简述
SourceMap提供了从源代码到生成代码之间的转换关系,通过它使得各类代码生成工具生成的代码调试变得简单。前面我们写过两篇文章描述过SourceMap的历史,使用方式和生成工具等,对SourceMap有了一定的了解:
但是对于SourceMap数据中最重要的内容,记录着转换前后代码中变量/属性名的位置关系的mappings字段却没有介绍。这也是SourceMap的核心生成原理。那么它是如何关联位置的,以及如何生成和解析这段字符串,这篇文章将会一一解答。
创建SourceMap示例
在正式的介绍之前,为了方便后面描述,首先让我们创建一个SourceMap的示例,后面会一直用这个例子。这里采用Terser生成,首先看下源代码:
js
// src/index.js
try {
const sum = jzplp + 10;
} catch (err) {
console.log(err);
throw err;
}然后执行命令,生成代码和SourceMap。注意这里为了展示两行场景,没有开启代码压缩。semicolons=false表示不采用分号,而使用换行符。
sh
terser src/index.js --mangle --format semicolons=false -o dist.js --source-map url=dist.js.map然后看下生成的结果:
js
// dist.js
try{const o=jzplp+10}catch(o){console.log(o)
throw o}
//# sourceMappingURL/* 防止报错 */=dist.js.map
// dist.js.map
{
"version": 3,
"names": ["sum", "jzplp", "err", "console", "log"],
"sources": ["src/index.js"],
"mappings": "AAAA,IACE,MAAMA,EAAMC,MAAQ,EACtB,CAAE,MAAOC,GACPC,QAAQC,IAAIF;AACZ,MAAMA,CACR",
"ignoreList": []
}还有一个index.html,后面在浏览器中查看效果使用:
html
<html>
<script src="./dist.js"></script>
</html>最后还有一个解析SourceMap数据的工具,这里我们直接采用这篇文章中使用的解析SourceMap工具代码即可,Webpack中各种devtool配置的含义与SourceMap生成逻辑。注意要修改下文件路径。
source-map中的行号从1开始,列号从0开始。但是我们为了符合SourceMap数据规范,后面所有的标号都从0开始,包括行号和列号。因此我们对代码稍作改造,后面都按照这个标准来计算。这里解析上面生成的SourceMap数据结果如下:
ruby
生成代码行0 列0 源代码行0 列0 源名称- 源文件:src/index.js
生成代码行0 列4 源代码行1 列2 源名称- 源文件:src/index.js
生成代码行0 列10 源代码行1 列8 源名称sum 源文件:src/index.js
生成代码行0 列12 源代码行1 列14 源名称jzplp 源文件:src/index.js
生成代码行0 列18 源代码行1 列22 源名称- 源文件:src/index.js
生成代码行0 列20 源代码行2 列0 源名称- 源文件:src/index.js
生成代码行0 列21 源代码行2 列2 源名称- 源文件:src/index.js
生成代码行0 列27 源代码行2 列9 源名称err 源文件:src/index.js
生成代码行0 列30 源代码行3 列2 源名称console 源文件:src/index.js
