作者:来自 Elastic Chris Hegarty, Hemant Malik, Corey Nolet 及 5 more

了解 Elasticsearch 如何通过 GPU 加速向量索引和 NVIDIA cuVS 实现近 12 倍更高的索引吞吐量。
从向量搜索到强大的 REST API,Elasticsearch 为开发者提供了最全面的搜索工具包。前往 GitHub 上的示例笔记本尝试新东西。你也可以开始免费试用,或在本地运行Elasticsearch。
今年早些时候,Elastic 宣布与 NVIDIA 合作,将 GPU 加速引入 Elasticsearch,并与 NVIDIA cuVS 集成 ------ 正如在 NVIDIA GTC 的会议和各种博客中详细介绍的那样。本文是对与 NVIDIA 向量搜索团队共同工程进展的更新。
回顾
首先,让我们让你了解最新进展。Elasticsearch 已经成为一个强大的向量数据库,为大规模相似度搜索提供丰富的功能和强劲的性能。凭借标量量化、Better Binary Quantization(BBQ)、SIMD 向量操作,以及像 DiskBBQ 这样更高磁盘效率的算法,它已经为管理向量工作负载提供了高效而灵活的选项。
通过将 NVIDIA cuVS 集成为可调用模块来处理向量搜索任务,我们的目标是为向量索引的性能和效率带来显著提升,以更好地支持大规模向量工作负载。
挑战
构建高性能向量数据库中最困难的挑战之一就是构建向量索引 ------ HNSW 图。当每个向量都要与许多其他向量比较时,索引构建很快就会被数百万甚至数十亿次算术操作所主导。此外,索引生命周期操作(例如压缩和合并)会进一步增加索引的总体计算开销。随着数据量和相关向量嵌入指数级增长,为大规模并行和高吞吐数学运算而构建的 GPU 加速计算非常适合处理这些工作负载。
进入 Elasticsearch-GPU 插件
