树型结构
树是一种非线性的数据结构,它是由n(n>=0)个有限节点组成一个具有层次关系的集合 。把它叫做树是因为它看起来像一棵倒挂的树 ,也就是说它是根朝上,而叶朝下的。它具有以下的特点:
- 有一个特殊的节点,称为根节点,根结点没有前驱节点
- 除根节点外,其余节点被分成M(M > 0)个互不相交的集合T1、T2、......、Tm,其中每一个集合Ti (1 <= i <= m) 又是一棵与树类似的子树。每棵子树的根节点有且只有一个前驱,可以有0个或多个后继节点
- 树是递归定义的。

注意:
- 树形结构中,子树之间不能有交集/相交,否则就不是树形结构
- 除了根节点外,每个节点有且只有一个父节点
- 一棵N 个节点的树有 N-1条边
重要概念
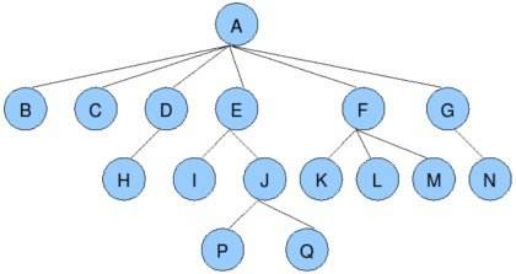
节点的度:一个节点含有子树的个数称为该节点的度; 如上图:A的度为6
树的度 :一棵树中,++所有结点度的最大值++称为树的度; 如上图:树的度为6
叶子节点或终端节点 :++度为0的节点++称为叶节点; 如上图:B、C、H、I...等节点为叶节点
双亲节点或父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点; 如上图:A是B的父节点
孩子节点或子节点:一个节点含有的子树的根节点称为该节点的子节点; 如上图:B是A的孩子节点
根节点:一棵树中,没有双亲节点的节点;如上图:A
节点的层次:从根开始定义起,根为第1层,根的子结点为第2层,以此类推
树的高度或深度:树中节点的最大层次; 如上图:树的高度为4
非终端节点或分支节点:度不为0的节点; 如上图:D、E、F、G...等节点为分支节点
兄弟节点:具有相同父节点的节点互称为兄弟节点; 如上图:B、C是兄弟节点
堂兄弟节点:双亲在同一层的节点互为堂兄弟;如上图:H、I互为堂兄弟节点
节点的祖先:从根到该节点所经分支上的所有节点;如上图:A是所有节点的祖先
子孙:以某节点为根的子树中任一节点都称为该节点的子孙。如上图:所有节点都是A的子孙
森林:由m(m>=0)棵互不相交的树组成的集合称为森林
树的表示形式
树的结构相对线性表比较复杂,树的存储表示方式有:双亲表示法、孩子表示法、孩子双亲表示法、孩子兄弟表示法等,这里我们简单了解常用的方法:孩子兄弟表示法。
java
static class Node {
public int val;//树中存储的数据
public Node firstChild;//第一个孩子的引用
public Node nextBrother;//下一个兄弟的引用
}示例:
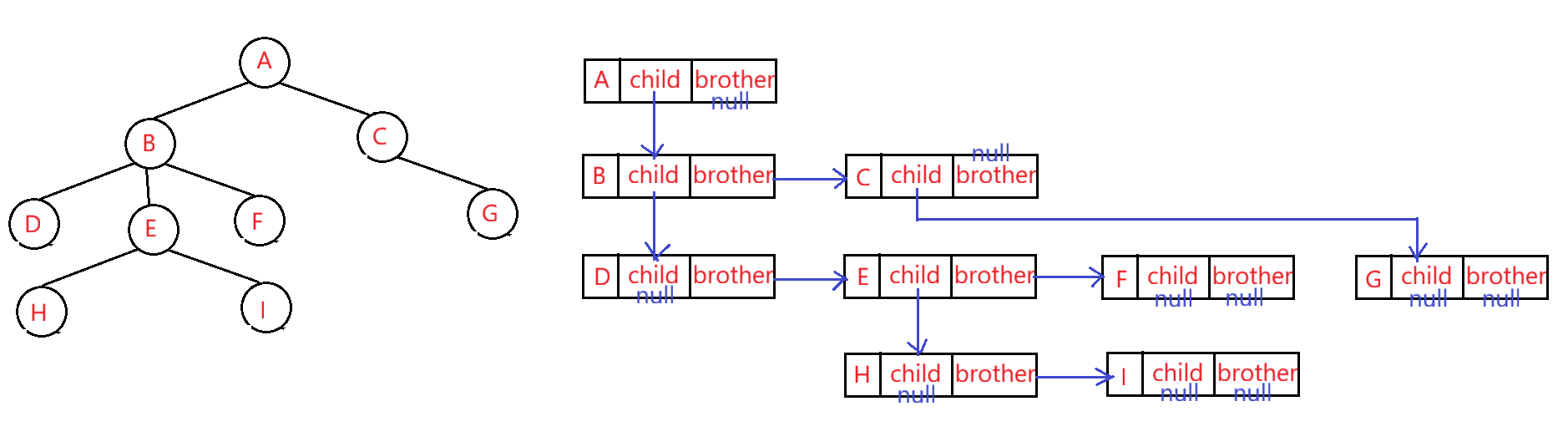
树一般应用在 文件系统管理(目录和文件)。
二叉树
一棵二叉树是节点的一个有限集合,该集合:
- 或者为空
- 或者是由一个根节点加上两棵别称为左子树和右子树的二叉树组成。
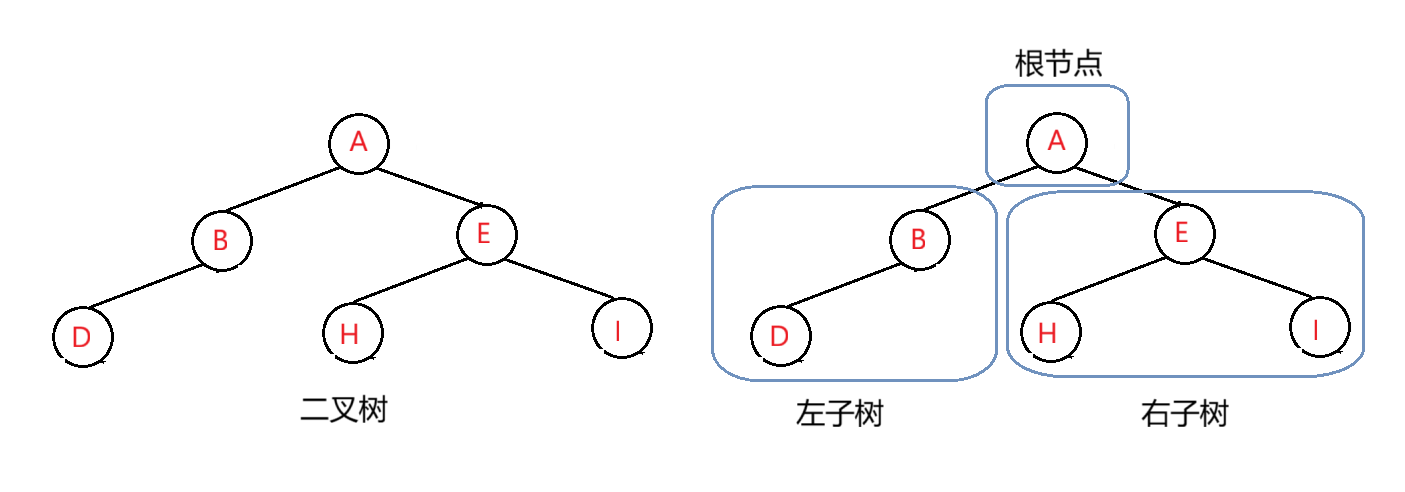
从上图可以看出:
- 二叉树不存在度大于2的节点
- 二叉树的子树有左右之分,次序不能颠倒,因此二叉树是有序树
注意:对于任意的二叉树都是由以下几种情况复合而成的:
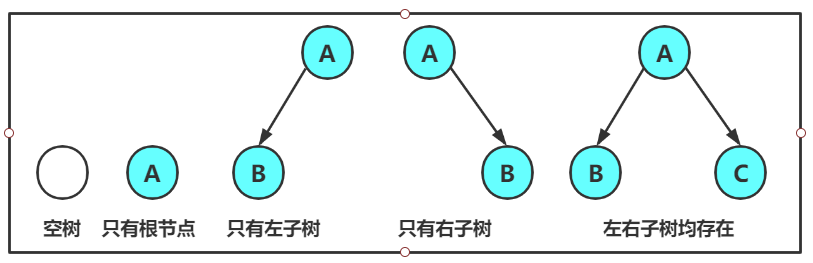
两种特殊的二叉树
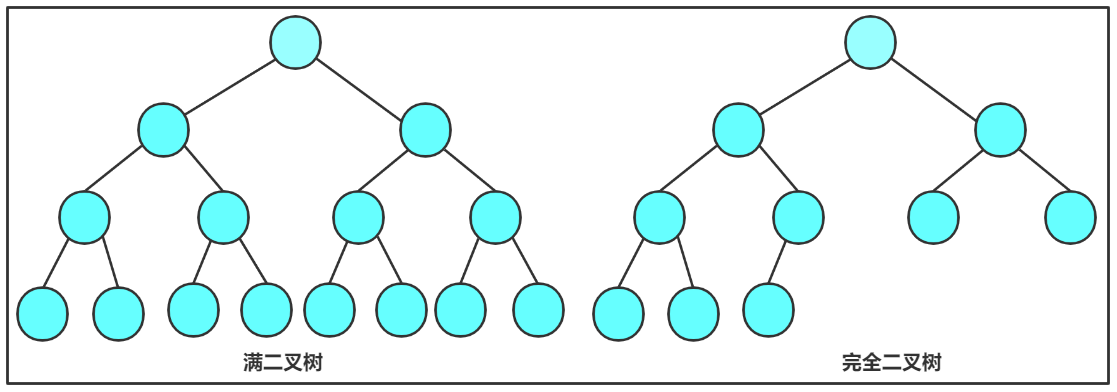
- 满二叉树: 一棵二叉树,如果每层的节点数都达到最大值 ,则这棵二叉树就是满二叉树。也就是说,如果一棵二叉树的层数为K,且节点总数是
,则它就是满二叉树。
- 完全二叉树:完全二叉树是效率很高的数据结构,完全二叉树是由满二叉树而引出来 的。对于深度为K的,有n个结点的二叉树,当且仅当其每一个节点都与深度为K的满二叉树中编号从0至n-1的结点一一对应时称之为完全二叉树(核心特征是除了最后一层,其他层都是满的,并且最后一层的节点都紧靠左边 )。 要注意的是满二叉树是一种特殊的完全二叉树。
二叉树的特性
- 若规定根节点的层数为1 ,则一棵非空二叉树的第 i 层上最多有
- 若规定只有根节点的二叉树的深度为1 ,则深度为K的二叉树的最大节点数是
