单的图像统计操作:
**第一步:找"有效亮度天花板"**计算输入图像 I 的灰度直方图累积分布函数(CDF)。找到一个灰度值 v,使得 CDF 达到一个预设的阈值 C(比如 C=0.99)。这个 v 就被认为是当前光照下图像的"最大有效亮度"。
**第二步:算"放大系数"**根据 v 计算一个直方图放大系数 γ。公式如下:
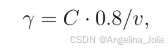
这里的 0.8 是一个安全因子,防止放大过度导致过曝。
第三步:生成初始反射分量直接用这个系数去乘原始图像:
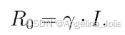
得到的 R0 就是ABA预处理后的输出,它的亮度分布被归一化了,不同亮度输入产生的 R0 会非常相似(回顾图2(c)(d))。这个 R0 将作为后续反射估计网络(RE-Net)的起点。
这个操作好比在让网络学习之前,先给所有输入数据做了一次"标准化",大大降低了学习的难度,提升了模型对不同光照的适应能力。
网络结构揭秘:LD-Net、RE-Net、RD-Net如何协同作战?
看懂了ABA这个"前菜",我们再来品味TempRetinex的"主菜"------增强模块。它由三个核心子网络组成,像流水线一样紧密协作。
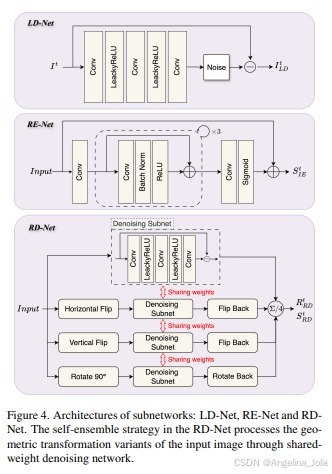
图4:子网络架构:LD-Net、RE-Net和RD-Net。RD-Net中的自集成(SE)策略通过共享权重的去噪网络处理输入图像的几何变换变体。
第一站:LD-Net(低光去噪网络)
输入的低光图像 I 首先进入LD-Net。它的结构很简单,就三层3x3的卷积。它的任务不是直接增强,而是初步抑制加性噪声 n,输出一个初步去噪的图像 I_LD。为什么先做这一步?因为后续的照明估计对噪声很敏感,先降噪能让照明估计更准确。
第二站:ABA预处理 + RE-Net(反射估计网络)
I_LD 不会直接进入RE-Net,而是先经过我们刚讲的ABA预处理,变成初始反射估计 R0。然后 R0 被送入RE-Net进行迭代细化。
RE-Net采用带残差结构的卷积网络,一步步优化反射图。经过RE-Net,我们得到优化的反射分量 R_RE(注意,它还包含传感器噪声N)和光照分量 S_RE。它们的关系是:
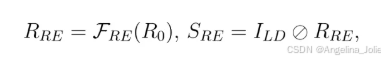
第三站:RD-Net(反射去噪网络) + 自集成(SE)
现在,我们手上有带噪的反射 R_RE 和估计好的光照 S_RE。RD-Net的任务就是专门对付附着在反射分量上的传感器噪声 N,输出干净的最终反射 R_RD。
这里,TempRetinex玩了一个很聪明的花招------自集成(Self-Ensemble, SE)。它把 R_RE 和 S_RE 拼接起来作为输入,但并不是直接处理。
它会把这个输入图像做四种几何变换:原图、水平翻转、垂直翻转、旋转90度。然后把这四个"变体"++同时++喂给同一个RD-Net(网络权重共享)去处理。得到四个去噪结果后,再分别做逆变换还原回来,最后取个平均,就得到了最终的 R_RD。
这招有什么用?相当于让网络从多个不同的"视角"去看同一张图,综合判断哪里是噪声哪里是细节。这能有效提升去噪效果和对不同纹理的鲁棒性,而且不增加任何额外的网络参数,性价比极高!
时序反馈模块:如何让视频帧"步调一致"?
