

今日语录:只有经历地狱般的磨练,才能炼出创造天堂的力量。
文章目录
⭐一、两数之和
题目链接:两数之和
题目描述:
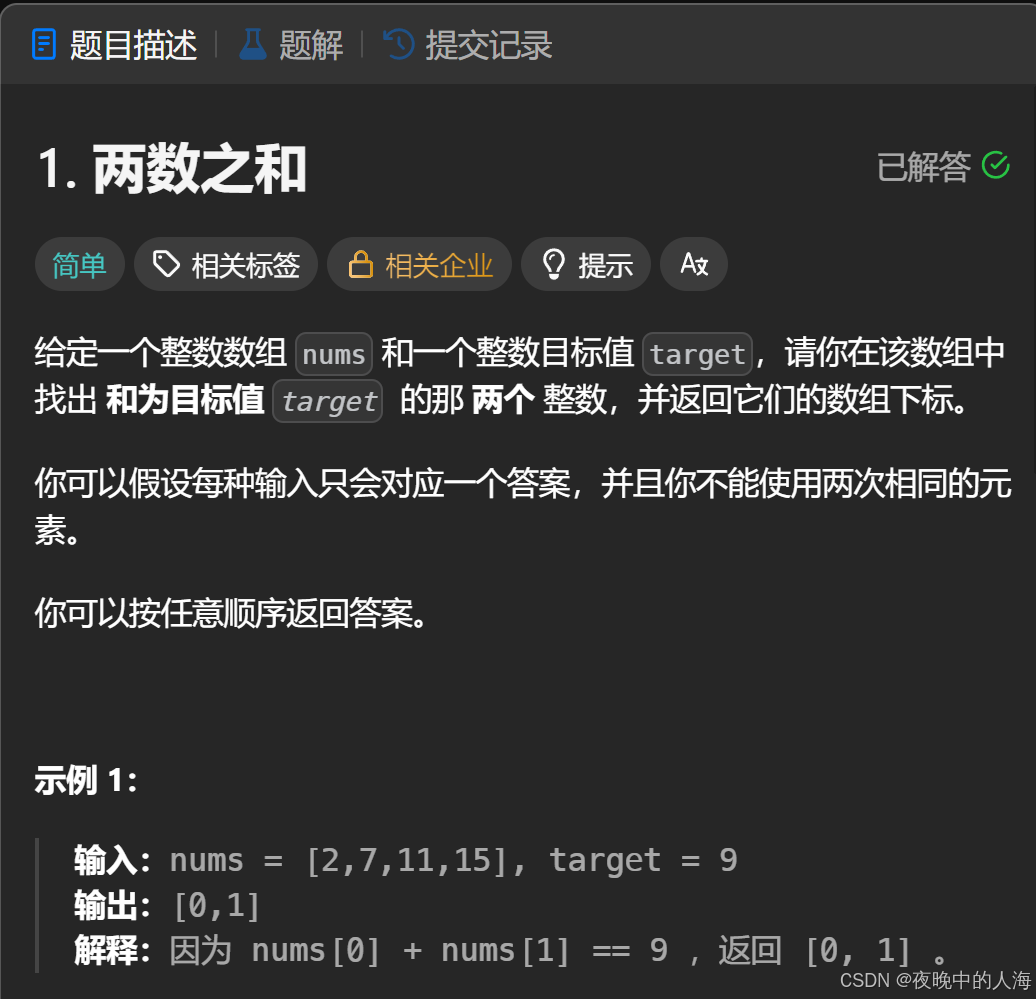
解题思路:
1.解法一:采用暴力解法,使用两层for循环遍历所有的数对,时间复杂度为O ( n² ),查找互补数时时间复杂度为O(n),整体时间复杂度高
2.解法二:使用哈希表 ,采用空间换时间的方法,存储已经遍历过的元素及其下标,将查找互补数的时间复杂度从O(n)降成O(1),整体时间复杂度变成O(n)
代码实现:
cpp
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
//存储元素的值和对应的下标
unordered_map<int,int> hash;
int n = nums.size();
for(int i = 0;i < n;i++)
{
int x = target - nums[i];
if(hash.count(x))
return {i,hash[x]};
else
hash[nums[i]] = i;
}