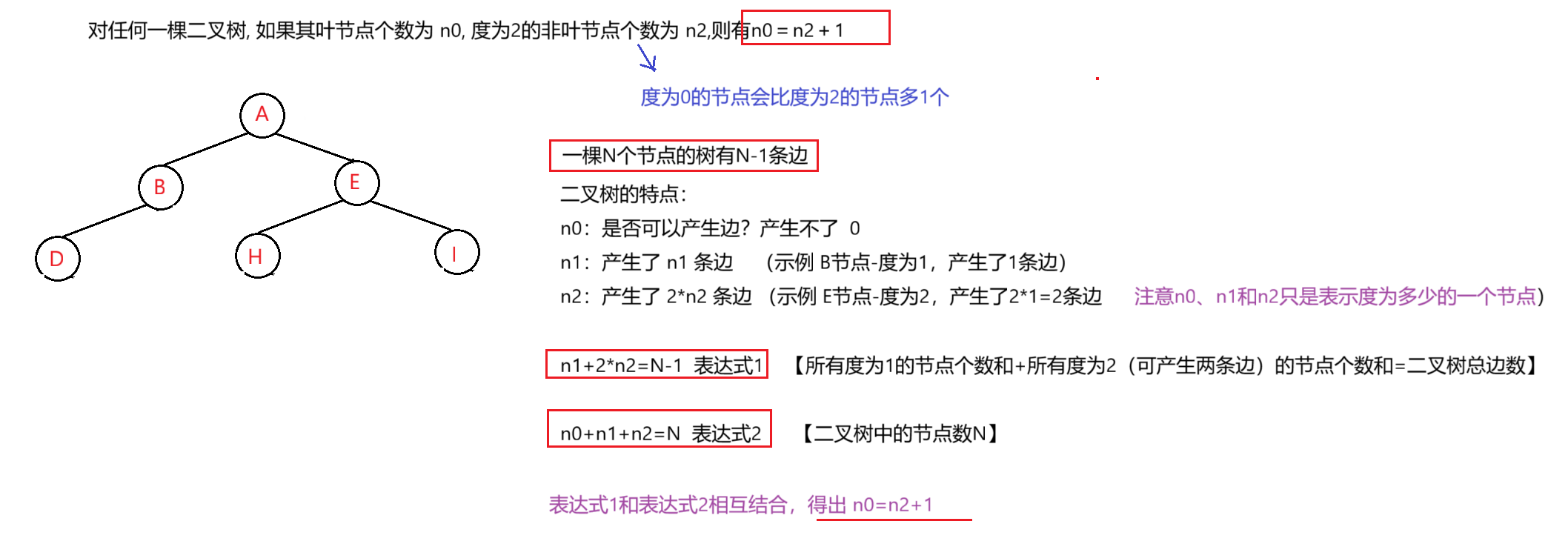
- 对任何一棵二叉树, 如果其叶节点个数为 n0 , 度为2的非叶节点个数为 n2 ,则有n0=n2+1
- 具有n个结点的完全二叉树的深度k为
- 对于具有n个节点的完全二叉树,如果按照从上至下从左至右 的顺序对所有节点从0开始编号,则对于序号为 i 的节点有:
- 若 i>0,双亲序号:(i-1)/2 ;i=0,i为根结点编号,无双亲结点
- 若2i+1<n,左孩子序号:2i+1,否则无左孩子
- 若2i+2<n,右孩子序号:2i+2,否则无右孩子
解释为何 对任何一棵二叉树, 如果其叶节点个数为 n0 , 度为2的非叶节点个数为 n2 ,则有n0=n2+1这一条公式?
------------ 上述的话简单来说,就是 度为0的节点会比度为2的节点多1个 。
公式的推导:
前面我们说过一棵N个节点的树有N-1条边,那么在二叉树的节点中,
- 度为0的节点n0 是产生不了边的
- 度为1的节点n1 可以产生 n1 条边
- 度为2的节点n2 可以产生 2*n2 条边
- 将所有的n1节点和n2节点的产生的边相加,就得到了一棵二叉树的边数,即 n1+2*n2=N-1
- 而二叉树的所有节点数是所有n0、n1和n2节点的和,即 n0+n1+n2=N
- 结合上述的两条表达式,最终九得出了公式 n0=n2+1
例题练习
1. 某二叉树共有 399 个结点,其中有 199 个度为 2 的结点,则该二叉树中的叶子结点数为( )
分析:由 n=n0+n1+n2 得出,399=n0+n1+199 ------> n0+n1=200
又有 n-1=n1+2*n2 ------> 398=n1+2*199=n1+398 ------> n1=0
代入得出,**n0=200-0=200 ,**即叶子节点数等于200。
总结:如果二叉树中的节点数是奇数 ,那么度为1的节点n1=0,二叉树的节点数n=n0+n2。
2.在具有 2n 个结点的完全二叉树中,叶子结点个数为( )
分析:由第一道题的分析,我们可以知道,此时的二叉树中节点数为偶数,也就是该完全二叉树中,从上到下从左到右最后一个子树只有一个节点,这也是唯一一个度为1的节点,所以n1=1。
由 2n=n0+n1+n2 得出 ------> 2n=n0+1+n2 ------> 2n-1=n0+n2
又有 n0=n2+1 ------> 2n-1=n0+n0-1 ------> 2n=2n0 ------> n=n0 ,即叶子节点的个数为n。
总结:如果二叉树中的节点数是偶数,那么度为1的节点n1=1,而且度为0的节点数等于度为2的节点数,即 n0=n2=n,等于总节点数的一半。
3.一个具有767个节点的完全二叉树,其叶子节点个数为()
分析:767=n0+n1+n2=n0+n2=n0+n0-1 ------> 768=2n0 ------> n0=384
4.一棵完全二叉树的节点数为531个,那么这棵树的高度为( )
分析:由 得出,高度/深度K=
=
------>
------>向上取整
,即这棵树的高度为10。
二叉树的存储
二叉树的存储结构分为:顺序存储 和类似于链表的链式存储。
现在我们先学习链式存储。
二叉树的链式存储是通过一个一个的节点引用起来的 ,常见的表示方式有二叉(孩子表示法)和三叉(孩子双亲表示法)表示方式,具体如下:
java
//孩子表示法
static class Node {
public int val;//数据域
public Node left;//左孩子的引用,常常代表左孩子为根的整棵左子树
public Node right;//右孩子的引用,常常代表右孩子为根的整棵右子树
}
//孩子双亲表示法
static class Node {
public int val;//数据域
public Node left;//左孩子的引用,常常代表左孩子为根的整棵左子树
public Node right;//右孩子的引用,常常代表右孩子为根的整棵右子树
public Node parent;//当前节点的根节点
}本文采用孩子表示法来构建二叉树。
二叉树的基本操作
