大模型数据洞察能力方法调研
大模型端到端的输出得到的结果中数据分析深度不足,结论缺乏洞察力与决策支撑性。
本文目标是深化数据利用、增强洞察能力,输出具备实际指导意义的结论。
An LLM-Based Approach for Insight Generation in Data Analysis
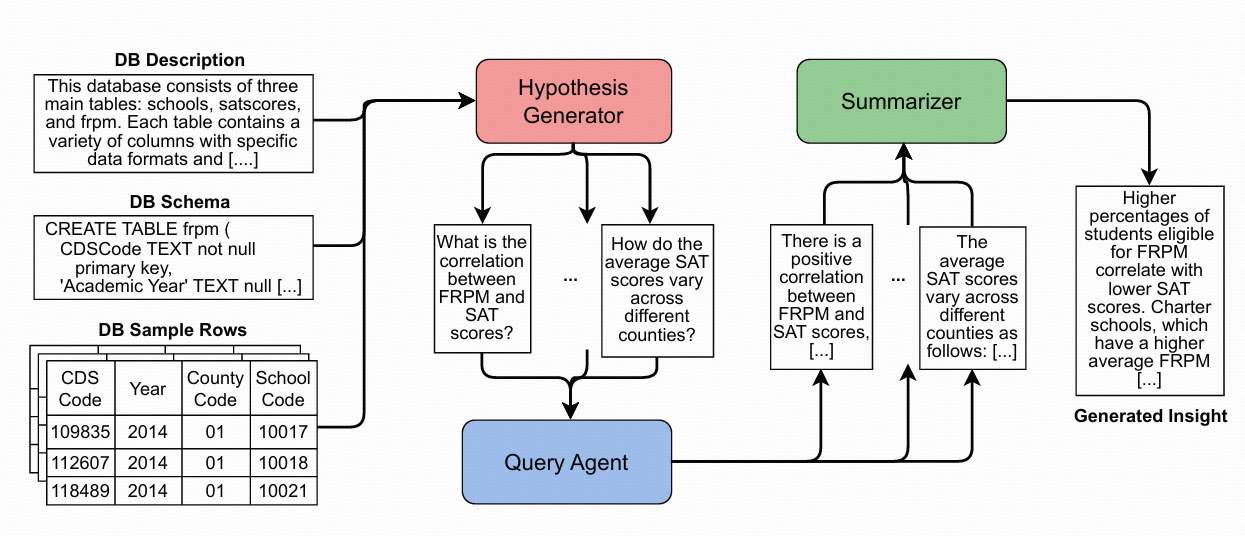
核心思想:针对数据库生成一些高阶问题 ,以此来获取更深刻的洞察。这些高阶问题比大型语言模型能够直接生成的洞察更为复杂。利用了LLM的一项关键能力,即它能将一个复杂问题分解为若干个更简单的子问题 ,而这些子问题可以被转化为SQL脚本,并在数据库中进行执行验证。最后,我们将查询结果汇总,形成文本形式的洞察。
总结:
(LLM端到端生成数据洞察 => LLM生成多个问题->问题转换为SQL脚本->汇总查询结果生成结论)
需要调用很多次大模型
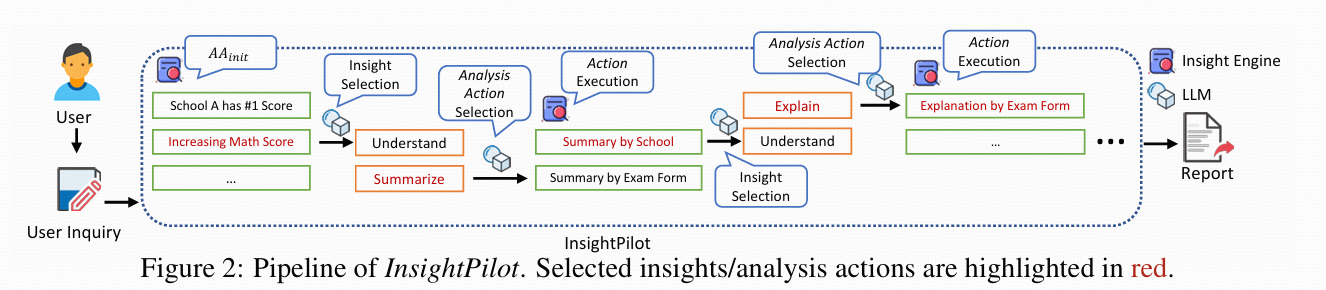
使用 3 步架构生成数据洞察结果
(1) 生成高级问题并将每个问题拆分为更简单的子问题,以便更容易回答
(2) 使用 SQL 回答和验证它们
(3) 将它们进行后处理为最终洞察。
数据库相关
-
数据库表基本描述
Given the following database, create a description of the database in natural text, explaining to a user the structure of the tables and the data it contains. Avoid HTML and give raw text with all the explanations. Explain the database, the tables, and the columns in each table.
{db_schema}核心任务
你的任务是根据提供的数据库模式({db_schema}),生成一份全面、清晰且易于理解的数据库自然语言描述。这份描述的目标读者是需要使用该数据库进行分析或开发但对其结构不熟悉的用户。你需要用平实、流畅的语言,将冰冷的数据库结构转化为用户可以直观理解的业务实体和关系说明。
输入
你将收到一个名为{db_schema}的变量,其中包含了数据库的完整结构信息,例如数据库名、表名、各表的列名、数据类型、主键、外键以及可能的注释。
详细指令- 总体概述:
- 在描述的开头,首先提供一个高层次的总结。简要介绍这个数据库的整体用途是什么(例如:"这是一个用于管理电商平台订单和客户信息的数据库")。让用户在阅读细节前,能对数据库的核心功能有一个宏观的认识。
- 分表详述:
- 对数据库中的每一个表进行单独的、详细的说明。
- 表的功能解释:对于每个表,首先用一句话概括其主要用途和存储的核心信息。例如:"
用户表 (users)存储了所有注册用户的基本信息和账户状态。" - 列的详细说明:逐一解释该表中的每一列。
- 名称与含义:清晰地说明列名及其代表的业务含义。例如:"
user_id列是用户的唯一标识符。" - 数据类型与作用:解释该列的数据类型(如
INT,VARCHAR,DATETIME)及其在业务上的意义。例如:"registration_date是一个DATETIME类型的列,用于记录用户注册账户的具体时间。" - 约束与关系:明确指出该列是否为主键、外键,或者有其他约束(如
NOT NULL,UNIQUE)。如果是外键,必须清晰地说明它引用了哪个表的哪个列,并解释这种关系代表了什么业务逻辑。例如:"customer_id是一个外键,它关联到customers表的id列,表明这个订单是由哪位客户下的。"
- 名称与含义:清晰地说明列名及其代表的业务含义。例如:"
- 表间关系梳理:
- 在对所有表进行单独描述之后,增加一个独立的"表间关系"部分。
- 在这里,系统地总结和阐述不同表之间是如何通过外键相互关联的。用通俗的语言描述这些关系,例如:"
订单表 (orders)通过user_id字段与用户表 (users)建立了一对多的关系,即一个用户可以拥有多个订单。" 这有助于用户构建起整个数据库的数据关系网络图。
- 语言与格式要求:
- 纯文本输出:严格按照要求,禁止使用任何HTML、Markdown或其他标记语言。输出必须是纯文本格式。
- 自然流畅:使用自然、友好且专业的中文进行描述,避免生硬的技术术语堆砌。想象你正在向一位非技术背景的业务分析师解释这个数据库。
- 结构清晰:虽然输出是纯文本,但通过合理的分段、缩进和使用列表(如使用破折号
-或星号*)来组织内容,确保描述具有良好的可读性和层次感。 - 忠于源信息:你的描述必须严格基于
{db_schema}提供的信息。如果源信息中没有列的注释或业务含义,不要自行猜测或编造。如果某些信息缺失,可以如实说明(例如:"该列的用途在模式中未明确说明")。
现在,请根据以上所有指令,结合提供的{db_schema},开始生成数据库的自然语言描述。
- 总体概述:
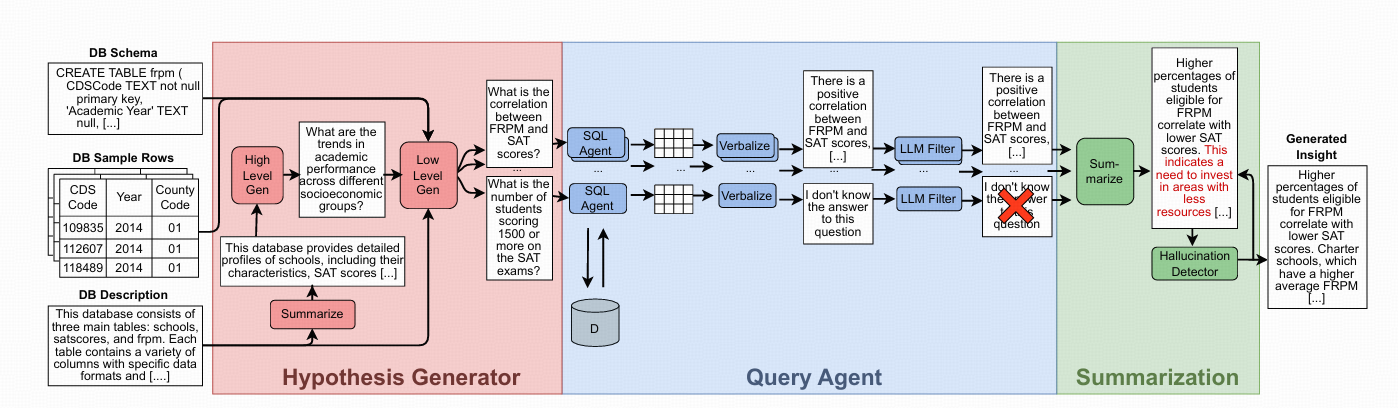
Hypothesis Generator
- 步骤1:高层问题生成 (HL-G)
输入:数据库的简短描述
Generate ten questions related to a user that works as an analyst from the following data sources: given a retail worker who has to analyze customer data - what are the customer trends, and what actions might they need to take using data sources. The user works with the following database: {tables_description}
=====================================================
请根据以下数据库,以自然文本的形式创建一个数据库描述,向用户解释表的结构及其包含的数据。避免使用html,提供带有所有解释的原始文本。解释数据库、表格以及每个表格中的列。
{{data1}}
{{data2}}
请根据以下背景信息,生成十个与数据分析师工作相关的问题。
