1 引言
前序学习进程中,已经了解了CNN相关的基本运算,包括卷积运算原理、卷积值提取和卷积图像扩充。
再继续深入的时候,发现一个小知识点比较重要:CNN要求格式标准的四维张量,具体有样本数,通道数,高(行),宽(列)。
今天我们就来学习一下CNN的四维张量格式相关的小知识。
代码测试
使用reshape()函数规定张量格式
首先来看一段代码:
python
import torch
# 2样本2通道(正确,已验证)
data_2s2c = torch.tensor([
# 样本1-通道1(两层括号:通道层+像素层)
[
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12],
[13, 14, 15, 16]
],
# 样本1-通道2
[
[17, 18, 19, 20],
[21, 22, 23, 24],
[25, 26, 27, 28],
[29, 30, 31, 32]
],
# 样本2-通道1
[
[33, 34, 35, 36],
[37, 38, 39, 40],
[41, 42, 43, 44],
[45, 46, 47, 48]
],
# 样本2-通道2
[
[49, 50, 51, 52],
[53, 54, 55, 56],
[57, 58, 59, 60],
[61, 62, 63, 64]
]
], dtype=torch.float32).reshape(2, 2, 4, 4)
print("2样本2通道形状:", data_2s2c.shape) # 输出:(2,2,4,4)代码运行后会输出:
 这里有一个重要定义,data_2s2c不仅是以一个四维pytorch张量,还通过reshape(2,2,4,4)被规定了格式,所以print()函数按照reshape()函数规定的效果输出。
这里有一个重要定义,data_2s2c不仅是以一个四维pytorch张量,还通过reshape(2,2,4,4)被规定了格式,所以print()函数按照reshape()函数规定的效果输出。
为进行对比,可以尝试删除reshape()函数。
不使用reshape()函数规定张量格式
此时的代码为:
python
import torch
# 2样本2通道(正确,已验证)
data_2s2c = torch.tensor([
# 样本1-通道1(两层括号:通道层+像素层)
[
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12],
[13, 14, 15, 16]
],
# 样本1-通道2
[
[17, 18, 19, 20],
[21, 22, 23, 24],
[25, 26, 27, 28],
[29, 30, 31, 32]
],
# 样本2-通道1
[
[33, 34, 35, 36],
[37, 38, 39, 40],
[41, 42, 43, 44],
[45, 46, 47, 48]
],
# 样本2-通道2
[
[49, 50, 51, 52],
[53, 54, 55, 56],
[57, 58, 59, 60],
[61, 62, 63, 64]
]
], dtype=torch.float32).reshape(2, 2, 4, 4)
# 2样本2通道(正确,已验证)
data_2s2d = torch.tensor([
# 样本
[
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12],
[13, 14, 15, 16]
],
# 样本
[
[17, 18, 19, 20],
[21, 22, 23, 24],
[25, 26, 27, 28],
[29, 30, 31, 32]
],
# 样本
[
[33, 34, 35, 36],
[37, 38, 39, 40],
[41, 42, 43, 44],
[45, 46, 47, 48]
],
# 样本
[
[49, 50, 51, 52],
[53, 54, 55, 56],
[57, 58, 59, 60],
[61, 62, 63, 64]
]
], dtype=torch.float32)
print("2样本2通道形状:", data_2s2c.shape) # 输出:(2,2,4,4)
print("样本通道形状:", data_2s2d.shape) # 输出:(4,4,4)此时的代码和是上一节的不同在于,先复制data_2s2c改名为data_2s2d,然后删除reshape()函数,最后使用size()函数输出data_2s2c和data_2s2d的格式,输出效果为:

此时会看到data_2s2d的形状格式混淆了样本数和通道数,把它们相乘的结果2X2直接输出。
此时有一个重要的议题,如果想把data_2s2d转换为标准格式的四维Pytorch张量,该如何修改代码?
