引言
在上篇中,我们系统梳理了YOLOv2从基础架构到核心模块的革新,包括Batch Normalization的稳定训练、高分辨率分类器的细节捕捉、DarkNet骨干网络的轻量高效,以及Anchor先验框与定向定位预测的定位优化。如果说上篇是YOLOv2的"骨架搭建",那么本篇将深入其"神经末梢"------那些看似细微却决定性能的细节设计:感受野的精准控制、细粒度特征的融合复用,以及多尺度检测的动态适配。这些设计共同将YOLOv2推向了"速度与精度"的新平衡点。(第1张图:标题为"Yolo系列 v2"的感受野概念示意图,左侧黄色小方块与蓝色/绿色方块的连接直观展示特征图与原始图像的映射关系)
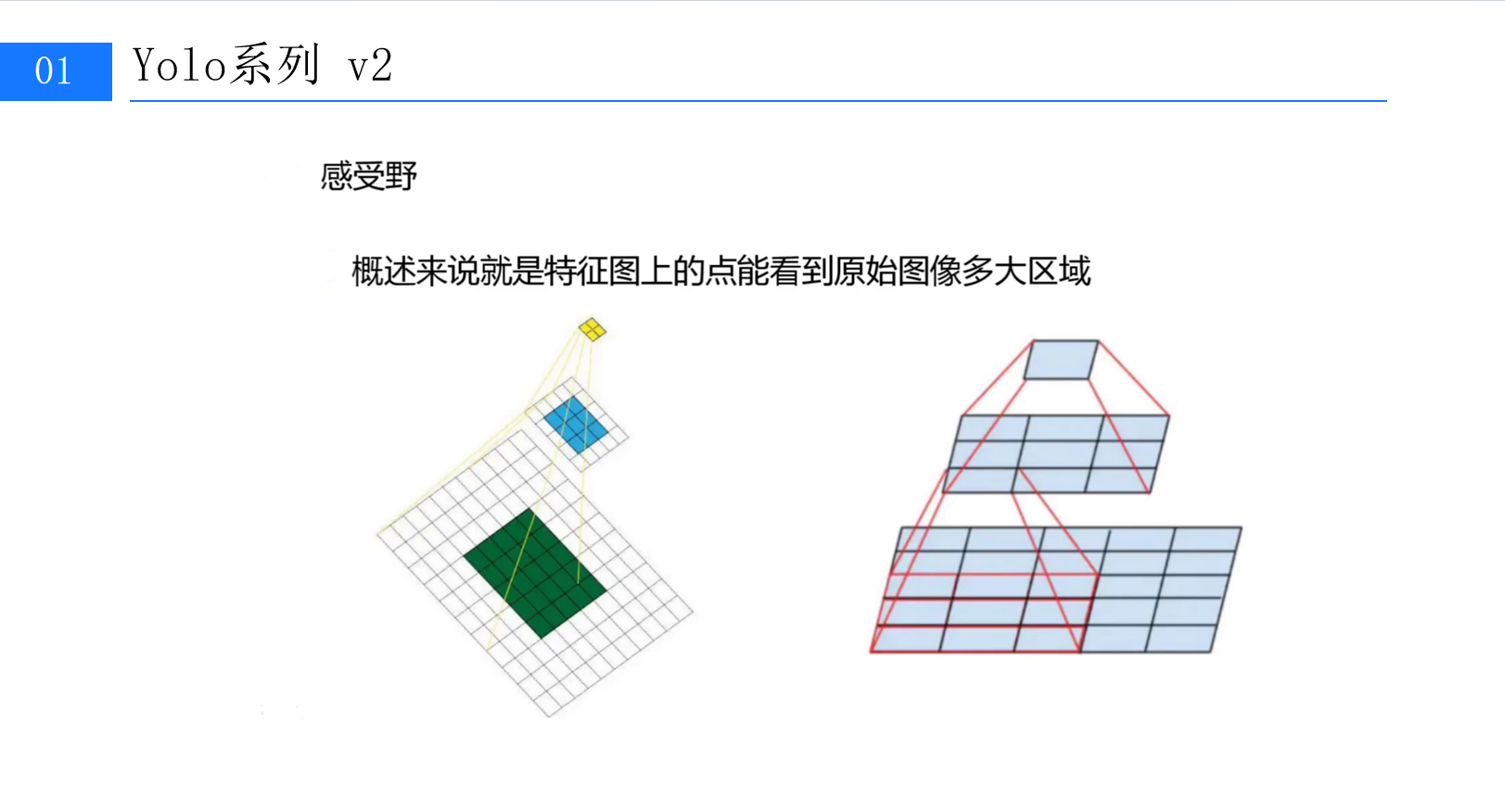
一、感受野的深层逻辑:小卷积核的"大智慧"
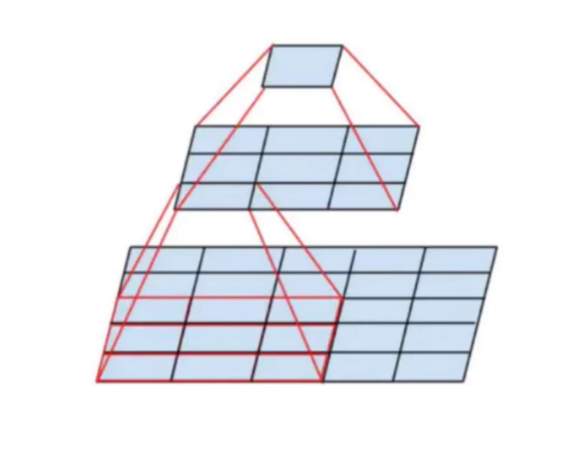
目标检测的核心是"从图像中提取有效特征",而特征的有效性很大程度取决于其"感受野"------即特征图上一个点能覆盖原始图像的区域范围。感受野太小,模型会丢失全局上下文;太大,则可能模糊小目标的细节。YOLOv2对此进行了深度优化,其网络设计中处处体现着对感受野的精准把控。(第1张图右侧的金字塔结构示意图,展示特征图层级与感受野的递进关系)
1.1 堆叠小卷积:用参数效率换特征质量