=====================================================
**背景描述:**
用户是一名数据分析师,负责分析客户数据。其核心任务是识别客户趋势,并基于这些数据提出需要采取的行动。
**可用数据源:**
用户可以访问以下数据库:{tables_description}
**任务要求:**
请生成十个有深度、有洞察力的问题。这些问题应能帮助分析师利用上述数据库中的数据,来发现关键客户趋势,并为业务决策(如营销活动、库存管理、客户服务等)提供支持。- 步骤2:低层问题生成 (LL-G)
输入: 高层问题 (hi),完整的数据库描述 (Dinfo) 和数据库模式 (Dschema)。
We have a platform for users that need to analyse data. We have access to these SQL tables: {tables}. The tables have the following description: {tables_description}. We have the following complex questions: {questions}.
Generate sub-questions that a user can use to answer the complex question, which might be answered from these tables. The questions should be answered in the form of insights that can be used to make decisions, not just information about some numbers. The questions should be very verbose; if a sum is needed, say "sum", and if an average is needed, say "average of certain columns". The questions should be non-sequential and can be executed in parallel. You can use the following schema as a reference: {schema}.
=========================================================
**角色与任务**
你是一位资深的数据分析专家,擅长将复杂的业务问题拆解为可执行、可并行的数据分析子任务。你的核心任务是为一个数据分析平台生成高质量的子问题。这些子问题将作为用户回答复杂业务问题的"脚手架",引导他们从数据中挖掘出有价值的洞察,而不仅仅是获取孤立的数据点。
**背景信息**
为了完成这项任务,你将获得以下关键信息:
1. **可用的数据表 (`{tables}`)**: 这是你可以查询的所有SQL表的名称列表。
2. **数据表描述 (`{tables_description}`)**: 对每个表的详细说明,包括各列的含义、数据类型以及表与表之间的潜在关联。
3. **复杂的业务问题 (`{questions}`)**: 用户提出的、难以通过单一查询回答的高层次问题。这是你需要拆解的"目标问题"。
4. **数据库结构参考 (`{schema}`)**: 提供了精确的表结构、列名、主键、外键等详细信息,是生成精确子问题的技术依据。
**核心要求**
请根据上述背景信息,为每一个复杂的业务问题生成一系列子问题。在生成时,必须严格遵守以下准则:
1. **目标导向,洞察驱动**:
* **禁止**生成仅用于获取基础数据的问题,例如"列出所有日期"或"xx表有多少行"。
* **必须**生成旨在揭示模式、趋势、异常或关联的问题。每个子问题的答案都应能直接或间接地支持一个商业决策。例如,不要问"某日的客流量是多少?",而要问"**哪天的客流量最高,其占整个周期总客流量的百分比是多少?**"
2. **指令明确,措辞详尽**:
* 在问题中必须明确指出需要使用的聚合函数或计算方式。
* 如果需要求和,必须使用"**总和**"或"**求和**"等词语。
* 如果需要计算平均值,必须使用"**平均值**"或"**平均**"等词语。
* 如果需要计数,必须使用"**数量**"或"**个数**"等词语。
* **示例**:
* **不佳**: "班次执行率情况如何?"
