token化后可能有顺序可能无序
无序为词包模型
布尔检索-共现矩阵(无序)
向量空间模型-换为tf-idf权重
概率模型-对tf-idf的权重进行调整,bm25
主题模型-稀疏向量变为稠密向量,但仍为词包模型
若考虑顺序,用语言模型
2.语言模型
根据语言客观事实对语言进行数学建模
句子空间:把所有句子采集起来,句子空间的分布可以描述出来
在句子空间中,每个句子出现的概率和为1
语言模型为计算模型,判断一个文本序列是不是像一个合理的句子,衡量文本出现的可能性或概率
应用:拼写纠错(错误句子出现概率小),语音识别,句子转换

(这里是2-gram,后续会讲)
核心任务:计算一个句子的概率,实际上是这个序列的概率(通过链式法则)
链式法则:联合概率可以表示为一系列条件概率的乘积
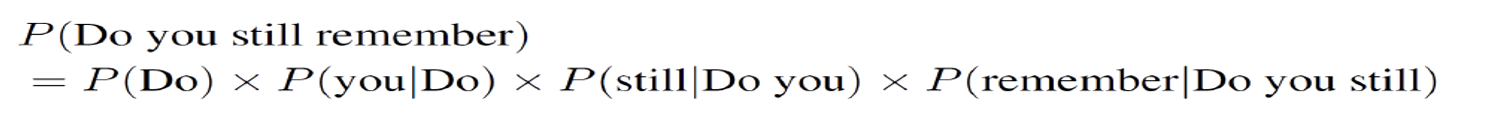

训练时,要估计右边所有的参数
有估计参数的不同方法
3.统计语言模型
实现语言模型的具体方法,从概率论视角,从大量数据来估计文本序列中的参数
核心思想:一个词出现的概率依赖于它们前面出现的几个词
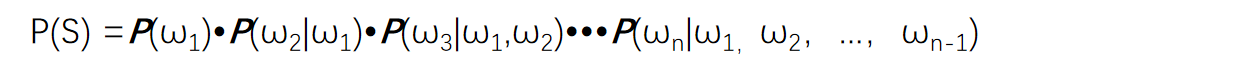


存在的问题:

直接算一个长句子,维度灾难问题,用链式法则、马尔可夫假设
马尔可夫假设:一个词典概率只依赖于它前面的有限个词
n-gram语言模型
第n个词只考虑前面的n-1个词

unigram相当于词包模型

n较大时,为什么参数估计不可靠?n大时需要几个词在一起的计数,这个计数可能不存在,因为单词出现符合幂律分布,虽然语料库变大但是词还是偏向常见的,这种几个词在一起的组合变少,概率为0,出现零概率问题,有一些解决方法,这些方法导致参数不可靠
这些解决方法有(不包括增加语料库,因为词还是幂律分布):平滑技术
平滑技术

n-gram模型的优缺点:简单直接,易实现,可解释性强,计算高效;
数据稀疏(未出现的词需用平滑技术处理,还是稀疏
上下文局限,因为有窗口,捕捉的是短距离的词
缺乏语义理解,基于计数实现,没有语义关系
4.神经网络语言模型

词语之间的相似度:上下文共现;语法相似
共线关系更鲁棒,语法关系更精确
NNLM

没有解决长度的依赖关系
(这个课程不需要记训练、损失函数等)

在emb处降维,通过节点控制,进行了单词的降维
拼在一起,保留顺序

文档向量化


解决:循环神经网络?
神经网络语言模型的核心思想:用词向量来表示每个词
优势

(也可能推测错误,这就是幻觉问题)
5.Word2Vec / Doc2Vec
词向量和文档向量直接做内积
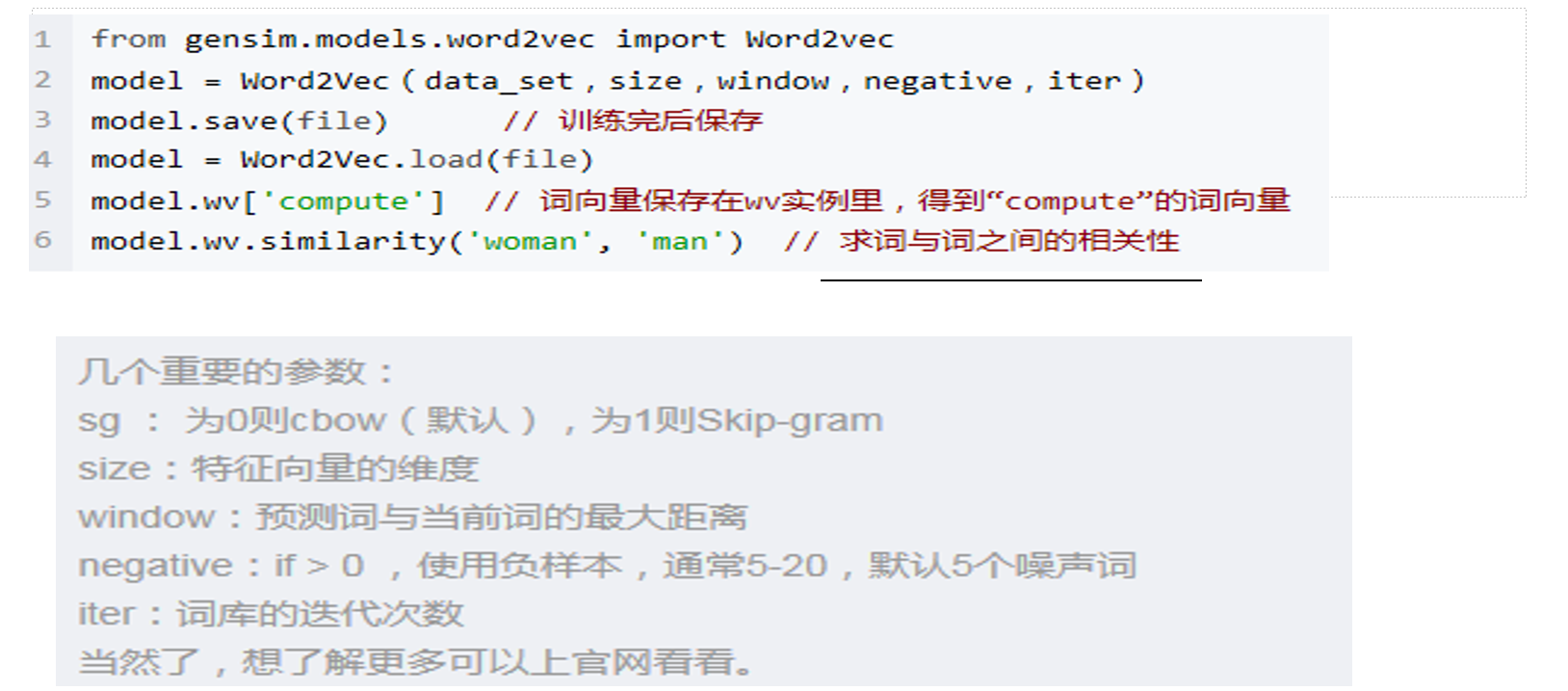
word2vec(这是方法)
CBOW continuous Bag of words model
词向量相加,此时在这个范围内位置没有关系(局限性)
连续:指的是连续特定窗口的上下文词
它不是语言模型
但是我们这个过程中可以得到词的emb
word2vec本身也有缺点

训练和实际的语料库要同分布
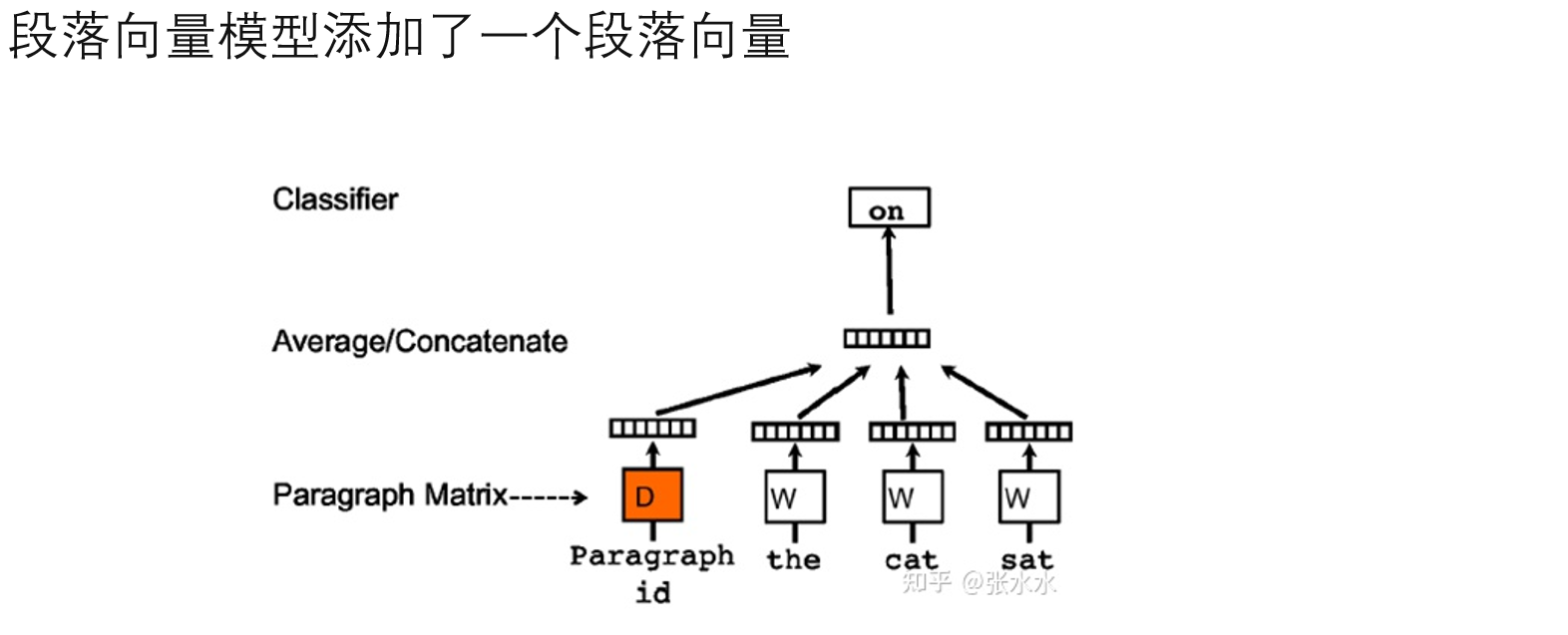
Doc2Vec
把变长句子变为定长向量
段落向量模型:得到橙色的参数矩阵(用id的向量表示这个段落,在训练时id维度为段落数,会降维到与其他词相同)

gensim

检索流程

优点
解决词汇鸿沟问题: 能够关联不同词语但表达相同概念的情况。
语义理解能力强: 这是最大的优点。 例如,查询"苹果手机", 传统的BM25算法可能无法召回只包含"iPhone"但不包含"苹果"的文档。 Word2Vec/Doc2Vec模型,"苹果"和"iPhone"的向量会很接近,从而能够成功匹配。
对短文本查询友好: 即使查询很短,只要其中的词语语义明确,也能找到相关文档。(社交媒体之类)
缺点与挑战