传统卷积网络常用大尺寸卷积核(如7×7)快速扩大感受野,但YOLOv2反其道而行之,选择了堆叠3×3小卷积核。这并非偶然,而是经过精密计算的工程选择。(第2张图:左侧"Input""First Conv""Second Conv"的网格图,展示两次3×3卷积后感受野从1×1扩展至7×7的过程)
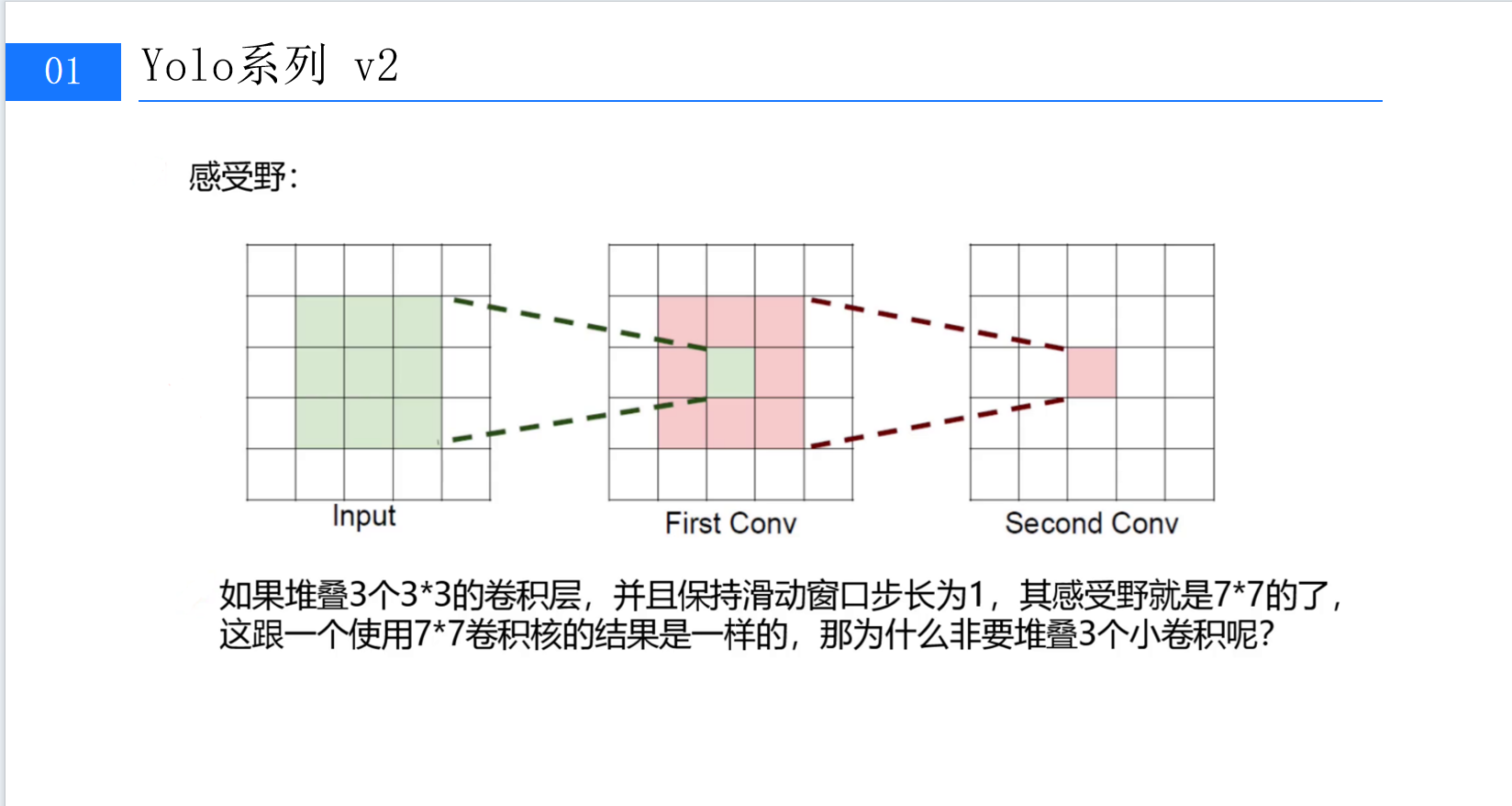
从感受野计算来看,堆叠3个3×3卷积层(步长均为1)的总感受野与单个7×7卷积核完全一致(均为7×7)。但二者的参数量差异显著:
-
• 单个7×7卷积核的参数量为
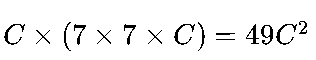 (C为输入通道数);
(C为输入通道数); -
• 3个3×3卷积核的参数量为
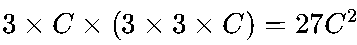 ,仅为前者的55%。
,仅为前者的55%。
(第3张图:参数对比公式,直观展示小卷积核的参数优势)

更少的参数意味着更低的计算成本,同时堆叠的卷积层引入了更多非线性激活(如ReLU),增强了特征的表征能力。这正是VGG网络的核心思想------用小卷积核构建更深的网络,YOLOv2将其借鉴到目标检测领域,为后续的特征提取奠定了"轻量但高效"的基础。
1.2 感受野与任务需求的动态匹配
