问题
我在使用显卡时发现,vllm会倾向用直接占用所有显存,纵然是一个很小的模型的情况下。我更期待在同一张先看上部署多个模型,并行使用。
实验环境
本次实验的模型选择qwen3-0.6b-fp8模型,他的参数占用只有小小的0.71gb。剩余的全是其他类型的占用。
本次实验的主要参数是:调整--gpu-memory-utilization、--max-model-len。
--gpu-memory-utilization:代表gpu的使用率,vllm默认为0.8
--max-model-len:代表模型的最长长度,qwen3-0.6b默认为40960
--block-size:代表KV Cache 的块大小,默认为16
对比结果:
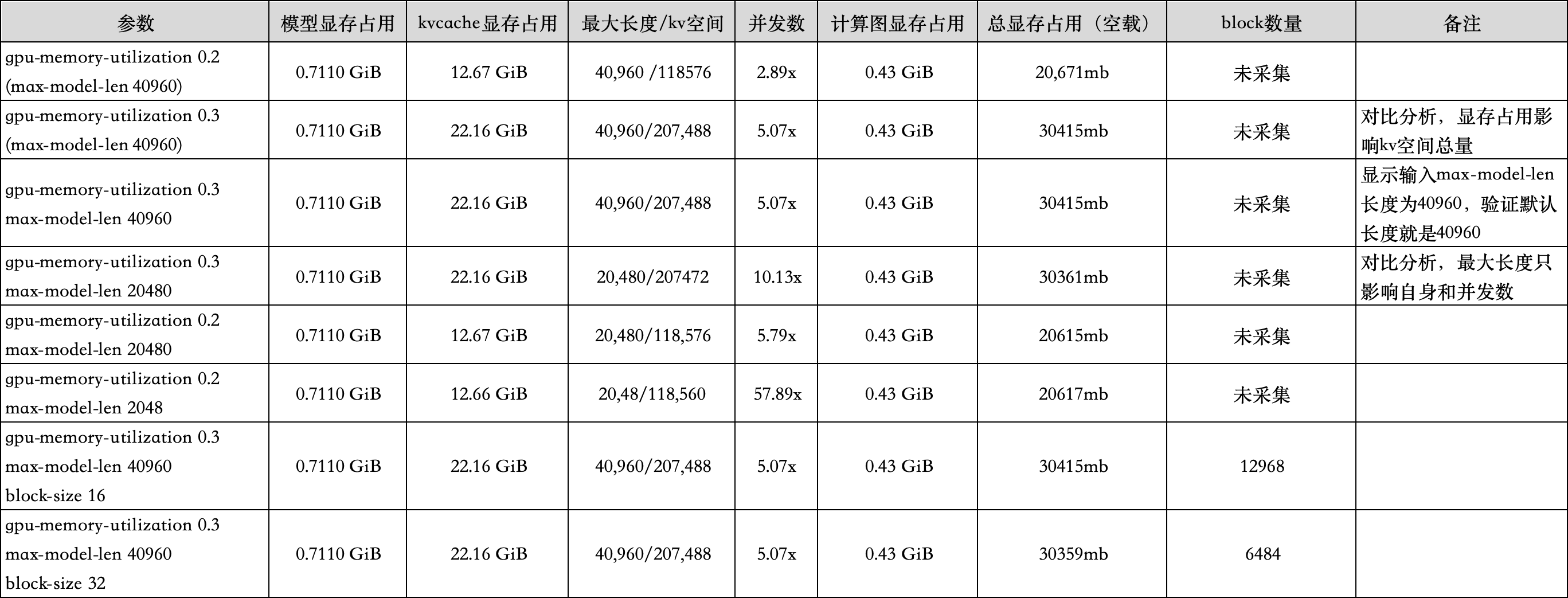
结论:
max-model-len等比例显著影响kvcache的使用率。gpu-memory-utilization控制能够使用的显存总量,总量内部划分各种需求。block-size大会在相同的kv空间占据更大的显存,即管理颗粒度更加粗放。
原始记录
#使用命令
VLLM_USE_MODELSCOPE=true vllm serve Qwen/Qwen3-0.6B-FP8 --reasoning-parser deepseek_r1 --gpu-memory-utilization 0.2
#一些关键信息
(EngineCore_DP0 pid=604868) INFO 11-13 15:35:17 [gpu_model_runner.py:2653] Model loading took 0.7110 GiB and 1.033386 seconds
......
