2025 年 11 月,由谢赛宁领导,杨立昆(Yann LeCun)、李飞飞(Li Fei-Fei)参与指导的团队的新论文"Cambrian-S: Towards Spatial Supersensing in Video"的起点。
论文地址: Cambrian-S: Towards Spatial Supersensing in Video
项目地址:https://github.com/cambrian-mllm/cambrian-s
这篇文章明确地将世界模型视为实现空间超感知这一宏伟目标的最终阶段和核心能力。它诊断了当前 MLLMs 在此方面的不足,并提出了"预测性感知"作为一条具体的、以自监督学习为基础的路径,以开始构建这些至关重要的内部世界模型。
现在先用一个简单的例子来解释"世界模型",想象一下一个婴儿。当一个婴儿刚出生时,他对周围的世界知之甚少。他会看到、听到、摸到各种东西,但这些都只是零散的感官信息。
随着他长大,他开始学习和理解世界是如何运作的:
- 他扔出一个球,球会掉到地上(重力)。
- 他藏在毯子后面,虽然他看不见妈妈,但他知道妈妈还在那里(客体永久性)。
- 他搭积木,知道如果把重心放歪了,积木塔就会倒(物理定律)。
- 他饿了会哭,然后妈妈会来喂奶(因果关系和社会互动)。
所有这些"知道"和"理解",并不是他每次都重新从零开始思考。而是他大脑中逐渐形成了一套关于"世界是如何运作的"的内在规则和预测机制。这套内在的、隐性的规则,就是他的**"世界模型"**。
"世界模型"可以理解为:
- 你大脑里的一套模拟器(Simulator)或预测器(Predictor): 它不是一个真实的世界,而是你对真实世界工作原理的一种内在模拟和预测。就像你心里有一个小小的"小世界",它能模拟出"如果你这样做,接下来会发生什么"。
- 它帮助你理解和解释现象: 当你看到一个新事物,你会用你已有的"世界模型"去解释它,而不是觉得一切都是随机的。
- 它帮助你做决策和规划: 因为你能预测未来,你就能决定"现在做什么"来达到你想要的结果。比如,你知道天要下雨了(预测),所以你会带伞(决策)。
- 它通过"惊喜"来学习和更新: 当你的预测出错了,比如你以为球会往上飞,结果掉下来了,这个"惊喜"(预测误差)就会促使你修正你的"世界模型",让它变得更准确。
所以,对于 AI 来说:
一个 AI 的"世界模型"就是它内部构建的、对它所处环境的动态和规律的理解。它能让 AI:
- 预测未来: 比如,视频的下一帧会是什么样子?
- 理解因果: 如果我推这个方块,它会怎么移动?
- 进行规划: 为了从 A 到 B,我应该怎么走?
- 更高效地学习: 不用每次都从头体验,而是通过内在的模拟来学习。
这篇论文中的 Predictive World Modeling 和 Predictive Sensing,就是希望 AI 也能拥有这样一个"小世界模拟器",尤其是在处理视频这种连续、动态的感官信息时。它不再是被动地接收信息,而是主动地预测、理解、学习,就像我们人类一样。
希望这个解释能帮助您更好地理解"世界模型"!