生成代码行0 列38 源代码行3 列10 源名称log 源文件:src/index.js
生成代码行0 列42 源代码行3 列14 源名称err 源文件:src/index.js
生成代码行1 列0 源代码行4 列2 源名称- 源文件:src/index.js
生成代码行1 列6 源代码行4 列8 源名称err 源文件:src/index.js
生成代码行1 列7 源代码行5 列0 源名称- 源文件:src/index.js整理对应关系
首先第一步,我们分析源代码和生成代码,将对应关系整理出来。先列一下对应关系拥有的字段,这些字段值对于SourceMap转换来说是必须的。
- 源代码文件名
- 源代码行号
- 源代码列号
- 源代码标识符
- 生成代码文件名
- 生成代码行号
- 生成代码列号
- 生成代码标识符
| 源代码文件名 | 源代码标识符 | 源代码行号 | 源代码列号 | 生成代码文件名 | 生成代码标识符 | 生成代码行号 | 生成代码列号 |
|---|---|---|---|---|---|---|---|
| src/index.js | sum | 1 | 8 | dist.js | o | 0 | 10 |
| src/index.js | jzplp | 1 | 14 | dist.js | jzplp | 0 | 12 |
| src/index.js | err | 2 | 9 | dist.js | o | 0 | 27 |
| src/index.js | console | 3 | 2 | dist.js | console | 0 | 30 |
| src/index.js | log | 3 | 10 | dist.js | log | 0 | 38 |
| src/index.js | err | 3 | 14 | dist.js | o | 0 | 42 |
| src/index.js | err | 4 | 8 | dist.js | o | 1 | 6 |
可以看到这个表格和上面我们解析SourceMap数据得到的值是一样的。但是前面SourceMap中还多了一些没有标识符的对应关系数据,通过对比了解那是代码中其它内容的对应,这里我们忽略,按照标准的标识符关系来计算。此时我们创建一个JSON,存放我们生成的SourceMap数据。现在里面只有版本号:
json
{
"version": 3,
}下面我们开始一步一步进行精简流程,目的是保证信息量不减少的情况下,减少最后形成的字符串长度。
文件名精简
生成代码文件名这个字段无需表示,因为SourceMap数据是从生成文件的注释中指定的,那么SourceMap数据对应的生成文件就是这个指定的文件,无需标明。
然后是源代码文件名,这个我们用一个专门的数组存放,取名叫做sources。此时我们的SourceMap内容如下:
json
{
"version": 3,
"sources": ["src/index.js"],
}然后记录表格中的源代码文件名变成数组的下标,从0开始。这时我们的表格变成了这样:
| 源代码文件名下标 | 源代码标识符 | 源代码行号 | 源代码列号 | 生成代码标识符 | 生成代码行号 | 生成代码列号 |
|---|---|---|---|---|---|---|
| 0 | sum | 1 | 8 | o | 0 | 10 |
| 0 | jzplp | 1 | 14 | jzplp | 0 | 12 |
| 0 | err | 2 | 9 | o | 0 | 27 |
| 0 | console | 3 | 2 | console | 0 | 30 |
| 0 | log | 3 | 10 | log | 0 | 38 |
| 0 | err | 3 | 14 | o | 0 | 42 |
