初始设计检查(Initial Design Checks)
a)概述
1)检查初始设计:在实现(imp)之前,检查资源利用率、逻辑层级、时序约束。
2)时序基线:逐个实现步骤后,都检查并处理时序违规,方便布线后时序收敛。
3)解决时序违规:定位建立时间或保持时间违规的根因并解决。
b)可使用QoR报告快速检查设计。该报告将关键的设计和约束指标与推荐极值做比较,未符合要求的会标记为 REVIEW(需审查)。该报告包含如下章节:设计特性(Design characteristics)、方法学检查(Methodology checks)、基于目标最高频率的保守逻辑层级评估。(详见UG906)
c)Vivado在实现阶段会自动调用report_qor_suggestions命令。该报告将分析设计、提供优化建议,部分情况下会自动应用建议。在 Vitis环境中,使用编译参数v++ --R 1或v++ --R 2时,编译流程会自动调用report_qor_assessment生成报告。
d)
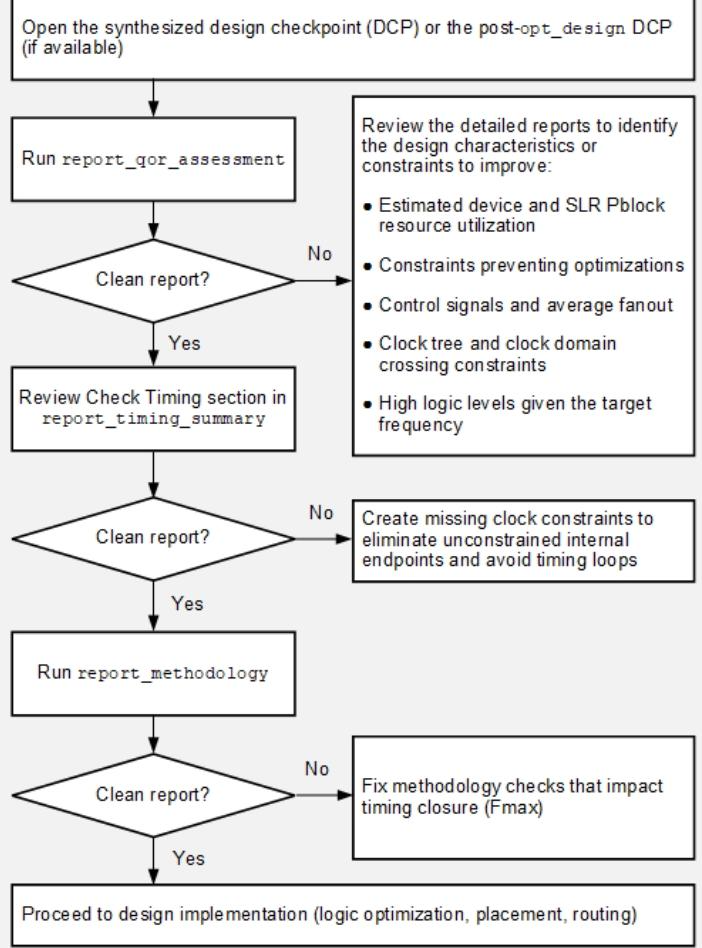
1)判断Clean report(QoR报告是否无异常):若不是,进入详细审查,筛选出宏观设计缺陷。若报告存在REVIEW项,需针对性优化以下维度:资源(器件、SLR、Pblock的资源利用率是否超标,因为过高易导致拥堵)、约束(是否存在阻碍优化的约束,如过度约束、约束冲突);信号(控制信号扇出是否过高,高扇出会增加网延迟);时钟(时钟树结构、跨时钟域约束是否合理);逻辑(目标频率下逻辑层级是否过高,高逻辑层级直接增加路径延迟)。
2)接着审查report_timing_summary:聚焦时钟约束完整性,此步骤专门检查无约束内部端点、时序环路。
3)判断Clean report(时序约束是否完整):若不是,则补充时钟约束,修复时序分析的底层缺陷,需通过create_clock、set_false_path等命令,补全缺失的时钟约束,消除无约束端点和时序环路。
4)接着审查report_methodology:确保设计适配工具优化策略,检查设计是否符合Vivado的优化方法学(如逻辑结构是否利于工具优化、约束写法是否符合最佳实践)。
5)判断Clean report(方法学是否合规):若不是,则修复方法学缺陷,消除工具优化的阻碍项。
e)在实现阶段若要自动解决大多数时序收敛难题,可以使用智能设计运行IDR。它是一种特殊的实现运行模式,应用了report_qor_suggestions、基于机器学习(ML)的策略预测、增量编译技术。详见UG949。
f)尽管在AMD器件上实现设计是一项自动化程度较高的任务,但要实现更高性能、解决因时序或布线违规导致的编译问题,过程可能复杂且耗时。仅通过工具生成的简单日志信息或后实现时序报告,往往难以定位失败原因。因此,必须采用分步式的设计开发与编译方法论,包括审查中间结果,以确保设计能够顺利进入下一阶段的实现流程。初始设计检查的第一步是确保所有初始检查项均已处理完毕。需从以下层级开展这些检查:
1)每个由自定义RTL代码生成或Vivado HLS工具生成的核。注:需验证目标时钟频率约束是否具备现实可行性。
2)每个对应子系统的主要层级结构,例如包含多个核、IP模块及连接逻辑的Vivado IP集成器框图。
3)包含所有主要功能与层级结构、I/O接口、完整时钟电路以及物理约束和时序约束的完整设计。