(EngineCore_DP0 pid=604868) INFO 11-13 15:35:28 [gpu_worker.py:298] Available KV cache memory: 12.67 GiB
(EngineCore_DP0 pid=604868) INFO 11-13 15:35:28 [kv_cache_utils.py:1087] GPU KV cache size: 118,576 tokens
(EngineCore_DP0 pid=604868) INFO 11-13 15:35:28 [kv_cache_utils.py:1091] Maximum concurrency for 40,960 tokens per request: 2.89x
......
(EngineCore_DP0 pid=604868) INFO 11-13 15:35:36 [gpu_model_runner.py:3480] Graph capturing finished in 7 secs, took 0.43 GiB实际显存占用情况

#使用命令
VLLM_USE_MODELSCOPE=true vllm serve Qwen/Qwen3-0.6B-FP8 --reasoning-parser deepseek_r1 --gpu-memory-utilization 0.3
#一些关键信息
(EngineCore_DP0 pid=610223) INFO 11-13 15:42:01 [gpu_model_runner.py:2653] Model loading took 0.7110 GiB and 1.116882 seconds
......
(EngineCore_DP0 pid=610223) INFO 11-13 15:42:12 [gpu_worker.py:298] Available KV cache memory: 22.16 GiB
(EngineCore_DP0 pid=610223) INFO 11-13 15:42:12 [kv_cache_utils.py:1087] GPU KV cache size: 207,488 tokens
(EngineCore_DP0 pid=610223) INFO 11-13 15:42:12 [kv_cache_utils.py:1091] Maximum concurrency for 40,960 tokens per request: 5.07x
......
(EngineCore_DP0 pid=610223) INFO 11-13 15:42:20 [gpu_model_runner.py:3480] Graph capturing finished in 8 secs, took 0.43 GiB实际显存占用情况

#使用命令
VLLM_USE_MODELSCOPE=true vllm serve Qwen/Qwen3-0.6B-FP8 --reasoning-parser deepseek_r1 --gpu-memory-utilization 0.3 --max-model-len 40960
#一些关键信息
(EngineCore_DP0 pid=616627) INFO 11-13 15:46:15 [gpu_model_runner.py:2653] Model loading took 0.7110 GiB and 1.265348 seconds
(EngineCore_DP0 pid=616627) INFO 11-13 15:46:26 [gpu_worker.py:298] Available KV cache memory: 22.16 GiB
(EngineCore_DP0 pid=616627) INFO 11-13 15:46:26 [kv_cache_utils.py:1087] GPU KV cache size: 207,488 tokens
(EngineCore_DP0 pid=616627) INFO 11-13 15:46:26 [kv_cache_utils.py:1091] Maximum concurrency for 40,960 tokens per request: 5.07x
(EngineCore_DP0 pid=616627) INFO 11-13 15:46:34 [gpu_model_runner.py:3480] Graph capturing finished in 8 secs, took 0.43 GiB
#使用命令
VLLM_USE_MODELSCOPE=true vllm serve Qwen/Qwen3-0.6B-FP8 --reasoning-parser deepseek_r1 --gpu-memory-utilization 0.3 --max-model-len 20480
#一些关键信息
(EngineCore_DP0 pid=622553) INFO 11-13 15:49:56 [gpu_model_runner.py:2653] Model loading took 0.7110 GiB and 1.018419 seconds
(EngineCore_DP0 pid=622553) INFO 11-13 15:50:41 [gpu_worker.py:298] Available KV cache memory: 22.16 GiB
(EngineCore_DP0 pid=622553) INFO 11-13 15:50:42 [kv_cache_utils.py:1087] GPU KV cache size: 207,472 tokens
(EngineCore_DP0 pid=622553) INFO 11-13 15:50:42 [kv_cache_utils.py:1091] Maximum concurrency for 20,480 tokens per request: 10.13x
(EngineCore_DP0 pid=622553) INFO 11-13 15:50:50 [gpu_model_runner.py:3480] Graph capturing finished in 8 secs, took 0.43 GiB
#使用命令
VLLM_USE_MODELSCOPE=true vllm serve Qwen/Qwen3-0.6B-FP8 --reasoning-parser deepseek_r1 --gpu-memory-utilization 0.2 --max-model-len 20480
#一些关键信息
(EngineCore_DP0 pid=628922) INFO 11-13 15:53:36 [gpu_model_runner.py:2653] Model loading took 0.7110 GiB and 1.109638 seconds