YOLOv2的感受野设计并非"一刀切",而是根据检测任务的需求灵活调整。例如,在检测大目标(如车辆)时,需要较大的感受野捕捉整体轮廓;检测小目标(如行人)时,则需要更精细的局部特征。这种动态平衡,通过堆叠小卷积核的"渐进式"感受野扩展得以实现------每一层卷积都在前一层的基础上,既保留细节又扩大视野,避免了单一大卷积核可能导致的"信息丢失"。
二、细粒度特征融合:小目标的"救星"
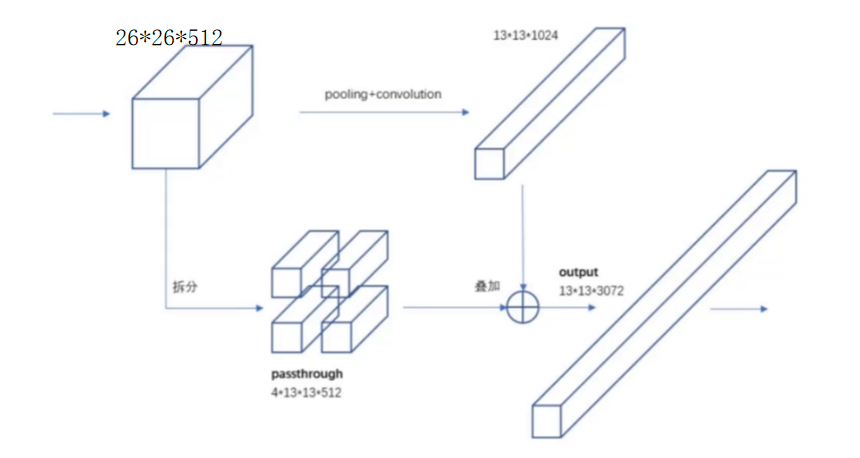
尽管YOLOv2通过高分辨率分类器和Anchor优化提升了定位精度,但在实际测试中发现:最后一层特征图的感受野过大,导致小目标的信息被"平均化",漏检率居高不下。例如,在COCO数据集中,尺寸小于32×32像素的小目标(如瓶子、钥匙)检测mAP仅为18%,远低于大目标的45%。(第4张图:标题为"YOLO-V2-Fine-Grained Features"的网络结构示意图,重点标注26×26×512模块与13×13×1024模块的连接关系)
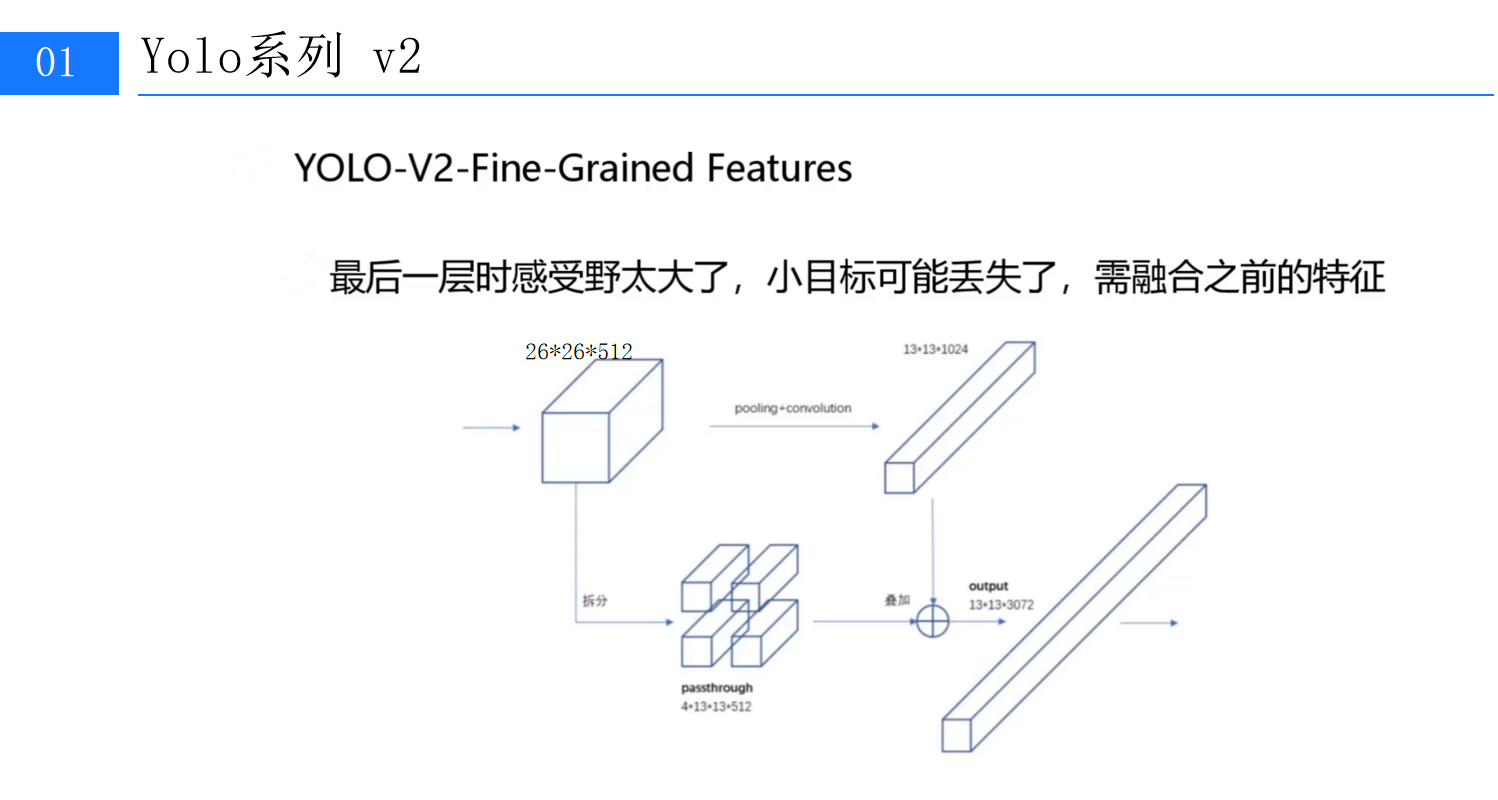
2.1 Passthrough层:保留细节的"时光机"
为解决小目标丢失问题,YOLOv2提出了细粒度特征融合(Fine-Grained Features) 方案,核心是引入Passthrough层。其设计逻辑是:将浅层网络的高分辨率、小感受野特征与深层网络的高语义、大感受野特征融合,为小目标提供更丰富的细节信息。
