大数据时代时序数据库选型指南:为何Apache IoTDB是最优解
-
- 一、时序数据库选型核心维度
-
- [1. 性能适配性](#1. 性能适配性)
- [2. 功能完备性](#2. 功能完备性)
- [3. 兼容性与扩展性](#3. 兼容性与扩展性)
- [4. 稳定性与可靠性](#4. 稳定性与可靠性)
- [5. 成本与维护性](#5. 成本与维护性)
- 二、国内外主流时序数据库对比
- [三、Apache IoTDB核心优势深度解析](#三、Apache IoTDB核心优势深度解析)
-
- [1. 架构设计:分层解耦,适配海量时序数据](#1. 架构设计:分层解耦,适配海量时序数据)
- [2. 极致性能:大数据量下的读写优化](#2. 极致性能:大数据量下的读写优化)
- [3. 功能完备:贴合业务的全生命周期管理](#3. 功能完备:贴合业务的全生命周期管理)
- [4. 无缝兼容:适配复杂IT架构](#4. 无缝兼容:适配复杂IT架构)
- [5. 稳定可靠:企业级高可用保障](#5. 稳定可靠:企业级高可用保障)
- [6. 易用易维护:降低全生命周期成本](#6. 易用易维护:降低全生命周期成本)
- 四、IoTDB部署与升级实践
-
- [1. 环境配置优化](#1. 环境配置优化)
- [2. 版本升级指南](#2. 版本升级指南)
- [3. 语法兼容示例](#3. 语法兼容示例)
- 五、选型建议与总结
在物联网、工业互联网、金融风控等领域的爆发式增长下,时序数据呈现指数级增长态势。这类数据具有高写入、高查询、强时序关联、生命周期长等特性,传统关系型数据库难以承载,时序数据库(Time Series Database, TSDB)应运而生。面对市面上众多的时序数据库产品,如何结合业务场景与技术特性选型,成为企业数字化转型的关键命题。

下载链接:https://iotdb.apache.org/zh/Download/
企业版官网链接:https://timecho.com
一、时序数据库选型核心维度
时序数据库的选型需围绕业务需求与技术特性双向匹配,核心需关注以下五大维度,其权重分布与决策逻辑可通过下图清晰呈现:
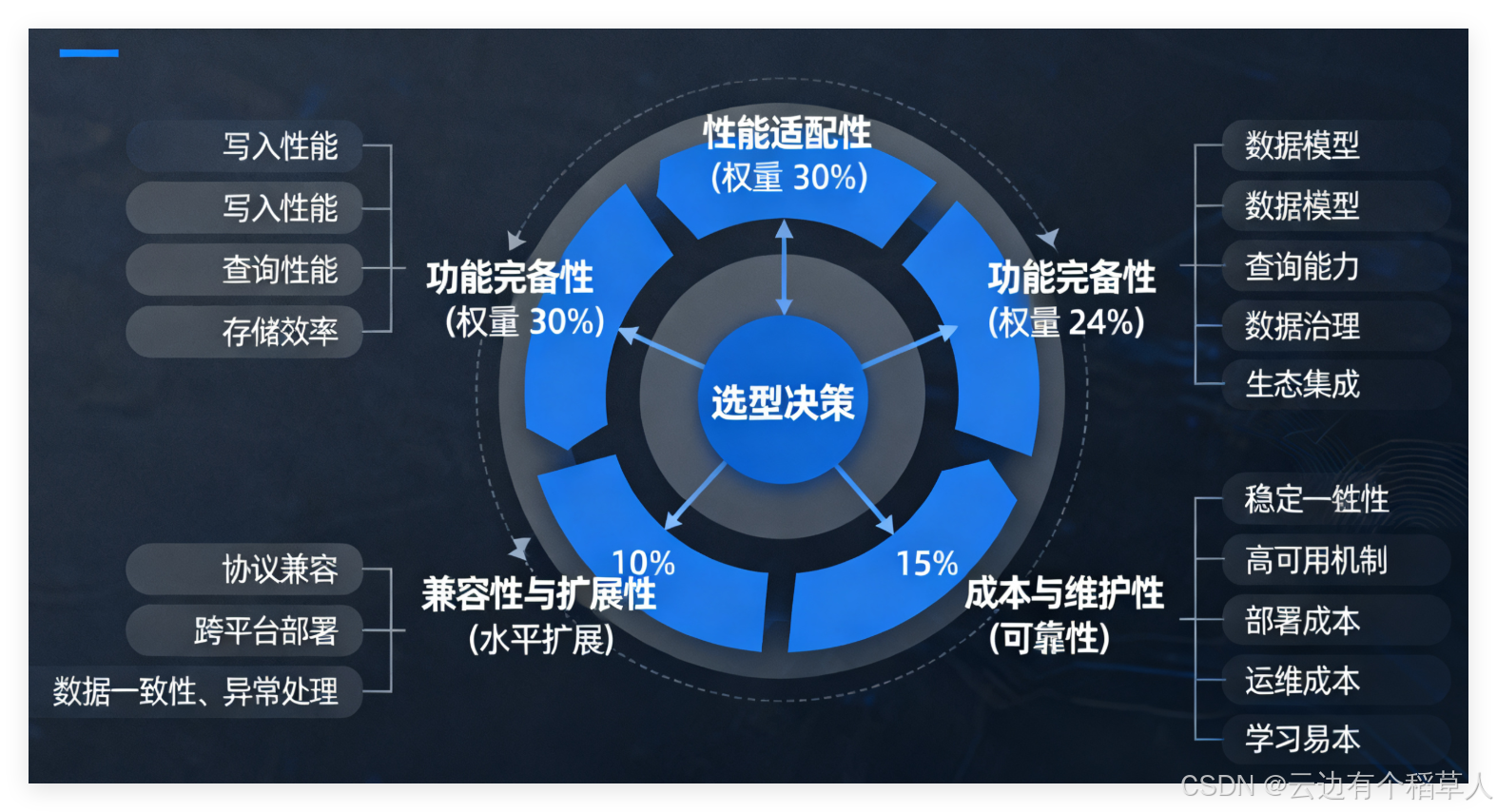
1. 性能适配性
时序数据的核心诉求是高吞吐写入与低延迟查询。大数据场景下,单集群需支撑每秒十万级甚至百万级数据写入,同时满足毫秒级时序聚合、区间查询等操作。选型时需重点考察:
- 写入性能:是否支持批量写入、异步写入,能否适配高并发场景。
- 查询性能:对时间窗口聚合、多维度过滤、降采样等操作的响应速度。
- 存储效率:是否支持数据压缩、分层存储,降低海量数据存储成本。
2. 功能完备性
完备的功能体系是时序数据库支撑复杂业务的基础,关键功能包括:
- 数据模型:是否支持灵活的设备-指标层级模型,适配多维度时序数据管理。
