编者按: 在构建基于大语言模型的 RAG 系统时,您是否曾思考过:究竟哪种表格数据格式能让 LLM 最准确高效地理解和提取信息?
我们今天为大家带来的文章,作者通过一项对照实验指出:表格格式对 LLM 的理解能力有显著影响,其中 Markdown-KV 格式在准确率上表现最佳,但也伴随着更高的 token 消耗。
文章详细介绍了作者针对 GPT-4.1-nano 模型进行的对照实验,测试了包括 CSV、JSON、Markdown Table、YAML 等在内的 11 种常见表格格式,使用 1000 条员工记录和对应问题,系统性地评估了各种格式在准确率和 token 消耗两个维度的表现。研究发现,虽然 Markdown-KV 格式准确率最高(60.7%),但也消耗了更多 token,而常见的 CSV 和 JSONL 格式表现不佳。
作者 | Improving Agents
编译 | 岳扬
在讨论基于 AI 的系统的可靠性时,有一个简单却常被忽视的问题:究竟用什么格式向大语言模型传递表格数据最合适?
应该用 Markdown table 还是 CSV?
选 JSON 抑或是 YAML?
或者有没有其他格式比上述这些都更优?
01 为什么这个问题很重要
当前许多 RAG pipeline 都需要处理含表格的文档,并将这些表格信息输入大语言模型。
1.1 系统准确性
若未能以易于大语言模型解析的格式呈现表格信息,可能会降低整个系统的准确性。
1.2 Token 成本
某些格式表示相同数据所需的 token 数量可能是其他格式的数倍。如果你按处理的 token 数量付费,那么格式的选择将直接影响你的 LLM 推理成本。