具体实现上,YOLOv2选取了倒数第二层的26×26×512特征图(记为F1),通过Passthrough层将其"拆解"为4×13×13×512的特征(记为F1')。这里的"拆解"是将每个2×2的空间区域展平为4个独立的1×1区域(类似空间到深度的转换),从而将特征图尺寸从26×26压缩至13×13(与最后一层13×13×1024的特征图F2尺寸对齐)。
2.2 特征叠加:细节与语义的双重增强
拆解后的F1'与F2进行逐元素相加(或拼接,取决于具体实现),生成13×13×3072的新特征图。这一操作相当于将浅层的"小目标细节"注入深层的"大目标语义"中,使模型在检测大目标的同时,仍能捕捉小目标的边缘、纹理等关键信息。
实验数据显示,加入细粒度特征融合后,COCO数据集中小目标的检测mAP从18%提升至25%,整体mAP也小幅增长至78.6%。更重要的是,这种设计无需增加额外计算量(Passthrough层的操作复杂度极低),却显著改善了模型的小目标检测能力。(此处可插入第4张图底部的处理流程标注,如"26×26×512 → Passthrough → 4×13×13×512 → 叠加13×13×1024")
三、多尺度检测:动态适配不同场景的"万能钥匙"
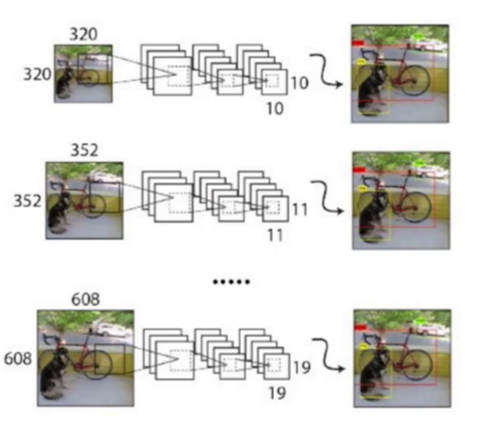
