zookeeper: Apache Hadoop生态组件部署分享-zookeeper
hadoop:Apache Hadoop生态组件部署分享-Hadoop
hive: Apache Hadoop生态组件部署分享-Hive
hbase: Apache Hadoop生态组件部署分享-Hbase
impala:Apache Hadoop生态组件部署分享-Impala
1、下载spark并解压
下载地址: https://spark.apache.org/downloads.html
apache
tar -xf spark-3.5.7-bin-hadoop3.tgz -C /opt/apache/
bash
cd /opt/apache/spark-3.5.7-bin-hadoop3/confcp spark-env.sh.template spark-env.sh
vim spark-env.sh 添加以下内容:YARN_CONF_DIR=$HADOOP_HOME/etc/hadoopexport SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=30 -Dspark.history.fs.logDirectory=hdfs://nameservice1/spark-yarn-log"3、配置spark-defaults.conf
bash
cp spark-defaults.conf.template spark-defaults.conf
vim spark-defaults.confspark.eventLog.enabled truespark.eventLog.dir hdfs://nameservice1/spark-yarn-logspark.yarn.historyServer.address=apache230.hadoop.com:18080 #作业: 在yarn rm 8088页面可以通过history跳转过去spark.history.ui.port=180804、启动spark history服务
bash
/opt/apache/spark-3.5.7-bin-hadoop3/sbin/start-history-server.shhttp://apache230.hadoop.com:18080
5、验证spark-yarn
A. 客户端部署模式 验证计算pi
swift
/opt/apache/spark-3.5.7-bin-hadoop3/bin/spark-submit \--master yarn \--class org.apache.spark.examples.SparkPi \/opt/apache/spark-3.5.7-bin-hadoop3/examples/jars/spark-examples_2.12-3.5.7.jar 10注: 此时部署模式是在客户端上 所以日志在客户端显示
B.集群部署模式 验证计算pi
swift
/opt/apache/spark-3.5.7-bin-hadoop3/bin/spark-submit \--master yarn --deploy-mode cluster \--class org.apache.spark.examples.SparkPi \/opt/apache/spark-3.5.7-bin-hadoop3/examples/jars/spark-examples_2.12-3.5.7.jar 2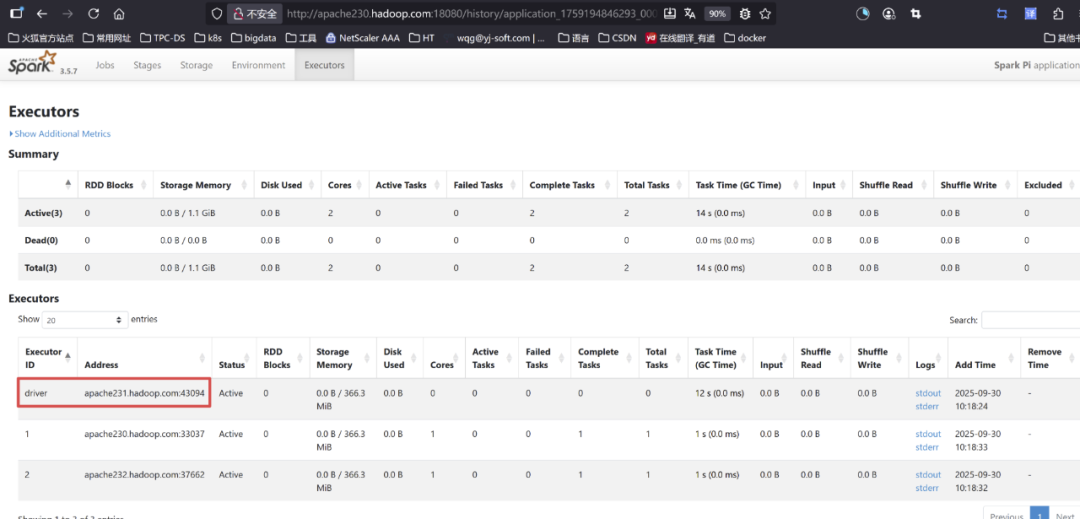
说明: 这个时候就可以看到driver在231节点了,之前客户端部署模式是在哪个客户端执行,driver就在哪个机器上面
6、spark-shell验证
swift
[root@apache230 bin]# ./spark-shellSetting default log level to "WARN".To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).25/09/30 10:24:22 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable25/09/30 10:24:23 WARN DomainSocketFactory: The short-circuit local reads feature cannot be used because libhadoop cannot be loaded.Spark context Web UI available at http://apache230.hadoop.com:4040Spark context available as 'sc' (master = local[*], app id = local-1759199063061).Spark session available as 'spark'.Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 3.5.7 /_/
Using Scala version 2.12.18 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_144)Type in expressions to have them evaluated.Type :help for more information.
scala> sc.textFile("/tmp/wqg.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_ + _).collectres0: Array[(String, Int)] = Array((16:07:50,243,2), (15:38:53,698,4), (15:20:03,258,2), (15:39:46,035,1), (15:50:34,501,4), (15:43:54,365,2), (16:12:00,567,2), (15:27:26,953,4), (16:13:23,677,4), (16:13:08,656,4), (15:36:57,946,2), (15:55:30,218,2), (15:48:41,009,4), (15:53:15,033,2), (15:53:50,076,4), (15:34:18,110,3), (15:21:56,442,4), (15:36:58,947,4), (15:08:51,130,4), (15:54:27,125,1), (16:07:38,229,2), (15:42:32,881,2), (15:58:28,461,2), (15:23:33,591,4), (15:10:53,351,2), (16:15:33,856,2), (15:12:37,531,2), (15:29:32,402,2), (16:08:03,626,1), (15:46:44,408,2), (15:55:38,227,2), (15:55:54,252,2), (15:32:41,569,1), (15:30:50,899,2), (16:12:14,584,2), (15:38:32,596,1), (15:05:54,815,3), (15:13:09,586,2), (15:17:46,039,2), (16:05:18,014,3), (16:12:02,569,2)...