(EngineCore_DP0 pid=628922) INFO 11-13 15:53:47 [gpu_worker.py:298] Available KV cache memory: 12.67 GiB
(EngineCore_DP0 pid=628922) INFO 11-13 15:53:47 [kv_cache_utils.py:1087] GPU KV cache size: 118,576 tokens
(EngineCore_DP0 pid=628922) INFO 11-13 15:53:47 [kv_cache_utils.py:1091] Maximum concurrency for 20,480 tokens per request: 5.79x
(EngineCore_DP0 pid=628922) INFO 11-13 15:53:55 [gpu_model_runner.py:3480] Graph capturing finished in 7 secs, took 0.43 GiB
#使用命令
VLLM_USE_MODELSCOPE=true vllm serve Qwen/Qwen3-0.6B-FP8 --reasoning-parser deepseek_r1 --gpu-memory-utilization 0.2 --max-model-len 2048
#一些关键信息
(EngineCore_DP0 pid=643965) INFO 11-13 16:03:12 [gpu_model_runner.py:2653] Model loading took 0.7110 GiB and 1.059420 seconds
(EngineCore_DP0 pid=643965) INFO 11-13 16:03:57 [gpu_worker.py:298] Available KV cache memory: 12.66 GiB
(EngineCore_DP0 pid=643965) INFO 11-13 16:03:57 [kv_cache_utils.py:1087] GPU KV cache size: 118,560 tokens
(EngineCore_DP0 pid=643965) INFO 11-13 16:03:57 [kv_cache_utils.py:1091] Maximum concurrency for 2,048 tokens per request: 57.89x
(EngineCore_DP0 pid=643965) INFO 11-13 16:04:05 [gpu_model_runner.py:3480] Graph capturing finished in 8 secs, took 0.43 GiB
#使用命令
VLLM_USE_MODELSCOPE=true vllm serve Qwen/Qwen3-0.6B-FP8 --reasoning-parser deepseek_r1 --gpu-memory-utilization 0.3 --max-model-len 40960 --block-size 32
#一些关键信息
(EngineCore_DP0 pid=685002) INFO 11-14 08:13:45 [gpu_model_runner.py:2653] Model loading took 0.7110 GiB and 1.045983 seconds
(EngineCore_DP0 pid=685002) INFO 11-14 08:13:56 [gpu_worker.py:298] Available KV cache memory: 22.16 GiB
(EngineCore_DP0 pid=685002) INFO 11-14 08:13:57 [kv_cache_utils.py:1087] GPU KV cache size: 207,488 tokens
(EngineCore_DP0 pid=685002) INFO 11-14 08:13:57 [kv_cache_utils.py:1091] Maximum concurrency for 40,960 tokens per request: 5.07x
(EngineCore_DP0 pid=685002) INFO 11-14 08:14:04 [gpu_model_runner.py:3480] Graph capturing finished in 8 secs, took 0.43 GiB
(APIServer pid=684662) INFO 11-14 08:14:06 [loggers.py:147] Engine 000: vllm cache_config_info with initialization after num_gpu_blocks is: 6484
#使用命令
VLLM_USE_MODELSCOPE=true vllm serve Qwen/Qwen3-0.6B-FP8 --reasoning-parser deepseek_r1 --gpu-memory-utilization 0.3 --max-model-len 40960 --block-size 16
#一些关键信息
(EngineCore_DP0 pid=693725) INFO 11-14 08:19:15 [gpu_model_runner.py:2653] Model loading took 0.7110 GiB and 1.071295 seconds
(EngineCore_DP0 pid=693725) INFO 11-14 08:19:26 [gpu_worker.py:298] Available KV cache memory: 22.16 GiB
(EngineCore_DP0 pid=693725) INFO 11-14 08:19:26 [kv_cache_utils.py:1087] GPU KV cache size: 207,488 tokens
(EngineCore_DP0 pid=693725) INFO 11-14 08:19:26 [kv_cache_utils.py:1091] Maximum concurrency for 40,960 tokens per request: 5.07x
(EngineCore_DP0 pid=693725) INFO 11-14 08:19:34 [gpu_model_runner.py:3480] Graph capturing finished in 8 secs, took 0.43 GiB
(APIServer pid=693380) INFO 11-14 08:19:36 [loggers.py:147] Engine 000: vllm cache_config_info with initialization after num_gpu_blocks is: 12968
进行对话会显著提升gpu的使用率,但是并不会提升显存使用。