NVIDIA cuVS 是一个用于 GPU 加速向量搜索和数据聚类的开源 CUDA-X 库,可为 AI 和推荐类工作负载提供快速的索引构建和向量嵌入检索。
Elasticsearch 通过 cuvs-java 使用 cuVS,cuvs-java 是一个由社区开发并由 NVIDIA 维护的开源库。cuvs-java 库轻量级,基于 cuVS 的 C API,并使用 Panama Foreign Function 以符合 Java 习惯的方式暴露 cuVS 功能,同时保持现代化和高性能。
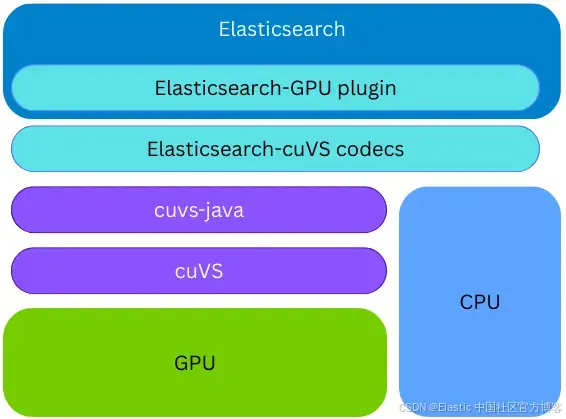
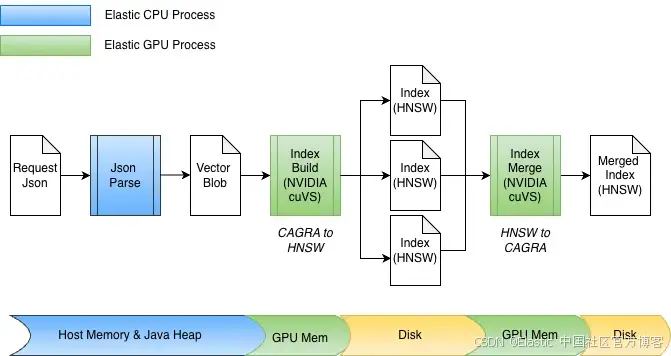
cuvs-java 库被集成到一个新的 Elasticsearch 插件中;因此,GPU 上的向量索引可以在同一个 Elasticsearch 节点和进程中完成,而无需配置任何外部代码或硬件。在索引构建期间,如果安装了 cuVS 库并且存在并配置了 GPU,Elasticsearch 将使用 GPU 来加速向量索引过程。向量会被交给 GPU,由其构建 CAGRA 图。然后,这个图会被转换为 HNSW 格式,从而可以立即在 CPU 上用于向量搜索。构建后的图的最终格式与在 CPU 上构建的相同;这使得 Elasticsearch 在底层硬件支持的情况下能够利用 GPU 进行高吞吐量向量索引,同时释放 CPU 以处理其他任务(并发搜索、数据处理等)。
索引构建加速
作为将 GPU 加速集成进 Elasticsearch 的一部分,cuvs-java 做了多项增强,重点在高效的数据输入/输出和函数调用。一个关键的增强是使用 cuVSMatrix 来透明地表示向量,无论它们位于 Java 堆上、堆外,还是在 GPU 内存中。这使数据能够在内存与 GPU 之间高效移动,避免对可能达数十亿规模的向量进行不必要的拷贝。