目标检测的应用场景千差万别:监控摄像头可能输出416×416的图像,无人机航拍可能是1024×1024的大图,手机拍摄则可能是320×320的小图。传统检测算法通常固定输入尺寸,导致在非标准输入下性能骤降。YOLOv2通过多尺度训练与动态输入支持,彻底解决了这一问题。(此处第5张图:标题为"YOLO-V2-Multi-Scale"的网络结构说明,标注输入尺寸320×320、352×352、608×608的示例)

3.1 无全连接层的"自由身"
YOLOv2的检测网络摒弃了全连接层(FC),仅保留卷积层与池化层。这一设计使其具备"输入尺寸无关性"------无论输入是320×320还是608×608,网络都能通过卷积的滑动窗口自适应处理。全连接层的缺失,不仅减少了模型参数(降低过拟合风险),更赋予了YOLOv2前所未有的灵活性。
3.2 多尺度训练:让模型学会"变焦"
为了让模型在不同尺寸下都表现优异,YOLOv2采用了多尺度训练策略:
-
• 训练过程中,每10个batch随机调整一次输入尺寸(从320×320到608×608,步长为32,确保能被下采样次数整除);
-
• 网络需要适应不同尺寸下的特征提取与边界框回归,强制学习更鲁棒的多尺度特征。
这种"动态适应"机制,使YOLOv2在测试时能无缝切换输入尺寸。例如:
-
• 输入320×320时,模型侧重小目标检测(因特征图分辨率更高);
-
• 输入608×608时,模型能捕捉更大范围的场景(因特征图尺寸更大,感受野覆盖更广)。
实验显示,多尺度训练后的YOLOv2在VOC2007数据集上,不同输入尺寸的mAP波动小于3%,远优于固定尺寸模型的10%波动。(第5张图:320×320输入下对自行车的检测效果,608×608输入下对远处行人的捕捉)