| 0 | err | 4 | 8 | o | 1 | 6 |
代码标识符精简
关于生成代码标识符,既然我们有了SourceMap数据指定的行列号,生成代码本身又是可见的,就可以从代码中定位到生成代码标识符,无需在表格中列出。
然后是源代码标识符,可以看到有很多重复出现的标识符,我们将这些标识符用一个专门的数组存放,取名叫做names。此时我们的SourceMap内容如下:
json
{
"version": 3,
"names": ["sum", "jzplp", "err", "console", "log"],
"sources": ["src/index.js"],
}然后再将表格中的源代码标识符简化为源代码标识符下标,可以看到现在表格中全都是数字了。
| 源代码文件名下标 | 源代码标识符下标 | 源代码行号 | 源代码列号 | 生成代码行号 | 生成代码列号 |
|---|---|---|---|---|---|
| 0 | 0 | 1 | 8 | 0 | 10 |
| 0 | 1 | 1 | 14 | 0 | 12 |
| 0 | 2 | 2 | 9 | 0 | 27 |
| 0 | 3 | 3 | 2 | 0 | 30 |
| 0 | 4 | 3 | 10 | 0 | 38 |
| 0 | 2 | 3 | 14 | 0 | 42 |
| 0 | 2 | 4 | 8 | 1 | 6 |
表格转为字符串
SourceMap数据中的mappings是一个字符串,但我们是一个表格,这一步我们将表格转化为字符串。将每一个对应关系用逗号分隔,对应关系中间的六个数字我们用|分隔。那么数据可以被转为这样:
0|0|1|8|0|10,0|1|1|14|0|12,0|2|2|9|0|27,0|3|3|2|0|30,0|4|3|10|0|38,0|2|3|14|0|42,0|2|4|8|1|6为了便于生成代码查找,我们将生成代码的每行做分隔,中间用分号表示,例如 第一行,第一行;第二行;;第四行。这种方式可以去掉数据中的行号列。这样我们的数据可以被转为这样:
ini
0|0|1|8|10,0|1|1|14|12,0|2|2|9|27,0|3|3|2|30,0|4|3|10|38,0|2|3|14|42;0|2|4|8|6这份数据对应的表格表示如下:
| 源代码文件名下标 | 源代码标识符下标 | 源代码行号 | 源代码列号 | 生成代码列号 |
|---|---|---|---|---|
| 0 | 0 | 1 | 8 | 10 |
| 0 | 1 | 1 | 14 | 12 |
| 0 | 2 | 2 | 9 | 27 |
| 0 | 3 | 3 | 2 | 30 |
| 0 | 4 | 3 | 10 | 38 |
| 0 | 2 | 3 | 14 | 42 |
| 0 | 2 | 4 | 8 | 6 |
数字转为增量计数
从上面的字符串可以看到,行号列号数字是不断增长的。我们的代码非常短不明显,在大项目中行号列号可能会到数万行,这样还是会导致字符串长度过长。针对这个问题,可以使用增量计数的方式精简。
增量计数指的是,后面的数字以前一个数字为基准,只记录增加的数字。例如原始的数据为:1, 3, 8, 6, 10。我们将每一个数据减去前一个数据,就得到了增量数组:1, 2, 5, -2, 4。从例子中可以看到,如果这个数字相比于前一个数字是减小的,那么这个增量就是负值。
按照这个方式,我们将所有数据进一步精简:
| 源代码文件名下标增量 | 源代码标识符下标增量 | 源代码行号增量 | 源代码列号增量 | 生成代码列号增量 |
|---|---|---|---|---|
| 0 | 0 | 1 | 8 | 10 |
| 0 | 1 | 0 | 6 | 2 |
| 0 | 1 | 1 | -5 | 15 |
