文章目录
- 电商微服务日志处理全方案:从MySQL瓶颈到大数据架构的实战转型
-
- 一、传统日志存储的痛点:为什么必须转型?
- 二、大数据日志处理架构设计:全链路技术栈
- 三、全链路技术实现与选型深度解析
-
- (一)采集层:Filebeat------微服务容器的"日志搬运工"
-
- [1. 技术实现:轻量无侵入的日志采集](#1. 技术实现:轻量无侵入的日志采集)
- [2. 选型解析:为什么是Filebeat?](#2. 选型解析:为什么是Filebeat?)
- (二)缓冲层:Kafka------抗住流量洪峰的"缓冲阀"
-
- [1. 技术实现:高吞吐日志缓冲](#1. 技术实现:高吞吐日志缓冲)
- [2. 选型解析:为什么是Kafka?](#2. 选型解析:为什么是Kafka?)
- (三)处理层:Flink+Spark------实时与离线的"双引擎"
-
- [1. 技术实现:日志清洗与结构化](#1. 技术实现:日志清洗与结构化)
- [2. 选型解析:为什么是Flink+Spark?](#2. 选型解析:为什么是Flink+Spark?)
- (四)存储层:Elasticsearch+HDFS/Hudi------热冷分离的"成本平衡术"
-
- [1. 技术实现:分层存储策略](#1. 技术实现:分层存储策略)
- [2. 选型解析:为什么是ES+HDFS/Hudi?](#2. 选型解析:为什么是ES+HDFS/Hudi?)
- (五)分析层:Kibana+Superset------业务价值的"转化器"
-
- [1. 技术实现:从数据到决策的落地](#1. 技术实现:从数据到决策的落地)
- [2. 选型解析:为什么是Kibana+Superset?](#2. 选型解析:为什么是Kibana+Superset?)
- 四、新旧方案对比与落地建议
-
- [1. 方案对比](#1. 方案对比)
- [2. 落地注意事项](#2. 落地注意事项)
- 总结
电商微服务日志处理全方案:从MySQL瓶颈到大数据架构的实战转型
若对您有帮助的话,请点赞收藏加关注哦,您的关注是我持续创作的动力!有问题请私信或联系邮箱:funian.gm@gmail.com
在电商微服务架构中,用户行为日志是业务优化的核心依据------从商品浏览路径分析到下单转化漏斗监控,每一条日志都隐藏着用户需求与业务痛点。但随着业务增长,传统的"日志写入MySQL"方案会逐渐暴露致命缺陷:高并发写入时的性能瓶颈、非结构化数据的存储冗余、历史数据分析的效率低下......
本文将系统拆解日志处理的完整转型方案,不仅包含从采集到分析的全链路技术实现(附代码),更深入解析每个环节的技术选型逻辑------为什么采集层必须用Filebeat?缓冲层为何选择Kafka?处理层为何是Flink+Spark的组合?带你构建"高吞吐、低成本、可扩展"的电商日志处理体系。
一、传统日志存储的痛点:为什么必须转型?
在微服务初期,很多团队会选择将用户行为日志存入MySQL,典型表结构如下:
sql
CREATE TABLE `user_behavior_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`user_id` varchar(64) DEFAULT NULL COMMENT '用户ID',
`behavior_type` varchar(32) DEFAULT NULL COMMENT '行为类型:浏览/加购/下单',
`product_id` varchar(64) DEFAULT NULL COMMENT '商品ID',