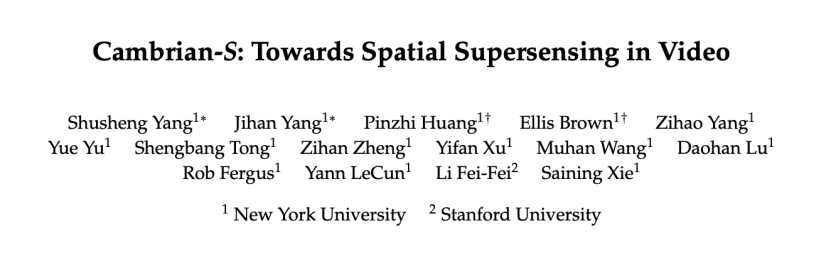
- 该论文提出多模态智能应从被动任务驱动和暴力长上下文转向"空间超感知"范式,涵盖语义感知、流式事件认知、隐式3D空间认知和预测性世界建模,以克服当前多模态大语言模型(MLLMs)在长视频空间推理中的局限。
- 为推动这一领域发展,研究人员引入了VSI-SUPER基准测试和VSI-590K空间感知数据集,并训练了Cambrian-S模型;尽管Cambrian-S在现有空间认知任务上表现出色,但在VSI-SUPER上仍面临挑战,表明仅靠数据和模型规模不足以实现真正的空间超感知。
- 论文进而提出"预测性感官"新范式,通过自监督的下一潜在帧预测利用"惊喜"(预测误差)来驱动记忆管理和事件分割,该方法在VSI-SUPER任务上显著优于现有长上下文基线模型,证明模型需要主动预测、选择和组织经验。
该论文提出,要实现真正的多模态智能,需要从任务驱动和蛮力长上下文的方法,转向一种更广泛的"空间超感知"(spatial supersensing)范式。论文将空间超感知定义为超越单纯语言理解的四个阶段:语义感知(命名所见事物)、流式事件认知(在连续体验中保持记忆)、隐式3D空间认知(推断像素背后的世界)以及预测性世界建模(创建过滤和组织信息的内部模型)。目前大多数基准测试仅涵盖前几个阶段,对空间认知的覆盖范围狭窄,很少能真正挑战模型建立世界模型的能力。
为了推动空间超感知的发展,论文提出了VSI-SUPER基准,它包含两部分:VSR(long-horizon visual spatial recall,长时程视觉空间回忆)和VSC(continual visual spatial counting,连续视觉空间计数)。这些任务需要任意长的视频输入,但又不易被蛮力上下文扩展方法解决。
VSI-SUPER基准:
- VSR:要求MLLMs观察长时程时空视频,并按顺序回忆不寻常物体的位置。通过将生成模型编辑的视频(在室内环境中插入令人惊讶的物体)与其他房间漫游视频拼接而成,视频长度可任意扩展。任务要求序列回忆,类似于语言领域的"大海捞针"测试。
- VSC:测试MLLMs在不断变化的视角和场景下连续累积信息的能力。通过拼接多个房间漫游视频构建,模型需要在处理视角切换、重复出现和场景转换的同时,保持一致的累积计数。它还会在视频不同时间戳进行查询,以评估模型在流式设置下的性能。
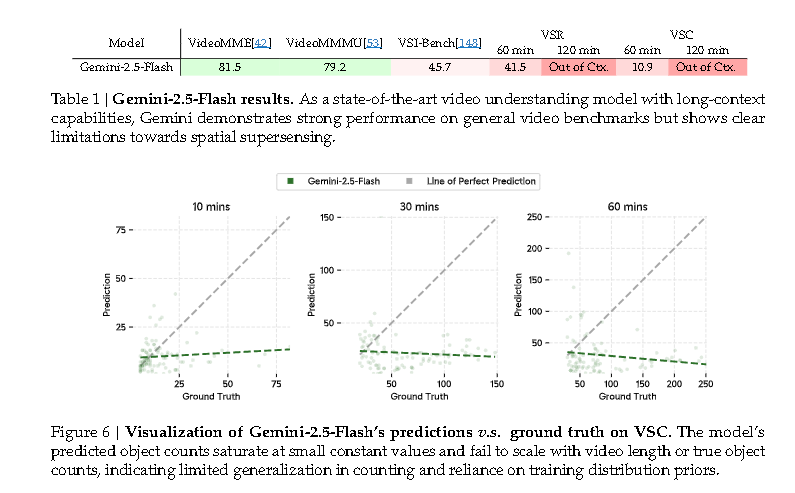
