本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。
在大模型应用的浪潮里,推理能力 和高效微调 正成为核心竞争力。尤其是在数学推理、逻辑问答、结构化输出等任务中,如何快速训练出一个推理稳定、推理链条清晰的模型,是很多开发者的痛点。
今天给大家推荐的这个项目,使用Unsloth训练自己的R1模型,就是一个端到端的 强化学习 推理模型训练实践,不仅跑得通,还跑得快。
创作者主页:www.heywhale.com/u/6a143e
项目指路:www.heywhale.com/u/e29054
项目简介及亮点解说
这个项目旨在演示如何利用Unsloth 框架在低显存条件下高效训练推理增强大模型 。项目基于DeepSeek-R1 同类架构,结合LoRA微调 、4bit量化 与GRPO * 强化学习*,实现从数据加载、模型训练到推理部署的完整流程。
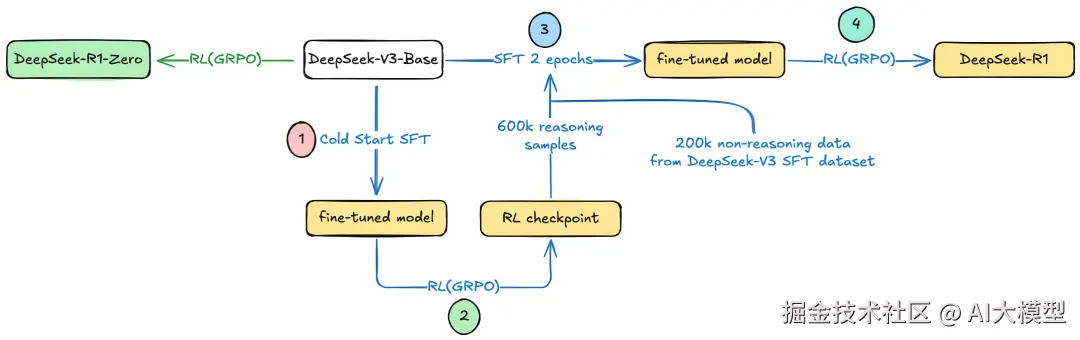
DeepSeek R1系列训练流程图,源自:Elwin Wong
训练数据以GSM8K数学推理集为例,并设计多维度奖励函数,既评估答案正确性,也衡量推理链完整度与格式规范性。该方案不仅显著降低了硬件门槛(单卡8GB可运行),还具备可复用性与可扩展性,适合在科研、数学问答、逻辑推理等任务中快速构建定制化大模型。
🌟加速利器:Unsloth+vLLM
传统RLHF或GRPO训练常常遇到两大问题:显存不够和推理太慢。
这个项目直接用上了Unsloth 的FastLanguageModel +vLLM快速推理 ,再配合4bit量化 与LoRA低秩适应,大幅降低显存占用。即便是单卡8GB显存,也能跑得动。亮点功能:
gpu_memory_utilization控制显存占用load_in_4bit=True显著压缩模型fast_inference=True加速生成

🌟数据驱动:GSM8K推理任务
项目选择了经典的数学推理数据集GSM8K,并用XML格式来约束模型的推理过程与答案输出:
xml
<reasoning>
推理步骤......