02 我们的实验方法
我们设计了一个对照实验,测试数据格式如何影响 LLM 回答该数据相关问题的准确性。
测试过程包含向大语言模型输入 1000 条记录,要求其根据数据回答问题,随后逐条评估是否回答正确。
我们针对 1,000 个问题,分别使用了 11 种不同的数据格式重复了这一过程。
- 数据集:包含 8 个属性(ID、姓名、年龄、城市、部门、薪资、工作经验、项目数量)的 1000 条虚拟员工记录
- 问题设置:1000 个针对具体数据点的随机查询
- 测试模型:GPT-4.1-nano
- 格式验证:11 种不同的数据呈现格式
2.1 示例问答对
问:"Grace X413 有多少年工作经验?(只需返回数字,例如'12')"
答:"15"
问:"Alice W204的薪资是多少?(只需返回数字,例如'85200')"
答:"131370"2.2 实验方法说明
我们选择向大语言模型传递相对大数量的记录来测试其极限。在实际应用中,处理大型结构化数据集时,通常需要对其进行分块处理和通过查询提取最相关的记录或信息,仅将精简后的上下文内容传递给大语言模型。
使用包含表头的表格格式(如 CSV、HTML table 和 Markdown table)时,建议定期重复表头(例如每 100 条记录重复一次)以增强理解。 为简化实验流程,本次实验未采用该做法。
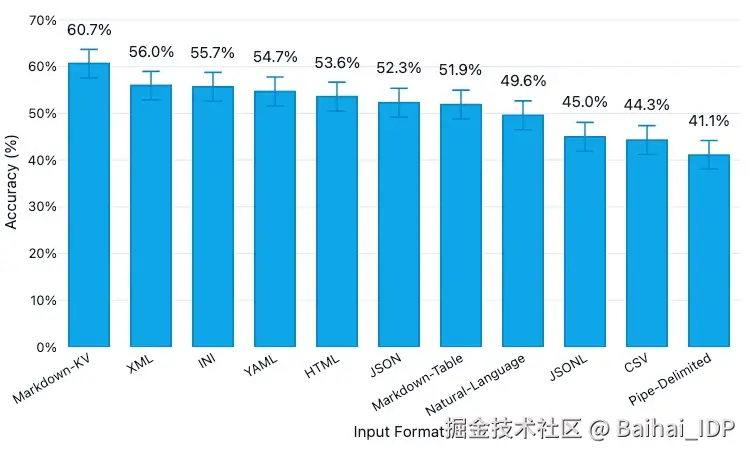
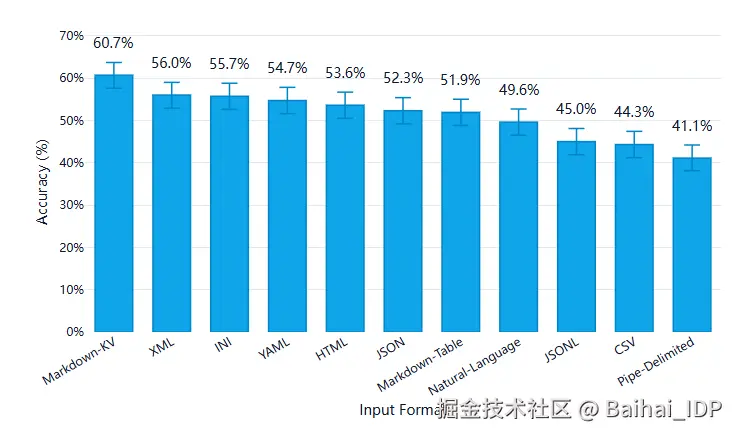
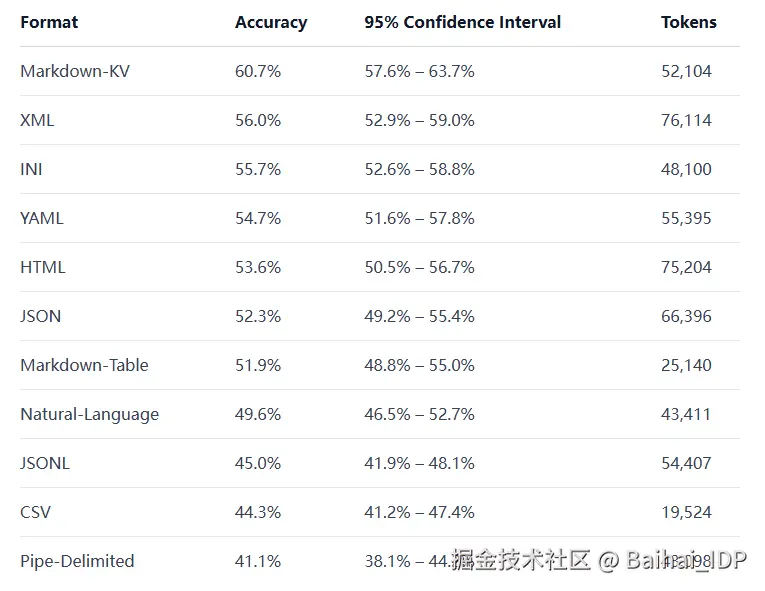