回顾一下二叉树的知识:要么二叉树是空的,要么非空,由根节点、根节点的左子树、根节点的右子树组成。而且二叉树定义是递归式的,因此后序基本操作中基本都是按照该概念实现的。
在学习二叉树的基本操作之前,先学习二叉树的遍历方式。
二叉树的遍历
学习二叉树结构,最简单的方式就是遍历。所谓遍历(Traversal)是指沿着某条搜索路线,依次对树中每个结 点均做一次且仅做一次访问。访问结点所做的操作依赖于具体的应用问题(比如:打印节点内容、节点内容加 1)。 遍历是二叉树上最重要的操作之一,是二叉树上进行其它运算的基础。
在遍历二叉树时,如果没有进行某种约定,每个人都按照自己的方式遍历,得出的结果就比较混乱,如果按 照某种规则进行约定,则每个人对于同一棵树的遍历结果肯定是相同的 。如果N代表根节点,L代表根节点的 左子树,R代表根节点的右子树,则根据遍历根节点的先后次序有以下遍历方式:
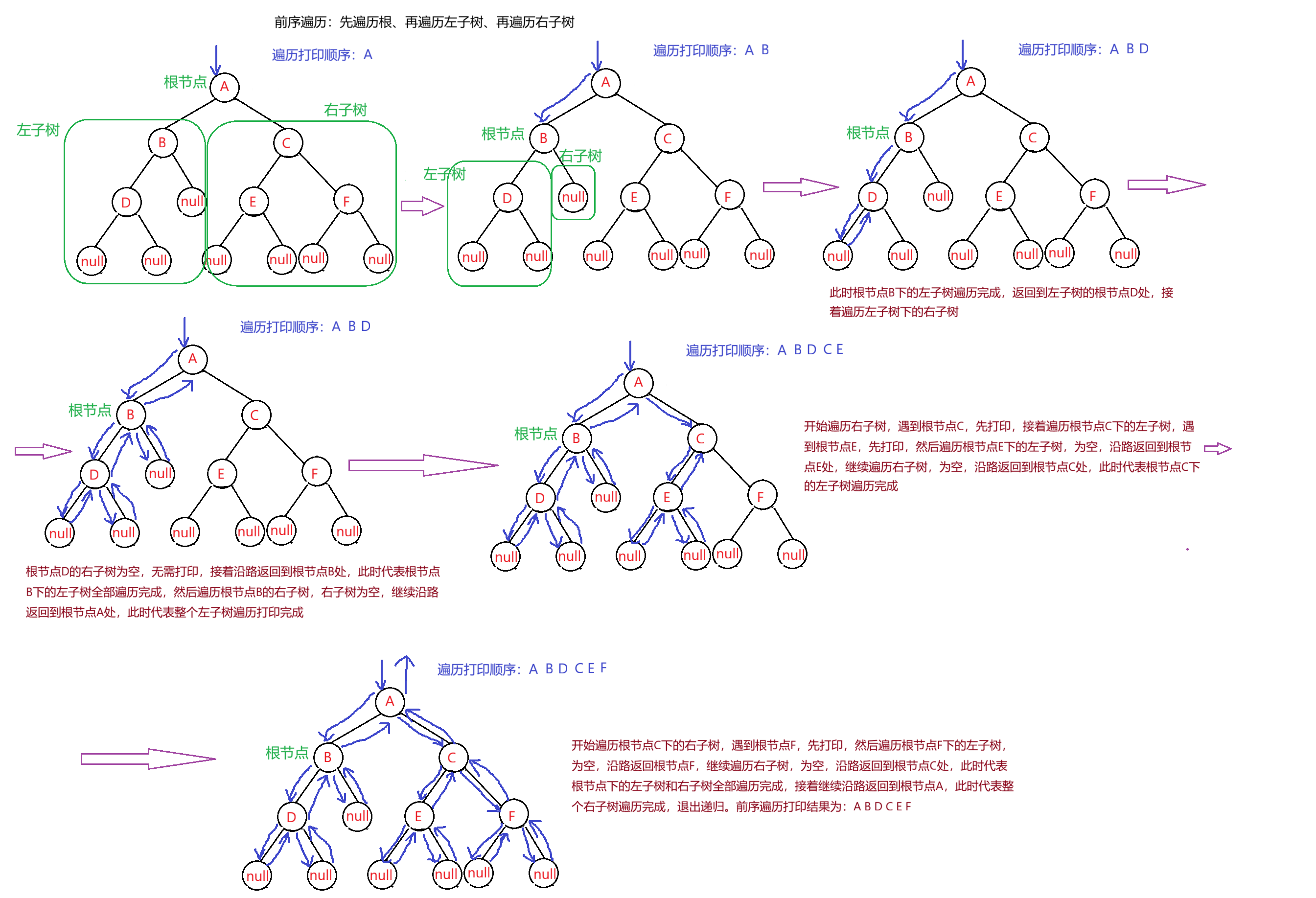
- NLR:前序遍历 (Preorder Traversal 亦称先序遍历)------访问根结点--->根的左子树--->根的右子树。
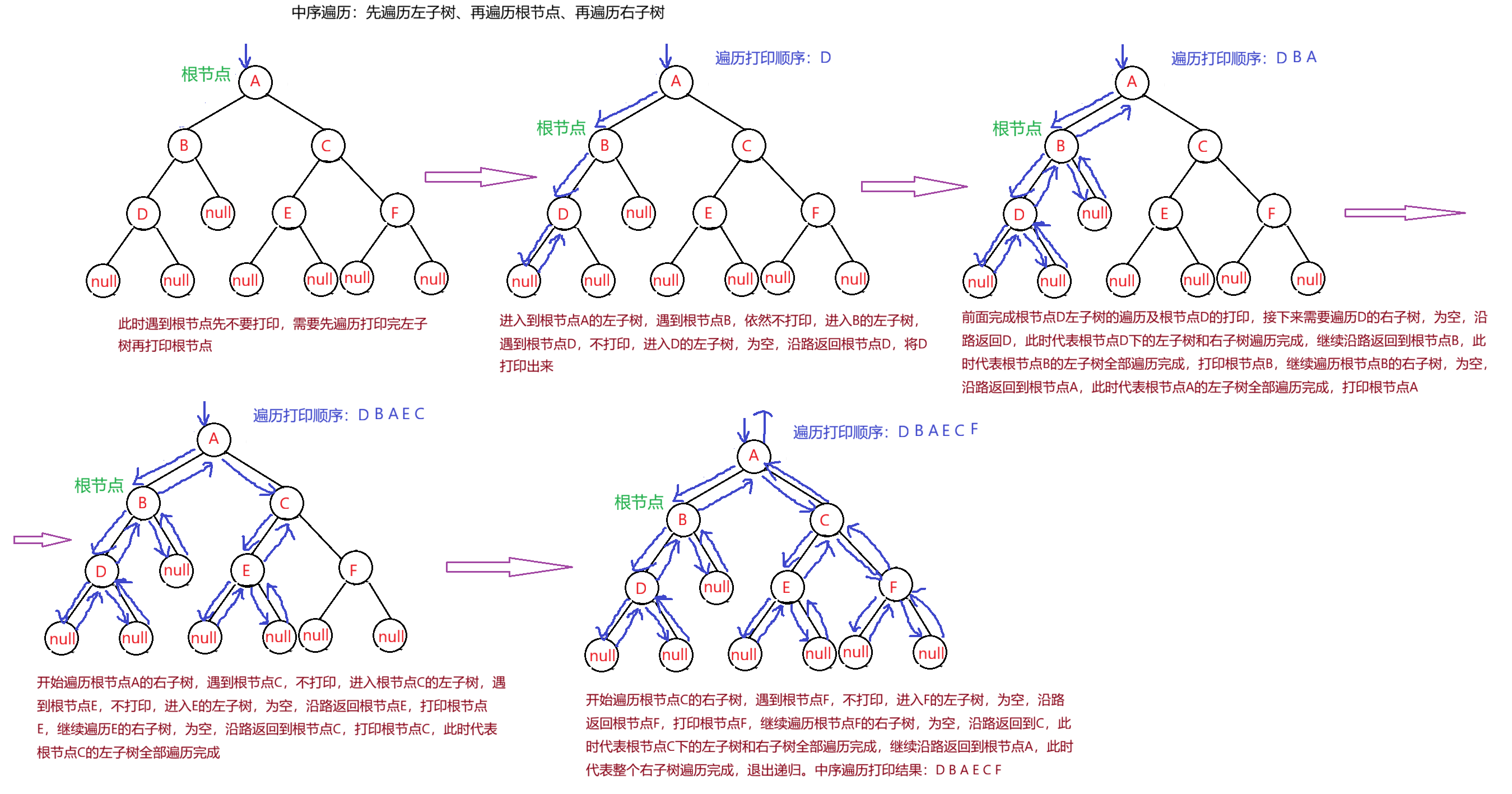
- LNR:中序遍历(Inorder Traversal)------根的左子树--->根节点--->根的右子树。
- LRN:后序遍历(Postorder Traversal)------根的左子树--->根的右子树--->根节点。
1.前序遍历
访问根结点--->根的左子树--->根的右子树
例如,遍历打印:前序遍历就是在遍历的过程中,如果遇到根节点,就打印该根节点,再往后遍历,一定是先遍历根的左子树(在该左子树中,又会有根节点、左子树和右子树的分支,全部遍历完后返回到该左子树,在进行右子树的遍历),然后遍历根的右子树(该右子树又有根节点、左子树和右子树),全部遍历打印完后,返回根节点,此时表示左子树和右子树全部遍历打印完成,返回按前序遍历打印的节点的数据。(递归思想)
2.中序遍历
根的左子树--->根节点--->根的右子树
例如,遍历打印:中序遍历就是在遍历过程中,每次遇到根节点时,先不打印,而是要先遍历打印根的左子树,遍历完左子树之后,沿路返回到根节点,将这个根节点打印后,接着沿路遍历右子树,遍历打印完右子树后,再沿路返回根节点,最后出递归。(递归思想)
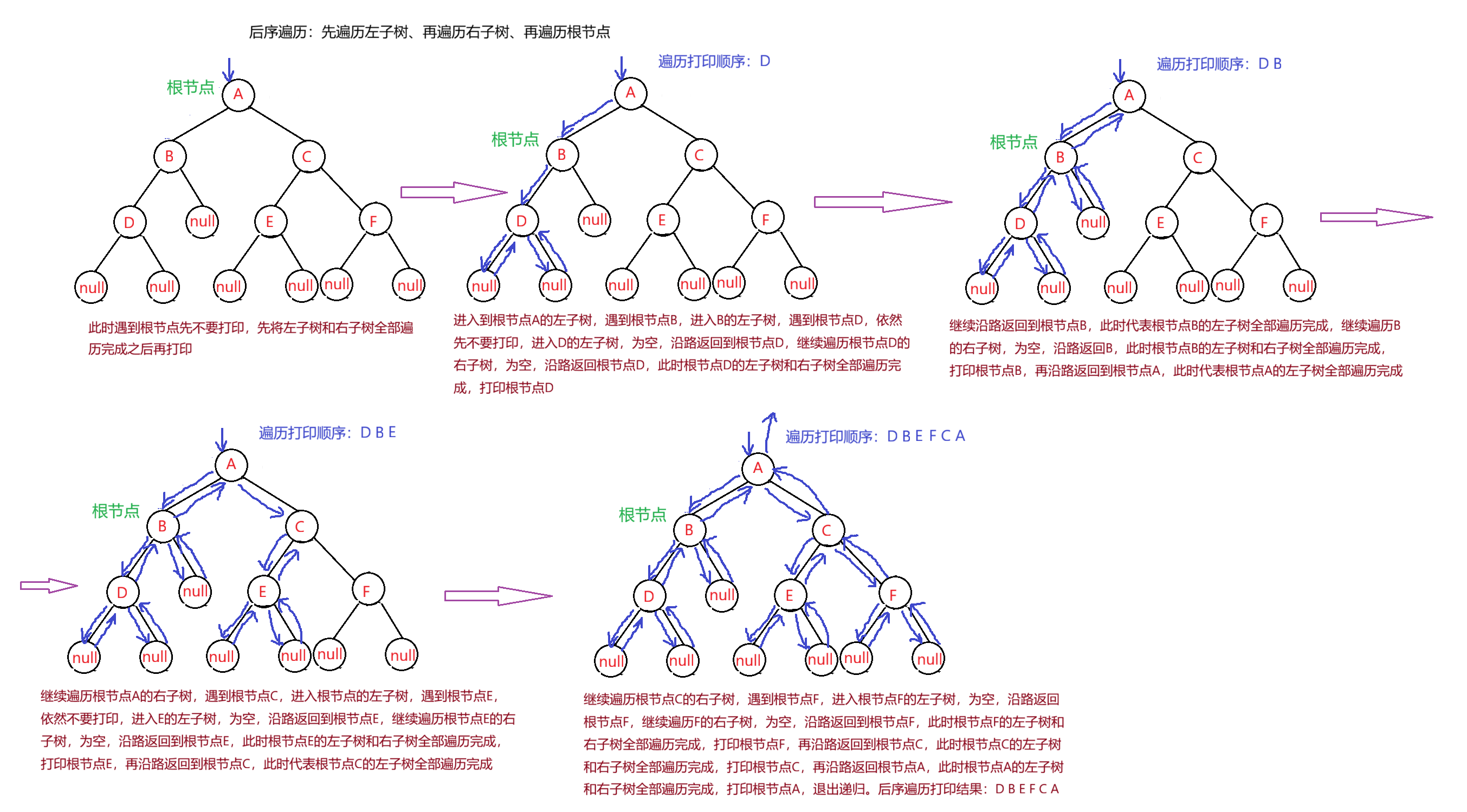
3.后序遍历
根的左子树--->根的右子树--->根节点
例如,遍历打印:后序遍历就是在遍历过程中,每次遇到根节点,先不打印,而是要先遍历打印根的左子树,遍历完左子树之后,沿路返回根节点,依然不打印,而是先要遍历打印完成根的右子树之后,沿路又返回根节点,将根节点打印出来,最后出递归。(递归思想)
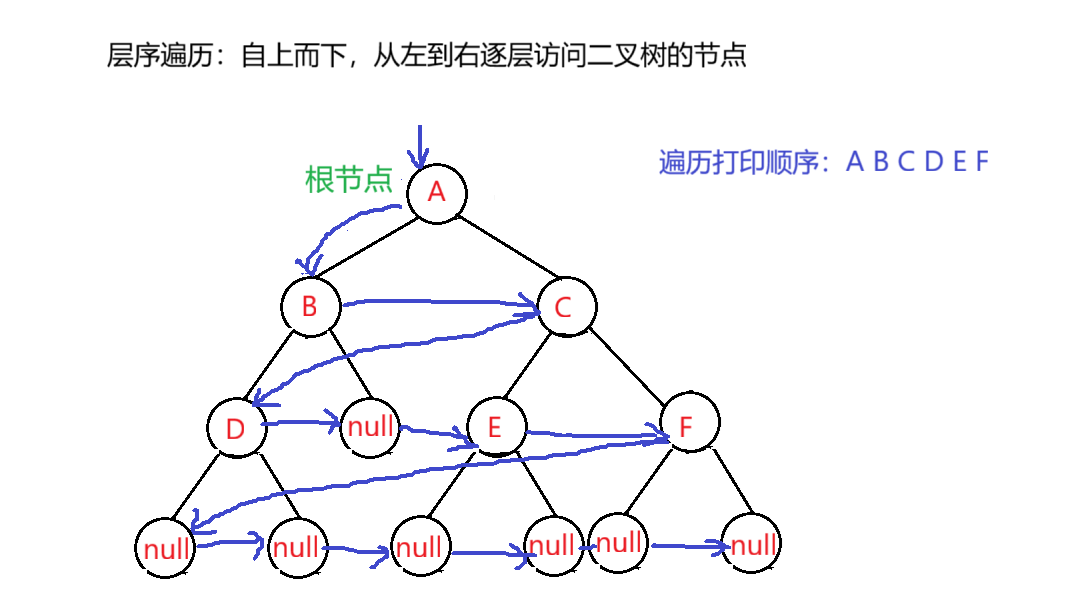
4.层序遍历
层序遍历:除了先序遍历、中序遍历、后序遍历外,还可以对二叉树进行层序遍历 。设二叉树的根节点所在层数为1,层序遍历就是从所在二叉树的根节点出发,首先访问第一层的树根节点,然后从左到右访问第2层上的节点,接着是第三层的节点,以此类推,自上而下,自左至右逐层访问树的节点的过程就是层序遍历。
例题练习
根据二叉树的三种遍历方式,推断遍历顺序
1.某完全二叉树按层次输出(同一层从左到右)的序列为 ABCDEFGH 。该完全二叉树的前序序列为()
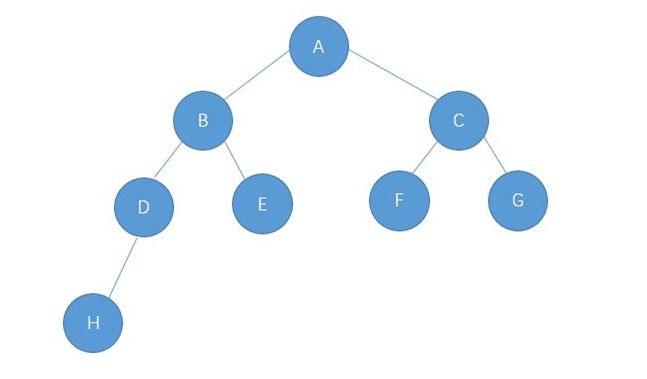
分析:前序遍历是按照根节点 -> 根的左子树 -> 根的右子树的顺序遍历的,因此,该完全二叉树的前序序列为 A B D H E C F G
2.二叉树的先序遍历和中序遍历如下:先序遍历:EFHIGJK;中序遍历:HFIEJKG.则二叉树根结点为()
分析:由于前序遍历的遍历顺序,我们知道,它遍历的第一个节点就是根节点,即根节点为E。

3.设一课二叉树的中序遍历序列:badce,后序遍历序列:bdeca,则二叉树前序遍历序列为()
分析:由后序遍历序列可知,根节点为最后一个节点,即为a,根据中序遍历序列和后序遍历序列复原二叉树的形状,然后再得出前序遍历序列。

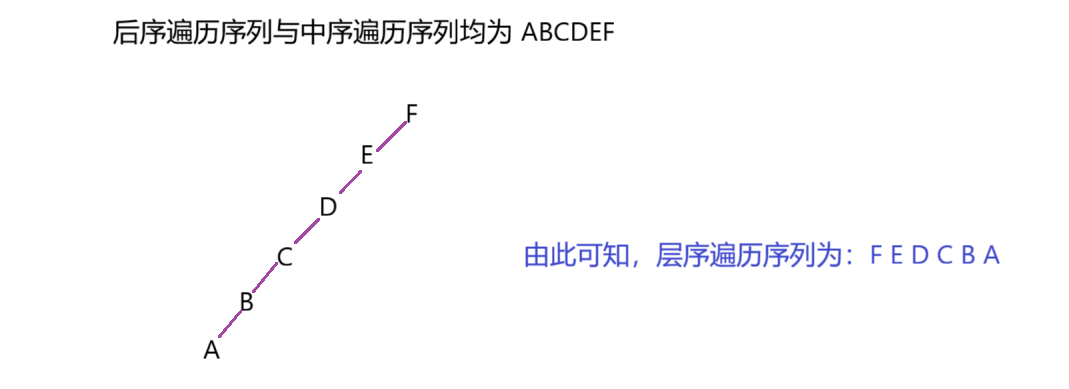