- 查询能力:是否兼容SQL标准,支持时序特有的插值、聚合、窗口函数。
- 数据治理:是否提供数据生命周期管理、自动过期删除、冷热数据分离等功能。
- 生态集成:能否与大数据生态(Hadoop、Spark)、可视化工具(Grafana)无缝对接。
3. 兼容性与扩展性
企业IT架构往往复杂多样,选型时需关注:
- 协议兼容:是否支持MQTT、HTTP、JDBC等主流接入协议,降低设备接入成本。
- 跨平台部署:能否支持单机、集群、云原生等多种部署模式。
- 水平扩展:集群扩容时是否无需停机,能否线性提升处理能力。
4. 稳定性与可靠性
时序数据的连续性与完整性至关重要,需考察:
- 高可用机制:是否支持主从复制、故障自动转移,避免单点故障。
- 数据一致性:集群部署下能否保证数据读写一致性。
- 异常处理:面对网络抖动、设备离线等情况的容错能力。
5. 成本与维护性
技术选型需兼顾长期运营成本,包括:
- 部署成本:是否开源免费,降低license费用支出。
- 运维成本:配置是否简洁,是否提供完善的监控、告警工具。
- 学习成本:文档是否齐全,社区是否活跃,问题解决效率如何。
二、国内外主流时序数据库对比
当前市场上主流的时序数据库可分为国外开源产品(如InfluxDB、Prometheus)与国内开源产品(以Apache IoTDB为代表),其核心特性对比如下:
| 产品特性 | Apache IoTDB | InfluxDB | Prometheus |
|---|---|---|---|
| 开源协议 | Apache 2.0 | MIT(开源版)/商业版 | Apache 2.0 |
| 写入性能 | 百万级/秒(单节点) | 十万级/秒(单节点) | 十万级/秒(单节点) |
| 存储压缩比 | 10:1~20:1 | 5:1~10:1 | 3:1~5:1 |
| SQL兼容性 | 完全兼容SQL标准 | 自定义InfluxQL | PromQL(非SQL) |
| 数据模型 | 树形层级模型(设备-指标) | 时序标签模型 | 指标-标签键值对 |
| 生态集成 | 支持Hadoop、Spark、Grafana等 | 支持Grafana,生态较单一 | 与K8s生态深度集成 |
| 部署模式 | 单机/集群/云原生 | 单机/集群(商业版) | 单机/联邦集群 |
| 中文支持 | 原生支持中文标识符、中文文档 | 有限支持 | 不支持中文标识符 |
| 高可用 | 集群主从复制、故障自动转移 | 商业版支持集群高可用 | 需依赖外部组件(如Thanos) |
| UDF支持 | 完善的UDF框架,独立模块设计 | 有限支持 | 不支持自定义UDF |
从对比可见,Apache IoTDB在写入性能、存储效率、SQL兼容性和中文支持上具有显著优势,尤其适配国内企业的技术栈与业务场景;而InfluxDB和Prometheus在特定场景(如K8s监控)有其专长,但在大数据量处理、功能完备性和企业级高可用支持上存在短板。
