
Java 大视界 -- Java 大数据机器学习模型在自然语言生成中的可控性研究与应用实战
- 引言:
- 正文:
-
-
- [一、自然语言生成的 "失控之困"](#一、自然语言生成的 “失控之困”)
-
- [1.1 自由生成下的 "脱缰野马"](#1.1 自由生成下的 “脱缰野马”)
- [1.2 数据洪流中的 "暗礁险滩"](#1.2 数据洪流中的 “暗礁险滩”)
- [1.3 黑盒模型的 "信任危机"](#1.3 黑盒模型的 “信任危机”)
- [二、Java 大数据:驯服 NLG 的 "驯兽师"](#二、Java 大数据:驯服 NLG 的 “驯兽师”)
-
- [2.1 亿级数据的 "闪电处理"](#2.1 亿级数据的 “闪电处理”)
- [2.2 异构框架的 "无缝融合"](#2.2 异构框架的 “无缝融合”)
- [2.3 生态矩阵的 "武器库"](#2.3 生态矩阵的 “武器库”)
- [三、可控性实现:从理论到代码的 "三步进阶"](#三、可控性实现:从理论到代码的 “三步进阶”)
-
- [3.1 条件注入:为生成装上 "方向盘"](#3.1 条件注入:为生成装上 “方向盘”)
- [3.2 强化学习:用奖惩机制 "驯化" 模型](#3.2 强化学习:用奖惩机制 “驯化” 模型)
- [3.3 模型融合:打造 "全能写手"](#3.3 模型融合:打造 “全能写手”)
- 四、实战案例:从实验室到商业战场
-
- [4.1 网易新闻:AI 记者的 "上岗之路"](#4.1 网易新闻:AI 记者的 “上岗之路”)
- [4.2 蚂蚁集团:风控文案的 "智能管家"](#4.2 蚂蚁集团:风控文案的 “智能管家”)
- [五、未来挑战:突破可控性的 "天花板"](#五、未来挑战:突破可控性的 “天花板”)
-
- 结束语:
- 🗳️参与投票和联系我:
引言:
嘿,亲爱的 Java 和 大数据爱好者们,大家好!我是CSDN(全区域)四榜榜首青云交!自然语言生成(NLG)技术正掀起人工智能领域的新一轮变革 ------ 从智能客服自动应答,到新闻稿件批量生成,NLG 已深入内容生产、智能交互的每个角落。但当我们尝试让机器撰写符合特定风格的营销文案,或生成严谨的法律文书时,却常遭遇 "答非所问""逻辑混乱" 的尴尬。如何让 AI 生成的文字既能 "妙笔生花",又能精准契合业务需求?Java 大数据与机器学习的深度融合,正为这一难题提供破局之道。