`behavior_time` datetime DEFAULT NULL COMMENT '行为时间',
`ext_info` text COMMENT '扩展信息(JSON格式)',
`service_name` varchar(64) DEFAULT NULL COMMENT '微服务名称',
PRIMARY KEY (`id`),
KEY `idx_user_time` (`user_id`,`behavior_time`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;当日均日志量超过1000万条后,这套方案会面临4大核心问题:
-
写入性能瓶颈
促销活动期间,每秒万级日志写入会引发MySQL行锁竞争,写入延迟从毫秒级飙升至秒级,甚至导致微服务接口超时(日志写入通常是同步操作)。
-
存储成本激增
每条日志的
ext_info字段(如页面停留时间、来源URL)为非结构化JSON,MySQL行存储会产生大量冗余。按1000万条/天计算,单表年数据量超300亿条,需每月分表,运维成本极高。 -
查询效率低下
分析"近30天用户购买路径"时,需扫描数十亿行数据,即使加索引也需数小时,远无法满足业务实时性要求。
-
功能局限性
无法直接解析JSON字段(需用
JSON_EXTRACT等低效函数),更无法实现复杂的用户行为序列分析(如漏斗转化、路径挖掘)。
二、大数据日志处理架构设计:全链路技术栈
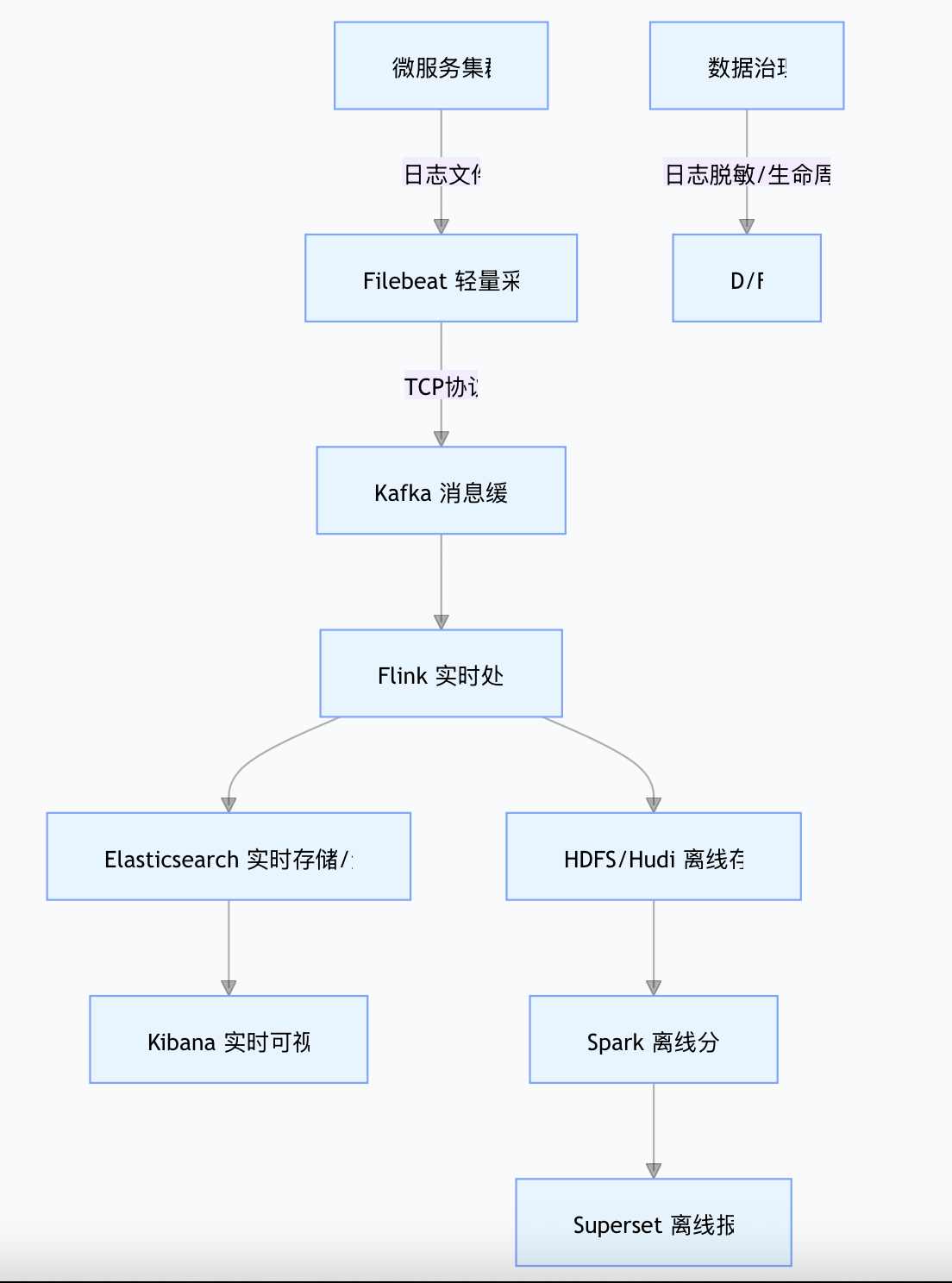
针对上述痛点,我们设计了一套"高吞吐写入、低成本存储、灵活分析"的架构,各组件职责与协作流程如下:
日志文件 TCP协议 微服务集群 Filebeat 轻量采集 Kafka 消息缓冲 Flink 实时处理 Elasticsearch 热数据存储 HDFS/Hudi 冷数据归档 Kibana 实时监控/告警 Spark 离线分析 Superset 离线报表
核心技术栈选型逻辑:
- 采集层:Filebeat(轻量无侵入,适配容器环境)
- 缓冲层:Kafka(高吞吐抗峰值,解耦上下游)
- 处理层:Flink(实时清洗结构化)+ Spark(离线批量计算)
- 存储层:Elasticsearch(近7天热数据,实时查询)+ HDFS/Hudi(冷数据,低成本归档)
- 分析层:Kibana(实时监控告警)+ Superset(离线深度分析)
三、全链路技术实现与选型深度解析
(一)采集层:Filebeat------微服务容器的"日志搬运工"
1. 技术实现:轻量无侵入的日志采集
日志标准化输出:微服务需按JSON格式输出日志(固定字段+扩展字段),示例:
json
{
"log_time": "2025-11-13 10:05:23.123", // 日志时间
"user_id": "U123456", // 用户ID(匿名用户用设备ID)
"behavior_type": "browse", // 行为类型
"product_id": "P7890", // 商品ID
"page_url": "/product/detail?pid=P7890",// 页面URL
"service_name": "product-service", // 微服务名称
"ext_info": { // 扩展信息
"stay_time": 15, // 停留时间(秒)
"referer": "/category/electronics" // 来源页面
}
}Spring Boot日志配置(logback-spring.xml):
xml