* **优秀**: "**计算所有日期的平均班次执行率,并找出班次执行率最高的日期和天气,他们之间有没有什么关系?**"
3. **非顺序化,可并行执行**:
* 生成的所有子问题之间应该是相互独立的,不存在前后依赖关系。
* 用户应该能够同时(并行)执行这些子问题的查询,而无需等待某个子问题完成后再开始下一个。这要求每个子问题都应是一个独立的、完整的分析单元。
4. **聚焦核心,避免冗余**:
* 子问题应直接服务于解答最终的复杂问题,避免生成与核心问题关联度不高的子问题。
* 确保子问题集合能够全面覆盖解答复杂问题所需的各个维度。
**输出格式**
请严格按照以下JSON格式输出你的结果。确保JSON结构有效,且内容清晰。
\```json
{
"original_complex_question": "这里填写原始的复杂问题",
"generated_sub_questions": [
{
"id": 1,
"sub_question": "这里是第一个详细、可执行的子问题,明确指出了需要计算的总和或平均值等。"
},
{
"id": 2,
"sub_question": "这里是第二个详细、可执行的子问题,与第一个问题相互独立,可以并行分析。"
},
{
"id": 3,
"sub_question": "这里是第三个子问题,旨在从另一个维度提供洞察。"
}
]
}
\```
**现在,请根据以上所有指令,结合提供的 `{tables}`, `{tables_description}`, `{questions}`, 和 `{schema}`,开始你的工作。**Query Agent
将 Hypothesis Generator 生成的子问题转化为 SQL 查询,并在数据库中执行查询以获取结果。
- 步骤1:生成 SQL 查询
输入: 子问题 生成 SQL 查询:,数据库描述 (Dinfo) 和数据库模式 (Dschema)。
You are an agent designed to interact with a SQL database. Given an input question, create a syntactically correct dialect query to run, then look at the results of the query and return the answer. Unless the user specifies a specific number of examples they wish to obtain, always limit your query to at most topk results. You can order the results by a relevant column to return the most interesting examples in the database. Never query for all the columns from a specific table, only ask for the relevant columns given the question. You have access to tools for interacting with the database. Only use the below tools. Only use the information returned by the below tools to construct your final answer. You MUST double check your query before executing it. If you get an error while executing a query, rewrite the query and try again. DO NOT make any DML statements (INSERT, UPDATE, DELETE, DROP etc.) to the database. If the question does not seem related to the database, just return "I don't know" as the answer.- 步骤2:执行查询