4.某二叉树的后序遍历序列与中序遍历序列相同,均为 ABCDEF ,则按层次输出(同一层从左到右)的序列为()
分析:依然由后序遍历序列可知,根节点为F,根据后序遍历序列和中序遍历序列复原二叉树的形状,然后得出层次输出序列。
了解完二叉树的三种遍历方式,现在用代码来实现 前/中后序遍历。
实现 前/中/后 序遍历
首先先创建一个二叉树类BinaryTree,然后创建二叉树节点(使用前面所说的孩子表示法创建):
java
public class BinaryTree {
//创建二叉树节点
static class TreeNode {
public char val;
public TreeNode left;//存储左孩子的引用
public TreeNode right;//存储有孩子的引用
public TreeNode(char val) {
this.val = val;
}
}
}接着以下图的二叉树为模板,创建一棵二叉树(以下代码并不是创建二叉树的方式,真正创建二叉树方式后序详解重点讲解,这里只是为了能够方便二叉树的学习而简单创建的):
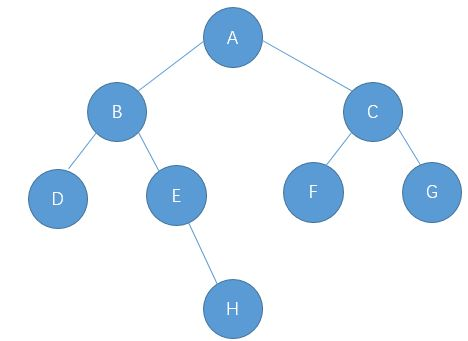
java
public class BinaryTree {
//创建二叉树节点
static class TreeNode {
public char val;
public TreeNode left;//存储左孩子的引用
public TreeNode right;//存储有孩子的引用
public TreeNode(char val) {
this.val = val;
}
}
//创建二叉树
public TreeNode createTree() {
TreeNode A = new TreeNode('A');
TreeNode B = new TreeNode('B');
TreeNode B = new TreeNode('C');
TreeNode B = new TreeNode('D');
TreeNode B = new TreeNode('E');
TreeNode B = new TreeNode('F');
TreeNode B = new TreeNode('G');
TreeNode B = new TreeNode('H');
A.left = B;
A.right = C;
B.left = D;
B.left = E;
C.left = F;
C.right = G;
E.right = H;
return A;//返回根节点
}
}接着开始实现二叉树的遍历方式(记住二叉树是递归定义的,在实现遍历方式时,也是递归的思路)
前序遍历
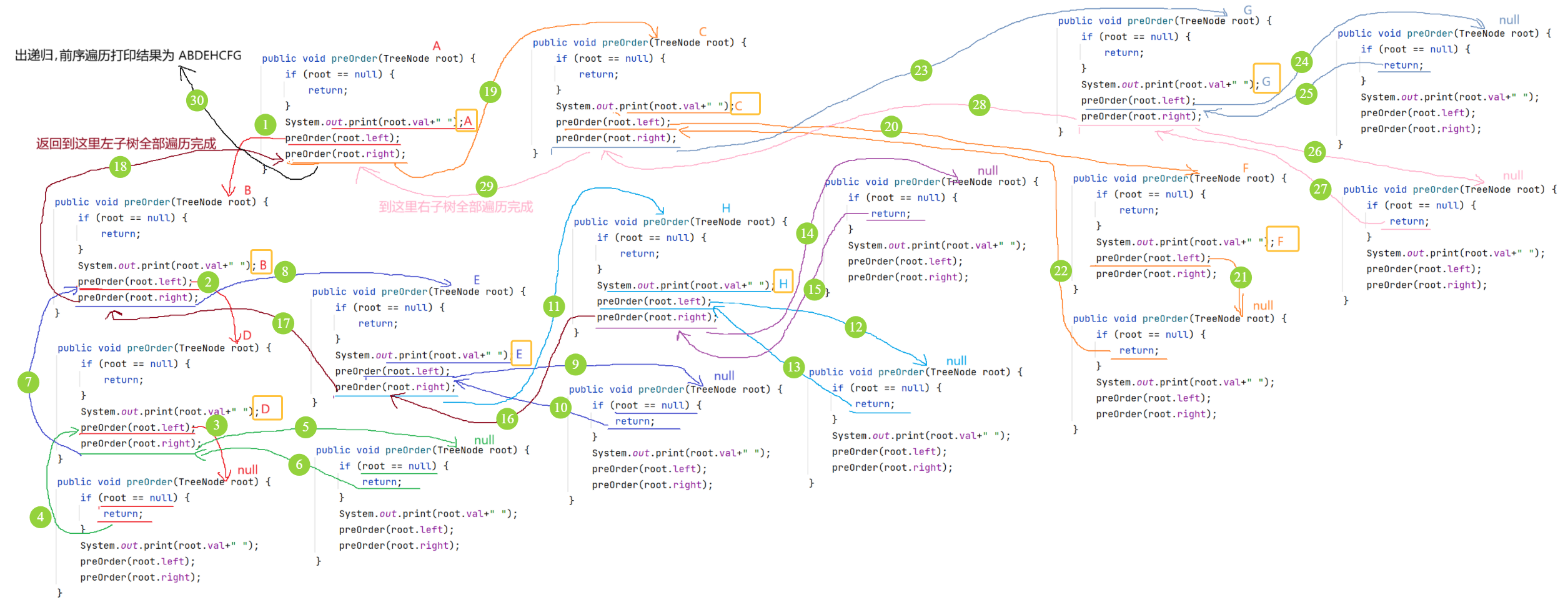
方法一:如果二叉树为空(根节点root为null),直接返回;不为空,就按照前序遍历的思路进行代码实现:先遍历根节点,然后再遍历左子树,最后遍历右子树(递归)。
java
public void preOrder(TreeNode root) {
if(root == null) {
return;
}
System.out.print(root.val + " ");
preOrder(root.left);
preOrder(root.right);
}递归图解:
方法二:在方法一中,是在边遍历的过程中边打印结果,并没有将前序遍历的结果进行保存,那么方法二就是要将结果保存起来:创建一个List列表,将遍历的结果保存在列表中,最后返回该列表
java
public List<Character> preorderTraversal(TreeNode root) {
List<Character> list = new ArrayList<>();
if(root == null) {
return list;
}
list.add(root.val);
List<Character> leftTree = preorderTraversal(root.left);
list.addAll(leftTree);
List<Character> rightTree = preorderTraversal(root.right);