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>/var/log/ecommerce/${SPRING_APPLICATION_NAME}/behavior.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>/var/log/ecommerce/${SPRING_APPLICATION_NAME}/behavior.%d{yyyy-MM-dd}.log</fileNamePattern>
<maxHistory>7</maxHistory> <!-- 本地保留7天日志 -->
</rollingPolicy>
<encoder class="net.logstash.logback.encoder.LogstashEncoder">
<includeMdcKeyName>user_id</includeMdcKeyName>
<includeMdcKeyName>product_id</includeMdcKeyName>
<fieldNames>
<timestamp>log_time</timestamp>
<message>behavior_type</message>
</fieldNames>
</encoder>
</appender>Filebeat配置(filebeat.yml):
yaml
filebeat.inputs:
- type: filestream
enabled: true
paths:
- /var/log/ecommerce/*/behavior.log # 采集所有微服务日志
parsers:
- ndjson: # 解析JSON格式
keys_under_root: true
overwrite_keys: true
output.kafka:
hosts: ["kafka-node1:9092", "kafka-node2:9092"]
topic: "ecommerce-user-behavior"
partition.hash:
partition: 12 # 12个分区(按微服务数量配置)
keys: ["service_name"] # 按服务名分区
compression: gzip # 压缩传输2. 选型解析:为什么是Filebeat?
-
轻量适配容器环境
微服务容器资源有限(通常1-2GB内存),Filebeat基于Go语言开发,启动仅占用10-20MB内存(Logstash基于JVM,需200MB+),可直接部署在每个容器中,不挤压业务资源。
-
无侵入解耦业务
若在微服务代码中直接写入Kafka(如Logback的Kafka Appender),会导致业务代码与日志采集耦合(Kafka地址变更需改代码),且Kafka故障可能阻塞业务线程。Filebeat通过"本地文件→采集"模式完全解耦,即使下游故障,日志也会暂存本地(支持断点续传)。
-
高可靠保障日志完整
Filebeat通过
registry文件记录采集偏移量,容器重启后不会重复采集或丢失日志,解决微服务动态扩缩容场景下的日志完整性问题。
(二)缓冲层:Kafka------抗住流量洪峰的"缓冲阀"
1. 技术实现:高吞吐日志缓冲
Kafka主题创建:
bash
# 12个分区,3个副本(支撑十万级/秒写入)
bin/kafka-topics.sh --create \
--bootstrap-server kafka-node1:9092 \
--topic ecommerce-user-behavior \
--partitions 12 \
--replication-factor 3 \
--config retention.ms=604800000 # 日志保留7天2. 选型解析:为什么是Kafka?