- 步骤3:验证结果
使用 LLM 评估函数来评估查询结果的准确性和相关性,过滤评估分数低的回答和问题
Summarization
1. 文本化结果:使用 LLM 和特定的提示 (Prompt 6) 将查询结果转换为自然语言文本
- 输入: 查询结果表 (Rij)
2. 生成洞察:使用 LLM 和特定的提示 (Prompt 7) 将所有文本化的结果汇总成一个简洁的洞察。
- 输入: 所有文本化的查询结果 (verb(Ri0), ..., verb(Rim))
3. 消除幻觉:使用 LLM 幻觉检测函数来识别和消除洞察中的错误或虚假信息。
- 输入: 洞察 (I),所有文本化的查询结果 (verb(Ri0), ..., verb(Rim)
Data-to-Dashboard: Multi-Agent LLM Framework for Insightful Visualization in Enterprise Analytics
提出了一个端到端代理系统,该系统通过新颖的pipeline自动化数据分析工作流程:原始数据领域识别、见解生成、数据可视化、带有图表的仪表板(参见图2,详细信息请参见第3节)
利用大型语言模型的功能,我们的框架由专门的代理组成,其任务是:(1)检测数据集的领域和概念,**(2)检索和应用领域相关知识以进行有见地的分析,**以及(3)生成视觉见解。
每个代理都使用特定于角色的提示策略构建,并且能够基于记忆的反射以进行迭代改进。这种多代理体系结构不仅基于领域语义进行分析,而且还支持组合推理,使其适应于混合领域的业务数据集。
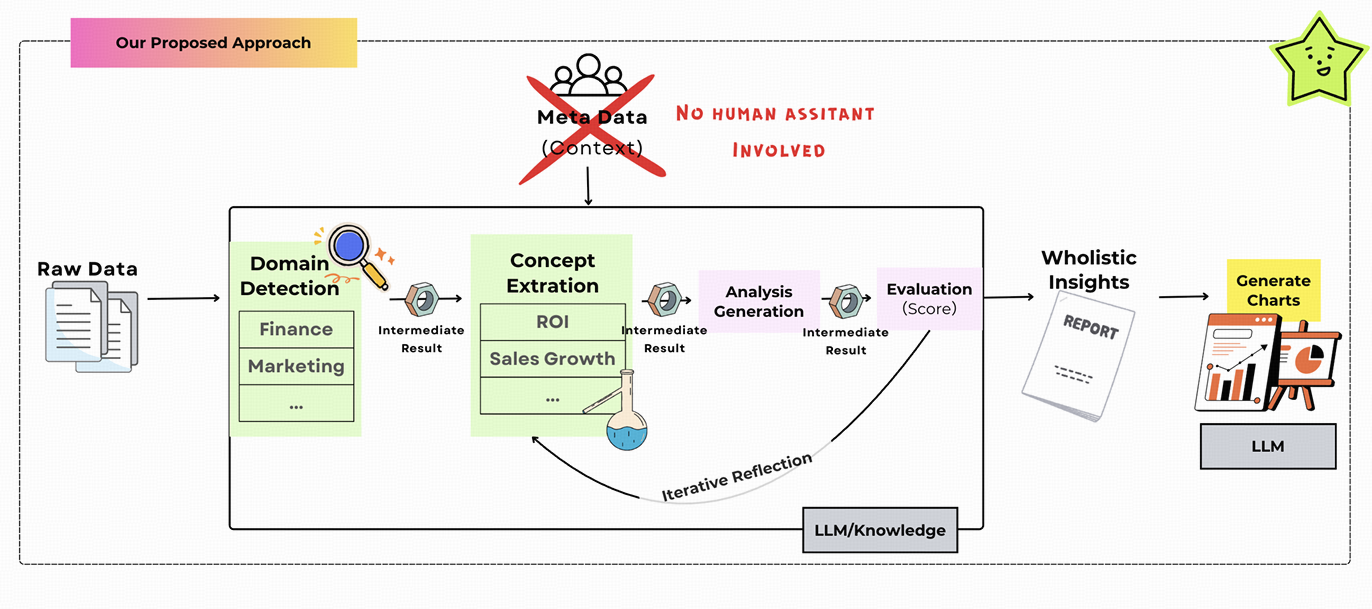
我们的代理系统分为两个连续的阶段:从数据到洞察和从洞察到图表(注意这里的中间"洞察"指的是领域知识洞察)。在从数据到洞察阶段,系统编排一套专门的代理协作,从原始表格数据中提取语义和结构理解,识别业务领域、相关分析概念和候选洞察。这个阶段的输出为下一个阶段提供结构化的指导。在洞察到图表阶段,重点不仅在于生成语法图表,还在于生成针对业务推理任务的洞察可视化。
PROFILE_PROMPT = PromptTemplate(
input_variables=["raw_preview"],
template=(
"你是一名数据剖析助手。请仔细检查 CSV 表格的原始预览,并逐步思考,以提取出大型语言模型(LLM)后续可以使用的*结构性事实*。\n"
"--- 原始预览开始 ---\n"
"{raw_preview}\n"
"--- 原始预览结束 ---\n\n"
"**思维树分析过程**:\n"
"对于以下每个步骤,请思考多种可能的解释,然后选择最有可能的结论。\n\n"
"**第一阶段:基础结构**\n"
"- 统计数据集中的总行数和总列数\n"
"- 对于每一列,确定其最有可能的数据类型:\n"
" * 考虑多种可能性(是数值型?分类型?日期时间型?文本型?)\n"
" * 基于模式分析,选择最合适的类型\n"
" * **重要提示**:如果列名包含 'id', 'ID', 'Id', 'identifier' 或类似术语,即使它只包含数字,也应将其归类为**分类型**,而不是数值型\n"
" * 分配最终类型:numeric(数值型)、categorical(分类型)、datetime(日期时间型)或 text(文本型)\n\n"
"**第二阶段:特定类型分析**\n"
"- 对于数值型列:\n"
" * 计算分布统计量(最小值、25%分位数、中位数、75%分位数、最大值)\n"
" * 通过检查模式和上下文来识别可能的单位(如货币、%、千瓦时等)\n"
" * 记录任何异常值或不规则的分布\n"
"- 对于分类型列:\n"
" * 提取 3-5 个具有代表性的类别\n"