list.addAll(rightTree);
return list;
}递归图解:
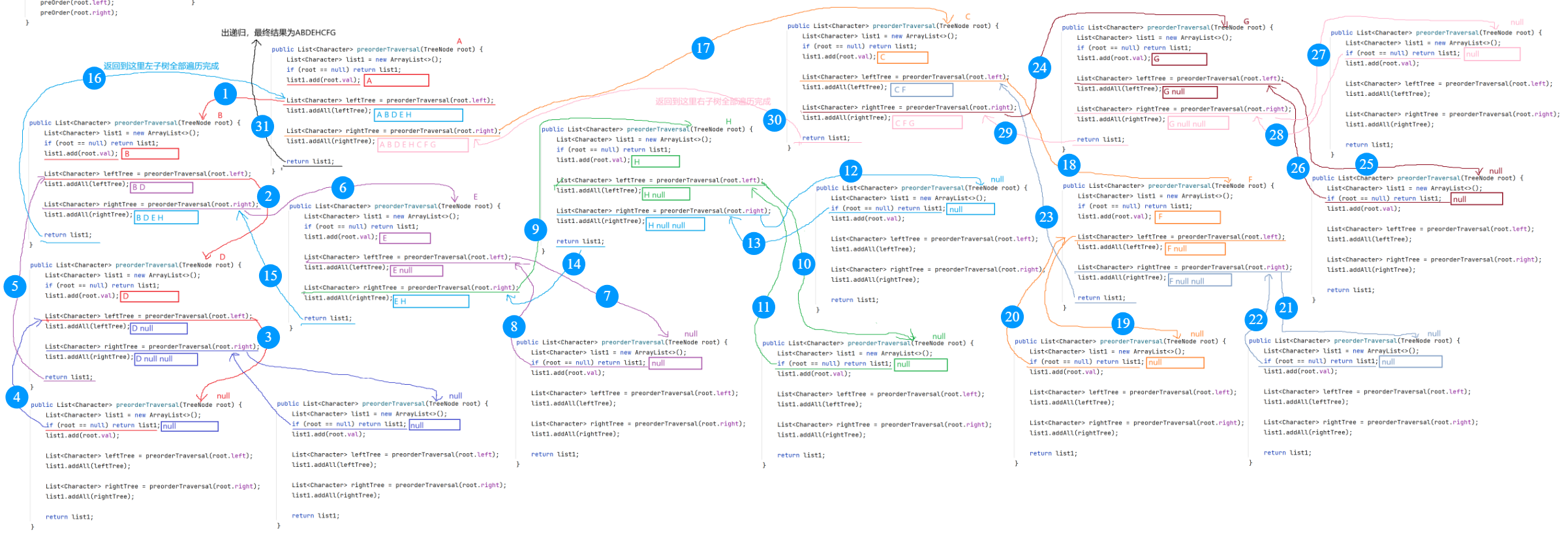
注意:上述的两种方法都是子问题思路。
子问题是指与原问题具有相同结构但规模更小的问题。在这个例子中:
- 原问题:遍历整棵二叉树(根-左子树-右子树)
- 子问题:遍历左子树和遍历右子树(左子树根-左子树中的左子树-左子树中的右子树等)
中序遍历
方法一:思路与前序遍历一样,只是变成先遍历左子树,再遍历根,最后遍历右子树。
java
public void inOrder(TreeNode root) {
if(root == null) {
return;
}
inOrder(root.left);
System.out.print(root.val + " ");
inOrder(root.right);
}方法二:与前序遍历一样的思路。
java
public List<Character> inorderTraversal(TreeNode root) {
List<Character> list = new ArrayList<>();
if(root == null) {
return list;
}
List<Character> leftTree = inorderTraversal(root.left);
list.addAll(leftTree);
list.add(root.val);
List<Character> rightTree = inorderTraversal(root.right);
list.addAll(root.right);
return list;
}后序遍历
方法一:与前序遍历的思路一样,只是变成了先遍历左子树,再遍历右子树,最后遍历根。
java
public void postOrder(TreeNode root) {
if(root == null) {
return;
}
postOrder(root.left);
postOrder(root.right);
System.out.print(root.val + " ");
}方法二:与前序遍历的思路一样。
java
public List<Character> postorderTraversal(TreeNode root) {
List<Character> list = new ArrayList<>();
if(root == null) {
return list;
}
List<Character> leftTree = postorderTraversal(root.left);
list.addAll(leftTree);
List<Character> rightTree = postorderTraversal(root.right);
list.addAll(rightTree);
list.add(root.val);
return list;
}二叉树遍历的实现到这里就结束了,接下来学习二叉树中的基本操作。
二叉树基本操作
还是按照之前遍历方式的那棵二叉树为例。
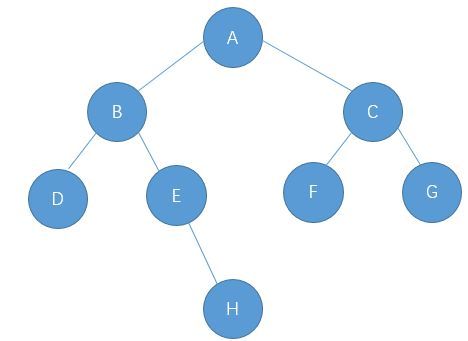
size() 获取二叉树中节点的个数
思路1:定义一个成员变量nodeSize,只要root不为空,记录遍历二叉树时节点的个数,每遍历一个节点就++,还是先遍历左子树,再遍历右子树。如果二叉树为空,则直接返回。
java
public static int nodeSize;
public void size(TreeNode root) {
if(root == null) {
return;
}
nodeSize++;
size(root.left);
size(root.right);
}思路2:子问题思路:整棵二叉树的节点=左子树的节点+右子树的节点+根节点root(root即为1)
再细分,就是 二叉树的节点=左子树中的左子树的节点+右子树的节点+root + 右子树中的左子树的节点+右子树的节点+root (等等,还可以再细分,直到遇到叶子节点返回)
java