-
高吞吐抗住促销峰值
电商日志流量具有突发性(日常1万条/秒,促销10万条/秒),Kafka单分区支持10万条/秒写入(多分区可线性扩展),而RabbitMQ单节点仅1万条/秒,无法支撑峰值。
-
削峰填谷保护下游
下游Flink/ES的处理能力有限(如Flink单节点5万条/秒),Kafka可暂存峰值日志,让下游按自身能力匀速消费,避免被"冲垮"。
-
多消费者组复用日志
同一日志可被多个消费者组消费(如Flink实时处理组、Spark离线备份组),实现"一份日志,多场景复用"。
(三)处理层:Flink+Spark------实时与离线的"双引擎"
1. 技术实现:日志清洗与结构化
Flink实时处理代码:
java
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.elasticsearch7.ElasticsearchSink;
import com.alibaba.fastjson.JSONObject;
import java.util.Properties;
public class LogProcessor {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(60000); // 1分钟Checkpoint
// 1. 读取Kafka日志
Properties kafkaProps = new Properties();
kafkaProps.setProperty("bootstrap.servers", "kafka-node1:9092");
kafkaProps.setProperty("group.id", "log-processor");
FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<>(
"ecommerce-user-behavior",
new SimpleStringSchema(),
kafkaProps
);
var logStream = env.addSource(consumer);
// 2. 清洗:过滤无效日志(缺失user_id/product_id)
var validStream = logStream.filter(log -> {
try {
JSONObject json = JSONObject.parseObject(log);
return json.containsKey("user_id") && json.containsKey("product_id");
} catch (Exception e) {
return false; // 过滤非JSON格式日志
}
});
// 3. 结构化:补全字段+转换时间格式
var structuredStream = validStream.map(log -> {
JSONObject json = JSONObject.parseObject(log);
// 补全缺失的停留时间
json.getJSONObject("ext_info").putIfAbsent("stay_time", 0);
// 转换为时间戳(便于排序)
String logTime = json.getString("log_time");
json.put("log_timestamp", DateUtils.parse(logTime).getTime());
return json;
});
// 4. 写入ES(热数据)
List<HttpHost> esHosts = Arrays.asList(new HttpHost("es-node1", 9200));
ElasticsearchSink.Builder<JSONObject> esSink = new ElasticsearchSink.Builder<>(
esHosts,
(log, ctx, indexer) -> {
String index = "behavior-" + log.getString("log_time").substring(0, 10);
indexer.add(Requests.indexRequest().index(index).source(log.toString(), XContentType.JSON));
}
);
structuredStream.addSink(esSink.build());
// 5. 写入HDFS(冷数据,按小时分区)
structuredStream.map(JSONObject::toString)
.addSink(new BucketingSink<>("/user/ecommerce/logs")
.setBucketer(new DateTimeBucketer<>("yyyy-MM-dd/HH")));
env.execute("Log Processing");
}
}Spark离线分析代码(用户转化漏斗):
scala
import org.apache.spark.sql.SparkSession
object FunnelAnalysis {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.appName("Funnel Analysis")
.enableHiveSupport()
.getOrCreate()
// 读取近30天日志
val behaviorDF = spark.sql(
"""
|SELECT user_id, product_id, behavior_type, log_time
|FROM user_behavior_hudi
|WHERE dt >= date_sub(current_date(), 30)
|""".stripMargin)
// 计算浏览→加购→下单转化率
val funnelDF = behaviorDF
.groupBy("user_id", "product_id")
.agg(collect_list(struct("behavior_type", "log_time")).alias("actions"))
.map(row => {
val actions = row.getAs[Seq[Row]]("actions").sortBy(_.getString(1))
val hasBrowse = actions.exists(_.getString(0) == "browse")
val hasAddCart = actions.exists(_.getString(0) == "add_cart")
val hasPurchase = actions.exists(_.getString(0) == "purchase")
(hasBrowse, hasAddCart, hasPurchase)
})
.toDF("browse", "add_cart", "purchase")
// 输出转化率
funnelDF.select(
avg(when($"browse", 1).otherwise(0)).alias("浏览率"),
avg(when($"add_cart", 1).otherwise(0)).alias("加购率"),
avg(when($"purchase", 1).otherwise(0)).alias("下单率")
).show()
}
}2. 选型解析:为什么是Flink+Spark?
-
Flink:实时处理的"低延迟王者"
实时监控(如运营看板)要求秒级延迟,Flink基于原生流处理(非Spark Streaming的微批),延迟可低至毫秒级;Checkpoint机制确保数据不丢不重,适合日志清洗等关键场景。
-
Spark:离线计算的"效率之王"
分析30天历史日志(数十亿条)时,Spark的内存计算比MapReduce快10倍以上,且Spark SQL支持复杂查询,降低业务人员使用门槛槛;MLlib库还可扩展至用户画像等高级场景。
-
双引擎互补:不可替代的组合
只用Flink处理离线任务会浪费资源(实时集群闲置),只用Spark处理实时任务无法满足秒级延迟,两者结合完美覆盖"实时+离线"全场景。
(四)存储层:Elasticsearch+HDFS/Hudi------热冷分离的"成本平衡术"
1. 技术实现:分层存储策略
Elasticsearch索引设计:
json
PUT _index_template/behavior_template
{
"index_patterns": ["behavior-*"],
"settings": {
"number_of_shards": 5,
"number_of_replicas": 1
},
"mappings": {
"properties": {
"user_id": {"type": "keyword"}, // 精确查询
"product_id": {"type": "keyword"},
"behavior_type": {"type": "keyword"},
"log_time": {"type": "date", "format": "yyyy-MM-dd HH:mm:ss.SSS"},
"page_url": {"type": "text", "analyzer": "ik_smart"} // 全文检索
}
}
}Hudi冷数据存储(Hive外部表):
sql
CREATE EXTERNAL TABLE user_behavior_hudi (
user_id STRING,
product_id STRING,
behavior_type STRING,
log_time STRING,
ext_info MAP<STRING, STRING>
)
PARTITIONED BY (dt STRING) // 按天分区
STORED AS INPUTFORMAT 'org.apache.hudi.hadoop.HoodieParquetInputFormat'
OUTPUTFORMAT 'org.apache.hudi.hadoop.HoodieParquetOutputFormat'
LOCATION 'hdfs:///user/ecommerce/logs';2. 选型解析:为什么是ES+HDFS/Hudi?