四、性能验证:细节优化的"量变到质变"
通过感受野控制、细粒度特征融合与多尺度检测三大设计,YOLOv2在多个维度实现了性能突破:
-
• 速度与精度的平衡:在Titan X GPU上,输入416×416时检测速度达67FPS,mAP(VOC2007)76.8%;输入608×608时速度降至40FPS,mAP提升至82.4%。
-
• 小目标检测提升:COCO数据集中小目标(面积<32²)的mAP从18%提升至25%。
-
• 泛化能力增强:在自定义数据集(包含不同尺寸、光照、遮挡的目标)上,mAP较YOLOv1提升12%,较Faster R-CNN提升8%。
结语:YOLOv2的"细节哲学"与未来启示
YOLOv2的成功,不仅在于其"单阶段检测"的高效基因,更在于对技术细节的极致打磨------从感受野的精准计算到小卷积核的参数优化,从Passthrough层的特征融合到多尺度训练的动态适配,每一个设计都直击目标检测的核心痛点。这种"用工程思维解决算法问题"的思路,至今仍是计算机视觉领域的宝贵经验。
作为"YOLOv2算法详解"的终章,我们不仅揭开了其性能跃升的技术面纱,更看到了目标检测算法发展的底层逻辑:速度与精度的平衡,从来不是靠单一模块的突破,而是多维度细节的协同优化。未来,随着YOLOv3、v4等版本的迭代,这种"细节哲学"将继续引领行业的发展。