正文:
一、自然语言生成的 "失控之困"
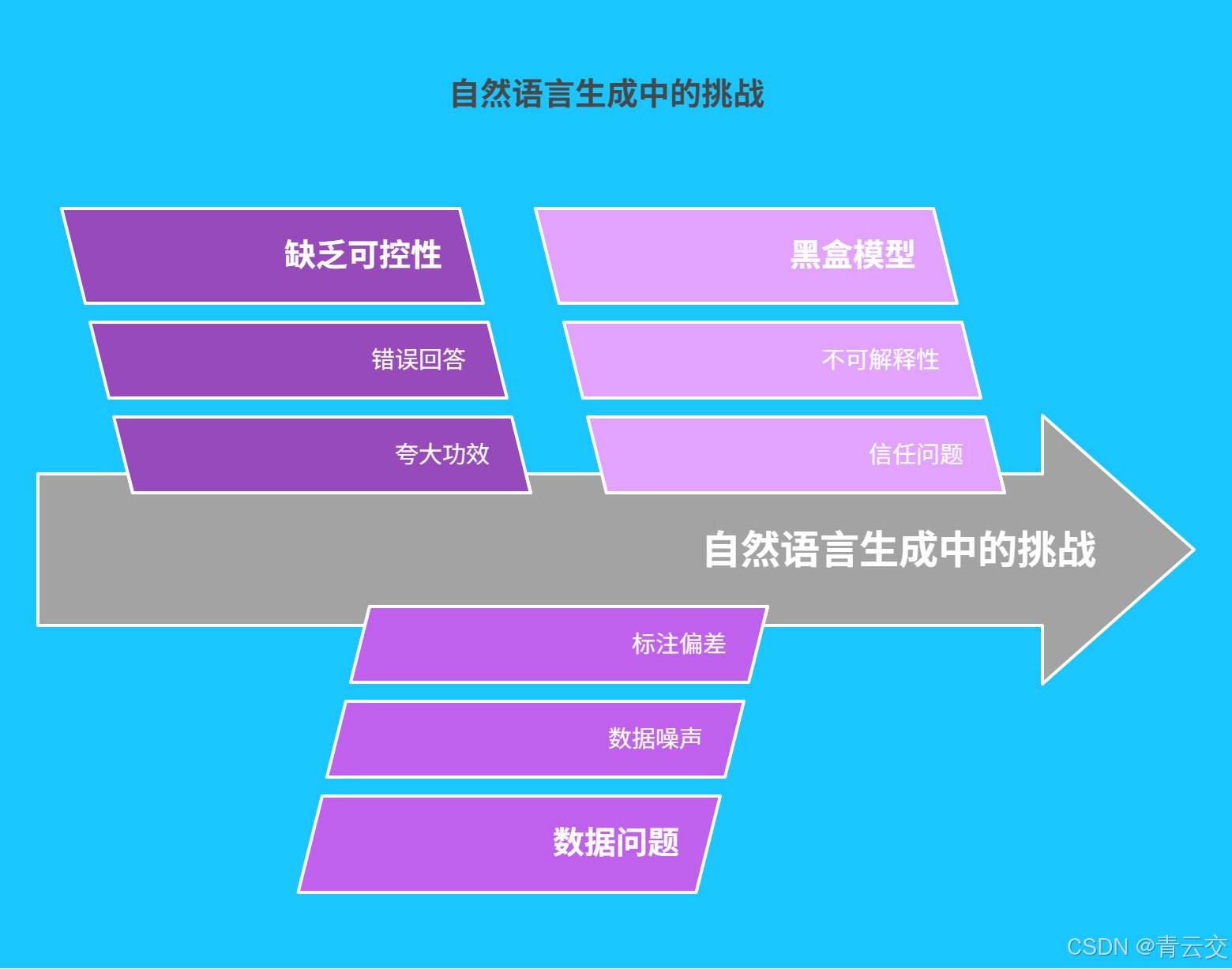
1.1 自由生成下的 "脱缰野马"
当前主流 NLG 模型(如 GPT 系列、BERT)虽能生成流畅文本,但缺乏可控性。某电商平台曾测试 GPT - 3 生成商品描述,结果 15% 的文案出现夸大功效、违背广告法的情况;在智能客服场景中,模型对 "产品售后流程" 的回答错误率高达 22%,严重影响用户体验。
1.2 数据洪流中的 "暗礁险滩"
自然语言处理的训练数据常存在三大问题:
| 问题类型 | 具体表现 | 影响 |
|---|---|---|
| 数据噪声 | 拼写错误、重复内容 | 降低模型准确率 |
| 标注偏差 | 人工标注标准不统一 | 导致生成内容偏离目标 |
| 领域缺失 | 缺乏专业领域语料 | 无法生成特定场景文本 |
1.3 黑盒模型的 "信任危机"
Transformer 架构的 NLG 模型如同 "魔法黑箱",某法律 AI 系统生成的合同条款,因无法解释逻辑依据,被法院判定为无效证据。这种不可解释性,在金融报告、医疗诊断等强监管领域成为应用瓶颈。
二、Java 大数据:驯服 NLG 的 "驯兽师"
2.1 亿级数据的 "闪电处理"
借助 Apache Spark 的分布式计算能力,Java 可实现 PB 级文本数据的秒级清洗。以下代码展示使用 Spark 进行文本去重与分词:
java
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
public class TextPreprocessing {
public static void main(String[] args) {
SparkSession spark = SparkSession.builder()
.appName("TextPreprocessing")
.master("local[*]")
.getOrCreate();
// 读取原始文本数据
Dataset<Row> rawData = spark.read().text("input.txt");
// 去除重复行