样本数和通道数判断
有一个简单的办法,如果张量定义过程中没有使用reshape()函数说明通道数和样本数,那就根据实际的代码判断:
data_2s2d = torch.tensor([
样本
\[1, 2, 3, 4\], \[5, 6, 7, 8\], \[9, 10, 11, 12\], \[13, 14, 15, 16
],
样本
\[17, 18, 19, 20\], \[21, 22, 23, 24\], \[25, 26, 27, 28\], \[29, 30, 31, 32
],
样本
\[33, 34, 35, 36\], \[37, 38, 39, 40\], \[41, 42, 43, 44\], \[45, 46, 47, 48
],
样本
\[49, 50, 51, 52\], \[53, 54, 55, 56\], \[57, 58, 59, 60\], \[61, 62, 63, 64
]
], dtype=torch.float32)
这段代码很直白,一个大括号内部,有四个大括号,每个大括号内部又有四个大括号,也就是会有三层大括号,不放按照从外到内的顺序,一次定义为第一层、第二层和第三层。
我们看第二层大括号,它约束了好几个第三层,这些第三层大括号内部的数字就是具体的张量,第三层可以直接看出张量的高度,对应行数,以及张量的宽度,对应列数。
由第三层张量组成的第二层,就是一个样本。也就是每一个第二层大括号内部的所有第三层张量组成一个样本。
所以上述代码有4个样本,此时没有定义通道数,应当增加一个通道数定义,通道数在CNN对应的Pytorch张量中属于第1个量(从第0个开始计),此时只需要在data_2s2d后面加一个unsqueeze(1),就会强制将通道数定义为1,代码为:
python
import torch
# 2样本2通道(正确,已验证)
data_2s2c = torch.tensor([
# 样本1-通道1(两层括号:通道层+像素层)
[
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12],
[13, 14, 15, 16]
],
# 样本1-通道2
[
[17, 18, 19, 20],
[21, 22, 23, 24],
[25, 26, 27, 28],
[29, 30, 31, 32]
],
# 样本2-通道1
[
[33, 34, 35, 36],
[37, 38, 39, 40],
[41, 42, 43, 44],
[45, 46, 47, 48]
],
# 样本2-通道2
[
[49, 50, 51, 52],
[53, 54, 55, 56],
[57, 58, 59, 60],
[61, 62, 63, 64]
]
], dtype=torch.float32).reshape(2, 2, 4, 4)
# 2样本2通道(正确,已验证)
data_2s2d = torch.tensor([
# 样本
[
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12],
[13, 14, 15, 16]
],
# 样本
[
[17, 18, 19, 20],
[21, 22, 23, 24],
[25, 26, 27, 28],
[29, 30, 31, 32]
],
# 样本
[
[33, 34, 35, 36],
[37, 38, 39, 40],
[41, 42, 43, 44],
[45, 46, 47, 48]
],
# 样本
[
[49, 50, 51, 52],
[53, 54, 55, 56],
[57, 58, 59, 60],
[61, 62, 63, 64]
]
], dtype=torch.float32)
# 2样本2通道(正确,已验证)
data_2s2f = torch.tensor([
# 样本
[
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12],
[13, 14, 15, 16]
],
# 样本
[
[17, 18, 19, 20],
[21, 22, 23, 24],
[25, 26, 27, 28],
[29, 30, 31, 32]
],
# 样本
[
[33, 34, 35, 36],
[37, 38, 39, 40],
[41, 42, 43, 44],
[45, 46, 47, 48]
],
# 样本
[
[49, 50, 51, 52],
[53, 54, 55, 56],
[57, 58, 59, 60],
[61, 62, 63, 64]
]
], dtype=torch.float32).unsqueeze(1)
print("2样本2通道形状:", data_2s2c.shape) # 输出:(2,2,4,4)
print("样本通道形状:", data_2s2d.shape) # 输出:(4,4,4)