return {-1,-1};
}
};🎄二、判定是否为字符重排
题目链接:判定是否为字符重排
题目描述:
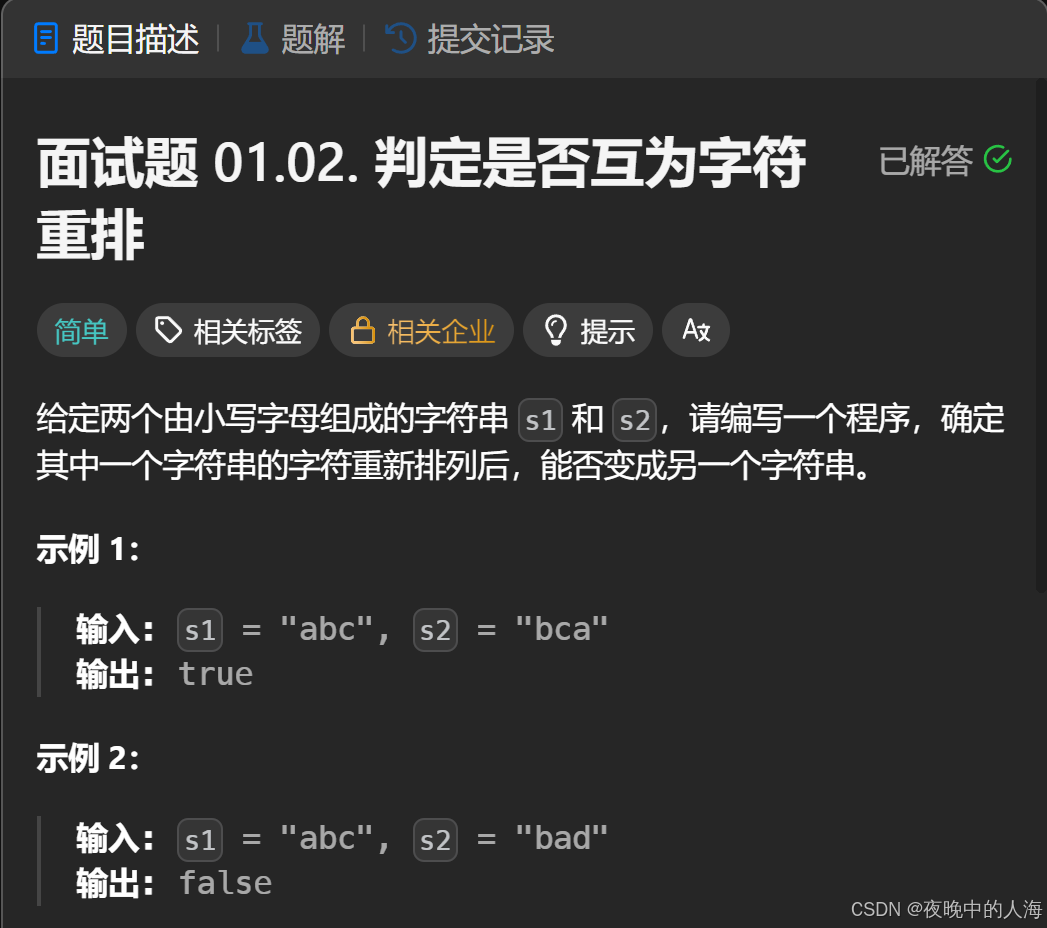
解题思路:
1.先处理边界情况,如果两个字符串长度不相等,则说明这两个字符串肯定构不成重排,直接返回false即可
2.如果两个字符串能构成重排 ,说明两个字符串中出现的字符个数是相等的 ,因此问题就转化成看这两个字符串中出现的字符个数是否相等,我们就可以借助哈希表来统计字符出现的个数
代码实现:
cpp
class Solution {
public:
bool CheckPermutation(string s1, string s2) {
if(s1.size() != s2.size())
return false;
int hash[26] = {0};
//遍历第一个字符串,并将其存进哈希表中
for(auto ch : s1)
{
hash[ch - 'a']++;
}
//遍历第二个字符串
for(auto ch : s2)
{
if(--hash[ch - 'a'] < 0)