三、Apache IoTDB核心优势深度解析
Apache IoTDB是 Apache 顶级开源项目,专为物联网时序数据设计,其架构设计与技术特性完美契合大数据场景下的选型需求。
1. 架构设计:分层解耦,适配海量时序数据
IoTDB 采用分层架构设计,从下至上分为存储层、查询层、接口层与工具层,各层职责清晰、松耦合,确保系统的扩展性与可维护性。
- 存储层:负责数据的持久化存储与压缩,支持列存储、时间分区、冷热数据分离,适配不同存储介质(内存、SSD、HDD)。
- 查询层:提供SQL解析、优化与执行,支持时序特有的查询优化(如时间范围剪枝、设备索引过滤),确保低延迟查询。
- 接口层:提供多协议接入与生态集成接口,包括JDBC、MQTT、Thrift、HTTP等,适配各类设备与大数据组件。
- 工具层:包含数据导入导出、备份恢复、监控告警等工具,降低运维成本。
2. 极致性能:大数据量下的读写优化
IoTDB 针对时序数据特性进行深度优化,在高并发写入与复杂查询场景下表现突出:
- 写入优化:采用批量写入、异步刷盘、写前日志(WAL)等机制,单节点可轻松支撑百万级/秒数据写入,集群模式下性能线性扩展。
- 存储优化:结合时序数据的时间局部性与值相关性,支持LZ4、SNAPPY、GZIP等多种压缩算法,实现10:1~20:1的超高压缩比,大幅降低存储成本。
- 查询优化:通过时间索引、设备索引、预聚合索引等技术,毫秒级响应复杂查询,支持千万级设备的并发查询。
以下为IoTDB批量写入的Java代码示例,通过Session接口实现高效数据写入:
java
// 初始化IoTDB Session
Session session = new Session("127.0.0.1", 6667, "root", "root");
session.open();
// 设备ID与测量指标
String deviceId = "root.sg.factory.device1";
List<String> measurements = Arrays.asList("temperature", "humidity", "pressure");
List<TSDataType> dataTypes = Arrays.asList(TSDataType.DOUBLE, TSDataType.DOUBLE, TSDataType.FLOAT);
// 批量写入数据(1000条记录)
long startTime = System.currentTimeMillis();
for (int i = 0; i < 1000; i++) {
long time = startTime + i;