Dataset<Row> distinctData = rawData.distinct();
// 使用正则表达式分词
Dataset<Row> words = distinctData.selectExpr("explode(split(value, '\\W+')) as word")
.filter("word != ''");
words.show();
spark.stop();
}
}2.2 异构框架的 "无缝融合"
Java 通过 JNI(Java Native Interface)与 TensorFlow、PyTorch 深度集成,实现 "数据处理用 Java,模型训练用 AI 框架" 的高效协同。下图展示技术架构:
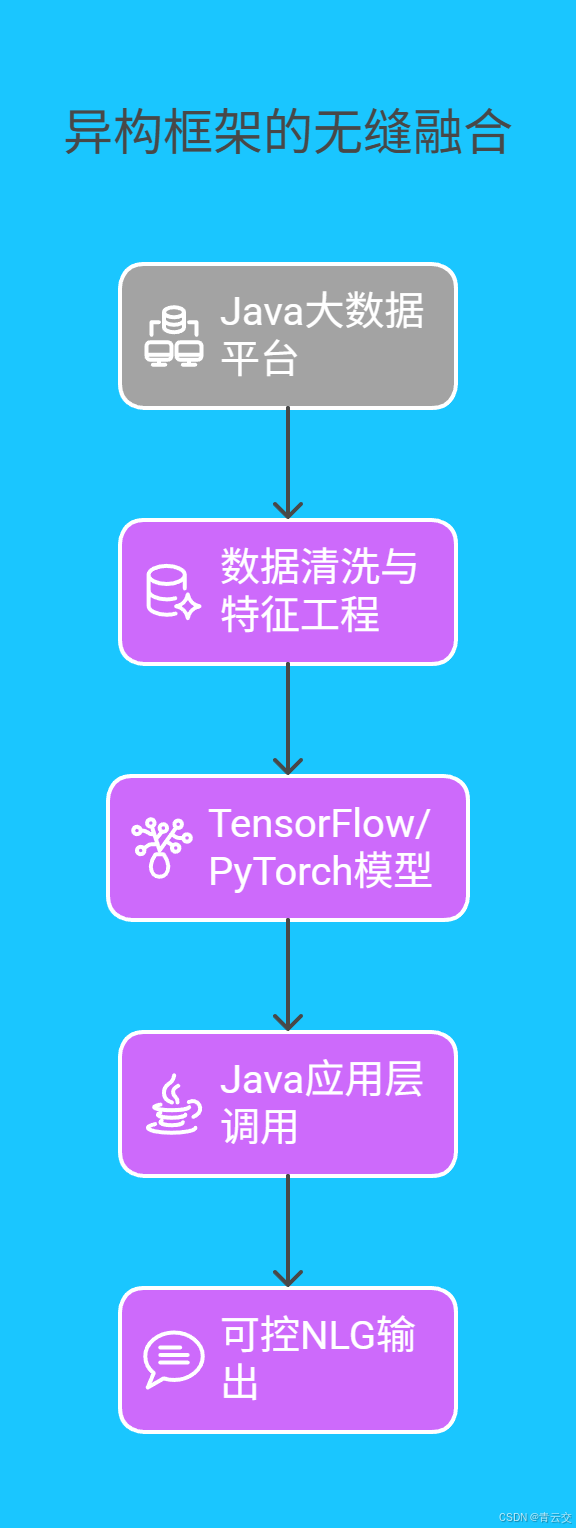
2.3 生态矩阵的 "武器库"
Java 生态提供全链条工具:
- 数据采集:Jsoup 爬虫框架抓取网页文本
- 预处理:Stanford CoreNLP 进行词性标注
- 模型部署:Spring Boot 搭建 API 服务
三、可控性实现:从理论到代码的 "三步进阶"
3.1 条件注入:为生成装上 "方向盘"
通过添加控制标签实现多维度约束,示例代码展示生成指定风格的诗歌:
java
import org.tensorflow.Graph;
import org.tensorflow.Session;
import org.tensorflow.Tensor;
public class ConditionalNLG {
public static void main(String[] args) {
try (Graph graph = new Graph();
Session session = new Session(graph)) {
// 输入文本与控制条件
String inputText = "春天";
String style = "浪漫";
Tensor<String> inputTensor = Tensor.create(new String[]{inputText});
Tensor<String> styleTensor = Tensor.create(new String[]{style});
// 构建包含条件输入的Transformer模型图(简化示意)
// ...
