目录
1:函数的查询、描述和调用
编程要求
使用Hive中的ceil函数求数字66666的ceil的结果,我们已经准备了表test_table,而且表中已经有若干的数据。
drop table if exists test_table;
create table test_table(id int,name string) row format delimited fields terminated by '\t' lines terminated by '\n' stored as textfile;
load data local inpath 'step1/data.txt' into table test_table;
--------- Begin ---------
select ceil(66666);
--------- End ---------2:Hive标准函数
编程要求
查询表test_table中所有的name不等于jerry的记录。表中的数据和上面开始准备的数据完全相同。
没有输入,正确的输出如下:
13 tom
12 tom
14 tom
100 tom
1 tom
drop table if exists test_table;
create table test_table(id int,name string) row format delimited fields terminated by '\t' lines terminated by '\n' stored as textfile;
load data local inpath 'step2/data.txt' into table test_table;
---- 求名字不等于jerry的所有记录 ----
--------- Begin ---------
select * from test_table where name != 'jerry';
--------- End ---------3Hive聚合函数
编程要求
求表test_table中所有的id大于12的记录的id的和。表中的数据如下:
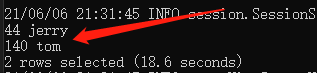
drop table if exists test_table;
create table test_table(id int,name string) row format delimited fields terminated by '\t' lines terminated by '\n' stored as textfile;
load data local inpath 'step3/data.txt' into table test_table;
---- 求id大于12的记录的id值的和 ----
--------- Begin ---------
SELECT SUM(id) FROM test_table WHERE id > 12;
--------- End ---------4:Hive日期函数
将时间戳转换为普通时间
时间戳:从1970年1月1日0点0分0秒距指定时间的秒数。比如1463308943指的实际上是2016年5月15号18点42分23秒。就是说这两个时间之间相距1463308943秒钟。
转换命令如下:
select from_unixtime(1463308943,'yyyyMMdd HH:mm:ss') from test_table limit 1;
其中yyyy表示结果中的年份将以2016这种四位数的形式展现,MM表示月份以05这种两位数的形式展现,dd表示两位数的天,HH表示24小时制,mm和ss分别表示分钟和秒钟以两位数的形式展示。
普通时间转时间戳
接着上面的讨论,怎么反过来将普通时间转为时间戳:
select unix_timestamp('20210606 13:01:03','yyyyMMdd HH:mm:ss') from test_table;
同样,这里需要说明普通时间的格式。
求当前时间
获取当前的时间戳的命令如下:
select unix_timestamp() from test_table;
计算相差天数
我们还可以使用Hive计算两个时间相差的天数:
select datediff('2019-12-08','2012-05-09') from test_table;
对时间进行加或者减
对指定的日期减去一天:
select date_sub('2021-06-06',1) from test_table;
指定日期加上100天:
select date_add('2021-06-06',100) from test_table;
编程要求
将时间戳1463308946转换为类似2012-02-02 02:02:02格式的普通时间。
无输入,正确的输出如下:
2016-05-15 10:42:26
drop table if exists test_table;
create table test_table(id int,name string) row format delimited fields terminated by '\t' lines terminated by '\n' stored as textfile;
load data local inpath 'step4/data.txt' into table test_table;
---- 将1463308946转换为格式类似 2012-02-02 02:02:02 的普通时间 ----
--------- Begin ---------
select from_unixtime(1463308946, 'yyyy-MM-dd HH:mm:ss');
--------- End ---------5:表生成函数
编程要求
将表test_table的字段id的名字改为age,类型不变。
测试说明
无输入,正确的输出如下:
age int
name string
drop table if exists test_table;
create table test_table(id int,name string) row format delimited fields terminated by '\t' lines terminated by '\n' stored as textfile;
---- 把列id的名字改为age,类型不变----
--------- Begin ---------
alter table test_table change column id age int;
--------- End ---------
desc test_table;6:分组排序取TopN
编程要求
实现对本例中开头部分给出的数据,按照name分组,然后select出前两名的全部信息以及序号(row_number()生成的数字)。
测试说明
测试输入:(无);
预期输出:
kaths math 96 1
kaths english 87 2
lrry math 69 1
lrry english 67 2
xiaoming english 100 1
xiaoming math 72
drop table if exists student_grades;
create table student_grades(name string, course string, score int) row format delimited fields terminated by '\t' lines terminated by '\n' stored as textfile;
load data local inpath 'step6/data.txt' into table student_grades;
---- 按name分组,取出前两名的信息----
--------- Begin ---------
select name, course, score, rn from (
select
name,
course,
score,
row_number() over (partition by name order by score desc) as rn
from student_grades
) t
where rn <= 2;
--------- End ---------