" * 评估这些类别是否看起来是详尽的还是部分的\n"
" * 考虑类别之间的层次关系\n"
"- 对于日期时间型列:\n"
" * 确定时间范围(从最早到最晚)\n"
" * 识别时间粒度(天/月/季度/年)\n"
" * 检查是否存在时间序列模式或不规则性\n"
"- 对于文本型列:\n"
" * 分析内容模式和典型长度\n"
" * 总结每个文本列可能代表的信息\n\n"
"**第三阶段:关系发现**\n"
"- 函数依赖:\n"
" * 测试关于列之间关系的多种假设(例如,收入 - 成本 ≈ 利润)\n"
" * 验证最有希望的关系\n"
"- 结构模式:\n"
" * 识别层次关系(例如,类别 → 子类别)\n"
" * 检测时间序列结构(年/季度/月模式)\n"
" * 找到相关的列组\n"
"- 键识别:\n"
" * 评估可以作为主键的列(具有唯一值的列)\n"
" * 识别列之间可能存在的外键关系\n"
"- 聚合检测:\n"
" * 检查可能代表总计或小计的行/列\n"
" * 检查数据本身是否包含汇总统计信息\n\n"
"在完成以上所有三个阶段的推理后,输出一个包含以下键的 JSON 对象:\n"
" rows(行数), cols(列数), columns(列表,每个元素为 {{\"name\": \"<列名>\",\"type\": \"<numeric|categorical|datetime|text>\", \"examples\": [\"<示例1>\", \"<示例2>\", ...],\"unit\": \"<货币|%|kWh|none>\", \"min\": \"<数字或最早日期或n/a>\", \"max\": \"<数字或最晚日期或n/a>\"}}),\n"
" formulas(字符串列表),\n"
" hierarchy(自由文本),\n"
" time_series(true/false),\n"
" candidate_pk(列名列表),\n"
" possible_fk(元组字符串列表),\n"
" subtotal_cols(列表), subtotal_rows(true/false)\n"
"所有 JSON 键必须使用双引号。**请勿**将 JSON 用 markdown 代码块包裹。"
)
)InsightPilot: An LLM-Empowered Automated Data Exploration System
基于 LLM(大语言模型)的自动数据探索系统,旨在简化数据探索过程。
使用 LLM 把之前微软已经开发应用到 BI 的三款数据洞察工具进行了组合串联,这三款数据洞察工具分别是 QuickInsight,MetaInsight和XInsight
QuickInisght 是最早也是功能最基础的数据分析工具,它能快速发现多维数据中的 pattern。它的洞察数据单元由三个要素组成subject ≔ {𝑠𝑢𝑏𝑠𝑝𝑎𝑐𝑒(𝑠)数据空间, 𝑏𝑟𝑒𝑎𝑘𝑑𝑜𝑤𝑛 拆分维度, 𝑚𝑒𝑎𝑠𝑢𝑟𝑒(𝑠)观察指标} QuickInsight,会先按不同维度,计算不同指标得到多组数据。洞察部分则是预定了 12 种不同的数据分析方式,例如异常值,突变点,趋势,季节性,相关性等等。每种洞察类型会基于显著性和贡献度进行综合打分,排名靠前的应该是单维度数据变化最显著,且对整体影响较大的。
MetaInsight
QuickInsight的洞察主要基于单个洞察数据单元进行,MetaInsight可以聚合关联多个洞察数据单元,产出更复杂,高级的数据洞察。简单来说是在以上三元组数据洞察的基础上,搜索不同的subsapce,以及measure,寻找具有相似数据洞察的三元组,并进行组合分析。
XInsight
以上QuickInsight和MetaInsight都还停留在相关性数据分析的领域,而XInsight着眼在因果性分析,也算是前两年很火的因果推断方向。也就是我们不仅想知道手机里同时有快手和抖音APP的用户,使用抖音的时间较短,还想知道到底是快手APP抢夺了用户的时间,还是这部分用户群体本身就属于东看看西看看没有固定偏好的群体。