| 0 | 1 | 1 | -7 | 3 |
| 0 | 1 | 0 | 8 | 8 |
| 0 | -2 | 0 | 4 | 4 |
| 0 | 0 | 1 | -6 | -38 |
可以看到,虽然整体得到了精简,但是还有一些负值存在,尤其是当换行之后,列号会从很大的数字变为很少的数字,这时候可能会出现一个较大的负值。不过常规情况下,每换一行也只会出现这一次。然后我们将数据字段位置按照规范调整一下:
| 生成代码列号增量 | 源代码文件名下标增量 | 源代码行号增量 | 源代码列号增量 | 源代码标识符下标增量 |
|---|---|---|---|---|
| 10 | 0 | 1 | 8 | 0 |
| 2 | 0 | 0 | 6 | 1 |
| 15 | 0 | 1 | -5 | 1 |
| 3 | 0 | 1 | -7 | 1 |
| 8 | 0 | 0 | 8 | 1 |
| 4 | 0 | 0 | 4 | -2 |
| -38 | 0 | 1 | -6 | 0 |
转成字符串形式如下:
ini
10|0|1|8|0,2|0|0|6|1,15|0|1|-5|1,3|0|1|-7|1,8|0|0|8|1,4|0|0|4|-2;-38|0|1|-6|0Base64VLQ编码
VLQ编码
在上一步中形成的字符串里,占用最多空间的是分隔符|,在这一步中的首要任务就是要去掉它。直接去掉肯定不行,例如15|0|1|-5|1,去掉之后是1501-51,我们根本不知道如何将数字分隔开。这时就需要采用VLQ编码来实现。
VLQ编码(Variable Length Quantity)是一种将任意大小的数字转化为连续二进制码的一种编码方式,默认是采用8位来编码。这里由于需要适配Base64编码,因此改为了6位编码。我们举三个例子介绍一下编码方式,数字3,数字-38,数字4268。
首先将这两个数字的绝对值转成二进制,然后正数在后面补0,负数在后面补1。
rust
3 -> 11 -> 110
-38 -> -100110 -> 1001101
4268 -> 1000010101100 -> 10000101011000然后再按照五个二进制位分为一组,不足五位的在前面补齐0。
rust
3 -> 110 -> 00110 -> 00110
-38 -> 1001101 -> 10 01101 -> 00010 01101
4268 -> 10000101011000 -> 1000 01010 11000 -> 01000 01010 11000然后将这几组的顺序倒转。
rust
3 -> 00110 -> 00110
-38 -> 00010 01101 -> 01101 00010
4268 -> 01000 01010 11000 -> 11000 01010 01000然后就是去掉分隔符的关键步骤,将每一组最前面补一位:1表示还没结束,后面还有表示同一个数字的其他组;0表示这个数字在这一组已经结束了。到这里,VLQ编码就完成了。
rust
3 -> 00110 -> 000110
-38 -> 01101 00010 -> 101101 000010
4268 -> 11000 01010 01000 -> 111000 101010 001000Base64编码
我们很久之前介绍过Base64编码,那时候是将3个字节转换为4个Base64编码值:因为 38=24, 64=24,位数相同正好能转换。但是这里由于我们在VLQ编码的时候就已经设置了6位,因此就不需要合并字节了,而是直接把一组二进制数转为对应字符即可:
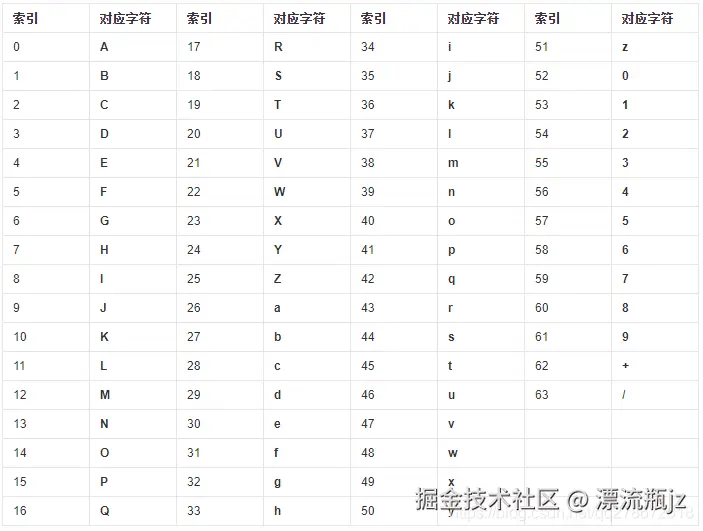 表格来源于百度百科
表格来源于百度百科
rust
3 -> 000110 -> 6 -> G