得益于这种底层零拷贝抽象,向 GPU 内存传输数据以及取回图都可以直接进行。在索引构建期间,向量首先缓存在 Java 堆的内存中,然后被发送到 GPU 构建 CAGRA 图。随后,该图从 GPU 中取回,被转换为 HNSW 格式,并持久化到磁盘。
在合并阶段,向量已经存储在磁盘上,从而完全绕过 Java 堆。索引文件被内存映射,数据会直接传输到 GPU 内存中。该设计也很容易支持不同的位宽,例如 float32 或 int8,并能自然扩展到其他量化方案。
鼓点响起......那么,它的表现如何?
我们最初的基准测试结果非常令人振奋。我们在一台带有本地 NVMe 存储的 AWS g6.4xlarge 实例上运行了基准测试。Elasticsearch 的单节点被配置为使用默认的、最佳数量的索引线程(8 个------每个物理核心一个),并禁用了合并限速(在快速 NVMe 磁盘下这一点不太适用)。
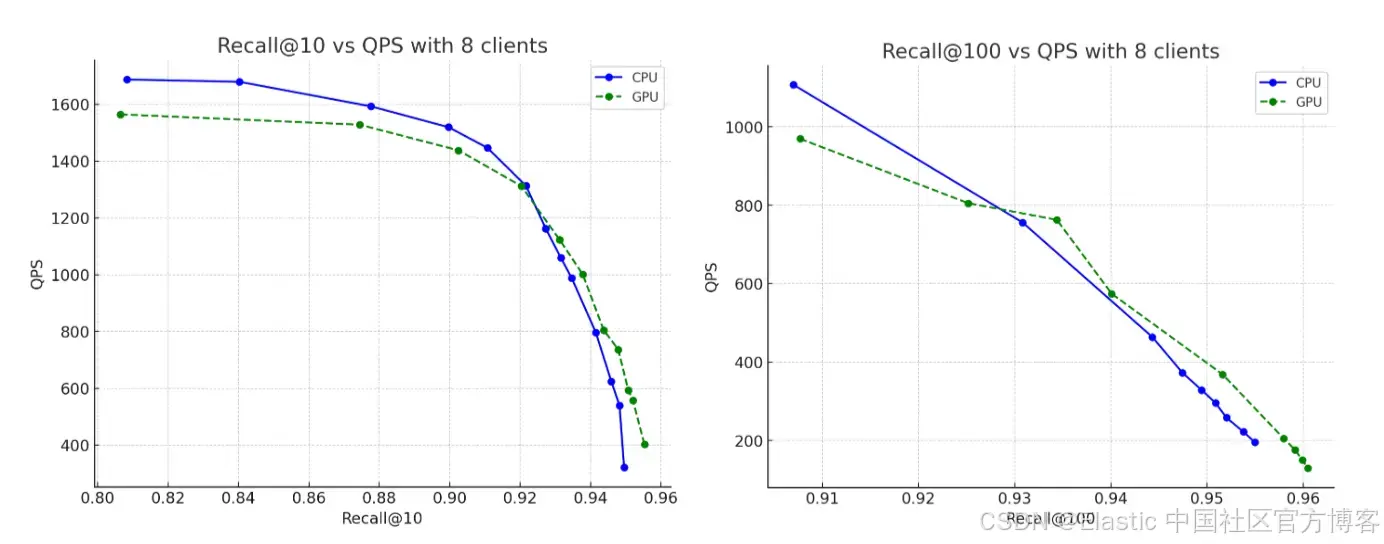
数据集方面,我们使用了来自 OpenAI Rally 向量任务的 260 万个向量,每个向量有 1,536 维,编码为 base64 字符串,并以 float32 hnsw 的方式建立索引。在所有情况下,构建的图都达到了最高 95% 的召回率。以下是我们的发现:
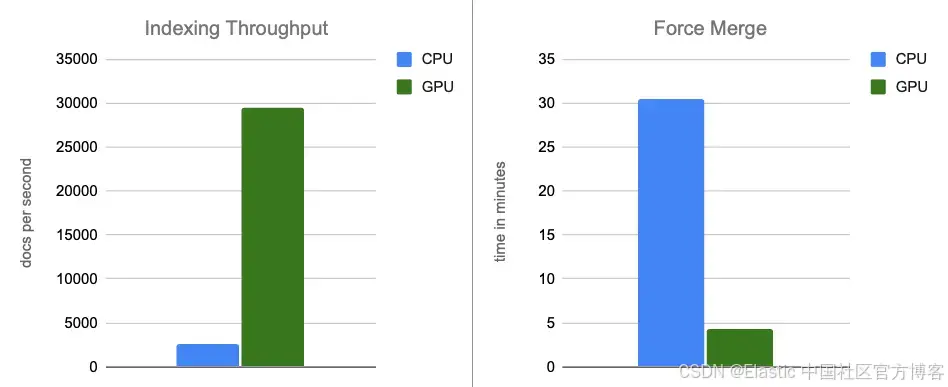
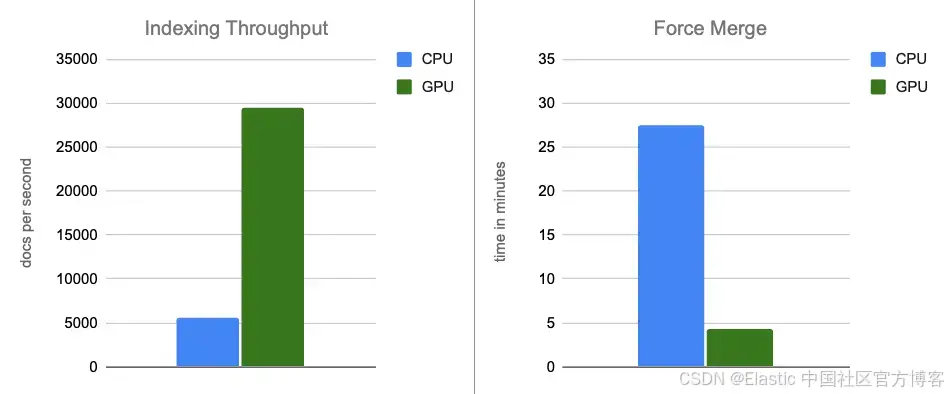
- 索引吞吐量:通过在内存缓冲区刷新的过程中将图构建移至 GPU,我们将吞吐量提高了约 12 倍。
- 强制合并:在索引完成后,GPU 继续加速段合并,使强制合并阶段加速约 7 倍。
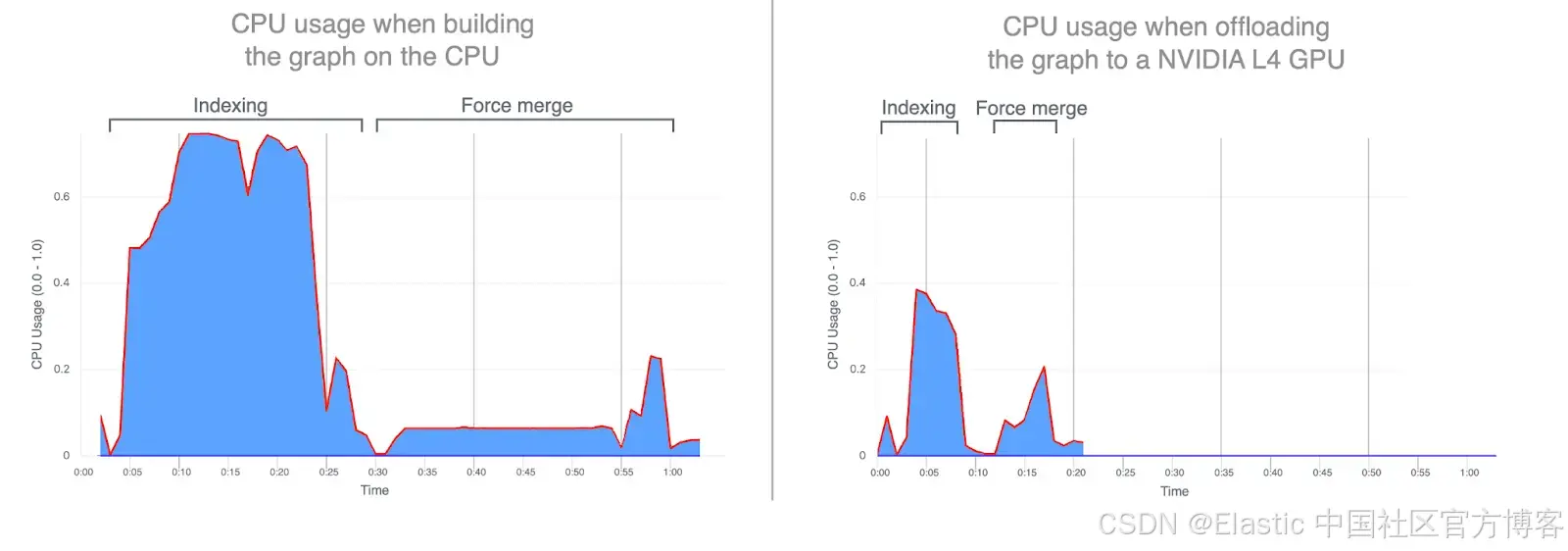