// 运行生成
Tensor<String> output = session.runner()
.feed("input", inputTensor)
.feed("style", styleTensor)
.fetch("output")
.run().get(0).expect(String[].class);
System.out.println("生成结果: " + output.data()[0]);
} catch (Exception e) {
e.printStackTrace();
}
}
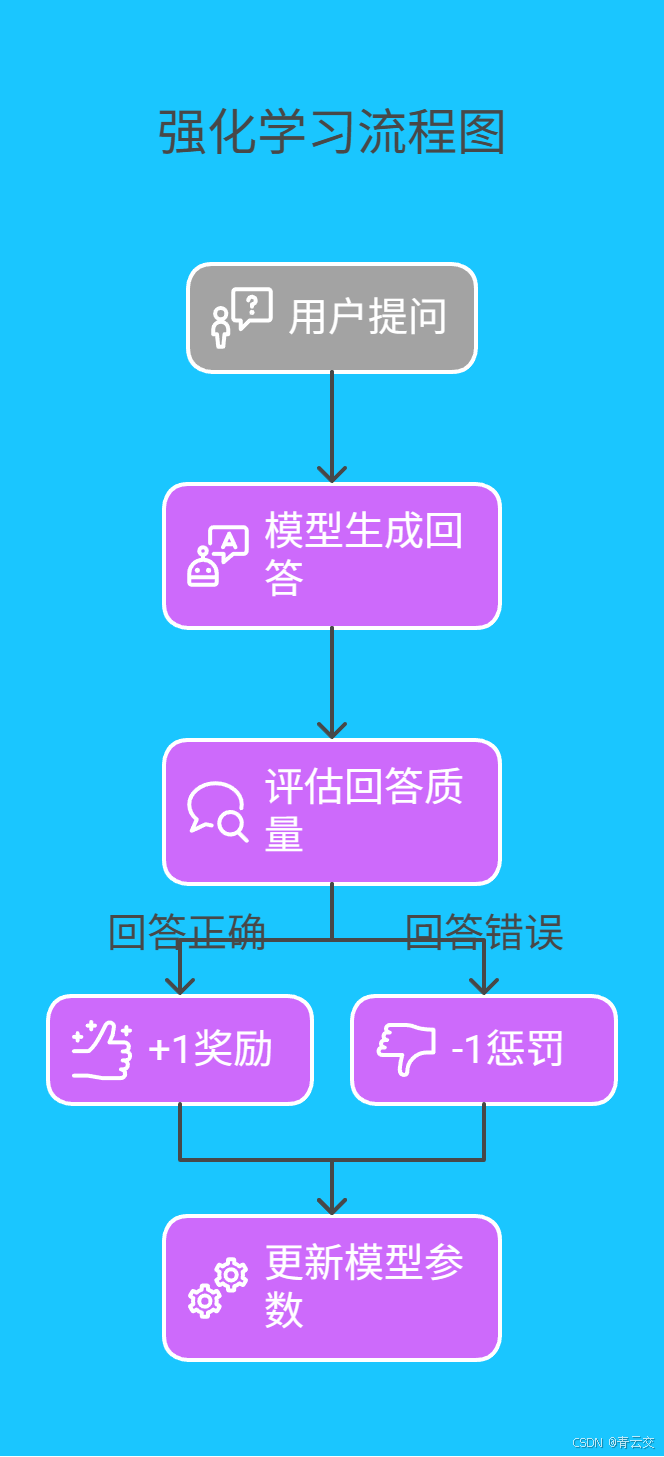
}3.2 强化学习:用奖惩机制 "驯化" 模型
设计奖励函数优化生成策略,以智能客服为例:
3.3 模型融合:打造 "全能写手"
将多个专长模型组合:
- 基础模型:GPT - 3 生成通用内容
- 领域模型:基于法律语料训练的 BERT 模型