g)若设计使用了布局规划约束(如SLR、Pblocks),需审查每个物理约束对应的预估资源利用率,并确保其符合利用率指南要求。运行report_qor_assessment命令时,系统会自动检查SLR和Pblock的违规情况;若未报告违规,则说明设计的资源利用率处于可接受范围内。
h)遇到的一些问题
1)
时序基线建立
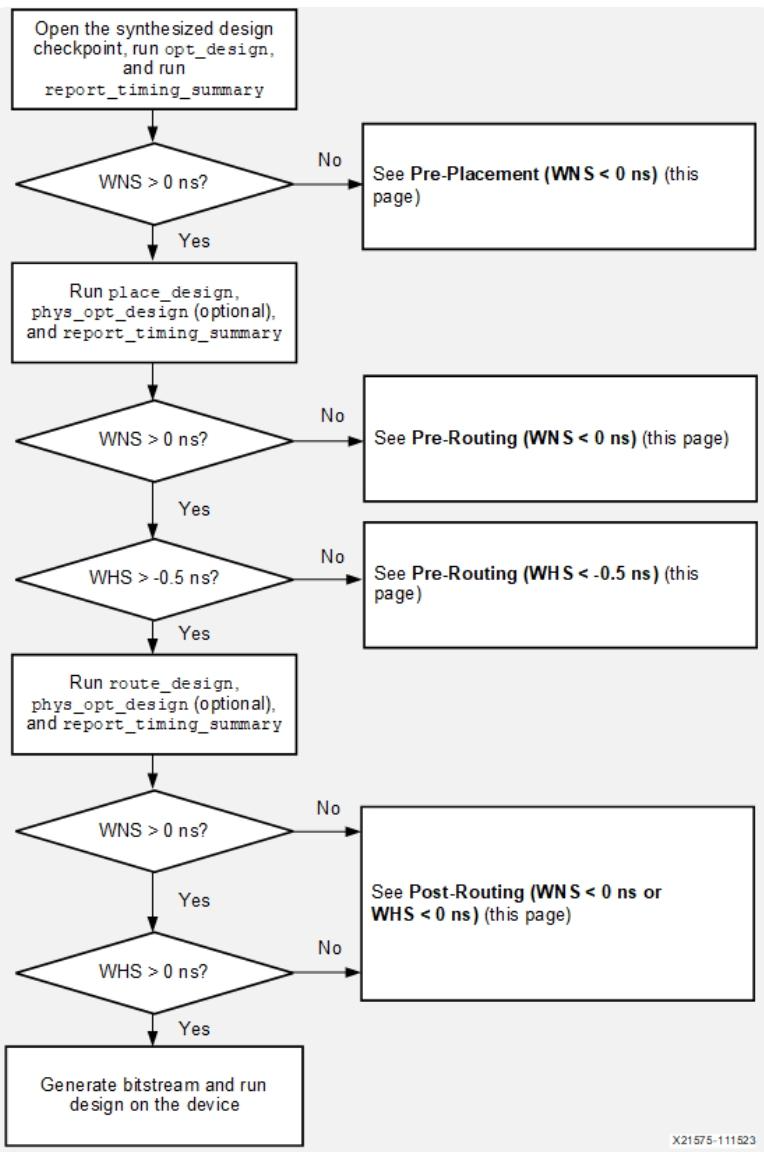
a)时序基线的目标是在每个实现的步骤后,分析并解决时序难题,确保设计满足时序要求。在编译流程早期修复设计与约束问题,能产生更广泛的优化效果并提升设计性能。在进入下一个实现步骤前,需通过生成中间报告来审查并处理时序违规。在每个实现步骤后添加以下报告命令:report_timing_summary、report_methodology、report_qor_assessment。
b)预布局阶段(Pre-Placement,WNS < 0 ns):布局前的时序报告假设每个逻辑路径都采用最优逻辑布局。若存在建立时间违规,需按照初始设计检查中的建议进行修复。
c)预布线阶段(Pre-Routing,WNS < 0 ns):布线前,时序报告是假设每个网络都采用最优布线延迟的(已考虑部分扇出代价,但未考虑保持时间修复的影响(如网络布线绕路)、拥堵问题)。若 WNS<0,说明布局导致路径延迟变差。建立时间违规通常源于次优布局,具体原因包括:1)器件、SLR资源利用率过高;2)复杂逻辑导致的布局拥堵;3)大量路径存在过多逻辑层级;4)非平衡时钟间的高时钟偏差或高时钟不确定性。此时需在Explore或AggressiveExplore模式下运行phys_opt_design,尝试提升布局后QoR。若优化无效,则需着重改善布局的QoR。
d)预布线阶段(Pre-Routing,WHS < -0.5 ns):若布线后未达到性能目标,且预布线阶段的WNS为正值,此时需尝试减少预估的WHS违规。预布线阶段的保持违规越少、违规程度越轻,route_design就能更专注于提升最高频率,而非花费资源修复保持时间违规。
e)后布线阶段(Post-Routing,WNS < 0 ns 或 WHS < 0 ns):route_design后,需检查日志或对布线后DCP运行report_route_status,验证设计是否完全布线。布线违规和严重的WNS/WHS违规,多与布线拥堵、线网延迟强相关。需分析拥堵等级(report_route_status),针对性优化(如降低资源利用率、高扇出网络)。参考《建立时间违规分析》、《保持时间违规解决》、《拥堵解决技术》,定位并执行修复步骤。对于违规值>-0.200ns的小幅建立时间违规,可尝试在布线后运行phys_opt_design进行修复。
f)在迭代设计、约束、编译策略时,需记录每个步骤后的QoR(包括拥堵信息)。使用QoR表格对比各次运行的特性,明确处理剩余时序违规时需优先关注的方向。

g)
h)遇到的一些问题
1)
在报告中查找建立时间时序路径特性
a)在Vivado项目模式下,查找建立时间时序路径特性:
时序摘要报告:<运行名称>_<流程步骤>report_timing_summary(文本格式为.rpt)
设计分析报告:<运行名称><流程步骤>_report_design_analysis
b)注意:使用Vivado可对报告、原理图、Device窗口之间进行交叉探查。对于每条时序路径,逻辑延迟、布线延迟、时钟偏差、时钟不确定性位于报告头部。此外还附加了逻辑层级、布线等额外信息。
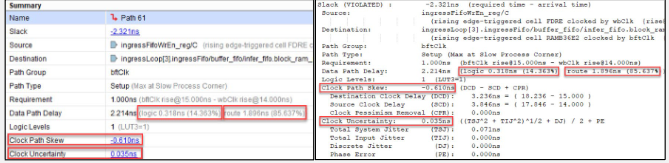

