一.项目概述
用python写的一个机器学习工程化项目,目前仅将模型保存至文件夹下,包括数据读取、删除等全通过文件的形式。不建议用于生产环境当中。
项目整体结构如图
machine-learning.py是工程化代码,.pkl为训练完成之后保存的模型,.json为模型信息。
二.接口列表
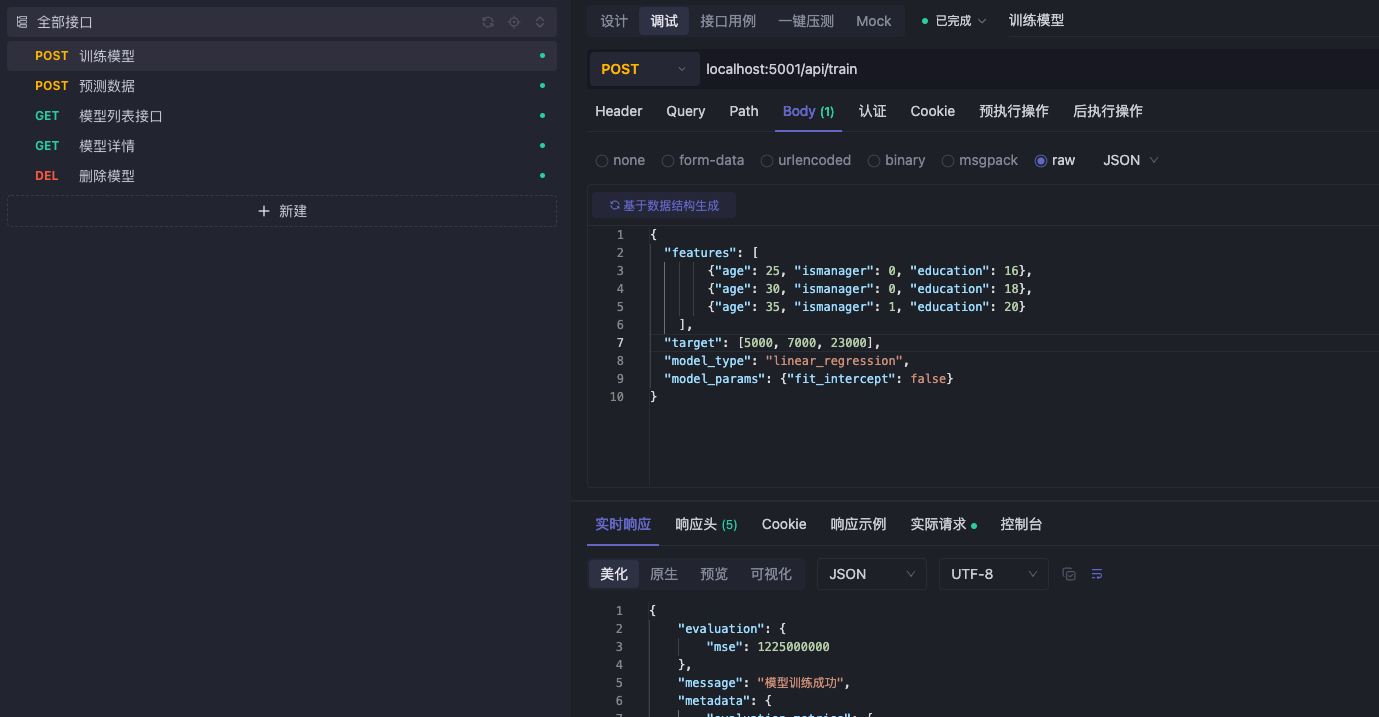
1.训练模型接口
url:localhost:5001/api/train POST
入参:
python
{
"features": [
{"age": 25, "ismanager": 0, "education": 16},
{"age": 30, "ismanager": 0, "education": 18},
{"age": 35, "ismanager": 1, "education": 20}
],
"target": [5000, 7000, 23000],
"model_type": "linear_regression",
"model_params": {"fit_intercept": false}
}返回:
python
{
"evaluation": {
"mse": 1225000000
},
"message": "模型训练成功",
"metadata": {
"evaluation_metrics": {
"mse": 1225000000
},
"feature_count": 3,
"feature_names": [
"age",
"ismanager",
"education"
],
"is_classification": false,
"model_id": "b1679812-9566-4f8b-a78a-735af78c51d1",
"model_params": {
"fit_intercept": false
},
"model_type": "linear_regression",
"sample_count": 3,
"training_date": "2025-11-13T10:08:09.474895"
},
"model_id": "b1679812-9566-4f8b-a78a-735af78c51d1",
"success": true
}训练完成之后,项目的saved_models文件夹下会生产对应模型id的pkl文件和json文件。
2.预测数据
url:localhost:5001/api/predict POST
入参:
python
{
"model_id": "b1679812-9566-4f8b-a78a-735af78c51d1",
"features": [
{"age": 40, "ismanager": 1, "education": 20}
]
}返回:
python
{
"model_id": "b1679812-9566-4f8b-a78a-735af78c51d1",
"model_type": "linear_regression",
"prediction_count": 1,
"predictions": [
41499.99999999999
],
"success": true
}3.模型接口列表
url:localhost:5001/api/models GET
返回:
python
{
"models": [
{
"feature_count": 3,
"model_id": "b1679812-9566-4f8b-a78a-735af78c51d1",
"model_type": "linear_regression",
"sample_count": 3,
"training_date": "2025-11-13T10:08:09.474895"
}
],
"success": true,
"total_models": 1
}4.模型详情接口
url:localhost:5001/api/models/<model_id> GET
返回:
python
{
"model_info": {
"evaluation_metrics": {
"mse": 0
},
"feature_count": 3,
"feature_names": [
"age",
"income",
"education"
],
"is_classification": false,
"model_id": "d73983a0-a15f-4ea2-b968-d399464cf4cd",
"model_params": {
"fit_intercept": false
},
"model_type": "linear_regression",
"sample_count": 3,
"training_date": "2025-11-12T16:50:14.160146"
},
"success": true
}5.删除模型
url:localhost:5001/api/models/<model_id> DELETE
返回:
python
{
"success": true
}三.源码
python
from flask import Flask, request, jsonify
import pandas as pd
import numpy as np
import pickle
import uuid
import os
from datetime import datetime
from sklearn.ensemble import RandomForestClassifier, RandomForestRegressor
from sklearn.linear_model import LinearRegression, LogisticRegression
from sklearn.svm import SVC, SVR
from sklearn.tree import DecisionTreeClassifier, DecisionTreeRegressor
from sklearn.preprocessing import StandardScaler, LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, mean_squared_error
import json
app = Flask(__name__)
# 存储模型和元数据的字典
models_storage = {}
models_metadata = {}
# 确保模型存储目录存在
MODEL_DIR = "saved_models"
if not os.path.exists(MODEL_DIR):
os.makedirs(MODEL_DIR)
class ModelManager:
"""模型管理器类"""
# 支持的模型映射
MODEL_MAP = {
'random_forest_classifier': RandomForestClassifier,
'random_forest_regressor': RandomForestRegressor,
'linear_regression': LinearRegression,
'logistic_regression': LogisticRegression,
'svm_classifier': SVC,
'svm_regressor': SVR,
'decision_tree_classifier': DecisionTreeClassifier,
'decision_tree_regressor': DecisionTreeRegressor
}
@staticmethod
def create_model(model_type, **kwargs):
"""创建模型实例"""
if model_type not in ModelManager.MODEL_MAP:
raise ValueError(f"不支持的模型类型: {model_type}")
model_class = ModelManager.MODEL_MAP[model_type]
return model_class(**kwargs)
@staticmethod
def save_model(model, model_id, metadata):
"""保存模型到文件"""
model_path = os.path.join(MODEL_DIR, f"{model_id}.pkl")
metadata_path = os.path.join(MODEL_DIR, f"{model_id}_metadata.json")
# 保存模型
with open(model_path, 'wb') as f:
pickle.dump(model, f)
# 保存元数据
with open(metadata_path, 'w', encoding='utf-8') as f:
json.dump(metadata, f, ensure_ascii=False, indent=2)
@staticmethod
def load_model(model_id):
"""从文件加载模型"""
model_path = os.path.join(MODEL_DIR, f"{model_id}.pkl")
metadata_path = os.path.join(MODEL_DIR, f"{model_id}_metadata.json")
if not os.path.exists(model_path):
return None, None
# 加载模型
with open(model_path, 'rb') as f:
model = pickle.load(f)
# 加载元数据
with open(metadata_path, 'r', encoding='utf-8') as f:
metadata = json.load(f)
return model, metadata
@app.route('/api/train', methods=['POST'])
def train_model():
"""
训练模型接口
输入: 特征数据、目标值、模型类型、参数
输出: 模型ID和训练结果
"""
try:
# 获取请求数据
data = request.get_json()
# 验证必需字段
required_fields = ['features', 'target', 'model_type']
for field in required_fields:
if field not in data:
return jsonify({
'success': False,
'error': f'缺少必需字段: {field}'
}), 400
features = data['features']
target = data['target']
model_type = data['model_type']
model_params = data.get('model_params', {})
# 验证数据格式
if not isinstance(features, list) or not isinstance(target, list):
return jsonify({
'success': False,
'error': 'features 和 target 必须是列表格式'
}), 400
if len(features) != len(target):
return jsonify({
'success': False,
'error': 'features 和 target 长度不一致'
}), 400
# 转换为DataFrame
try:
X = pd.DataFrame(features)
y = pd.Series(target)
except Exception as e:
return jsonify({
'success': False,
'error': f'数据格式错误: {str(e)}'
}), 400
# 数据预处理
# 处理分类目标变量
if y.dtype == 'object':
le = LabelEncoder()
y_encoded = le.fit_transform(y)
is_classification = True
else:
y_encoded = y
is_classification = len(y.unique()) / len(y) < 0.05 # 简单判断分类还是回归
