文章:OneTrackerV2: Unified Multimodal Visual Object Tracking with Mixture of Experts
代码:暂无
单位:暂无
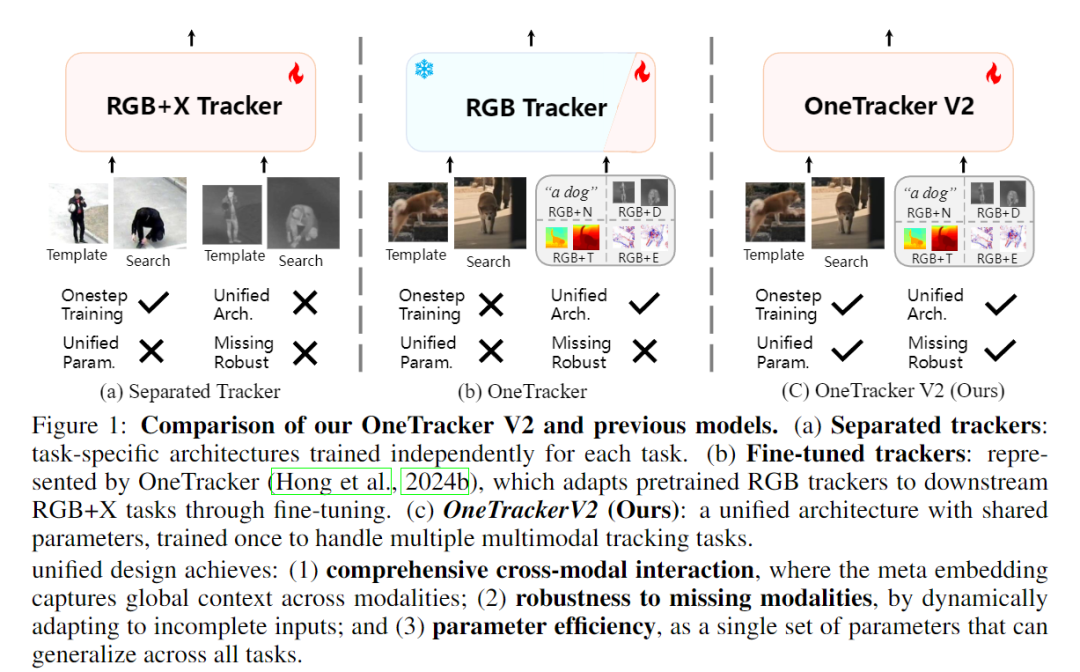
一、问题背景:多模态跟踪的"碎片化"困境 🎥
视觉目标跟踪(Visual Object Tracking)旨在根据目标在首帧中的外观,在后续帧中持续定位目标位置。 然而,随着模态数量的增加(RGB、RGB+D、RGB+T、RGB+E、RGB+N),研究者们遇到了一个巨大挑战:
🧩 不同模态(modality)需要不同架构和权重,难以统一训练与部署。
现有方案主要分为两类:
-
Separated Tracker:为每种模态独立设计网络,训练效率低;
-
Adaptation-based Tracker(如 OneTracker):通过微调 RGB 模型适配下游任务,性能受限。
这些方法普遍存在三大问题:
-
缺乏统一架构(Unified Architecture);
-
参数无法共享(Un-unified Parameters);
-
无法应对缺失模态(Missing Modality) 。
二、方法创新:Meta Merger + Dual Mixture-of-Experts 🧠
为解决这些痛点,作者提出 OneTrackerV2 ------一个可处理任意模态输入、一次训练即可泛化到多任务的统一框架 。
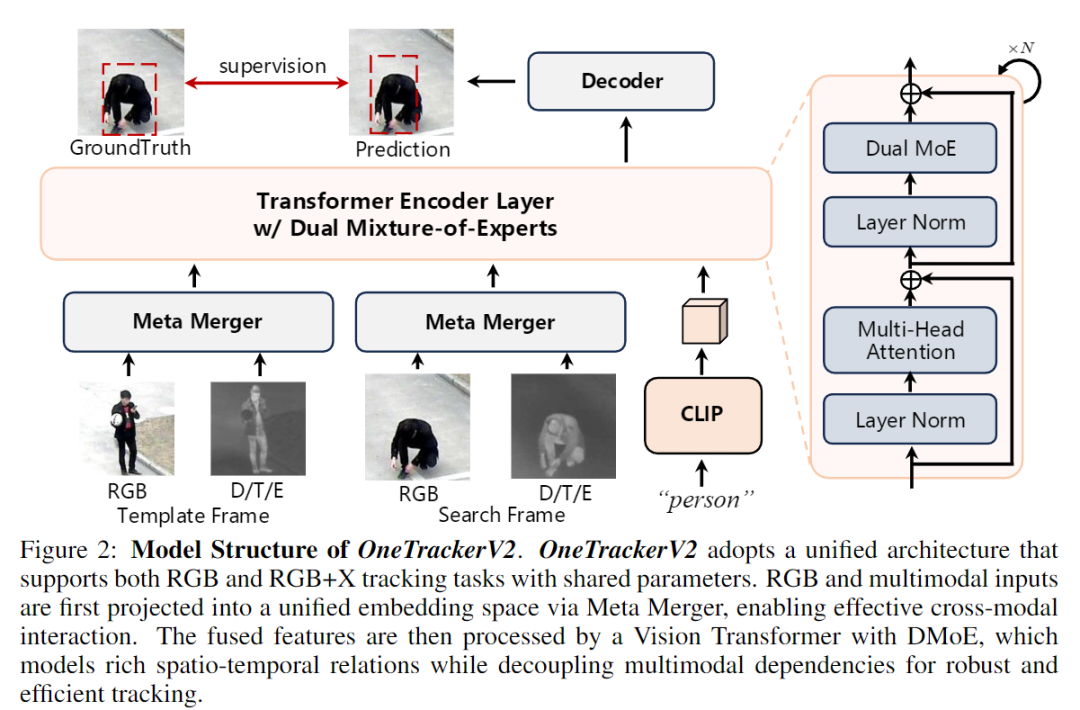
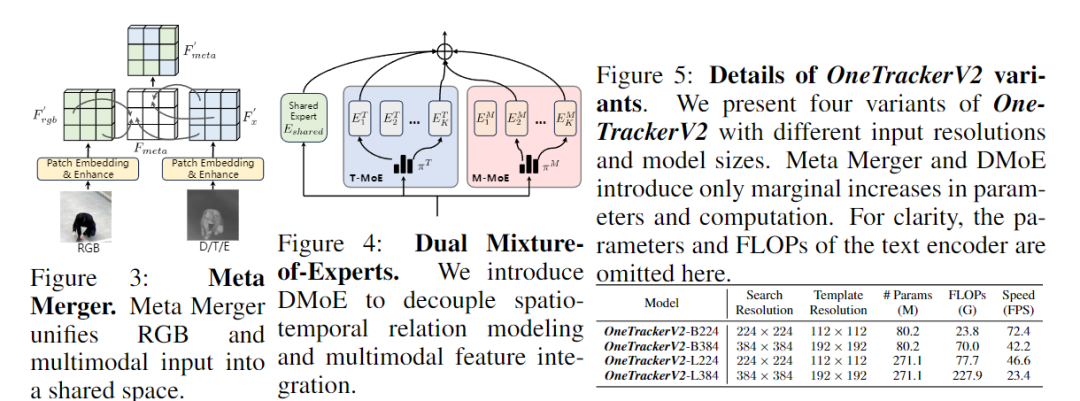
🔹 1. Meta Merger:模态融合中枢
Meta Merger 是一个轻量但高效的模态融合模块,用于将 RGB 与其他模态(Depth, Thermal, Event, Language)嵌入同一特征空间。
核心机制:
-
使用共享 Patch Embedding 统一输入结构;
-
通过 Spatial & Channel Attention 强调关键特征;
-
以 Meta Embedding 作为全局中介,实现跨模态交互与重分配。
优势包括:
-
Unified Modal Bridge:模态对齐无需手工规则;
-
Global Semantic Integration:提取全局一致语义;
-
Robust to Missing Modality:缺少模态时仍稳定运行;
-
Lightweight:仅增加 0.9% 参数与 0.4% FLOPs 。
🔹 2. DMoE:Dual Mixture-of-Experts 双专家机制
为进一步提升模型容量与泛化能力,作者提出 **DMoE (Dual Mixture-of-Experts)**:
-
T-MoE(Temporal-MoE):建模时空关系(spatio-temporal relations);
-
M-MoE(Multimodal-MoE):聚合多模态知识(multimodal knowledge) 。
这两个专家模块通过稀疏激活(sparse activation)提升模型表达能力,却几乎不增加计算量。 作者还设计了两项关键机制:
-
Expert Decoupling Loss:防止 T-MoE 与 M-MoE 学到重叠特征;
-
Router Cluster Regularization:让不同模态学习差异化专家分配,从而增强鲁棒性。
💡 "双专家结构"实现了跨模态解耦与高效融合,性能提升显著而代价极低。
三、实验结果:一套参数通吃五大任务 🏆
OneTrackerV2 在 5 个任务、12 个 benchmark 上全面超越现有方法。
📊 RGB Tracking
在 LaSOT、TrackingNet、GOT-10k 等基准上,OneTrackerV2 在 AUC / Precision / PNorm 上均超越 SOTA:
-
LaSOT AUC:76.1(相比 SUTrack 提升约 1%);
-
TrackingNet AUC:88.6(超越 ARTrackV2 与 ODTrack)。
🔥 RGB+X Tracking
在多模态任务上(Depth, Thermal, Event, Language),OneTrackerV2 同样领先:
-
DepthTrack F-score:67.5;
-
TNL2K AUC:69.5;
-
统一参数(Unified Param ✓)+ 单步训练(One-Step Training ✓)。
🚀 模型训练一次即可完成五类任务,仍超越分任务特化模型 。
⚙️ Missing Modality Robustness
在缺失模态测试(例如丢失 Thermal 或 Depth)下,OneTrackerV2 仍大幅领先:
-
F-score 提升 7.4 相比 SUTrack;
-
归功于 Meta Merger 的"中心式模态融合"策略,使模型具备模态自适应能力 。
四、优势与局限 ⚖️
✅ 优势
-
统一架构:一次训练适配所有模态;
-
双专家机制(DMoE):高效、解耦、可扩展;
-
强鲁棒性:可在模态缺失和压缩模型下保持高性能;
-
推理高效:压缩后模型仍达 159 FPS 。
⚠️ 局限
-
大规模训练成本较高;
-
对极端低光或语义模糊场景仍略有下降;
-
CLIP 编码器在语言模态中可能引入偏差。
🧭 一句话总结
OneTrackerV2 让目标跟踪从"任务专才"走向"多模态通才", 一次训练,统一架构,多模态适配,全面提升鲁棒性与可扩展性。