-38 -> 101101 000010 -> 45 2 -> tC
4268 -> 111000 101010 001000 -> 56 42 8 -> 4qI通过在线的BASE64VLQ转换工具,得到的结果是一致的,证明我们的算法是正确的。
最终生成SourceMap
由于这种编码方式可以通过第一个二进制位表示数字是否已经结束,因此不再需要分隔符了。上面前面三个数字的例子可以被表示为:
rust
3|-38|4268 -> GtC4qI我们用这个方式,将每个数字都进行编码,结果如下。这里分别列出了数字和对应的编码,中间用空格分隔:
| 生成代码列号增量 | 源代码文件名下标增量 | 源代码行号增量 | 源代码列号增量 | 源代码标识符下标增量 |
|---|---|---|---|---|
| 10 U | 0 A | 1 C | 8 Q | 0 A |
| 2 E | 0 A | 0 A | 6 M | 1 C |
| 15 e | 0 A | 1 C | -5 L | 1 C |
| 3 G | 0 A | 1 C | -7 P | 1 C |
| 8 Q | 0 A | 0 A | 8 Q | 1 C |
| 4 I | 0 A | 0 A | 4 I | -2 F |
| -38 tC | 0 A | 1 C | -6 N | 0 A |
转成字符串形式如下:
css
编码
U|A|C|Q|A,E|A|A|M|C,e|A|C|L|C,G|A|C|P|C,Q|A|A|Q|C,I|A|A|I|F;tC|A|C|N|A
去掉分隔符
UACQA,EAAMC,eACLC,GACPC,QAAQC,IAAIF;tCACNA最后生成真正的SourceMap完整数据文件:
json
{
"version": 3,
"names": ["sum", "jzplp", "err", "console", "log"],
"sources": ["src/index.js"],
"mappings": "UACQA,EAAMC,eACLC,GACPC,QAAQC,IAAIF;tCACNA"
}这里和Terser生成的SourceMap数据不同,因为它多生成了一些没有标识符的对应关系。如果对应关系中没有标识符,那么生成的结果中不存在对应数字即可,例如Terser生成的SourceMap数据中四个字母的数据,就肯定是没有标识符的。
浏览器测试
使用自己手工生成的完整的SourceMap数据,替换掉Terser生成的SourceMap文件内容。然后在浏览器中打开查看效果:
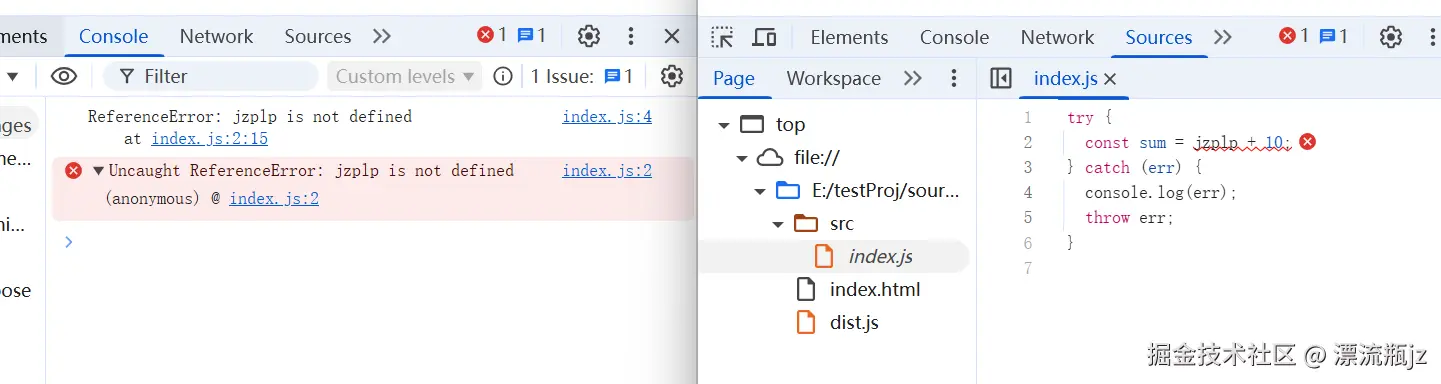
可以看到,报错位置成功的被转换为源文件index.js中的报错位置(浏览器行号列号都从1开始)。因此这说明我们手工生成的SourceMap是有效的。
参考
- 快速定位源码问题:SourceMap的生成/使用/文件格式与历史
jzplp.github.io/2025/js-sou... - Webpack中各种devtool配置的含义与SourceMap生成逻辑
jzplp.github.io/2025/webpac... - Terser 文档
terser.org/ - sourcemap 这么讲,我彻底理解了
juejin.cn/post/719989... - Base64编码详解与URL安全的Base64编码
jzplp.github.io/2021/base64... - JavaScript Source Map 详解 www.ruanyifeng.com/blog/2013/0...
- BASE64 VLQ CODEC (COder/DECoder) AND SOURCEMAP V3 / ECMA-426 MAPPINGS PARSER
www.murzwin.com/base64vlq.h...