# 特征标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 划分训练测试集
X_train, X_test, y_train, y_test = train_test_split(
X_scaled, y_encoded, test_size=0.2, random_state=42
)
# 创建和训练模型
try:
model = ModelManager.create_model(model_type, **model_params)
model.fit(X_train, y_train)
except Exception as e:
return jsonify({
'success': False,
'error': f'模型训练失败: {str(e)}'
}), 400
# 模型评估
y_pred = model.predict(X_test)
if is_classification:
accuracy = accuracy_score(y_test, y_pred)
evaluation_metric = {'accuracy': accuracy}
else:
mse = mean_squared_error(y_test, y_pred)
evaluation_metric = {'mse': mse}
# 生成模型ID
model_id = str(uuid.uuid4())
# 准备模型包(包含模型和预处理器)
model_package = {
'model': model,
'scaler': scaler,
'label_encoder': le if is_classification else None,
'is_classification': is_classification,
'feature_names': X.columns.tolist()
}
# 模型元数据
metadata = {
'model_id': model_id,
'model_type': model_type,
'model_params': model_params,
'training_date': datetime.now().isoformat(),
'feature_count': X.shape[1],
'sample_count': X.shape[0],
'is_classification': is_classification,
'evaluation_metrics': evaluation_metric,
'feature_names': X.columns.tolist()
}
# 保存模型
ModelManager.save_model(model_package, model_id, metadata)
# 存储在内存中(可选,用于快速访问)
models_storage[model_id] = model_package
models_metadata[model_id] = metadata
return jsonify({
'success': True,
'model_id': model_id,
'message': '模型训练成功',
'evaluation': evaluation_metric,
'metadata': metadata
}), 200
except Exception as e:
return jsonify({
'success': False,
'error': f'服务器错误: {str(e)}'
}), 500
@app.route('/api/predict', methods=['POST'])
def predict():
"""
预测接口
输入: 模型ID、特征数据
输出: 预测结果
"""
try:
data = request.get_json()
# 验证必需字段
if 'model_id' not in data or 'features' not in data:
return jsonify({
'success': False,
'error': '缺少 model_id 或 features 字段'
}), 400
model_id = data['model_id']
features = data['features']
# 从内存或文件加载模型
if model_id in models_storage:
model_package = models_storage[model_id]
metadata = models_metadata[model_id]
else:
model_package, metadata = ModelManager.load_model(model_id)
if model_package is None:
return jsonify({
'success': False,
'error': '模型不存在或已过期'
}), 404
# 验证特征数据
if not isinstance(features, list):
return jsonify({
'success': False,
'error': 'features 必须是列表格式'
}), 400
# 转换为DataFrame
try:
X_pred = pd.DataFrame(features)
except Exception as e:
return jsonify({
'success': False,
'error': f'特征数据格式错误: {str(e)}'
}), 400
# 检查特征数量
expected_features = metadata['feature_count']
if X_pred.shape[1] != expected_features:
return jsonify({
'success': False,
'error': f'特征数量不匹配。期望: {expected_features}, 实际: {X_pred.shape[1]}'
}), 400
# 数据预处理
scaler = model_package['scaler']
X_pred_scaled = scaler.transform(X_pred)
# 进行预测
model = model_package['model']