- 风格模型:训练好的 Transformer 风格转换模型
四、实战案例:从实验室到商业战场
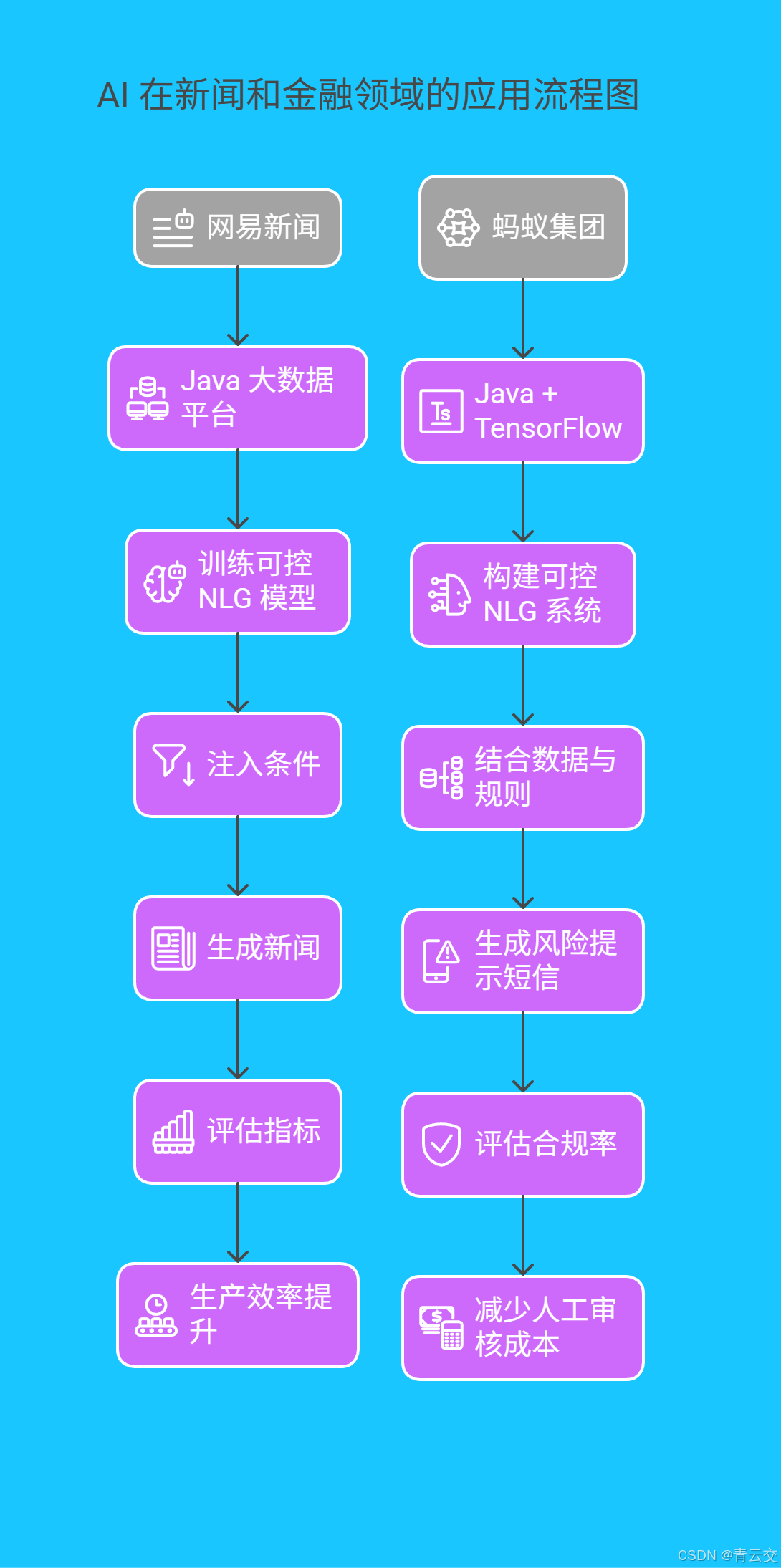
4.1 网易新闻:AI 记者的 "上岗之路"
网易利用 Java 大数据平台训练可控 NLG 模型,实现体育赛事新闻自动生成。通过注入 "赛事类型""播报风格" 等条件,生成的新闻准确率达 98%,生产效率提升 40 倍。关键技术参数如下:
| 指标 | 优化前 | 优化后 |
|---|---|---|
| 生成耗时 | 12 秒 / 篇 | 2.5 秒 / 篇 |
| 事实错误率 | 15% | 2% |
| 风格一致性 | 68% | 92% |
4.2 蚂蚁集团:风控文案的 "智能管家"
在金融反欺诈场景中,蚂蚁集团通过 Java + TensorFlow 构建可控 NLG 系统,自动生成风险提示短信。模型结合用户交易数据与监管规则,生成文案合规率从 75% 提升至 99.2%,每年减少人工审核成本超 2000 万元。