- CPU 使用率:将图构建任务卸载到 GPU 显著降低了平均和峰值 CPU 利用率。下图展示了索引和合并期间的 CPU 使用情况,突显了当这些操作在 GPU 上运行时 CPU 使用率大幅降低。在 GPU 索引期间较低的 CPU 利用率释放了 CPU 周期,可用于提升搜索性能。
- 召回率:CPU 和 GPU 运行之间的准确性基本保持不变,GPU 构建的图的召回率略高一些。
从另一个维度比较:价格
之前的比较故意使用了相同的硬件,唯一的区别是在索引期间是否使用 GPU。这有助于理解纯计算效果,但我们也可以从成本角度来看比较。以大致相同的价格,我们可以配置大约两倍数量的可比 vCPU 和内存。也就是 32 个 vCPU(AMD EPYC)和 64GB 内存,同时将索引线程数量翻倍到 16 个。
更强大的 CPU 实例确实表现出比上节基准更好的性能,这在预期之中。然而,当我们将这个更强大的 CPU 实例与最初的 GPU 加速结果进行比较时,GPU 仍然带来了显著的性能提升:索引吞吐量提高约 5 倍 ,强制合并提高约6 倍 ,同时构建的图的召回率可达 95%。
结论
在端到端场景中,使用 NVIDIA cuVS 的 GPU 加速在索引吞吐量上实现了近 12 倍的提升,强制合并延迟减少约 7 倍,同时 CPU 使用率显著降低。这表明向量索引和合并工作负载能从 GPU 加速中显著受益。在成本调整后的比较中,GPU 加速仍然带来可观的性能提升,索引吞吐量约提高 5 倍,强制合并操作约快 6 倍。
GPU 加速向量索引目前计划在 Elasticsearch 9.3 的技术预览中推出,预计将在 2026 年初发布。
敬请关注更多信息。
原文:https://www.elastic.co/search-labs/blog/elasticsearch-gpu-accelerated-vector-indexing-nvidia