print("样本通道形状:", data_2s2f.shape) # 输出:(4,4,4)此时新增了data_2s2f,相较于2s2d在最后增加了unsqueeze(1),代码输出的效果为:

样本数和通道数判断
实际上,定义张量的过程中,应当明确知道究竟定义了样本还是通道,因为中括号内部也可以代表通道数,比如继续修改上述代码:
python
import torch
# 2样本2通道(正确,已验证)
data_2s2c = torch.tensor([
# 样本1-通道1(两层括号:通道层+像素层)
[
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12],
[13, 14, 15, 16]
],
# 样本1-通道2
[
[17, 18, 19, 20],
[21, 22, 23, 24],
[25, 26, 27, 28],
[29, 30, 31, 32]
],
# 样本2-通道1
[
[33, 34, 35, 36],
[37, 38, 39, 40],
[41, 42, 43, 44],
[45, 46, 47, 48]
],
# 样本2-通道2
[
[49, 50, 51, 52],
[53, 54, 55, 56],
[57, 58, 59, 60],
[61, 62, 63, 64]
]
], dtype=torch.float32).reshape(2, 2, 4, 4)
# 2样本2通道(正确,已验证)
data_2s2d = torch.tensor([
# 样本
[
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12],
[13, 14, 15, 16]
],
# 样本
[
[17, 18, 19, 20],
[21, 22, 23, 24],
[25, 26, 27, 28],
[29, 30, 31, 32]
],
# 样本
[
[33, 34, 35, 36],
[37, 38, 39, 40],
[41, 42, 43, 44],
[45, 46, 47, 48]
],
# 样本
[
[49, 50, 51, 52],
[53, 54, 55, 56],
[57, 58, 59, 60],
[61, 62, 63, 64]
]
], dtype=torch.float32)
# 2样本2通道(正确,已验证)
data_2s2f = torch.tensor([
# 样本
[
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12],
[13, 14, 15, 16]
],
# 样本
[
[17, 18, 19, 20],
[21, 22, 23, 24],
[25, 26, 27, 28],
[29, 30, 31, 32]
],
# 样本
[
[33, 34, 35, 36],
[37, 38, 39, 40],
[41, 42, 43, 44],
[45, 46, 47, 48]
],
# 样本
[
[49, 50, 51, 52],
[53, 54, 55, 56],
[57, 58, 59, 60],
[61, 62, 63, 64]
]
], dtype=torch.float32).unsqueeze(1)
# 2样本2通道(正确,已验证)
data_2s2g = torch.tensor([
# 样本
[
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12],
[13, 14, 15, 16]
],
# 样本
[
[17, 18, 19, 20],
[21, 22, 23, 24],
[25, 26, 27, 28],
[29, 30, 31, 32]
],
# 样本
[
[33, 34, 35, 36],
[37, 38, 39, 40],
[41, 42, 43, 44],
[45, 46, 47, 48]
],
# 样本
[
[49, 50, 51, 52],
[53, 54, 55, 56],
[57, 58, 59, 60],
[61, 62, 63, 64]
]
], dtype=torch.float32).unsqueeze(0)
print("2样本2通道形状:", data_2s2c.shape) # 输出:(2,2,4,4)
print("样本通道形状:", data_2s2d.shape) # 输出:(4,4,4)
print("样本通道形状:", data_2s2f.shape) # 输出:(4,4,4)
print("样本通道形状:", data_2s2g.shape) # 输出:(4,4,4)此时新增了data_2s2g,这个张量使用unsqueeze(0)补充了样本维,输出效果为:
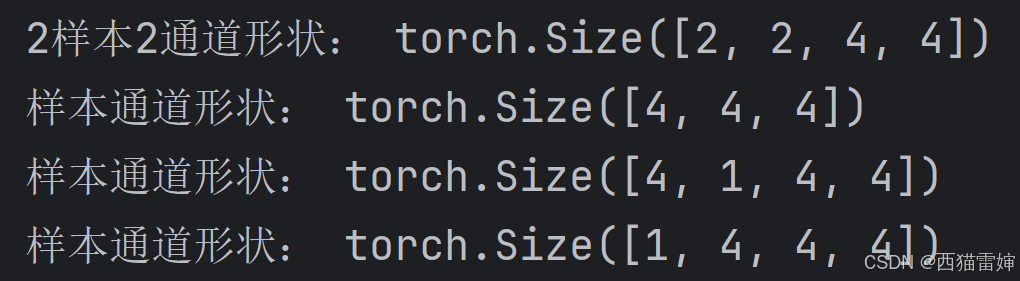
很显然,data_2s2f和data_2s2g的输出完全不一样。
总结
初步学习了CNN的四维Pytorch张量格式的基础知识。