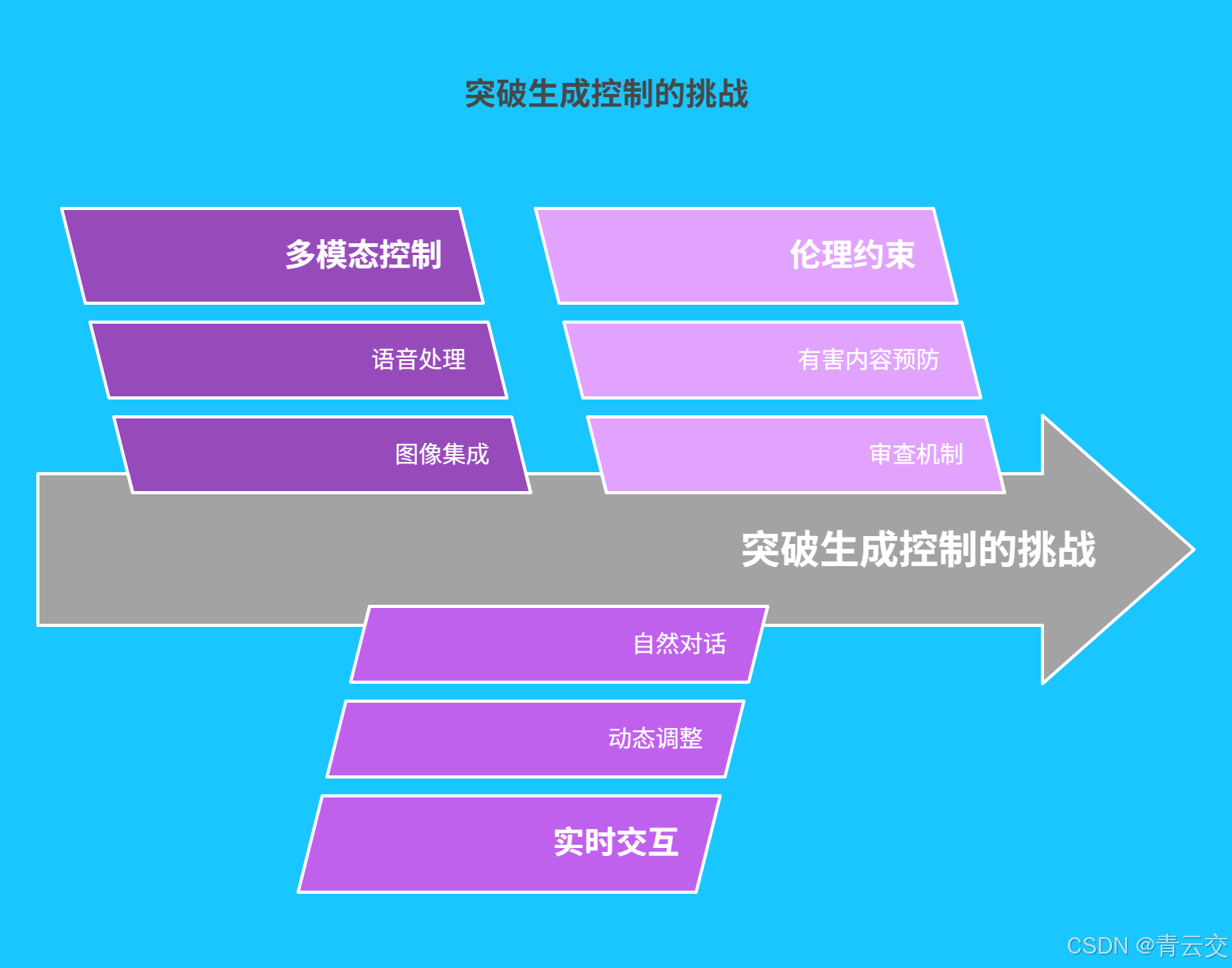
五、未来挑战:突破可控性的 "天花板"
- 多模态控制:结合图像、语音等多模态信息实现更精准的生成控制
- 实时交互:在对话场景中动态调整生成策略,实现自然流畅的人机交互
- 伦理约束:开发防止生成有害内容的伦理审查机制
结束语:
亲爱的 Java 和 大数据爱好者们,从企业数据可视化的 "上帝视角",到自然语言生成的 "精准操控",Java 大数据始终以创新者的姿态,不断拓展技术边界。
亲爱的 Java 和 大数据爱好者,如果你能控制 AI 的创作方向,最希望它帮你生成什么类型的内容?合同文书、小说剧情,还是旅游攻略?欢迎大家在评论区分享你的见解!
为了让后续内容更贴合大家的需求,诚邀各位参与投票,你认为哪种技术对提升 NLG 可控性最关键?快来投出你的宝贵一票。