好了,单个帧的增强流水线讲完了。但如果只是独立处理每一帧,我们还是会得到那个令人头疼的"灯光秀"效果。TempRetinex的"Temporal"精髓,就体现在这个时序反馈模块里。
它的目标很明确:利用已经处理好的前一帧信息,来引导和约束当前帧的处理,从而让整个视频看起来连贯、稳定。
具体怎么"引导"呢?核心工具是++光流(Optical Flow)++。假设我们正在处理第 t 帧。我们已经有前一帧(t-1帧)增强后的干净反射 R_RD^{t-1} 和光照 S_RD^{t-1}。
第一步,为了让光流估计更准,需要先把当前帧的初步去噪图 I_LD^t 和前一帧的结果 R_RD^{t-1} 的亮度分布对齐。这里用的是直方图匹配(Histogram Matching),把 I_LD^t 的直方图变得和 R_RD^{t-1} 一样。
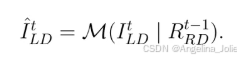
公式6:对 I_LD^t 进行直方图匹配,使其分布与 R_RD^{t-1} 一致,得到 \hat{I}_{LD}^t。
第二步,用预训练好的光流网络(比如RAFT),计算从 R_RD^{t-1} 到 \hat{I}_{LD}^t 的光流图 OF。这个光流图描述了从第t-1帧到第t帧,每个像素点是怎么移动的。
第三步,利用这个光流图,把前一帧的反射和光照"扭曲(Warp)"到当前帧的视角下。这样,我们就得到了对齐后的历史反射 R_RD^{(t-1)→t} 和历史光照 S_RD^{(t-1)→t}。
最后,把这些对齐后的历史信息(R和S)在通道维度上,与当前帧正在处理的对应特征拼接起来,一起送到RE-Net和RD-Net里去优化。这就好比在给当前帧"做决定"时,旁边有个"前辈"(前一帧)在提供参考意见,自然能大大提高决策(增强结果)的连贯性。
多尺度时序一致性损失:告别闪烁,实现丝滑流畅
光有网络结构上的引导还不够,还需要在"学习目标"上加以约束。TempRetinex设计了一个专门的**多尺度时序一致性感知损失(L_mtc)**来强力"鞭策"模型,让它输出的视频必须连贯。
这个损失函数的核心思想很简单:当前帧输出的反射 R_RD^t,应该和从上一帧对齐过来的反射 R_RD^{(t-1)→t} 尽可能相似。
但有两个精妙之处:
1. 遮挡感知掩码
如果场景中有物体在快速运动,前一帧的某些部分可能在当前帧被挡住了(比如一个人走过镜头)。光流对齐在这些区域会失效。强行让所有像素都一致,反而会引入错误。
因此,TempRetinex计算了一个++遮挡掩码(M)++ 。它通过比较 R_RE^t 和 R_RD^{(t-1)→t} 的差异来生成:差异大的地方,很可能是遮挡区域,掩码值就小(接近0),这样损失函数就会忽略这些地方;差异小的地方,掩码值大(接近1),损失函数会重点约束这些区域保持一致。这就实现了智能的、选择性的时间一致性。
2. 多尺度优化
直接在全分辨率上计算一致性,可能会因为微小的、无害的对齐误差而产生很大的损失值。于是,本方法把图像下采样到多个尺度(比如原图,1/2,1/4,1/8),分别在每个尺度上计算带掩码的一致性损失,然后加起来。
2. 多尺度优化
直接在全分辨率上计算一致性,可能会因为微小的、无害的对齐误差而产生很大的损失值。于是,本方法把图像下采样到多个尺度(比如原图,1/2,1/4,1/8),分别在每个尺度上计算带掩码的一致性损失,然后加起来。
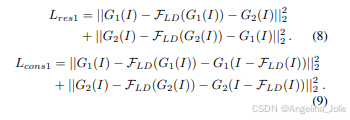
公式8:LD-Net的残差损失(L_res1)和一致性损失(L_cons1),通过下采样构造训练对进行无监督去噪学习。
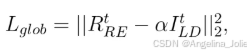
公式10:全局亮度约束损失(L_glob),约束反射分量的平均亮度接近预设目标α。
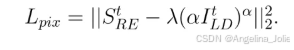
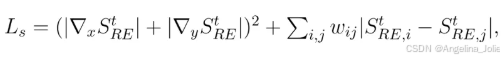
自集成与反向推理:两大策略进一步提升性能
讲完了核心模块,TempRetinex还有两个像"插件"一样好用的策略,能进一步拔高它的表现。
自集成(SE):我们前面在RD-Net里见过了。
它通过处理输入图像的多个几何变换版本来提升去噪的鲁棒性和效果,是个非常实用的"炼丹"技巧。
反向推理(Reverse Inference):离线处理的"时光机"。
时序反馈模块是"因果"的,只能利用过去的信息。但对于很多可以离线处理的视频(比如后期制作),我们明明有"未来"的信息可用!
反向推理策略就是为此而生:先把视频按正常顺序(从第1帧到第N帧)处理一遍,得到一组结果;再把视频倒过来(从第N帧到第1帧)处理一遍,得到另一组结果;最后把两组结果对应帧平均一下。
这样一来,处理中间某一帧时,它既能参考"过去",也能参考"未来",利用了更全面的时间信息,效果自然会更好。而且这个策略不需要改动任何网络结构或重新训练,即插即用。
实验结果:多项指标全面领先,视觉效果惊艳
说了这么多,TempRetinex实际效果到底怎么样?龙哥带你看硬核数据!论文在BVI-RLV和DID两个主流低光视频数据集上,与六个前沿的无监督方法进行了全面对比。
评价指标用了三个:PSNR(峰值信噪比,值越高越好)、SSIM(结构相似性,值越高越好)、LPIPS(感知相似性,值越低越好)。为了公平评估去噪能力,还提供了对结果进行直方图匹配(HM)后的指标,以排除亮度差异的影响。
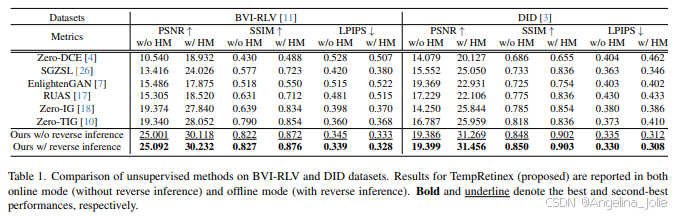
表1:在BVI-RLV和DID数据集上无监督方法的对比。TempRetinex的结果报告了在线模式(无反向推理)和离线模式(有反向推理)。加粗和下划线分别表示最佳和次佳性能。
结果一目了然:TempRetinex在几乎所有指标和设置下都取得了最优或接近最优的成绩。尤其是在BVI-RLV数据集上,在不做直方图匹配的情况下,相比之前最好的方法Zero-TIG,PSNR提升了惊人的29.7%!这充分证明了其综合增强能力的强大。
反向推理策略也证实有效,带来了小幅但稳定的指标提升。这为离线处理场景提供了免费的性能增益。