c)可根据需要右键单击表格标题以启用或禁用列。例如,DONT_TOUCH或MARK_DEBUG列默认不可见,启用这些列可查看否则难以识别的重要信息(如跳过逻辑优化分析的信息)。
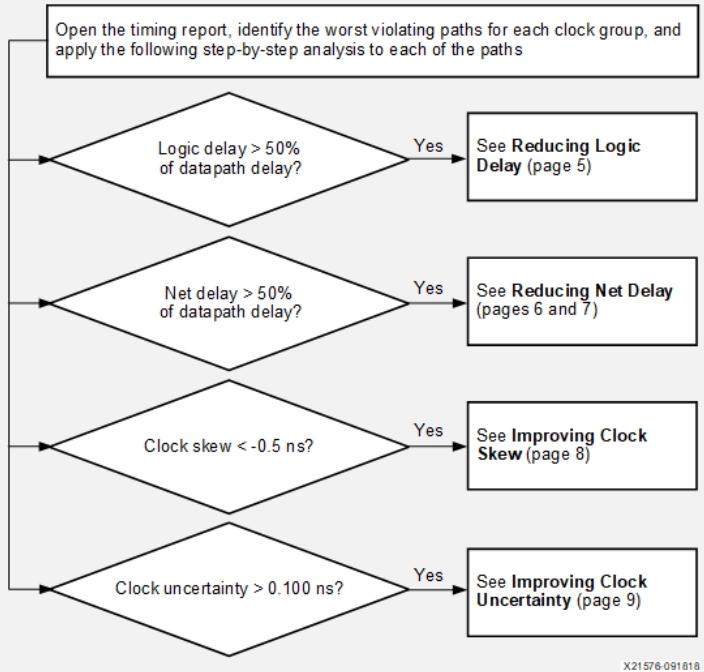
d)设计性能由以下因素决定:
1)时钟偏差与时钟不确定性(时钟的实现效率,即时钟电路的优化程度);
2)逻辑延迟(一个时钟周期内信号需经过的逻辑单元数量或逻辑层级);
3)线网或布线延迟(Vivado在实现设计时,布局与布线的效率)。
利用时序路径报告或设计分析报告识别上述哪个因素是导致时序违规的主要原因、确定如何通过迭代优化提升QoR。若有需要,可在每个步骤后打开DCP,生成额外报告以补充分析数据。
e)
在报告中查找保持时间时序路径特性
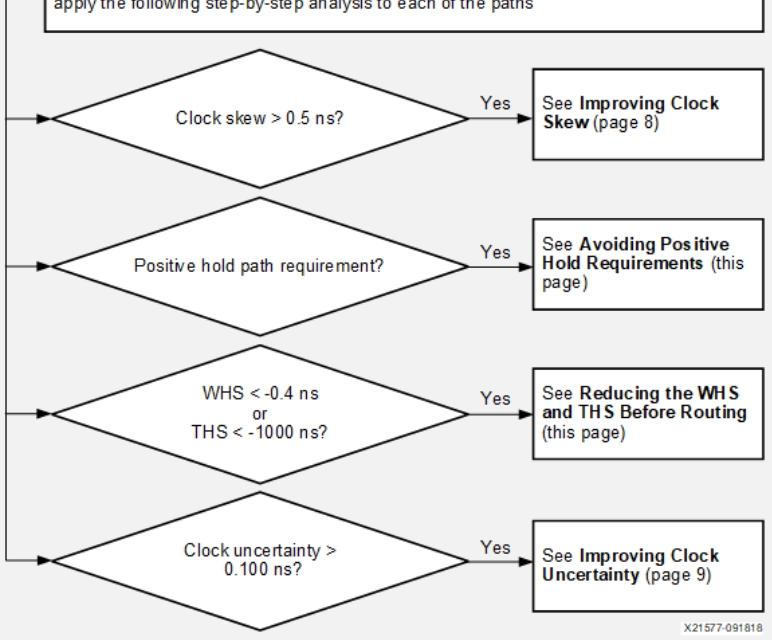
a)避免正保持需求
1)在多周期建立时间检查时,必须同步调整同一路径上的保持时间检查,确保两者采用相同的发射沿和捕获沿。若忽略此调整,将导致正保持时间需求(可能持续一个或多个时钟周期),从而无法实现时序收敛。
2)应明确指定端点引脚而非指定单元或时钟。例如,对于单元REGB的三个输入引脚(C、EN、D),只有数据输入引脚D适用于多周期路径约束,而不应将时钟使能EN引脚纳入约束范围,因为EN在每个时钟周期都可能变化。若约束仅附加到单元而非具体引脚,所有有效端点引脚(包括不合适的EN引脚)都会被自动纳入约束范围。
2)建议使用以下语法
c
set_multicycle_path -from [get_pins REGA/C] -to [get_pins REGB/D] -setup 3
set_multicycle_path -from [get_pins REGA/C] -to [get_pins REGB/D] -hold 2b)布线前减少WHS和THS
1)较大的预估保持时间违规会增加布线难度,且route_design并非总能解决这些问题。布局后phys_opt_design命令提供了几种保持时间修复选项:
①插入反边沿触发寄存器(phys_opt_design -insert_negative_edge_ffs):在时序元件之间插入反边沿触发寄存器,将一条时序路径拆分为两条半周期路径,可显著减少保持时间违规。仅当建立时间不会恶化时,才会执行此优化。使用命令:
②插入LUT1缓冲器:通过延迟数据路径,减少保持时间违规(且不引入建立时间违规)。
c
phys_opt_design -hold_fix:仅对最大WHS违规的路径执行LUT1插入。
phys_opt_design -aggressive_hold_fix:对更多路径执行LUT1插入,以显著减少总保持时序裕量,但会导致LUT利用率明显增加、编译时间延长。此选项可与任何phys_opt_design指令结合使用。
phys_opt_design -directive ExploreWithAggressiveHoldFix:除执行所有其他旨在提高Fmax的物理优化外,还通过LUT1插入修复保持时间违规。c)
减少逻辑延迟
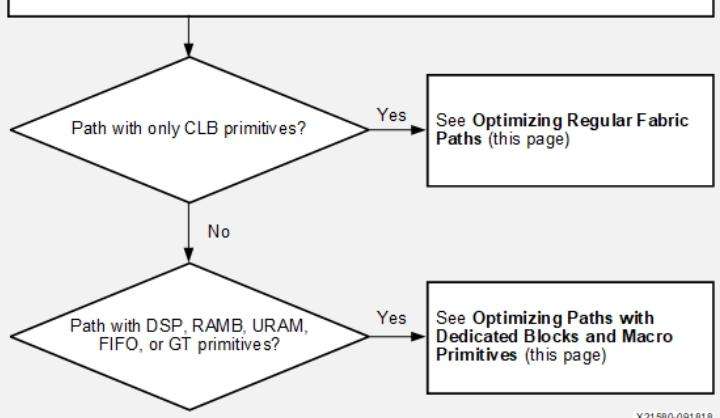
a)优化常规Fabric路径
1)常规Fabric路径是寄存器(FD*)或移位寄存器(SRL*)之间的路径,会经过LUT、MUXF、CARRY的组合。若常规Fabric路径出现问题,AMD建议采取以下措施:(更多信息参考UG901、UG904)