-
Elasticsearch:热数据的"实时查询引擎"
近7天的日志需支持多维度检索(如"查询用户U123的加购行为"),ES的倒排索引可实现毫秒级响应;全文检索能力支持URL、来源页等文本字段分析,这是MySQL无法实现的。
-
HDFS/Hudi:冷数据的"低成本归档库"
7天前的日志访问频率低(如月度报表),HDFS基于普通硬盘存储,单TB成本仅为SSD的1/5;Hudi支持增量更新(如补录漏报日志)和时间旅行查询,解决传统HDFS文件不可修改的痛点。
-
热冷分离:性能与成本的最优平衡
全用ES存储会导致成本激增(10TB数据成本超10万元),全用HDFS会导致实时查询延迟达分钟级,分层存储可降低60%+成本,同时保证热数据查询性能。
(五)分析层:Kibana+Superset------业务价值的"转化器"
1. 技术实现:从数据到决策的落地
Kibana实时监控 :
创建实时仪表盘,包含UV/PV趋势、行为类型占比、热门商品TOP10等指标。示例查询(近5分钟UV):
json
{
"aggs": {
"unique_users": {
"cardinality": {"field": "user_id", "precision_threshold": 100000}
}
},
"query": {
"range": {"log_timestamp": {"gte": "now-5m", "lte": "now"}}
}
}Superset离线报表 :
配置"用户转化漏斗"报表,定时生成并推送。支持关联订单表,分析"行为→下单"全链路转化。
2. 选型解析:为什么是Kibana+Superset?
-
Kibana:实时监控的"零代码工具"
运营人员无需编写SQL,通过拖拽即可创建实时仪表盘,支持异常告警(如"加购量骤降50%"),快速响应业务波动。
-
Superset:离线分析的"多源集成平台"
支持关联Hive、MySQL等多数据源,生成漏斗图、桑基图等复杂图表,满足"用户留存分析""商品路径挖掘"等深度需求。
-
场景互补:覆盖全业务视角
Kibana解决"实时监控与异常响应",Superset解决"离线复盘与策略优化",共同形成"监控-分析-决策"闭环。
四、新旧方案对比与落地建议
1. 方案对比
| 指标 | 传统MySQL方案 | 大数据架构方案 |
|---|---|---|
| 写入性能 | 万级/秒(易瓶颈) | 十万级/秒(支撑促销峰值) |
| 存储成本 | 高(GB级收费,冗余大) | 低(TB级收费,压缩率高) |
| 查询响应时间 | 分钟级(历史数据) | 秒级(ES实时)/分钟级(Spark离线) |
| 分析能力 | 简单聚合(GROUP BY) | 支持漏斗、路径、用户分群等 |
2. 落地注意事项
- 日志格式规范:强制微服务输出统一JSON格式,避免下游处理混乱;
- 资源隔离:Flink/Spark集群与业务微服务物理隔离,避免资源竞争;
- 数据生命周期:ES索引7天后自动删除,Hudi数据保留1年(按合规要求调整);
- 敏感信息脱敏 :Flink处理时对手机号、地址等脱敏(如
138****1234)。
总结
电商微服务日志处理的转型,本质是用"分布式架构"解决"高并发、大容量、多场景"的核心矛盾。从Filebeat的轻量采集到Kafka的流量缓冲,从Flink的实时处理到Spark的离线分析,从ES的热数据查询到HDFS的冷数据归档,每个技术组件的选择都精准匹配业务需求------最终实现"日志不丢、处理不堵、查询不慢、成本不高"的目标。
这套架构不仅能支撑日均亿级日志的处理,更能通过用户行为数据反哺业务(如个性化推荐、转化路径优化),让日志真正成为电商增长的"数据燃料"。