predictions = model.predict(X_pred_scaled)
# 如果是分类问题,解码标签
if model_package['is_classification'] and model_package['label_encoder'] is not None:
le = model_package['label_encoder']
predictions = le.inverse_transform(predictions)
# 返回预测结果
return jsonify({
'success': True,
'model_id': model_id,
'predictions': predictions.tolist(),
'prediction_count': len(predictions),
'model_type': metadata['model_type']
}), 200
except Exception as e:
return jsonify({
'success': False,
'error': f'预测失败: {str(e)}'
}), 500
@app.route('/api/models', methods=['GET'])
def list_models():
"""列出所有已训练的模型"""
try:
models_list = []
for model_id, metadata in models_metadata.items():
models_list.append({
'model_id': model_id,
'model_type': metadata['model_type'],
'training_date': metadata['training_date'],
'feature_count': metadata['feature_count'],
'sample_count': metadata['sample_count']
})
return jsonify({
'success': True,
'models': models_list,
'total_models': len(models_list)
}), 200
except Exception as e:
return jsonify({
'success': False,
'error': f'获取模型列表失败: {str(e)}'
}), 500
@app.route('/api/models/<model_id>', methods=['GET'])
def get_model_info(model_id):
"""获取特定模型的详细信息"""
try:
if model_id in models_metadata:
metadata = models_metadata[model_id]
else:
_, metadata = ModelManager.load_model(model_id)
if metadata is None:
return jsonify({
'success': False,
'error': '模型不存在'
}), 404
return jsonify({
'success': True,
'model_info': metadata
}), 200
except Exception as e:
return jsonify({
'success': False,
'error': f'获取模型信息失败: {str(e)}'
}), 500
@app.route('/api/health', methods=['GET'])
def health_check():
"""健康检查接口"""
return jsonify({
'status': 'healthy',
'timestamp': datetime.now().isoformat(),
'models_loaded': len(models_storage)
}), 200
@app.route('/api/models/<model_id>', methods=['DELETE'])
def delete_model(model_id):
"""删除模型接口"""
try:
if model_id in models_metadata:
os.remove(MODEL_DIR+"/"+model_id+".pkl")
os.remove(MODEL_DIR+"/"+model_id+"_metadata.json")
else:
_, metadata = ModelManager.load_model(model_id)
if metadata is None:
return jsonify({
'success': False,
'error': '模型不存在'
}), 404
return jsonify({
'success': True,
}), 200
except Exception as e:
return jsonify({
'success': False,
'error': f'删除模型失败: {str(e)}'
}), 500
if __name__ == '__main__':
# 启动时加载已保存的模型
print("正在加载已保存的模型...")
for filename in os.listdir(MODEL_DIR):
if filename.endswith('_metadata.json'):
model_id = filename.replace('_metadata.json', '')
model_package, metadata = ModelManager.load_model(model_id)
if model_package and metadata:
models_storage[model_id] = model_package
models_metadata[model_id] = metadata
print(f"已加载模型: {model_id}")
print(f"已加载 {len(models_storage)} 个模型")
app.run(debug=True, host='0.0.0.0', port=5001)