①针对高逻辑层级,可通过report_qor_assessment命令结合LUT/net预算检查来定位高逻辑层级路径。在设计初期通过RTL代码重构或重定时技术解决。优化建议:启用综合重定时、模块应用BLOCK_SYNTH.RETIMING 1、特定单元RETIMING_FORWARD/BACKWARD属性。
c
set_property BLOCK_SYNTH.RETIMING 1 [get_cells my_target_module]②小型级联LUT(LUT1-LUT4)通常可以合并为更少的LUT,但以下情况会阻止合并:设计层级限制、扇出≥10的中间网络、存在KEEP、KEEP_HIERARCHY、DONT_TOUCH、MARK_DEBUG等属性。优化建议:移除限制属性后,重新综合或执行opt_design -remap命令进行优化。
③单个CARRY非级联单元会限制LUT优化并可能导致次优布局。优化建议:使用FewerCarryChains综合指令,或对目标设置CARRY_REMAP属性,使opt_design可移除该CARRY单元。
④移位寄存器SRL的延迟通常高于寄存器FD,且其布局优化程度也较低。优化建议:在RTL中使用SRL_STYLE属性,或在综合后对单元设置SRL_STAGES_TO_INPUT/SRL_STAGES_TO_OUTPUT属性,将SRL的输入/输出寄存器转为FD*;动态SRL需在RTL中修改。
⑤当逻辑路径以LUT驱动Fabric寄存器的时钟使能、同步置位、同步复位引脚时,其布线延迟会显著高于驱动寄存器数据引脚,在路径末端网络的扇出大于1时尤为明显。优化建议:若以数据引脚为终点的路径具有更优的时序裕量和更少的逻辑层级,可在RTL代码中为相关信号设置EXTRACT_ENABLE或EXTRACT_RESET属性为no、在单元上设置CONTROL_SET_REMAP属性,该优化将在opt_design阶段自动执行。
b)优化含专用模块和宏原语的路径
1)往返于专用模块/宏原语(如DSP、RAMB、URAM、FIFO、GT_CHANNEL)或其之间的逻辑路径,布局难度更高,且单元与布线延迟更大。因此,在宏原语周围增加额外流水线寄存器,或减少宏原语路径的逻辑层级,对提升设计整体性能至关重要。修改RTL前,可通过启用所有可选的DSP、RAMB、URAM寄存器并重实现流程,验证增加流水线带来的QoR收益。采用该评估方法时无需生成比特流,命令:set_property --dict {DOA_REG 1 DOB_REG 1} get_cells xx/ramb18_inst
2)以下为布线后报告的RAMB18路径示例,该路径需增加额外流水线寄存器或减少逻辑层级:

c)Vivado实现流程优先聚焦于最关键的路径。这意味着在布局或布线后,原本难度较低的路径往往会变为关键路径。AMD建议在综合后或 opt_design后识别并优化最长路径,因为此举对QoR影响最大,且通常能大幅减少实现时序收敛所需的布局布线迭代次数。
1)可使用report_design_analysis中的逻辑层级分布表,通过将逻辑层级分布与时序需求进行比对,定位需要优化的时钟域。需求越严格(如目标频率越高),允许的逻辑层级越少。例如,在以下布局前逻辑层级分布报告中:

针对时钟域txoutclk_out0_4需审查所有逻辑层级≥8的路径;针对时钟域app_clk需审查所有逻辑层级≥11的路径。
2)级联的CARRY(进位)或MUXF(多路选择器)单元可能会人为增加逻辑层级数量,但对延迟的影响较小。