03 大语言模型对不同表格格式的理解程度如何?
04 Highlights
- 表格格式似乎很重要:我们在不同格式之间观察到了明显的理解差异。
- CSV 和 JSONL 表现不佳:如果你目前默认使用其中一种格式,更换格式可能带来立竿见影的改进效果。
- Markdown-KV 表现最佳,准确率达到 60.7%,比 CSV 高出约 16 个百分点。(Markdown-KV 是我们对一种非标准化格式的称呼,该格式在 Markdown 中使用"key: value"键值对。)
- 提升准确率需要以 token 的消耗为代价:表现最佳的 Markdown-KV 格式所使用的 token 数量是 token 效率最高的格式(CSV)的 2.7 倍。
4.1 准确率与 token 成本的权衡
下图可视化了准确率与 token 使用量之间的关系(采用对数刻度),有助于说明这两个关键指标之间的平衡关系:
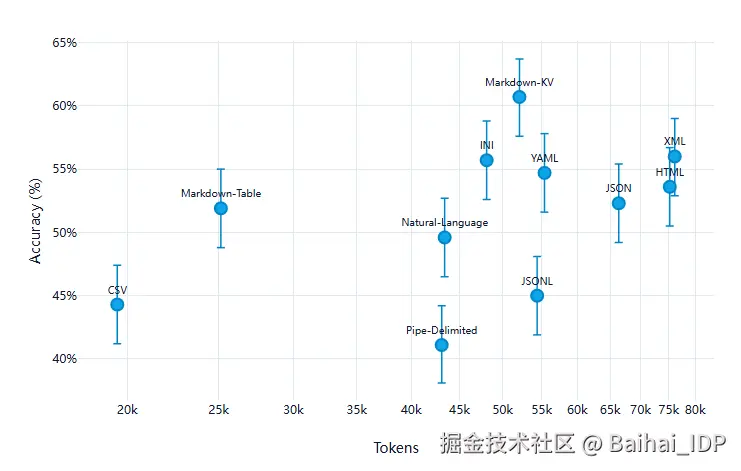
如图所示,总体趋势是 token 使用得越多,准确率越高,但并非线性相关。 有些格式表现超常(如 Markdown-KV),而另一些格式则在两个维度上都表现低效(如 Pipe-Delimited)。
05 所评估的数据格式
1)JSON
2)CSV
3)XML
4)YAML
5)HTML

6)Markdown Table
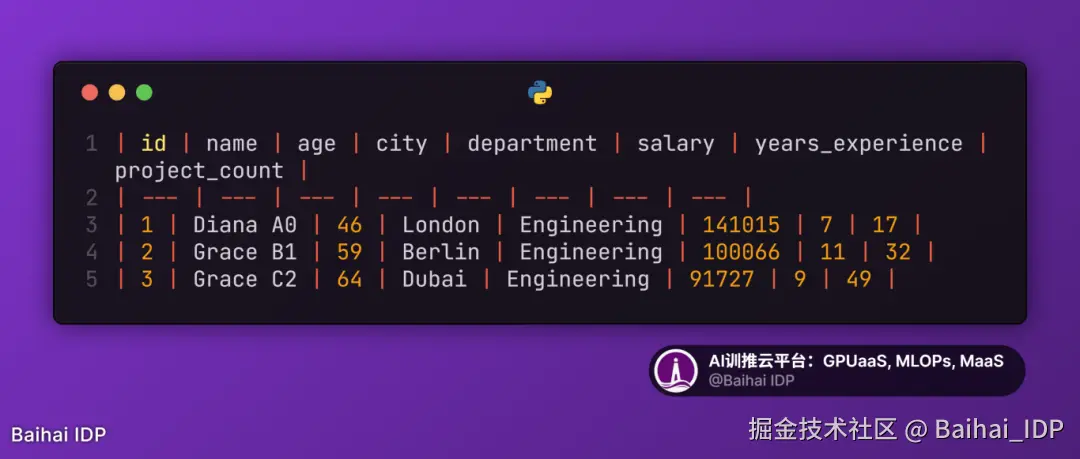
7)Markdown KV

8)INI
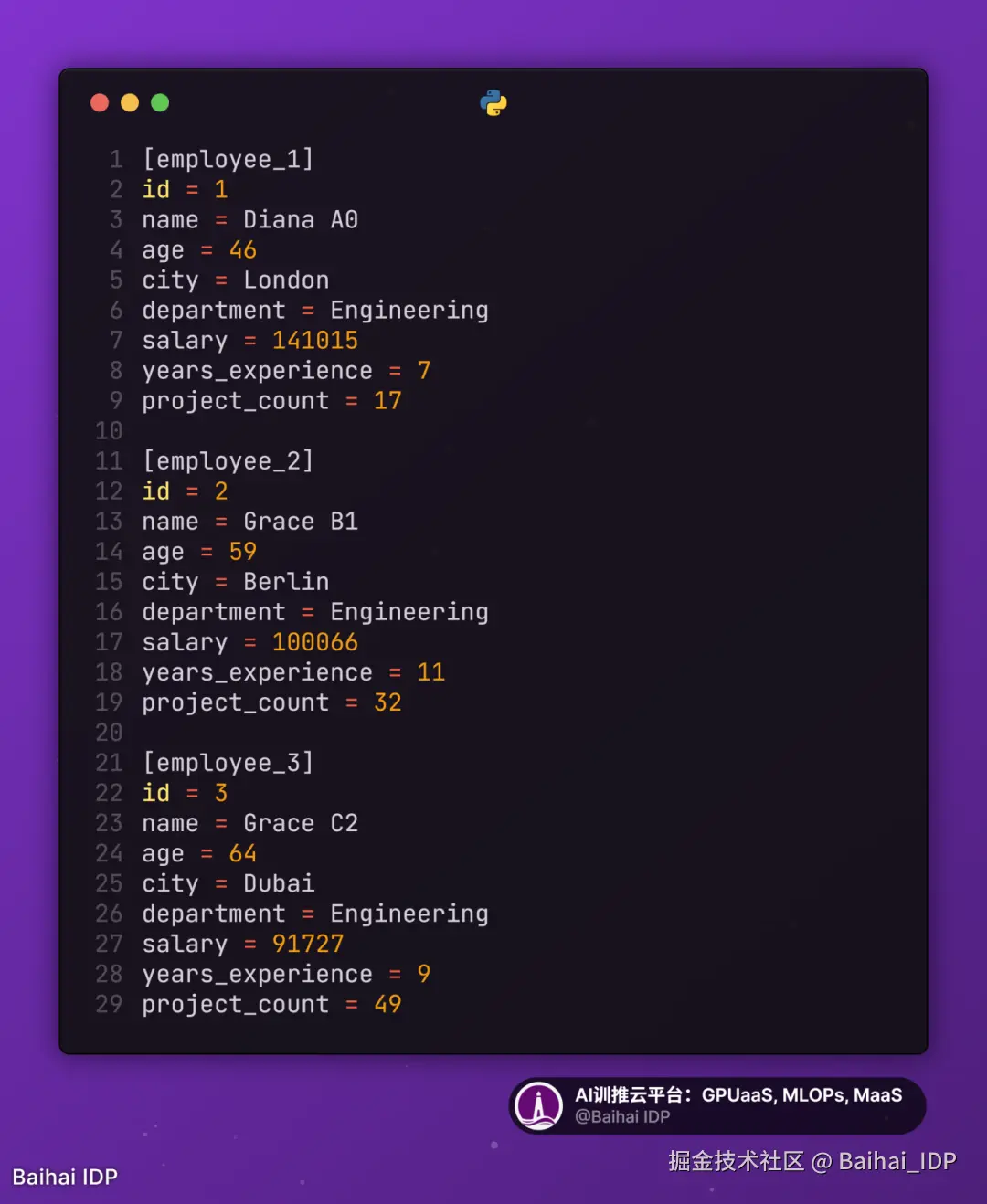
9)Pipe-Delimited