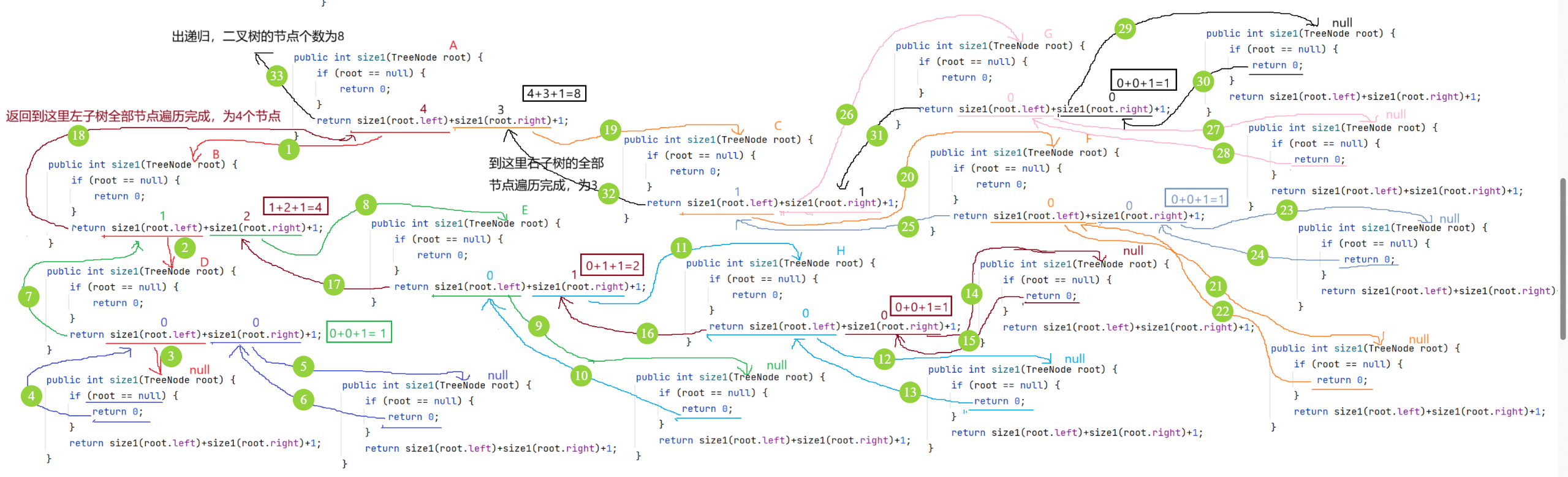
public int size(TreeNode root) {
if(root == null) {
return 0;
}
return size(root.left) + size(root.right) + 1;
}递归图解:
getLeafNodeCount() 获取叶子节点的个数
当一个根节点root的左子树和右子树都为空时,就是叶子节点,即root.left==null&&root.right==null。
思路1:定义一个成员变量leafSize,如果root符合上述叶子节点的特征,则leafSize++,否则继续递归。
java
public static int leafSize;
public void getLeafNodeCount(TreeNode root) {
if(root == null) {
return;
}
if(root.left == null && root.right == null) {
leafSize++;
}
getLeafNodeCount(root.left);
getLeafNodeCount(root.right);
}思路2:子问题思路:整棵二叉树的叶子节点=左子树的叶子节点+右子树的叶子节点
如果是叶子节点的话,就返回一个1,否则继续递归。
java
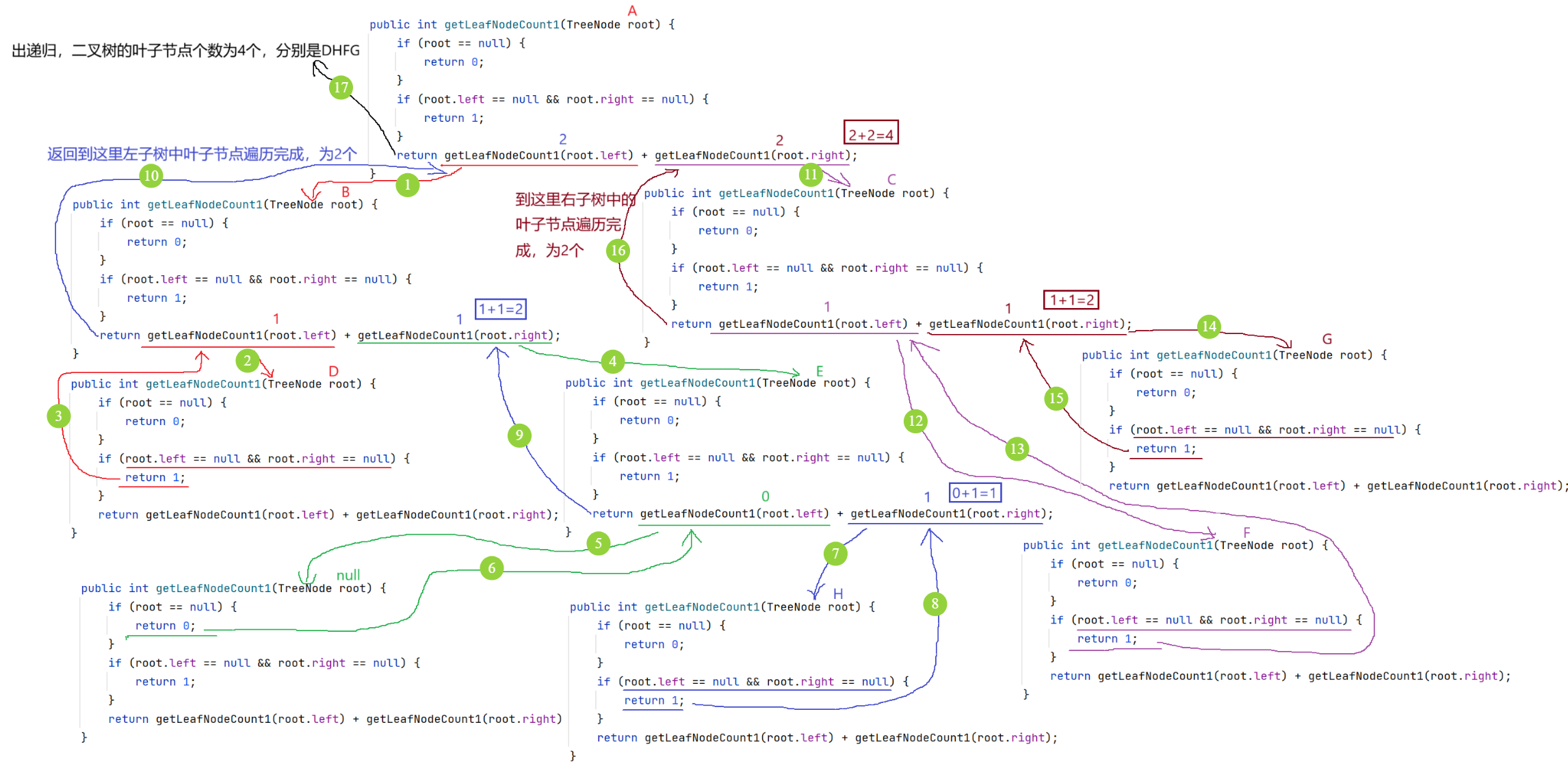
public int getLeafNodeCount(TreeNode root) {
if(root == null) {
return 0;
}
if(root.left == null && root.right == null) {
return 1;
}
return getLeafNodeCount(root.left) + getLeafNodeCount(root.right);
}递归图解:
getKLevelNodeCount() 获取第K层节点的个数
思路1:定义一个成员变量kSize,记录遍历的第K层节点的个数。思路如下图所示:
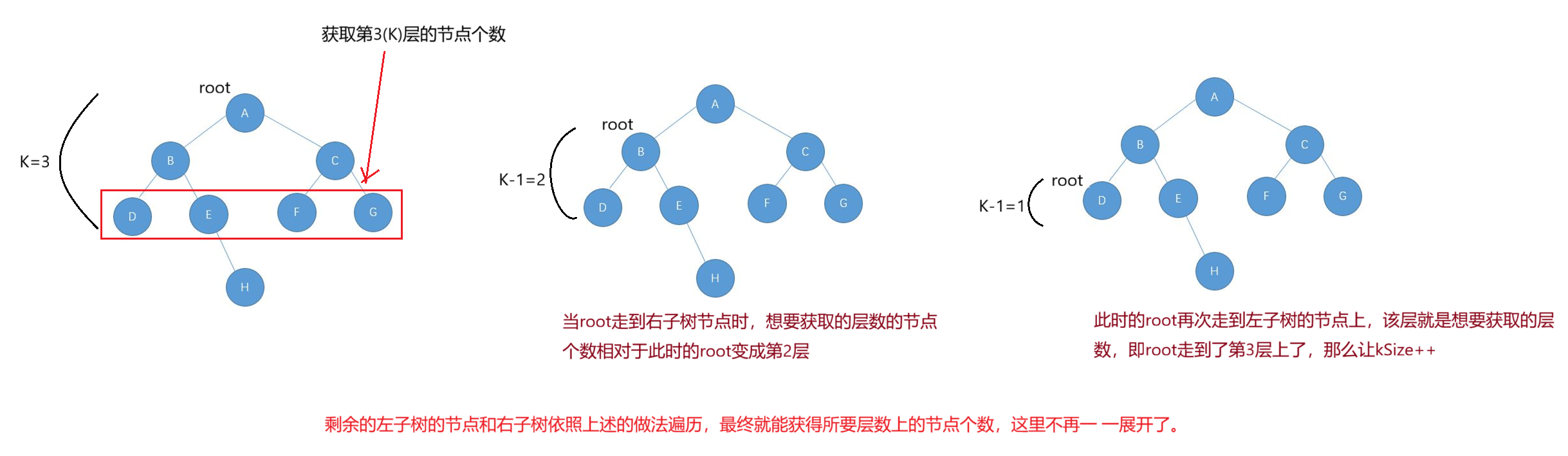
java
public static int kSize;
public void getKLevelNodeCount(TreeNode root,int k) {
if(root == null) {
return;
}
if(k == 1) {
kSize++;
}
getKLevelNodeCount(root.left,k-1);
getKLevelNodeCount(root.right,k-1);
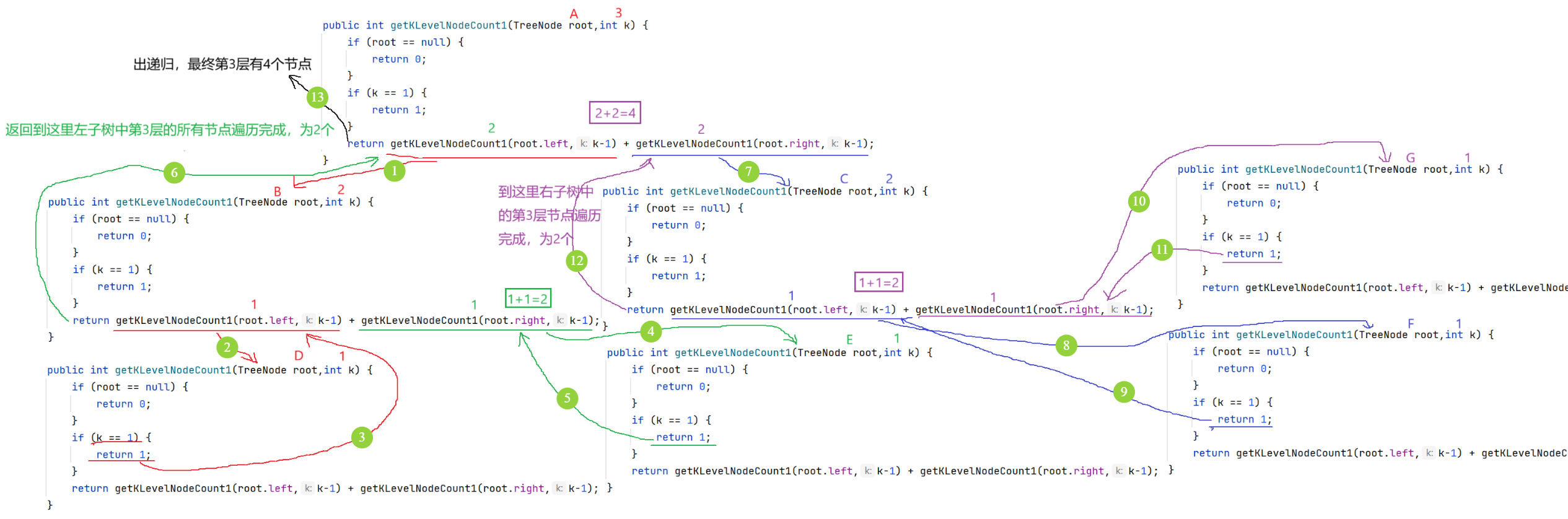
}思路2:子问题思路:第K层节点的个数=左子树的第K-1层+右子树的第K-1层
如果是第K层上的节点,则返回1,否则继续递归。
java
public int getKLevelNodeCount(TreeNode root,int k) {
if(root == null) {
return 0;
}
if(k == 1) {
return 1;
}
return getKLevelNodeCount(root.left,k-1) + getKLevelNodeCount(root.right,k-1);
}递归图解:
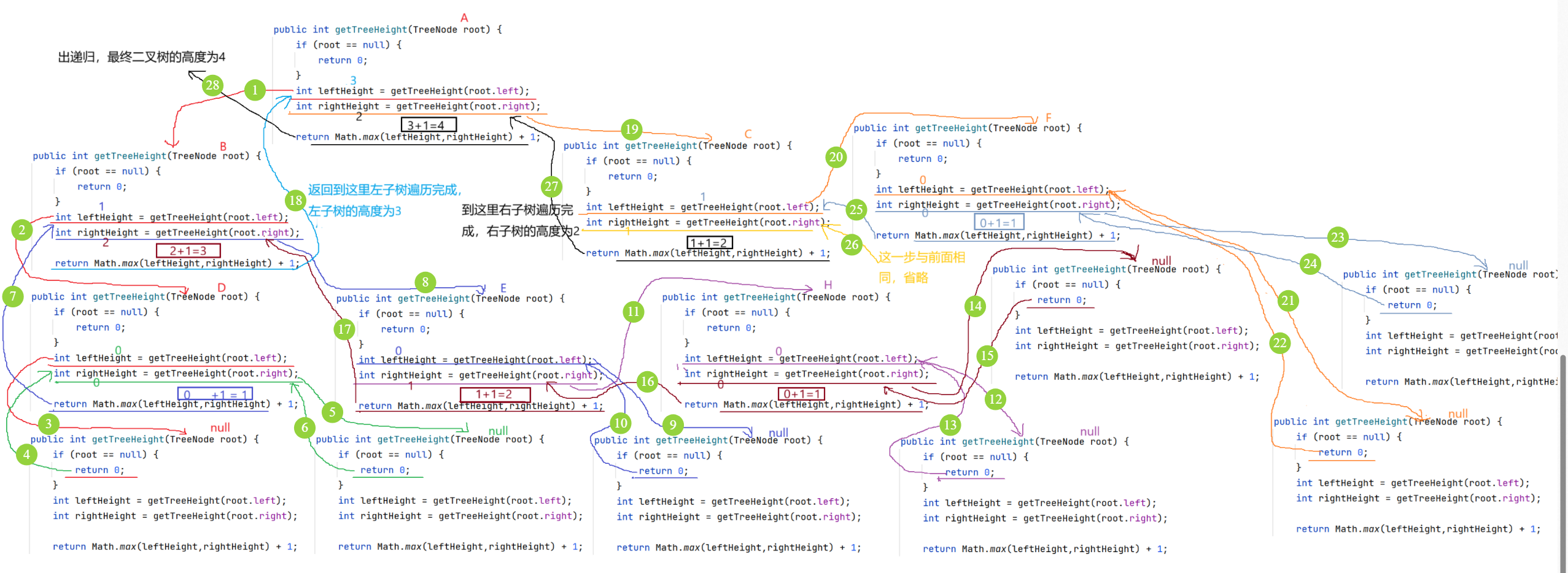
getHeight() 获取二叉树的高度
思路:子问题思路:前面我们在学习二叉树概念的时候说过,二叉树的高度/深度是树中节点的最大层次 ,也就是说,可以先比较根的左子树和右子树高度,谁的高度高,就取谁的高度去加上root根节点(1),最终的结果就是二叉树的高度。
java
public int getHeight(TreeNode root) {
if(root == null) {
return 0;
}
int leftHeight = getHeight(root.left);
int rightHeight = getHeight(root.right);
return Math.max(leftHeight,rightHeight) + 1;
}递归图解:
findVal() 检测值为value的元素是否存在
思路:遍历二叉树,有四种情况:
- 根节点的值就是value,那么直接返回根节点root。
- 如果不是root,那就判断左子树中是否有值为value的节点,如果有将该节点存放在leftTree引用中,如果leftTree为null,则说明左子树中并没有值为value的节点。
- 如果leftTree==null,那么判断右子树中是否有值为value的节点,步骤和左子树的判断相同。
- 如果rightTree==null,则说明右子树中也没有值为value的节点,也就是说整个二叉树中没有值为value的节点。
java
public TreeNode findVal(TreeNode root,char value) {
if(root == null) {
return null;
}
if(root.val == value) {
return root;
}
TreeNode leftTree = findVal(root.left);
if(leftTree != null) {
return leftTree;
}
TreeNode rightTree = findVal(root.right);
if(rightTree != null) {
return rightTree;
}
return null;//以上都不是,说明二叉树中没有值为value的节点,返回null
}levelOrder() 层序遍历
思路1:层序遍历就是从上到下从左到右遍历二叉树的节点,那么可以借用队列实现层序遍历(当然也是递归的思路)。
具体做法:首先实例化一个Queue对象,先将二叉树的根节点root插入到队列中;每次当队列不为空时,进入循环:将队列中的队头元素出队列,同时定义一个cur引用存放该队头元素,将该元素打印出来,如果cur的左子树left不为null,则将left插入到队列中,如果cur的右子树right也不为null,则将right页插入到队列中;此时的队列还是不为空,继续将队列的队头元素出队,打印该元素,重复上述操作,将此时的出队的队头元素的left入队,right入队(不为null时)。直到二叉树层序遍历打印完成,结束循环。
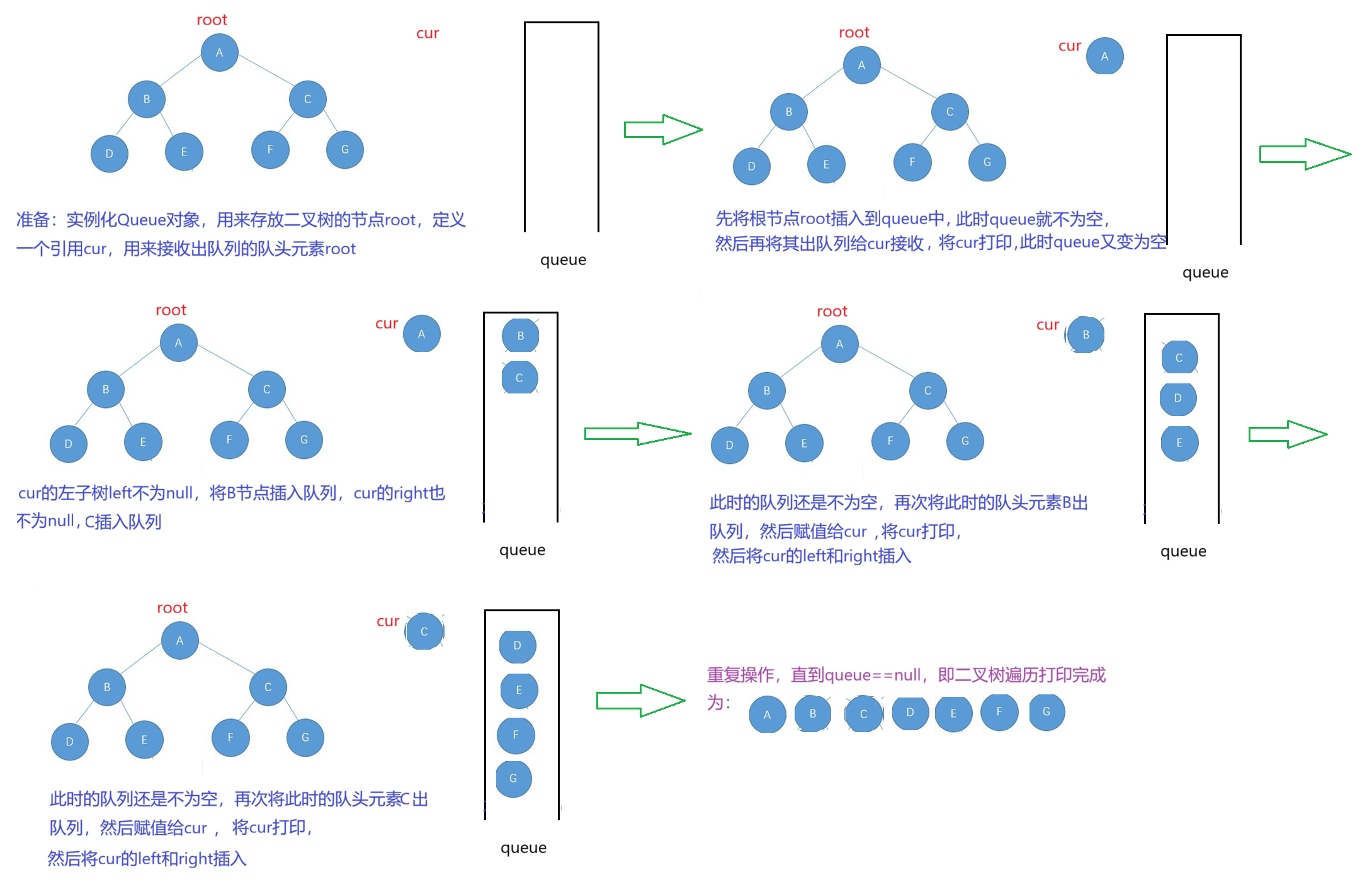
java
public void levelOrder(TreeNode root) {
if(root == null) {
return;
}
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
while(!queue.isEmpty()) {
TreeNode cur = queue.poll();
System.out.print(cur.val + " ");
if(cur.left != null) {
queue.offer(cur.left);
}
if(cur.right != null) {
queue.offer(cur.right);
}
}
}思路2:在方法一中,是在边遍历的过程中边打印结果,并没有将前序遍历的结果进行保存,那么方法二就是要将结果保存起来:与前中后序遍历不同的是,层序遍历是采用列表式的二维数组存储的,即二维列表List<LIst<>>,最后返回该二维列表。
示例:输入:root = A,B,D,null,null,E,null,null,C,F,null,null,G,null,null
输出: \[A , B,C , D,E,F,G ]
(如果对什么是二维列表不了解,请看这篇文章:https://blog.csdn.net/Zzzzmo_/article/details/152507227?spm=1001.2014.3001.5502)
只需要改变上面一种方法的一处,就是在每次打印节点值的部分,改成将节点值存放在二维列表的列表中,具体做法:
先将root存放到队列后,此时的队列不为空,进入循环:实例化一个一维列表,求此时队列的长度size,size是多大,就进行多少次循环:将队列中的节点出队列并使用cur引用接收,顺便查看cur的left和right,结束循环时,将一维列表中的节点存放到二维列表中;在新的一轮的循环中再次计算size,将队头元素出队,将它的左子树节点和右子树节点入队,然后将此时的新的一维列表中的节点存放到二维列表中,重复操作,直到全部节点都存放到二维列表中,出循环,返回该二维列表。
java
public TreeNode levelOrder(TreeNode root) {
List<LIst<Character>> ret = new ArrayList<>();
if(root == null) {
return ret;
}
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
while(!queue.isEmpty()) {
int size = queue.size();
List<Character> list = new ArrayList<>();
while(size != 0) {
TreeNode cur = queue.poll();
list.add(cur.val);
if(cur.left != null) {
queue.offer(cur.left);
}
if(cur.right != null) {
queue.offer(cur.right);
}
size--;
}
ret.add(list);
}
return ret;
}isCompleteTree() 判断一棵树是不是完全二叉树
依然借助队列实现该代码。
首先要知道队列中是可以存放null,这时候就要区分二叉树什么时候是空,什么时候是非空:如果队列中存放的是4个null,那么计算该队列的大小就是4,说明队列存放null是可以的,不代表队列是空;如果队列中什么都没有,即没有存放null或者其他有效的元素,这时候才是真正的空。

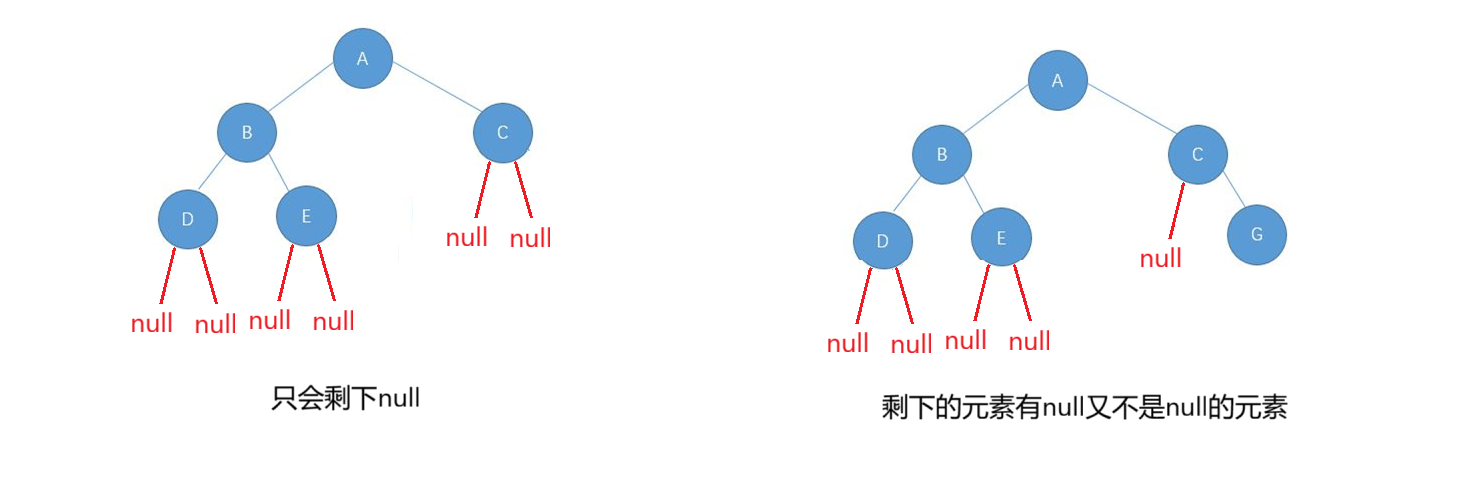
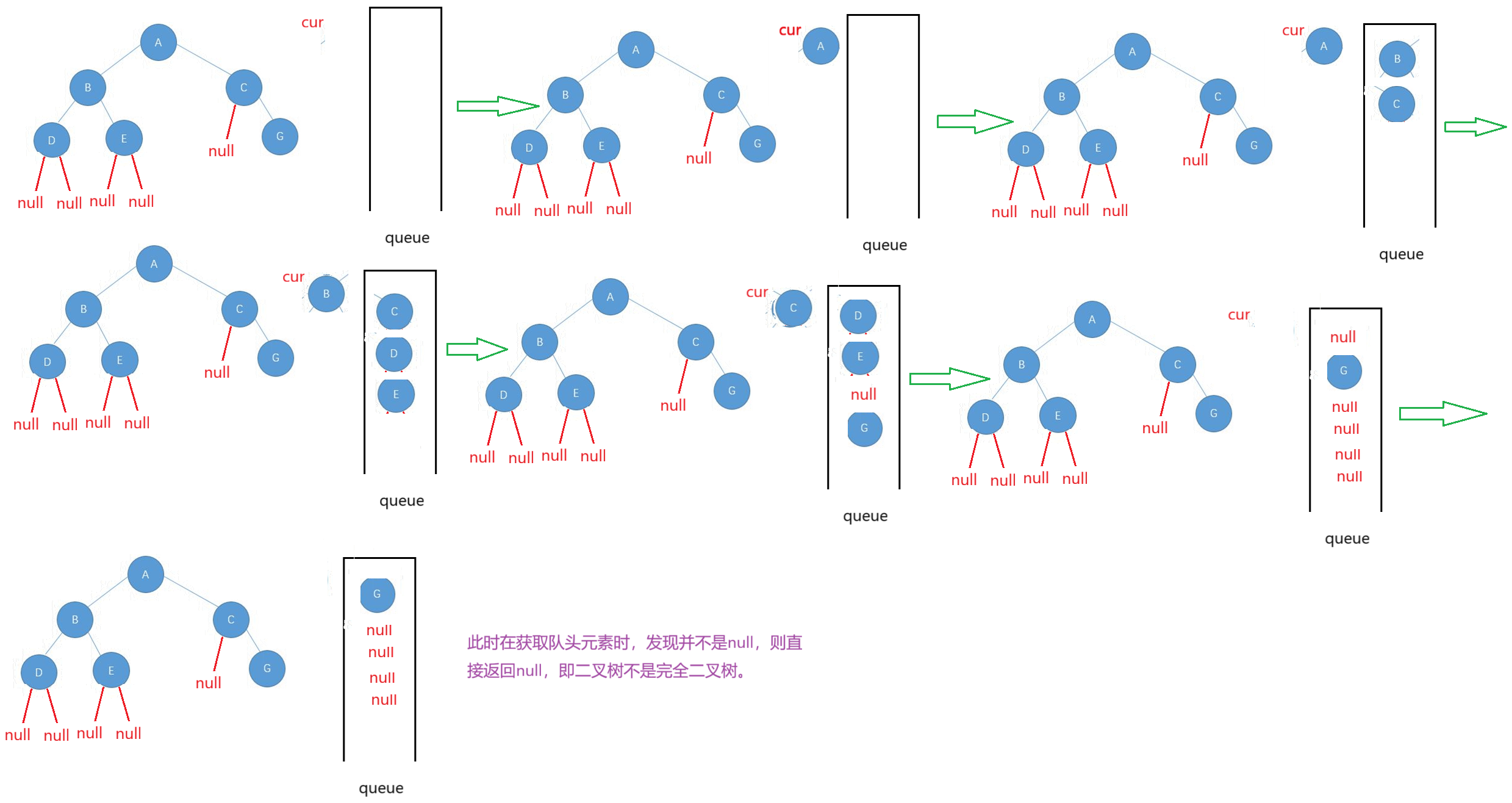
思路:按照层序遍历的方式,将所有节点存放到队列中,期间定义一个cur引用接收出队列的队头元素,由于完全二叉树的性质,知道最终所有元素出对后,队列中的元素只会剩下null ,这就表示该树是一颗完全二叉树,如果剩下的元素有null又不是null的元素,表示不是完全二叉树。
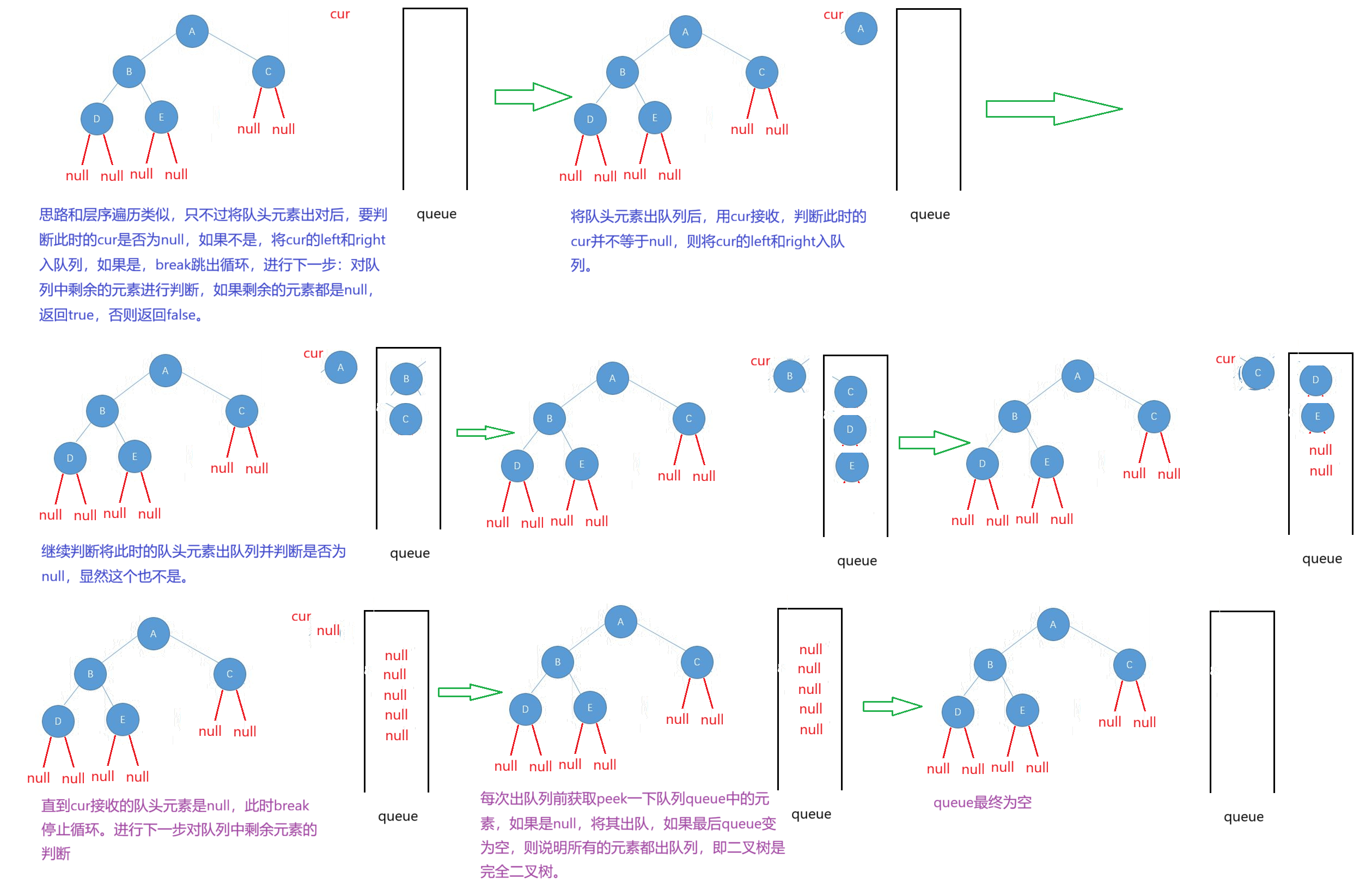
具体思路:当二叉树为空时,将其视为是一个完全二叉树。每次将root存放到队列中,当队列不为空时,进入循环,定义一个cur引用,将队头元素root出队列,cur接收这个结果,如果每次cur接收到的元素不是null,则将cur的left和right存放到队列中,如果是null,则break跳出循环;
此时判断队列中剩余的元素,当队列不为空时,进入循环,每次获取一下队列的队头元素,如果该元素等于null,将其出队列,然后继续循环,如果剩余元素全部都出队列了,那说明剩余的元素都是null,二叉树是完全二叉树;如果在获取队头元素期间,发现该元素不等于null,那就说明剩下的元素不都是null,说明二叉树不是完全二叉树,返回false。
- 为完全二叉树的情况:
- 不为完全二叉树的情况:
java
public boolean isCompleteTree(TreeNode root) {
if(root == null) {
return true;
}
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
while(!queue.isEmpty()) {
TreeNode cur = queue.poll();
if(cur != null) {
queue.offer(cur.left);
queue.offer(cur.right);
}else {
break;
}
}
while(!queue.isEmpty()) {
TreeNode peek = queue.peek();
if(peek != null) {
return false;
}
queue.poll();
}
return true;
}