3)在Vivado报告中,点击逻辑层级数字即可选中对应路径,按下F4可生成原理图,进而审查路径的逻辑结构。
d)
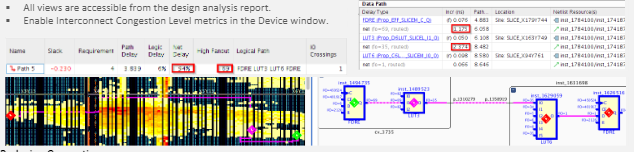
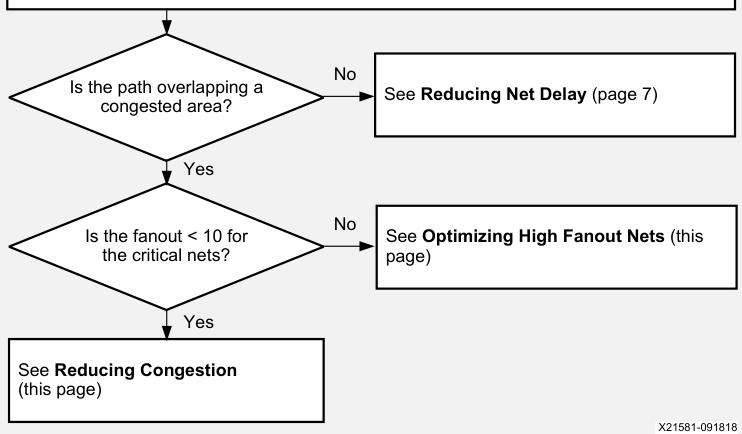
减少拥堵
a)以下为关键时序路径因拥塞区域导致布线绕路、进而增加净延迟的示例:
b)拥堵优化建议,按顺序给出:
1)当整体资源利用率超过70%-80%时,通过移除部分功能或迁移至其他SLR,降低器件或SLR利用率。避免LUT与DSP/RAMB/URAM的利用率同时超过80%。若宏原语利用率必须维持在较高水平,可尝试将LUT利用率控制在60%以下,此举能在不引入复杂布局规划约束的前提下,为拥塞区域的逻辑布局提供更多空间。布局后可通过report_qor_assessment查看各SLR的利用率。
2)将拥塞区域的非关键路径高扇出网络提升至全局时钟路由:set_property CLOCK_BUFFER_TYPE BUFG get_nets \<高扇出网络名\>。
3)合并综合生成的复制网络,减少拥塞区域内的等效网络重叠。可从RTL和XDC中移除MAX_FANOUT属性,或对目标单元执行命令:set_property EQUIVALENT_DRIVER_OPT merge 目标单元。
4)尝试多种布局器指令(如AltSpreadLogic或SSI_Spread )、Congestion_*系列实现运行策略,或ML策略。
5)减少拥塞区域内MUXF与LUT的组合使用。可参考设计分析报告拥塞部分的对应列,对拥塞叶单元设置MUXF_REMAP=1且SOFT_HLUTNM = ""。可借助report_qor_suggestions获取建议。
6)执行report_design_analysis -complexity -congestion,识别单元数> 15000且连接复杂度高(Rent指数>0.65或平均扇出>4)的大型拥塞模块。在XDC文件中添加设置如下:set_property BLOCK_SYNTH.STRATEGY {ALTERNATE_ROUTABILITY} get_cells \<拥塞层级单元名\>。
7)复用此前低拥塞实现运行中的DSP、RAMB、URAM布局约束,示例命令:read_checkpoint -incremental routed.dcp -reuse_objects all_rams -fix_objects all_rams。
c)优化高扇出网络
1)在RTL中显式采用基于层级的寄存器复制,或通过以下逻辑优化实现:opt_design --merge_equivalent_drivers --hier_fanout_limit 512。
2)布局前通过更多物理优化步骤,对关键高扇出网络强制启用复制:set_property FORCE_MAX_FANOUT 1 目标网络。
d)全局拥塞对设计性能的影响如下:4级(16x16规模):布线设计过程中,QoR的波动性较小;5级(32x32规模):布局效果次优,且 QoR出现明显波动;6级(64x64规模):布局与布线难度大,编译时间延长,除非性能目标较低,否则时序QoR会严重劣化;7级(128x128规模及以上):无法完成布局或布线。