论文指出,即使是目前最先进的长上下文模型(如Gemini-2.5-Flash),在VSI-SUPER上的表现也十分有限。Gemini-2.5-Flash在处理两小时视频时达到上下文限制,即使在上下文窗口内的60分钟视频上,VSR和VSC的准确率也仅为41.5%和10.9%。其预测的物体数量不能随视频长度或真实数量增加而按比例增长,反而饱和在一个较小的常量值,表明计数能力缺乏泛化性。这揭示了当前MLLM范式的根本局限性:单纯扩大上下文长度或模型规模不足以实现空间超感知。
为了探索在现有范式下提升空间感知能力的极限,论文:
-
升级基础模型 :将Cambrian-1的视觉编码器升级为SigLIP2-SO400m,语言模型升级为Qwen2.5,并使用两层MLP作为视觉-语言连接器,形成一个更强大的图像MLLM基座。
-
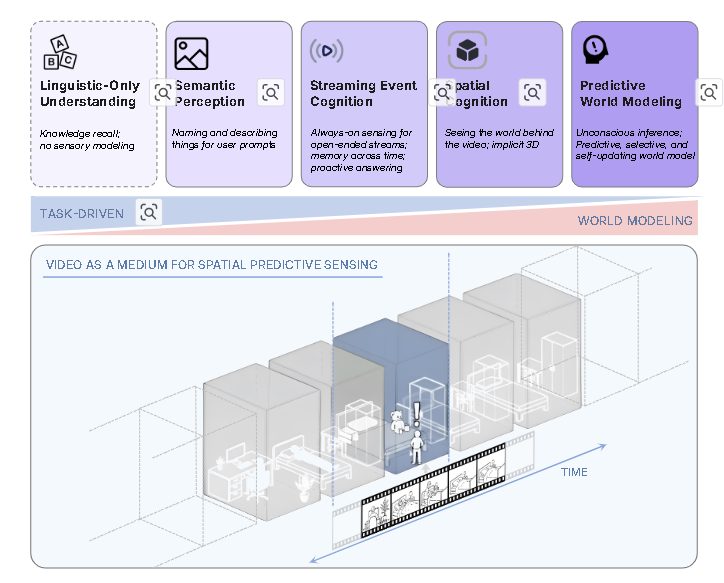
构建VSI-590K数据集:这是一个大规模、空间专注的指令微调数据集,包含590K个QA对,用于提高视觉空间理解能力。数据来源于:
- 带标注的真实视频:利用S3DIS、ScanNet、ARKitScenes和ADT等提供3D实例级标注的室内扫描和第一人称视频数据集。
- 模拟数据:利用ProcTHOR和Hypersim等模拟器程序化生成空间相关的视频轨迹和QA对。
- 无标注真实视频:从YouTube房间漫游视频以及Open-X-Embodiment和AgiBot-World等机器人学习数据集中收集,并通过伪标注流程(使用目标检测、分割和3D重建模型)生成QA对。
- 数据集定义了12种问题类型(尺寸、方向、计数、距离、出现顺序),涵盖配置、测量和时空能力,并包含相对和绝对变体。消融实验表明,带标注的真实视频数据贡献最大,其次是模拟数据,最后是伪标注图像。
-
提出后训练策略:研究表明,拥有更强通用视频数据曝光的基础模型能带来更好的空间理解能力;将VSI-590K与通用视频指令微调数据混合训练,能有效防止领域内SFT导致的泛化损失。
-
训练Cambrian-S模型家族 :基于上述洞察,论文通过四阶段训练流程构建了Cambrian-S模型,包括图像理解、通用视频理解和专门空间感知技能的开发。
Cambrian-S的实证结果:
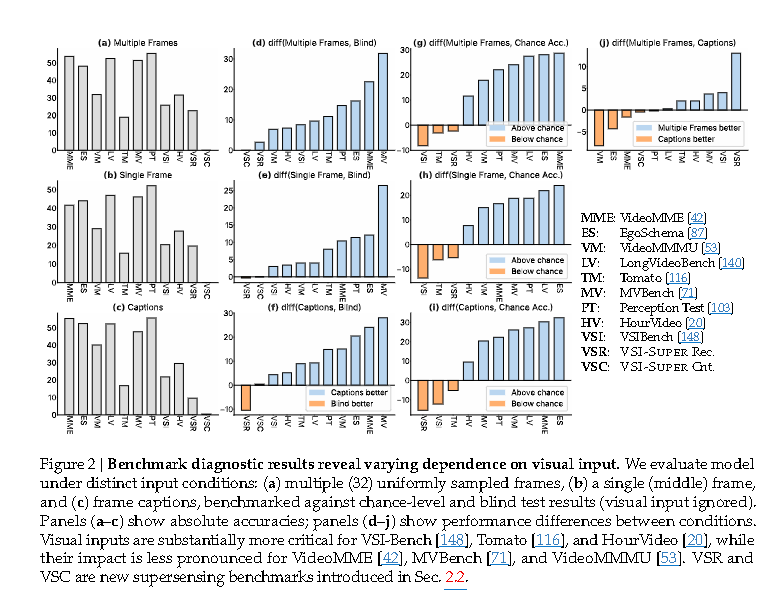
- 在VSI-Bench上,Cambrian-S-7B的准确率达到67.5%,显著优于所有开源模型和专有模型Gemini-2.5-Pro(超过16个绝对点)。即使在VSI-590K中未包含的"路径规划"等挑战性子任务上,Cambrian-S-7B也表现强劲。
- 在VSI-Bench-Debiased(旨在消除语言捷径的基准)上的评估也证实了其强大的视觉空间推理能力。
- 然而,Cambrian-S在VSI-SUPER的连续空间感知任务中仍然表现不佳。当视频长度从10分钟增加到60分钟时,VSR的准确率从38.3%急剧下降到6.0%,对于更长的视频则完全失败。VSC的性能也极差。这进一步强调了现有范式在处理连续、长时程、具有泛化性要求的空间感知任务方面的根本局限。
为了解决这一局限,论文提出了**预测感知(Predictive Sensing)**作为新的范式,其灵感来源于人类认知中选择性感知和记忆的机制,即大脑通过预测来处理输入,并利用"惊喜"(prediction error)来指导注意力、记忆和学习。
-
通过潜在帧预测实现预测感知:论文实现了一个轻量级的自监督"潜在帧预测"(LFP)模块。它与主要指令微调目标共同训练,预测下一视频帧的潜在表示。推理时,模型计算预测的潜在特征与实际下一帧特征之间的余弦距离,将此距离作为"惊喜"的量化度量。
-
案例研究I:惊喜驱动的VSR记忆管理系统:
- 方法:该系统根据"惊喜"程度动态压缩和整合视觉流。传入帧经过滑动窗口注意力编码,LFP模块为其KV缓存分配"惊喜水平"。低于阈值的帧进行2倍压缩。长时记忆有固定大小限制,通过整合功能根据惊喜分数丢弃或合并帧。用户查询时,系统从长时记忆中检索最相关的𝐾个帧。
- 结果 :搭载惊喜驱动记忆的Cambrian-S(w/ Mem.)在所有视频长度下都优于Gemini-1.5-Flash和未搭载记忆的Cambrian-S,并保持稳定的GPU内存使用。实验还表明,使用预测误差作为惊喜信号比使用相邻帧视觉特征相似度更有效。
-
案例研究II:惊喜驱动的VSC连续视频分割:
- 方法:在VSC任务中,惊喜信号被用于分割连续视觉输入,将场景变化识别为自然断点,从而将视频流划分为空间连贯的片段。模型在事件缓冲区中累积帧特征,当检测到高惊喜帧时,会汇总缓冲区特征以生成段级答案,并清空缓冲区开始新片段。所有段级答案最后汇总形成最终输出。
- 结果:搭载惊喜驱动事件分割的Cambrian-S(w/ Surprise Seg.)在所有视频长度上均表现出更高且更稳定的性能,远超Gemini-2.5-Flash。后者的预测范围受限,无法随视频中物体数量的增加而按比例增长,而Cambrian-S的预测与真实物体数量有更强的相关性。在流式评估中,Cambrian-S也显著优于商业MLLMs(如Gemini-Live和GPT-Realtime)。
总结:预测感知通过惊喜驱动的记忆和事件分割,使得Cambrian-S能够克服固定上下文长度的限制,在VSI-SUPER任务上表现出显著提升。这标志着向空间超感知迈出了早期一步,预示着构建能够预测、选择和组织经验的AI系统的潜力。
局限性:论文承认当前基准、数据集和模型设计在质量、规模和泛化性方面仍有限,所提出的原型仅作为概念验证。未来的工作应探索更多样化和具身化的场景,并与视觉、语言和世界建模的最新进展建立更强的联系。