10)JSONL

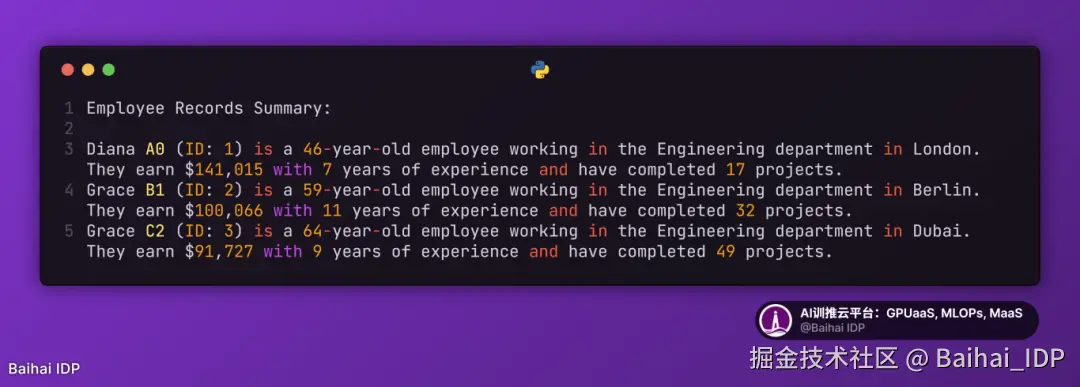
11)Natural Language
06 实用建议
根据我们的实验结果:
- 如果你大量使用表格数据,请考虑测试将数据转换为其他格式是否能提升准确率。
- 在准确率比较重要的场景下,Markdown-KV 可作为首选格式。
- 若需平衡可读性与成本,Markdown 的表格格式值得考虑。
- 慎将 CSV 或 JSONL 作为默认格式 ------ 这些常见格式可能会影响系统的准确性。
07 该实验的局限性与后续研究方向
- 模型与模型提供商: 我们仅测试了 OpenAI 的 GPT-4.1 nano。其他模型(尤其是来自其他提供商的模型)可能在不同数据格式下表现更佳(例如该模型训练时使用最多的格式)。
- 数据内容: 我们仅测试了一种数据模式。使用其他数据模式时,结果可能不同。
- 数据结构: 我们仅测试了简单的表格数据。若测试嵌套数据(如 JSON 配置文件)或包含合并单元格的表格,结果可能更有趣。
- 表格尺寸与表头重复: 为测试模型性能极限,我们使用了相对较大的数据表,且未重复表头。我们预计,更小的表格以及重复表头行会带来更高的准确率,尤其对于 CSV、HTML 和 Markdown table 等依赖表头行的格式。
- 问题类型: 我们的每个测试问题都对应于检索某条记录中某个字段的值。测试其他类型的问题也将很有意义。
END
本期互动内容 🍻
❓你最常使用哪种表格格式?看到 Markdown-KV 格式准确率领先 16% 的结果后,会考虑改变现有实践吗?为什么?
原文链接: