Transformer 中的 Softmax 注意力因二次复杂度难以适配视觉任务,线性注意力虽将复杂度降至线性,但输出特征图的低秩特性导致空间建模能力不足,性能显著落后于 Softmax 注意力,RALA 正是为解决这一线性注意力的低秩困境而提出。
 原模型
原模型
 改进后的
改进后的
1.RALA原理
RALA 从 KV 缓冲和输出特征两个关键环节提升矩阵秩:针对 KV 缓冲,引入上下文感知的重排系数为每个 token 分配权重,增强信息丰富度与多样性,提升其秩;针对输出特征,通过通道维度的特征交互策略,结合原始 token 信息进行调制,使输出特征达到满秩状态,从而在保持线性复杂度的同时,强化复杂空间特征建模能力。
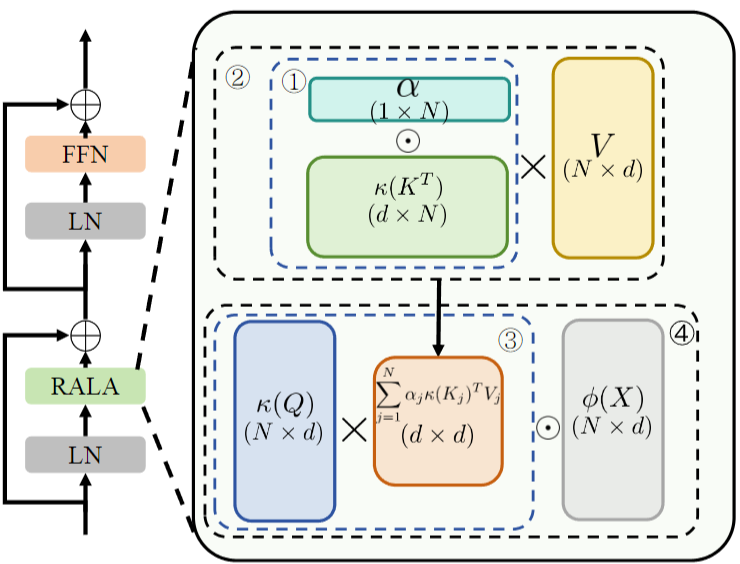
RALA 的核心结构包含 KV 缓冲秩增强模块和输出特征秩增强模块:前者通过权重系数调整 KV 缓冲的计算方式,后者采用 Hadamard 乘积融合原始 token 变换特征与 KV 缓冲交互结果;基于 RALA 构建的 RAVLT 网络,采用经典 Transformer 块设计,包含线性注意力层与 FFN 层,通过 CPE 提供位置编码,整体为分层式通用视觉骨干网络。
2.RALA习作思路
(一)目标检测场景
RALA 通过提升特征矩阵秩,增强了特征的多样性与表达能力,能够更精准地捕捉目标的细节信息与全局关联,同时线性复杂度保证了检测过程的高效性,可在不显著增加计算开销的前提下,提升对不同尺度、形态目标的识别与定位能力,兼顾检测精度与推理速度。
(二)图像分割场景
RALA 的满秩特征输出使模型能更好地建模像素级别的空间关系与语义信息,有效缓解线性注意力在细粒度特征学习上的不足,同时高效的计算特性支持大分辨率特征图处理,有助于精准分割不同语义类别区域,提升分割结果的边界完整性与类别一致性。
3. YOLO与 RALA的结合
RALA 的线性复杂度可在不大幅增加 YOLO 计算负担的前提下,提升特征表达能力,助力 YOLO 更好地捕捉目标细节与全局关联;其满秩特征能增强 YOLO 对小目标、复杂场景目标的识别能力,进一步优化检测精度与泛化性能。
4. RALA代码部分
YOLO12模型改进方法,快速发论文,总有适合你的改进,还不改进上车_哔哩哔哩_bilibili
YOLOv12 论文结构解析:强势来临,超越 YOLOv11!_哔哩哔哩_bilibili
代码获取: YOLOv8_improve/YOLOV12.md at master · tgf123/YOLOv8_improve · GitHub
5. RALA引入到YOLOv12中
第一: 先新建一个v12_changemodel,将下面的核心代码复制到下面这个路径当中,如下图如所示。E:\Part_time_job_orders\YOLO_NEW\YOLOv12\ultralytics\v12_changemodel。
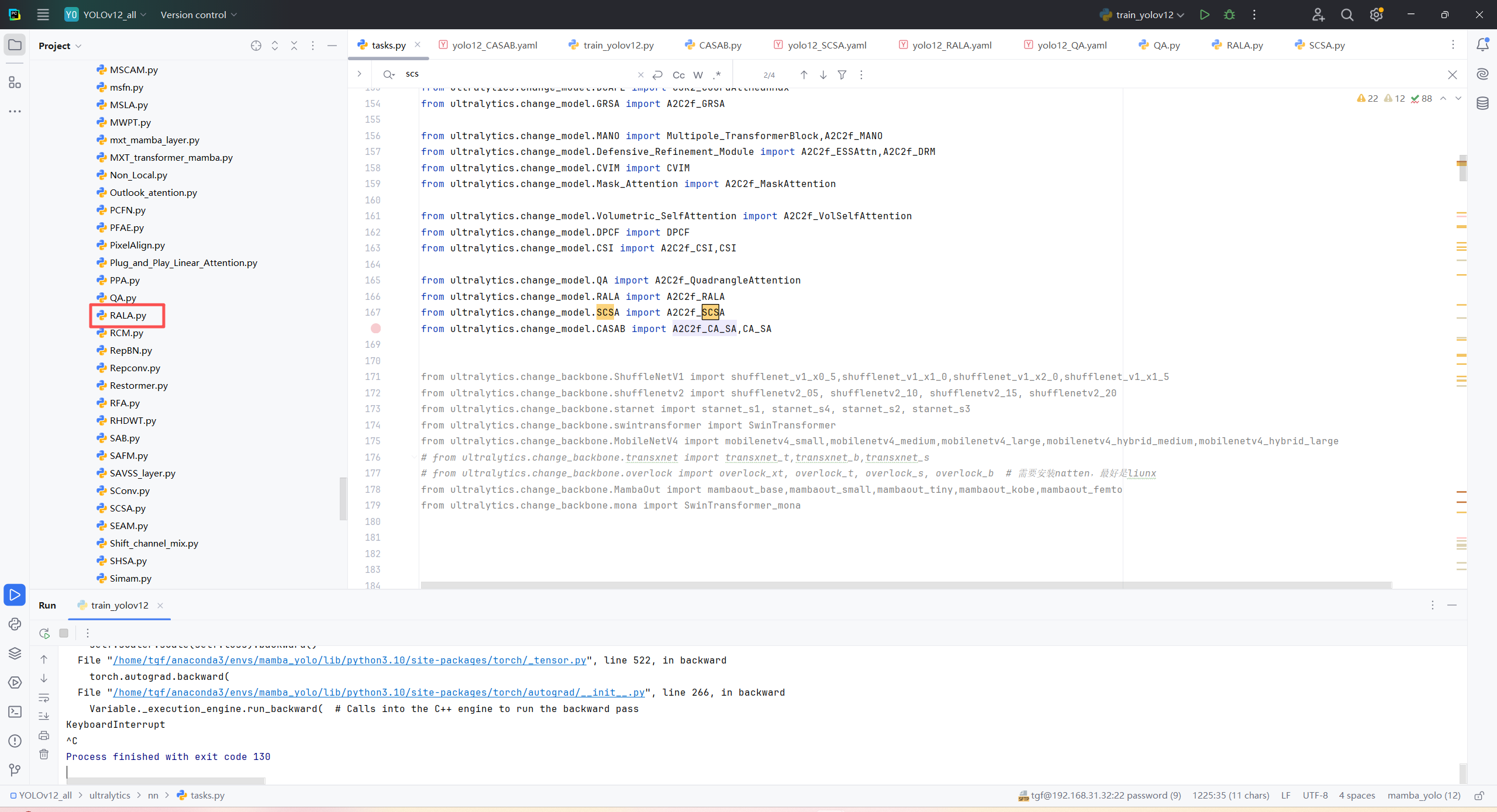
第二:在task.py中导入 包
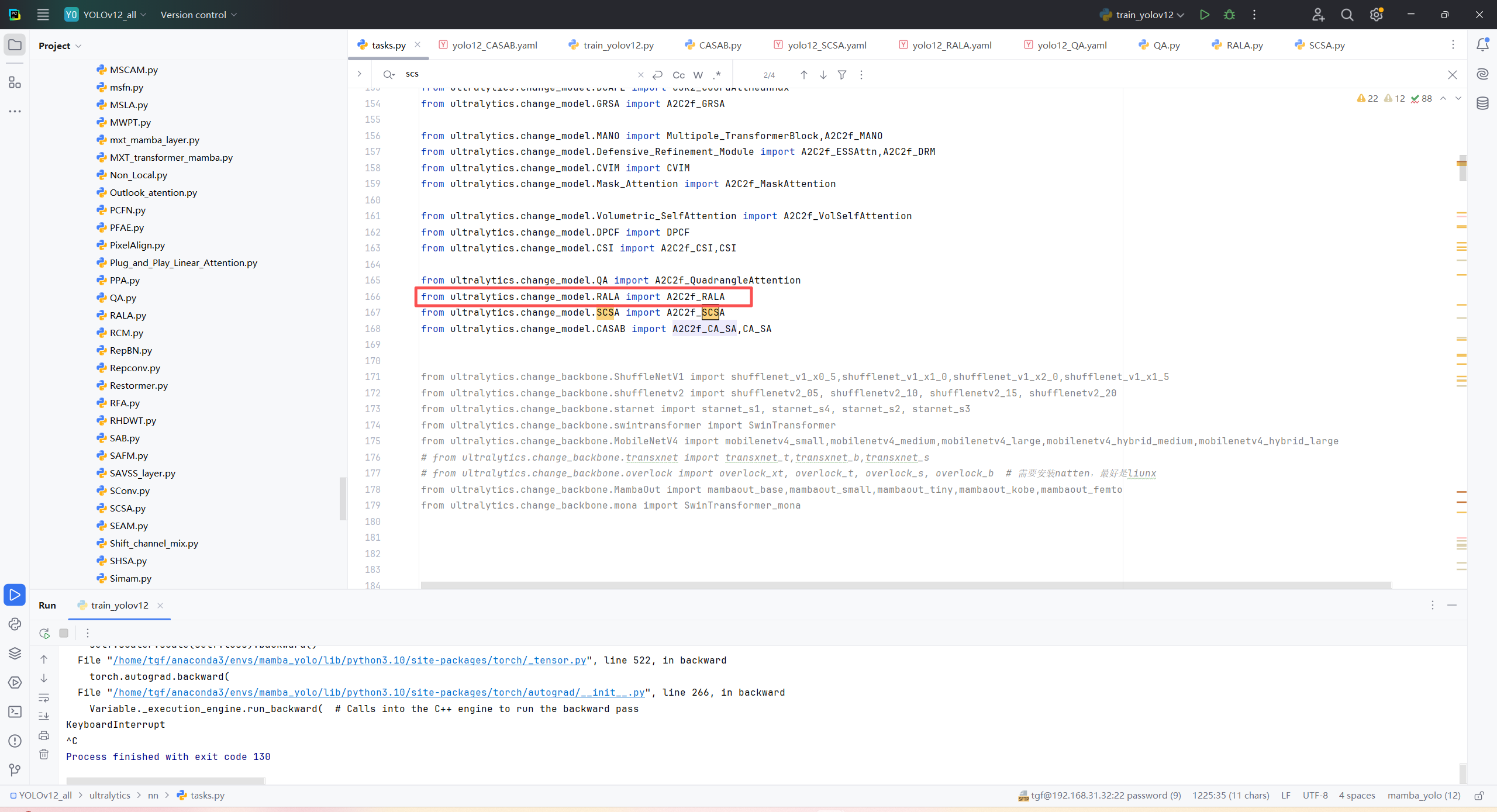
第三:在task.py中的模型配置部分下面代码
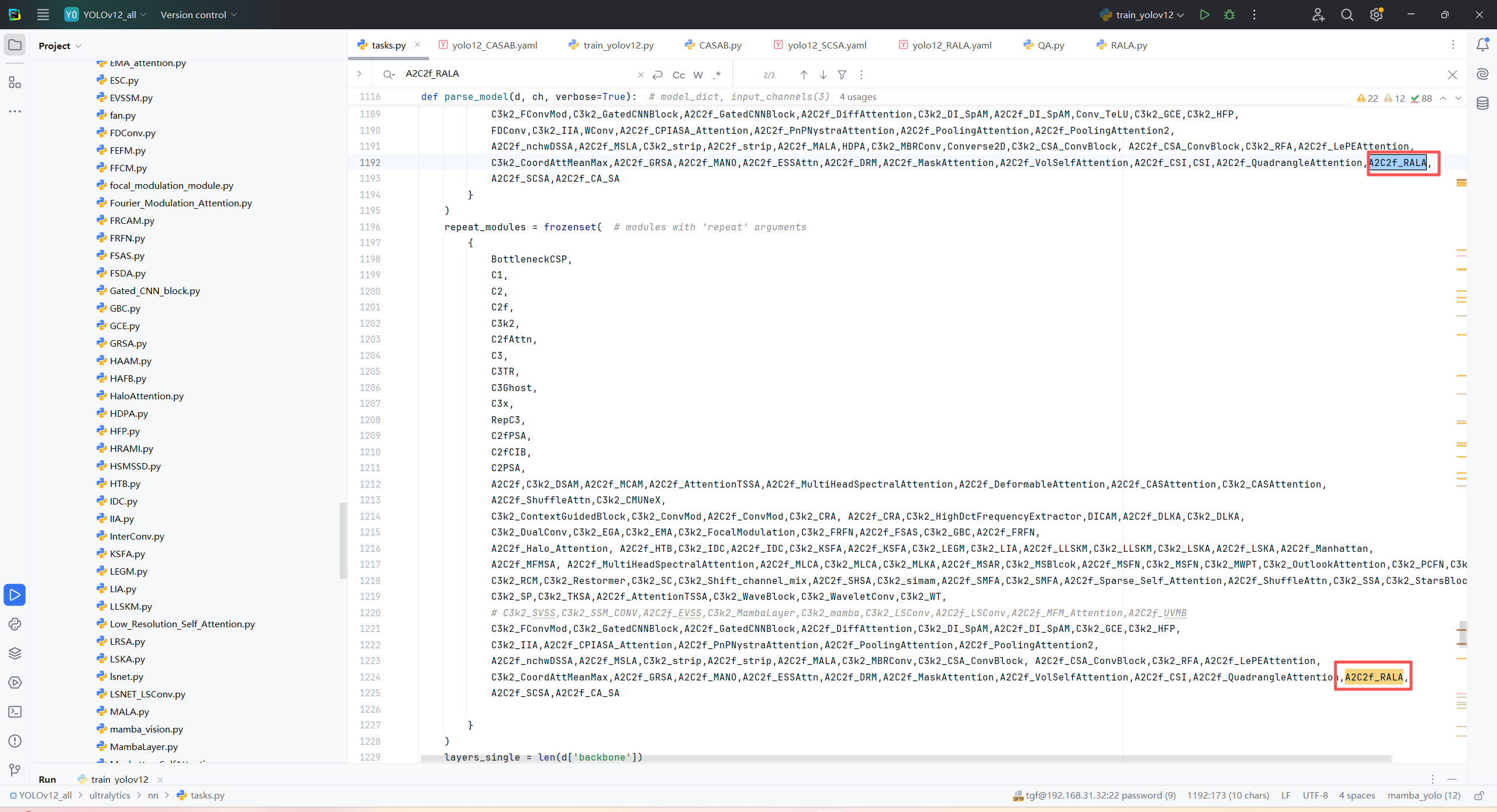
第四:将模型配置文件复制到YOLOV11.YAMY文件中
第五:运行代码
python
from ultralytics.models import NAS, RTDETR, SAM, YOLO, FastSAM, YOLOWorld
import torch
if __name__=="__main__":
# 使用自己的YOLOv8.yamy文件搭建模型并加载预训练权重训练模型
model = YOLO("/home/tgf/tgf/yolo/model/YOLO12_All/ultralytics/cfg/models/12/yolo12_RALA.yaml")\
# .load(r'E:\Part_time_job_orders\YOLO\YOLOv11\yolo11n.pt') # build from YAML and transfer weights
results = model.train(data="/home/shengtuo/tangfan/YOLO11/ultralytics/cfg/datasets/VOC_my.yaml",
epochs=300,
imgsz=640,
batch=4,
# cache = False,
# single_cls = False, # 是否是单类别检测
# workers = 0,
# resume=r'D:/model/yolov8/runs/detect/train/weights/last.pt',
amp = True
)