e)当拥塞等级达到4级及以上时,route_design命令会在日志文件中输出初始预估拥塞表。若需同时查看布局器和布线器的拥塞信息,可使用命令:report_design_analysis --congestion。在Vivado中打开布局后或布线后的DCP,可生成交互式的report_design_analysis窗口。通过高亮拥塞区域,并借助交叉探查功能,可直观查看拥塞对单个逻辑路径布局与布线的影响。
f)
减少线延迟
a)修复因保持修复绕路导致的建立违规
1)为确保设计在硬件中可正常工作,修复保持违规的优先级高于修复建立违规(或最高工作频率Fmax)。以下示例为两个同步时钟间存在高偏差、且建立要求严格的路径:

注:保持修复绕路(Hold Fix Detour)的单位为皮秒。若需解决保持修复绕路对Fmax的影响,参见《保持违规解决章节》。
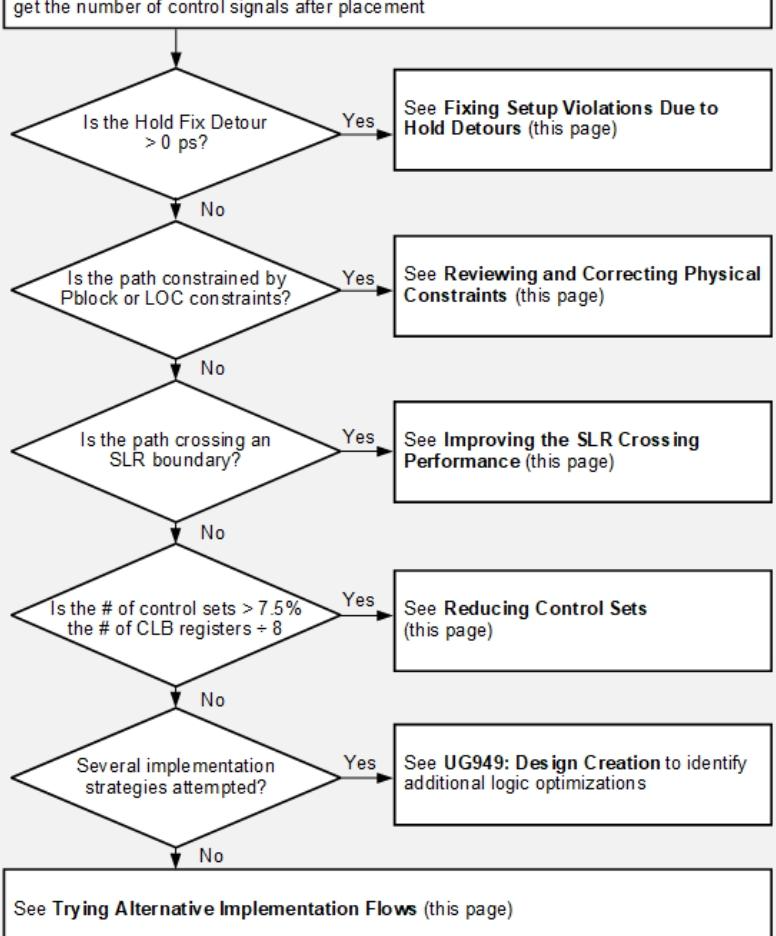
b)检查和纠正物理约束
1)所有设计均包含物理约束。尽管I/O位置通常无法修改,但在进行设计变更时,必须仔细检查Pblock与位置约束。设计变更可能导致逻辑单元间距增大,进而引入较长的净延迟。需重点审查跨多个Pblock(对应报告中PBlocks列)及含位置约束(对应报告中Fixed Loc列)的路径。
c)提升SLR交互性能:针对堆叠硅互连架构器件,在设计早期考虑以下措施可提升性能:
1)在设计层级边界添加流水线寄存器,助力长距离布线与SLR交叉布线;
2)验证各SLR的资源利用率是否符合指南(使用report_qor_assessment命令);
3)采用USER_SLR_ASSIGNMENT软约束引导实现工具(详见《UG949:使用软SLR布局规划约束》);
4)若软约束无效,可采用SLR Pblock布局约束;
5)布局或布线后运行phys_opt_design -slr_crossing_opt。
d)减少控制集:当器件或单个SLR的控制集数量超过指南阈值(7.5%)时,需尝试减少控制集:
1)在RTL中移除时钟使能CE、置位S、复位R信号的MAX_FANOUT属性;
2)提高综合阶段控制信号的最小扇出(synth_design --control_set_opt_threshold 16);
3)通过opt_design --control_set_merge或--merge_equivalent_drivers,合并复制的控制信号;
4)对CLB寄存器单元设置CONTROL_SET_REMAP属性,将低扇出控制信号重映射至 LUT。
e)替换实现流程:默认编译流程可快速获取设计基线,若时序不满足可启动分析。若初始实现后时序不达标,可尝试以下流程:
1)尝试多种place_design指令(最多10种),及多次phys_opt_design迭代(如Aggressive*、Alternate*类指令);
2)在place_design/phys_opt_design阶段,通过set_clock_uncertainty对最关键时钟进行过约束(最多0.500ns);
3)通过group_path --weight提高"必须满足时序的时钟"的时序QoR优先级;
4)小幅设计修改后,采用增量编译流程,以保留QoR并缩短运行时间;
5)运行report_qor_suggestions生成的设计Top 3实现ML策略。
f)
减少时钟skew
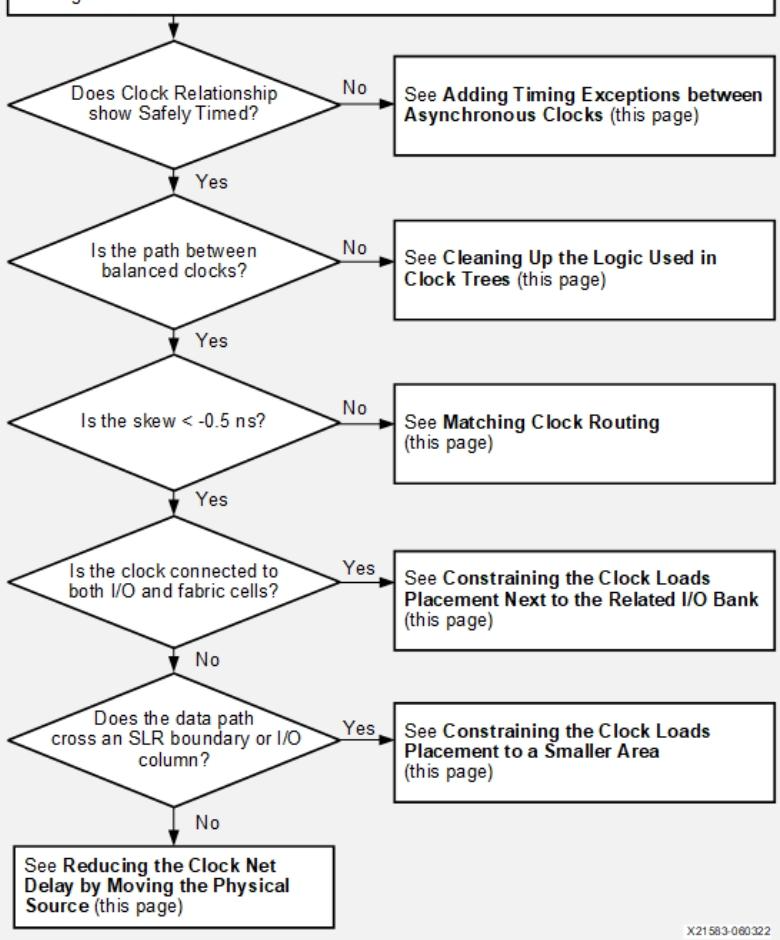
a)异步时钟添加时序例外