</reasoning>
<answer>
最终答案
</answer>这样的设计有两大好处:
- 可解析性强:方便后续自动评估或下游任务调用
- 奖励函数可精细化控制 :比如检查
<reasoning>是否闭合、<answer>是否存在、是否为数字等
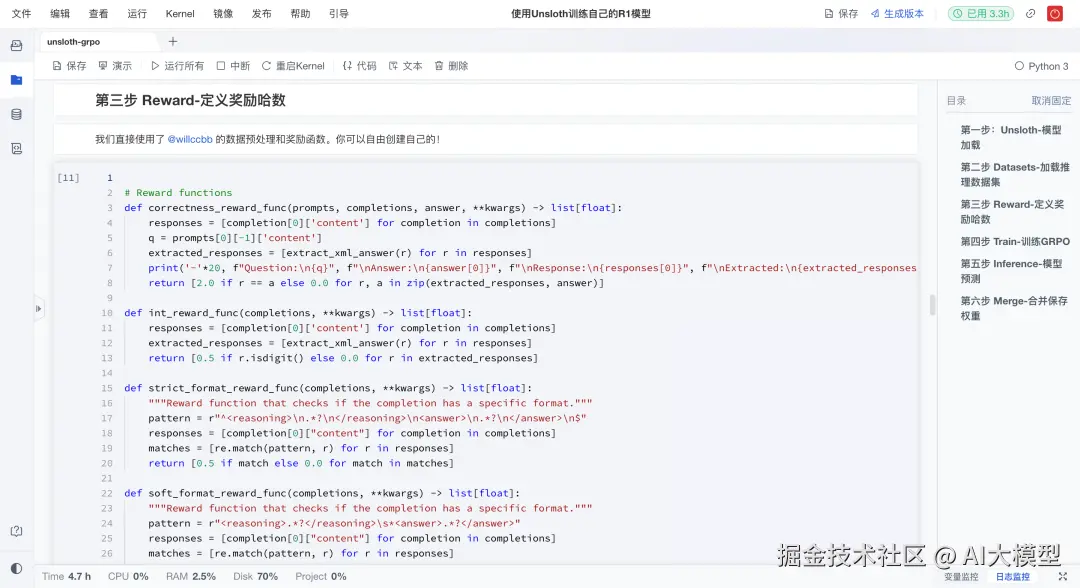
🌟奖励函数:从对不对到好不好
强化学习的关键是奖励设计。项目中定义了多个奖励函数:
- 正确性奖励:答案与标准答案匹配→+2.0
- 格式奖励:严格或宽松的XML标签检查→+0.5
- 数字判断奖励:答案是数字→+0.5
- 结构完整性奖励:标签数量与格式正确性计分
这种多维度奖励方式,让模型不仅要答对,还要答得规整。
🌟训练核心:GRPO优化
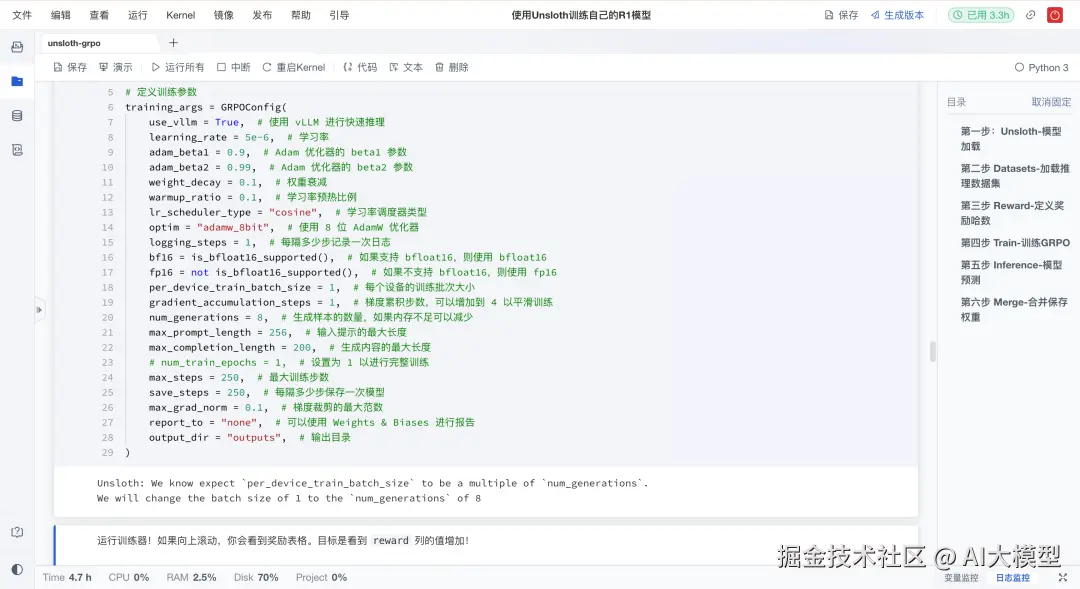
训练部分使用GRPOTrainer,结合如下优化:
- 学习率 * 调度*:余弦衰减+预热
- 梯度检查点:节省显存
- 8bit AdamW:加速优化
- 多样本生成:每次生成8个候选,增加探索性
训练日志也给出了参考,前100步可能奖励为0,150步后逐渐提升,这对初学者很重要------「别急,等模型"学会说话"」。
🌟推理与LoRA加载
训练完成后,模型的LoRA权重会被保存,可随时挂载到原模型进行推理。 推理示例里用低温采样 (temperature=0.1)保证稳定性,非常适合数学推理、法律逻辑等精确任务。
总的来说,这个项目的最大价值是可直接复用的 * 强化学习 *推理训练模板:
- 工程化细节到位
- 模块化设计方便替换
- 可扩展到自己的数据和任务
无论你做的是数学推理、代码生成还是结构化问答,都能在这个项目的基础上快速改造成属于你的R1模型。
学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。