return false;
}
return true;
}
};🏖️三、存在重复元素I
题目链接:存在重复元素I
题目描述:
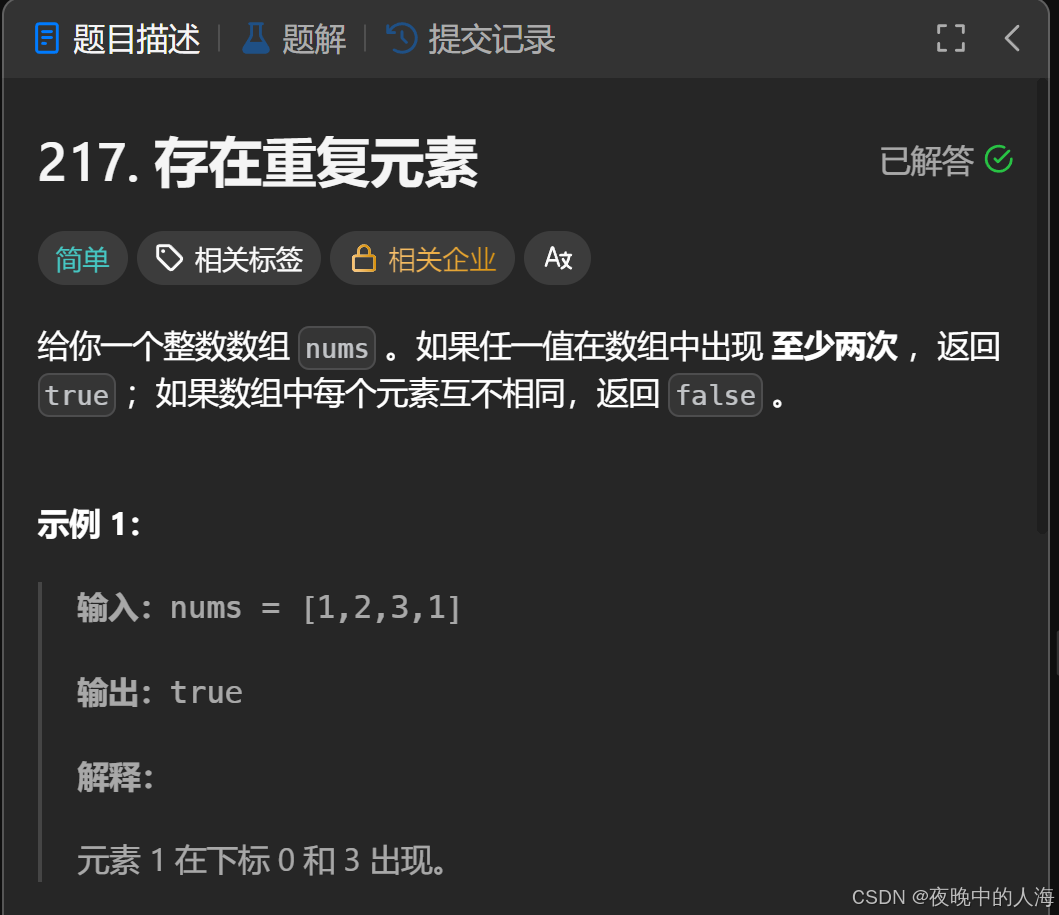
解题思路:
1.由于题目要求在数组中寻找至少出现两次的数字,因此我们只需检查当前数字是否已经出现过
2.借助哈希表这一容器,如果在遍历过程中该元素没出现过,则将它存进哈希表中,否则直接返回false即可
代码实现:
cpp
class Solution {
public:
bool containsDuplicate(vector<int>& nums) {
unordered_set<int> hash;
for(auto n : nums)
{
if(hash.count(n))
{
return true;
}
hash.insert(n);
}
return false;
}
};🏠四、存在重复元素II
题目链接:存在重复元素II
题目描述:
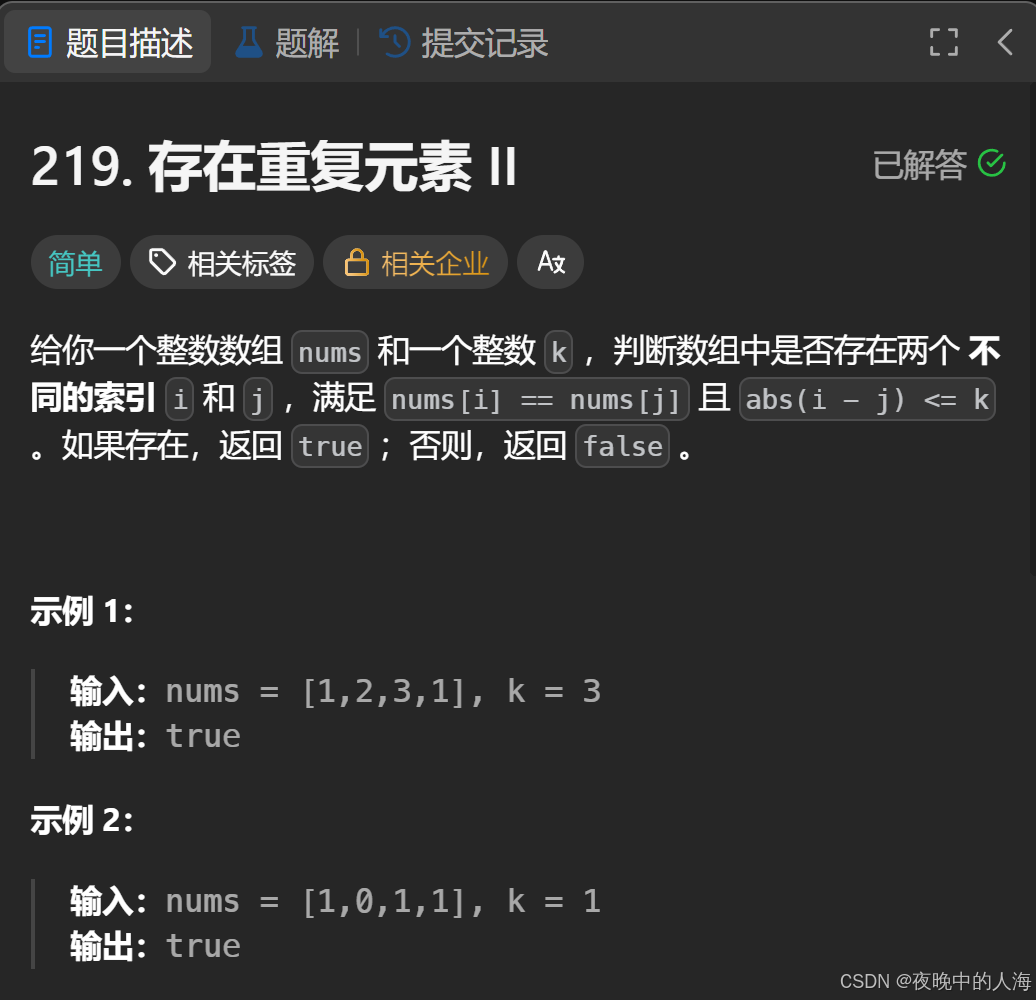
解题思路:
1.我们可以使用哈希表,将数组元素和对应的下标绑定一块存入哈希表中,在哈希表中检查对是否出现过该元素
2.在遍历过程中如果哈希表中已经出现该元素,我们还需判断一下它们对应的下标差是否 <= K ,如果是,则返回true,如果不是,我们可以大胆舍去前一个的下标,将其转换成新的下标(注:由于下标是不断变大的,如果前一个下标与当前遍历到的字符都不符合条件,那么它肯定与后面遍历到的字符也不符合条件)
代码实现:
cpp
class Solution {
public:
bool containsNearbyDuplicate(vector<int>& nums, int k) {
unordered_map<int,int> hash;
int n = nums.size();
for(int i = 0;i < n;i++)
{
if(hash.count(nums[i]))
{
if(i - hash[nums[i]] <= k)
return true;
}
hash[nums[i]] = i;
}
return false;
}
};🚀五、字母异位词分组
题目链接:字母异位词分组
题目描述:
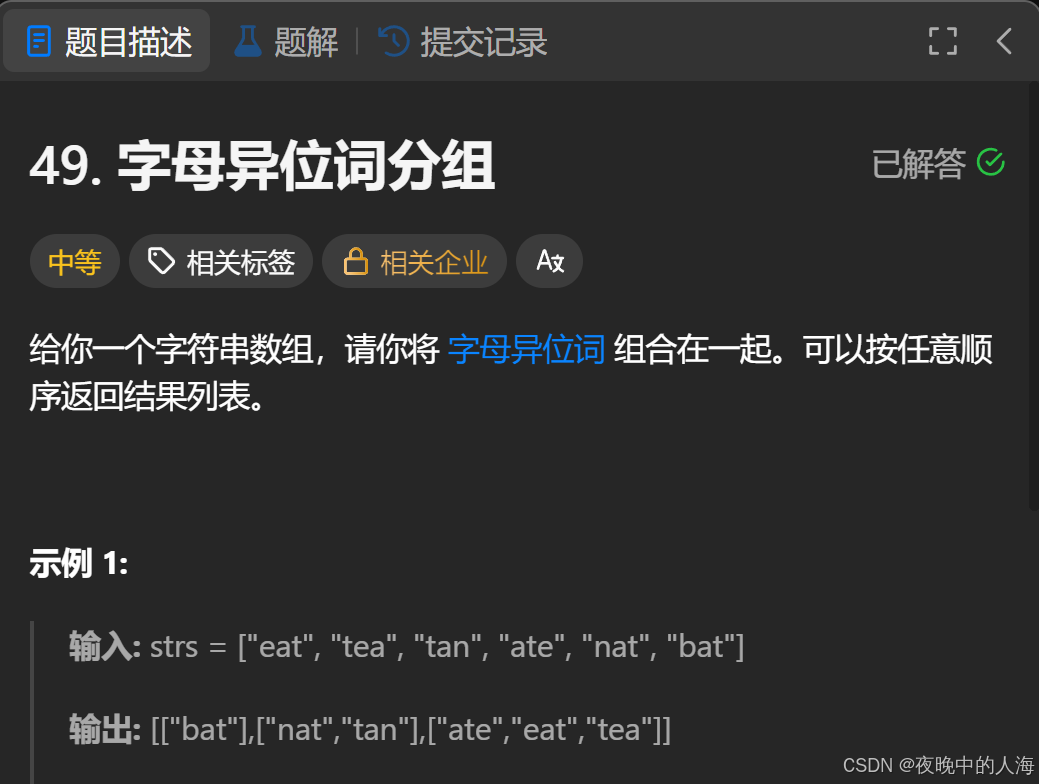
解题思路:
1.当两个单词互为字母异位词 时,当他们经过排序 后,两个单词是完全相同 的,因此根据这一特性,我们就可以将排序后的单词划分到同一组中,借助哈希表这一容器来实现这一功能
2.然后在从哈希表中提取我们所需要的结果即可
代码实现:
cpp
class Solution {
public:
vector<vector<string>> groupAnagrams(vector<string>& strs) {
unordered_map<string,vector<string>> hash;
//将所有字母异位词进行分组
for(auto s : strs)
{
string tmp = s;
sort(tmp.begin(),tmp.end());
hash[tmp].push_back(s);
}
//将结果提取出来
vector<vector<string>> ret;
for(auto& [x,y] : hash)
{
ret.push_back(y);
}
return ret;
}
};今天的分享就到这里啦,希望对您有所帮助!