List<Object> values = Arrays.asList(25.5 + Math.random() * 5, 60 + Math.random() * 20, 101325 + Math.random() * 1000);
session.insertRecord(deviceId, time, measurements, dataTypes, values);
}
// 关闭Session
session.close();
System.out.println("批量写入1000条数据完成");3. 功能完备:贴合业务的全生命周期管理
IoTDB 提供从数据采集、存储、查询到分析的全链路功能支持,满足复杂业务需求:
-
灵活数据模型:采用树形层级结构(root.sg.device.measurement),天然适配设备-指标的管理模式,支持多维度标签扩展,如下列SQL所示:
sql-- 创建带标签的时间序列 create timeseries root.sg.device1.temperature with datatype=DOUBLE, encoding=PLAIN, tags=("location"="factoryA", "type"="airconditioner"); -
标准SQL支持:完全兼容SQL-92标准,支持时序特有的窗口函数、插值函数、聚合函数,降低开发学习成本。以下为时序聚合查询示例:
sql-- 按5分钟窗口聚合查询温度数据(平均值、最大值、最小值) select avg(temperature), max(temperature), min(temperature) from root.sg.device1 where time >= 1690000000000 and time <= 1690003600000 group by time(5m); -
数据治理能力:支持数据TTL(生存时间)自动过期删除、冷热数据分层存储,优化存储资源分配。通过以下SQL配置数据TTL:
sql-- 配置root.sg下所有时间序列的TTL为30天 alter database root.sg set ttl=30d;
4. 无缝兼容:适配复杂IT架构
IoTDB 提供丰富的接口与协议支持,轻松融入现有技术栈:
- 多协议接入:支持MQTT、HTTP、JDBC、ODBC、Thrift等主流协议,适配各类物联网设备与大数据组件。
- 生态深度集成:与Hadoop、Spark、Flink等大数据框架无缝对接,支持时序数据的离线分析与实时计算;提供Grafana连接器与插件,快速实现数据可视化。以下为IoTDB集成Grafana的配置步骤:
- 下载IoTDB Grafana插件并解压至Grafana插件目录。
- 重启Grafana服务,在数据源中添加IoTDB,配置连接信息(地址、端口、用户名、密码)。
- 在仪表盘创建面板,通过SQL查询时序数据并可视化展示。
- 跨平台部署:支持Linux、FreeBSD、Darwin等操作系统,可部署于单机、集群、容器、云环境,满足不同场景需求。