1)若时序路径的源时钟与目的时钟源自不同主时钟,或无公共节点,则这些时钟必须视为异步时钟。这种情况下,时钟偏差可能极高,导致时序无法收敛。需根据需求添加set_clock_groups(时钟组约束)、set_false_path(伪路径约束)、set_max_delay --datapath_only(仅数据路径最大延迟约束)。参考《UG949:为异步时钟添加时序例外》。
b)清理时钟树中的逻辑
1)除非对时钟逻辑施加了DONT_TOUCH约束,否则opt_design会自动清理时钟树。选中时序路径,启用Clock Path Visualization工具栏按钮,再打开原理图(按F4)即可审查时钟逻辑。
2)通过移除不必要的缓冲器或并行连接,避免级联时钟缓冲器之间存在时序路径。例如:将并行时钟缓冲器合并为单个时钟缓冲器(时钟非等效时除外)。

3)移除时钟路径中的LUT或任何组合逻辑,这类逻辑会导致时钟延迟和时钟偏差变得不可预测。
c)匹配时钟路由
1)即使两条时钟网络已具备相同的CLOCK_ROOT,仍可使用CLOCK_DELAY_GROUP提升关键同步时钟之间的路由延迟匹配度。以下示例为未使用CLOCK_DELAY_GROUP的两条同步时钟。

d)约束时钟负载布局至相关I/O Bank附近
1)对于I/O与逻辑单元之间、负载数量少于2000的时钟,可在时钟网络上设置CLOCK_LOW_FANOUT属性,该属性会自动将所有负载布局在时钟缓冲器BUFG*所在的同一时钟区域,从而降低插入延迟和时钟偏差。
e)约束时钟负载布局至小区域
1)可使用Pblock强制时钟网络的负载布局在更小区域(如1个超级逻辑区域SLR),既能减少插入延迟和时钟偏差,也能避免跨越特殊列(如会引入偏差代价的I/O列)。
f)通过移动物理源减少时钟网络延迟
1)使用位置约束将时钟源移动至时钟负载的中心位置,降低时钟的最大插入延迟,进而减少时钟悲观度(因延迟不确定性引入的冗余)和时钟偏差。
g)
减少时钟不确定性
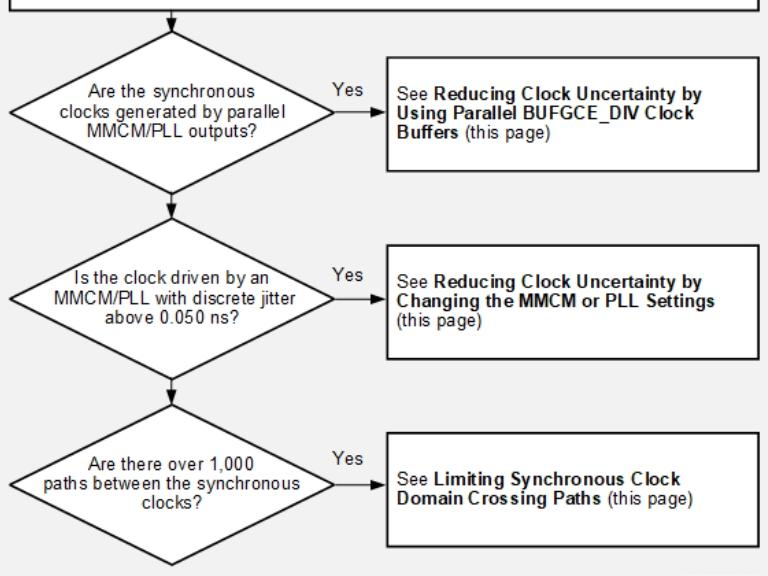
a)通过并行BUFGCE_DIV时钟缓冲器降低时钟不确定性
1)对于由同一MMCM/PLL生成、且时钟周期比为2、4、8的同步时钟,只需使用1个MMCM或PLL输出,并将其连接至并行BUFGCE_DIV时钟缓冲器。这种时钟拓扑可消除MMCM/PLL的相位误差,该误差在多数情况下会导致0.120ns的时钟不确定性。以下是150MHz与300MHz 时钟间的CDC路径中,时钟不确定性降低的示例:优化前时钟不确定性0.188 ns(建立时序)、0.188 ns(保持时序);优化后时钟不确定性:0.068 ns(建立时序)、0.000 ns(保持时序)。可使用Clocking Wizard生成含并行BUFGCE_DIV缓冲器的时钟拓扑,并为时钟设置CLOCK_DELAY_GROUP属性。
b)通过调整MMCM/PLL设置降低时钟不确定性
1)MMCM/PLL等时钟修改模块会以离散抖动和相位误差的形式导致时钟不确定性,使用Clocking Wizard或使用set_property命令,通过修改M和D值提高VCO频率。例如:VCO频率为1GHz的MMCM会引入167ps抖动与384ps相位误差,而VCO频率为1.43GHz的MMCM仅引入128ps抖动与123ps相位误差。
c)限制同步时钟域交叉路径
1)由分开的时钟缓冲器驱动的同步时钟,其跨域时序路径会表现出更高的时钟偏差。因为时钟树的公共节点位于时钟缓冲器之前,导致时序分析中的时钟悲观度(因延迟不确定性引入的冗余)升高。因此,这类路径难以同时满足建立与保持时序要求,尤其是在时钟频率超过 500MHz的场景下。