5. 稳定可靠:企业级高可用保障
IoTDB 具备完善的高可用机制,确保数据连续性与完整性:
-
集群高可用:支持主从复制、分区容错,集群节点故障时自动切换,无单点故障风险。IoTDB集群部署架构如下图所示:
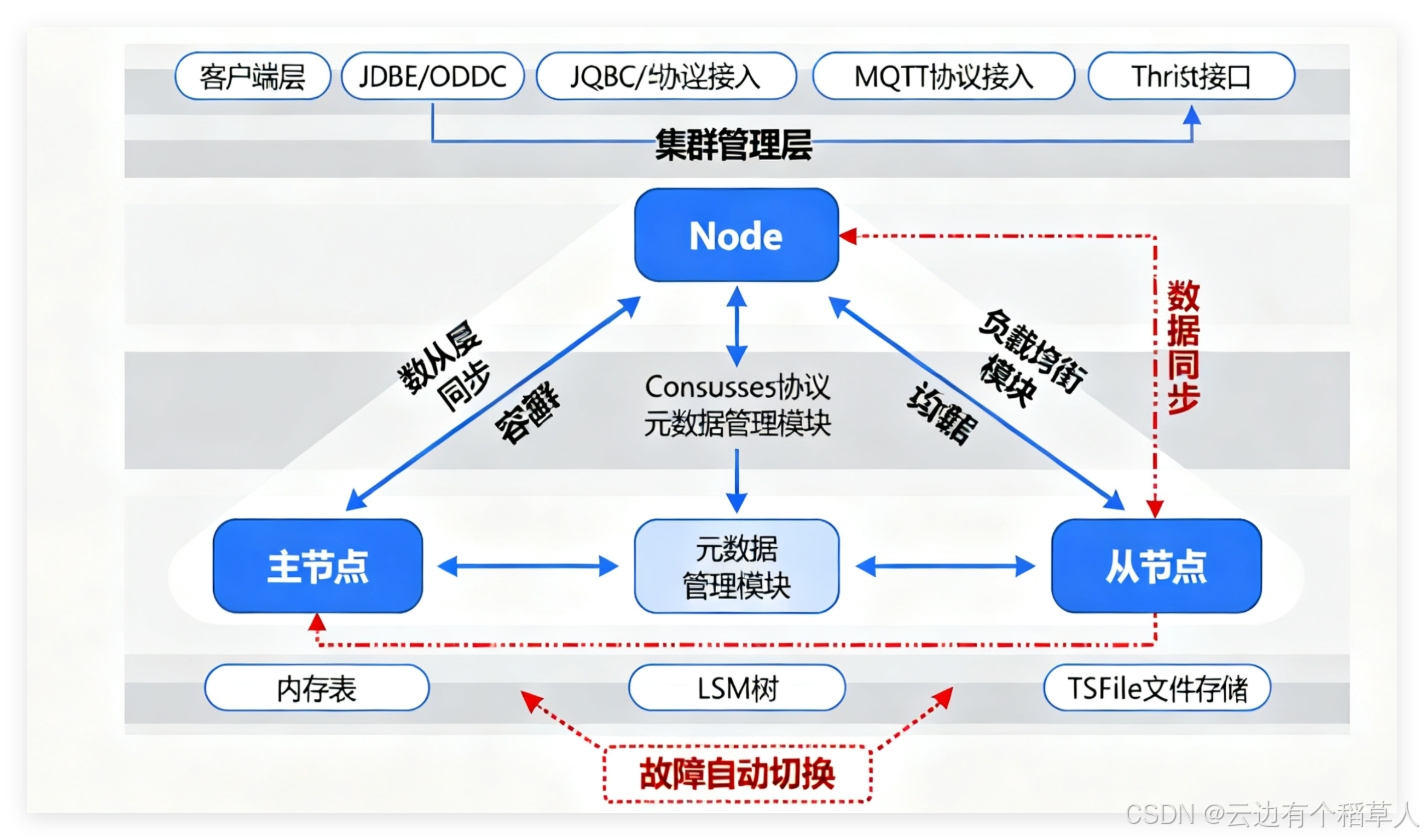
-
数据一致性:采用MVCC机制,保证集群环境下的数据读写一致性,支持事务ACID特性。
-
容错能力:支持数据备份与恢复,面对网络中断、设备离线等异常情况,可通过缓存机制保障数据不丢失。以下为IoTDB数据备份与恢复的命令行示例:
bash# 数据备份(备份root.sg下所有数据至指定目录) ./iotdb backup -d /data/iotdb/backup -p root.sg # 数据恢复(从备份目录恢复数据至IoTDB) ./iotdb restore -d /data/iotdb/backup -p root.sg
6. 易用易维护:降低全生命周期成本
IoTDB 注重用户体验,提供简洁的部署与运维方案:
-
轻量化部署:单节点安装包仅数十MB,启动快速,资源占用低。
-
简洁配置:核心配置参数清晰明了,支持动态配置调整,无需重启服务。以下为修改存储配置的示例:
sql-- 动态修改内存表大小为2GB set system memory_table_size=2147483648; -
完善文档与社区:提供中文官方文档、详细教程与示例代码,社区响应迅速,问题解决效率高。
四、IoTDB部署与升级实践
1. 环境配置优化
为确保IoTDB在高负载场景下稳定运行,需修改操作系统参数,避免连接数不足导致的异常:
bash
# Linux系统设置最大连接数(永久生效)
sudo echo "net.core.somaxconn=65535" >> /etc/sysctl.conf
sudo sysctl -p
# FreeBSD或Darwin系统设置最大连接数(永久生效)
sudo echo "kern.ipc.somaxconn=65535" >> /etc/sysctl.conf
sudo sysctl -p2. 版本升级指南
IoTDB 提供完善的版本升级方案,不同版本间升级流程清晰。
-
小版本升级(如1.0.0→1.0.5):直接下载新版本,同步配置文件,停止旧进程后启动新版本即可,数据完全兼容。
-
跨大版本升级(如0.13.x→1.0.x):需通过LOAD功能导入旧版本数据,同时适配SQL语法与UDF API的变更。以下为UDF API适配的代码示例:
java// 0.13.x版本UDF代码 import org.apache.iotdb.tsfile.utils.Binary; import org.apache.iotdb.tsfile.file.metadata.enums.TsDataType; public class OldUDFExample { public Binary process(TsDataType type, Binary value) { return value; } } // 1.0.x版本UDF代码(API变更适配) import org.apache.iotdb.udf.api.type.Binary; import org.apache.iotdb.udf.api.type.Type; public class NewUDFExample { public Binary process(Type type, Binary value) { return value; } } -
跨多版本升级(如0.10.x→0.13.x):支持逐步升级,每个版本均提供自动数据格式转换工具,升级过程中可正常查询与写入。
3. 语法兼容示例
IoTDB 1.0版本对SQL语法进行了优化,提升了易用性与一致性,以下为关键语法变更对比:
sql
-- 旧版本(0.13.x)创建含特殊字符的时间序列
create root.sg.'www.baidu.com' with datatype=BOOLEAN, encoding=PLAIN;
-- 查询该时间序列
select 'www.baidu.com' from root.sg;
-- 新版本(1.0.x)创建含特殊字符的时间序列(统一使用反引号)
create root.sg.`www.baidu.com` with datatype=BOOLEAN, encoding=PLAIN;
-- 新版本查询该时间序列
select `www.baidu.com` from root.sg;
-- 新版本支持路径结点名中直接使用单双引号(无需转义)
create root.sg.`a"b'c` with datatype=TEXT, encoding=PLAIN;
select `a"b'c` from root.sg;五、选型建议与总结
时序数据库的选型需立足业务实际,结合数据规模、查询需求、部署环境等因素综合判断:
- 若聚焦物联网、工业互联网等场景,需处理百万级设备接入与海量时序数据,Apache IoTDB是最优选择,其极致性能、完备功能、中文生态与企业级高可用保障可大幅降低落地成本。
- 若专注于监控场景(如K8s监控),数据量适中且以简单聚合查询为主,可选择Prometheus,但需注意其在大数据量存储与复杂查询上的局限性。
- 若需快速原型验证,对存储效率要求不高,InfluxDB开源版可作为临时方案,但长期使用需考虑商业版的license成本。

Apache IoTDB 作为国内自主研发的顶级开源时序数据库,在大数据场景下的性能、兼容性与易用性上均表现突出,已在能源、制造、交通、金融等多个行业大规模落地。其持续迭代的版本与活跃的社区生态,为企业提供了长期可靠的技术支撑。