2)若需统计两个时钟间的路径数量,可使用report_timing_summary或report_clock_interaction命令。以下示例为两个高频时钟(时序需求=1.592ns)间存在大量跨域路径的设计:30%的路径时序违规,表明这类路径实现难度极高。

3)审查时钟域交叉涉及的逻辑,移除冗余逻辑路径,或尝试以下修改:①对由时钟使能控制的路径添加多周期路径约束,因这类路径并非每个时钟周期都传输新数据;②用异步跨域电路及对应的时序例外替换原有跨域逻辑(代价是增加额外延迟),例如使用异步FIFO或XPM_CDC参数化宏。
d)时钟不确定性是输入抖动、系统抖动、离散抖动、相位误差、用户添加的不确定性的总和,将其叠加到理想时钟边沿上,可精准建模硬件的实际工作环境。时钟不确定性会同时影响建立时序路径与保持时序路径,且其大小会根据时钟树中使用的资源(如缓冲器类型、布线路径)而变化。
QoR报告
a)QoR评估分数用于预估设计达成时序的可能性,具体分级如下:1分设计无法完成实现流程;2分设计可完成实现流程,但无法满足时序要求;3分设计大概率无法满足时序要求;4分设计大概率可满足时序要求;5分设计可满足时序要求。
b)AMD建议在设计流程早期使用QoR评估分数,此阶段潜在的编译时间节省最大。但在流程不同阶段,分析的准确程度存在差异。report_qor_assessment命令会根据设计当前状态自动调整分析维度,同时考虑后续流程中可能的优化空间。各设计状态下的分析内容如下:
1)未布局:分析单元利用率、较宽松的时钟偏差阈值、LUT/net预算检查,不包含拥塞分析;
2)已布局:分析拥塞情况及更严格的时钟偏差阈值,不包含LUT/net预算检查;
3)已布线:分析内容与阈值完全准确。
注:分数基于当前可获取的最优指标计算,准确性误差约为±1分。
c)提升QoR评估分数的方法
1)在执行report_qor_assessment后,运行report_qor_suggestions可获取修复问题或降低编译失败风险的建议。若存在对应优化建议,评估分数较低的项(在QoR评估报告中标记为REVIEW状态)会自动被优先排列在QoR建议报告顶部。
2)SLR与Pblock分析:工具会自动对SLR和Pblock进行分析,仅报告分数低于5分的项(即未达标的项)。
3)开展进一步分析:使用-csv_output_dir选项可输出以下CSV文件,用于深入分析,qor_timing_<design_stage>.csv详细列出未通过网络与LUT预算检查的时序路径;qor_dont_touch_<design_stage>.csv列出含DONT_TOUCH属性的叶单元 / 层级单元及网络。
提示:在项目模式下,可通过以下Tcl命令添加评估报告:set_property STEPS.OPT_DESIGN.TCL.POST <路径>/postopt.tcl get_runs impl_\*
d)QoR 评估报告包含以下几个部分:
1)总体评估摘要:提供QoR评估分数,以及用于提升QoR的优化建议。
2)QoR评估详情:展示各项指标的QoR信息。对于分数低于5分的项目,状态列会标注REVIEW(需审查)。
3)提示:若要评估标注REVIEW状态项目的风险,可对比阈值列与实际值列的数据。阈值会根据设计内容和目标器件自动调整。若需查看通过检查的项目,可使用-full_assessment_details选项。
4)方法论检查详情:展示与方法论相关、且会影响QoR的失败项目。
5)ML策略可用性:列出生成ML策略时,训练运行所需的指令。